9. Những Rắc Rối Với Hệ Thống Phân Tán
Tai nạn là thứ kỳ lạ. Bạn không gặp chúng cho đến khi chúng ập đến.
A.A. Milne, The House at Pooh Corner (1928)
Như đã thảo luận trong “Độ Tin Cậy và Khả Năng Chịu Lỗi”, xây dựng một hệ thống đáng tin cậy có nghĩa là đảm bảo toàn bộ hệ thống tiếp tục hoạt động, ngay cả khi có sự cố (tức là khi xảy ra lỗi). Tuy nhiên, việc dự đoán tất cả các lỗi có thể xảy ra và xử lý chúng không phải là điều dễ dàng. Là một lập trình viên, bạn rất dễ bị cám dỗ tập trung chủ yếu vào “happy path” (con đường thuận lợi, tức là khi mọi thứ diễn ra bình thường) và bỏ qua các trường hợp lỗi, vì chúng tạo ra rất nhiều trường hợp đặc biệt.
Nếu bạn muốn hệ thống của mình đáng tin cậy khi có lỗi, bạn phải thay đổi tư duy một cách triệt để và tập trung vào những thứ có thể xảy ra sai, dù chúng có thể ít khi xảy ra. Không quan trọng liệu chỉ có một trong một triệu khả năng xảy ra sai: trong một hệ thống đủ lớn, những sự kiện một trong một triệu xảy ra mỗi ngày. Những người vận hành hệ thống giàu kinh nghiệm sẽ cho bạn biết rằng bất cứ điều gì có thể xảy ra sai sẽ xảy ra sai.
Hơn nữa, làm việc với các hệ thống phân tán về cơ bản khác với việc viết phần mềm trên một máy tính đơn lẻ, và sự khác biệt chính là có rất nhiều cách mới và thú vị để mọi thứ đi sai 1 2. Trong chương này, bạn sẽ nếm thử những vấn đề thực tế phát sinh, và hiểu được những gì bạn có thể và không thể dựa vào.
Để hiểu những thách thức mà chúng ta phải đối mặt, giờ chúng ta sẽ đẩy sự bi quan lên mức tối đa và khám phá những thứ có thể đi sai trong một hệ thống phân tán. Chúng ta sẽ xem xét các vấn đề với mạng (“Mạng Không Đáng Tin Cậy”) cũng như đồng hồ và các vấn đề về thời gian (“Đồng Hồ Không Đáng Tin Cậy”). Hệ quả của tất cả những vấn đề này rất gây mất phương hướng, vì vậy chúng ta sẽ khám phá cách suy nghĩ về trạng thái của một hệ thống phân tán và cách lý luận về những gì đã xảy ra (“Kiến Thức, Sự Thật, và Dối Trá”). Sau đó, trong Chương 10, chúng ta sẽ xem xét một số ví dụ về cách đạt được khả năng chịu lỗi trước những lỗi đó.
Lỗi và Thất Bại Một Phần
Khi bạn viết một chương trình trên một máy tính đơn lẻ, nó thường hoạt động theo cách khá dự đoán được: nó hoạt động hoặc không hoạt động. Phần mềm có lỗi có thể tạo ra cảm giác rằng máy tính đôi khi “đang trong ngày tệ” (một vấn đề thường được khắc phục bằng cách khởi động lại), nhưng đó chủ yếu chỉ là hệ quả của phần mềm được viết kém.
Không có lý do cơ bản nào tại sao phần mềm trên một máy tính đơn lẻ lại không ổn định: khi phần cứng hoạt động đúng, cùng một thao tác luôn tạo ra cùng một kết quả (nó là deterministic, tức là có tính xác định). Nếu có sự cố phần cứng (ví dụ: hỏng bộ nhớ hoặc một đầu nối lỏng), hệ quả thường là toàn bộ hệ thống bị lỗi (ví dụ: kernel panic, “màn hình xanh chết chóc,” không khởi động được). Một máy tính riêng lẻ với phần mềm tốt thường hoàn toàn hoạt động hoặc hoàn toàn bị hỏng, chứ không phải điều gì đó ở giữa.
Đây là một lựa chọn có chủ ý trong thiết kế máy tính: nếu xảy ra lỗi nội bộ, chúng ta muốn máy tính bị treo hoàn toàn hơn là trả về kết quả sai, vì kết quả sai rất khó và gây nhầm lẫn khi xử lý. Vì vậy, máy tính che giấu thực tế vật lý mờ nhạt mà chúng được triển khai và trình bày một mô hình hệ thống lý tưởng hoạt động với sự hoàn hảo toán học. Một lệnh CPU luôn thực hiện điều tương tự; nếu bạn ghi một số dữ liệu vào bộ nhớ hoặc đĩa, dữ liệu đó vẫn còn nguyên và không bị hỏng ngẫu nhiên. Như đã thảo luận trong “Lỗi Phần Cứng và Phần Mềm”, điều này thực sự không đúng, trong thực tế, dữ liệu bị hỏng âm thầm và CPU đôi khi âm thầm trả về kết quả sai, nhưng nó xảy ra hiếm đến mức chúng ta có thể bỏ qua.
Khi bạn viết phần mềm chạy trên nhiều máy tính, được kết nối qua mạng, tình huống về cơ bản khác nhau. Trong các hệ thống phân tán, lỗi xảy ra thường xuyên hơn nhiều, và vì vậy chúng ta không thể bỏ qua chúng nữa, chúng ta không có lựa chọn nào khác ngoài việc đối mặt với thực tế lộn xộn của thế giới vật lý. Và trong thế giới vật lý, một loạt đáng kể những thứ có thể xảy ra sai, như được minh họa bởi giai thoại này 3:
Với kinh nghiệm hạn chế của mình, tôi đã xử lý các phân vùng mạng tồn tại lâu trong một trung tâm dữ liệu (DC), các sự cố PDU [đơn vị phân phối nguồn điện], sự cố switch, các chu kỳ cấp nguồn ngẫu nhiên cho toàn bộ tủ rack, các sự cố đường trục toàn DC, các sự cố nguồn điện toàn DC, và một tài xế bị hạ đường huyết lao xe tải Ford của anh ta vào hệ thống HVAC [sưởi ấm, thông gió và điều hòa không khí] của một DC. Và tôi thậm chí không phải là người vận hành hệ thống.
Coda Hale
Trong một hệ thống phân tán, rất có thể có một số phần của hệ thống bị hỏng theo cách không thể đoán trước, ngay cả khi các phần khác của hệ thống hoạt động bình thường. Đây được gọi là partial failure (thất bại một phần). Khó khăn là các thất bại một phần là nondeterministic (không xác định): nếu bạn cố thực hiện bất kỳ điều gì liên quan đến nhiều node và mạng, đôi khi nó có thể hoạt động và đôi khi thất bại không thể đoán trước. Như chúng ta sẽ thấy, bạn thậm chí có thể không biết liệu điều gì đó có thành công hay không!
Tính không xác định và khả năng xảy ra thất bại một phần chính là điều khiến hệ thống phân tán khó làm việc 4. Mặt khác, nếu một hệ thống phân tán có thể chịu đựng các thất bại một phần, điều đó mở ra những khả năng mạnh mẽ: ví dụ, nó cho phép bạn thực hiện rolling upgrade (nâng cấp cuốn chiếu), khởi động lại từng node một để cài đặt cập nhật phần mềm trong khi toàn bộ hệ thống tiếp tục hoạt động không bị gián đoạn suốt thời gian đó. Khả năng chịu lỗi do đó cho phép chúng ta làm cho các hệ thống phân tán đáng tin cậy hơn các hệ thống đơn node: chúng ta có thể xây dựng một hệ thống đáng tin cậy từ các thành phần không đáng tin cậy.
Nhưng trước khi chúng ta có thể triển khai khả năng chịu lỗi, chúng ta cần biết thêm về các lỗi mà chúng ta phải chịu đựng. Điều quan trọng là phải xem xét nhiều loại lỗi có thể xảy ra, kể cả những lỗi khá ít khi xảy ra, và tạo ra những tình huống như vậy một cách nhân tạo trong môi trường kiểm thử của bạn để xem điều gì xảy ra. Trong các hệ thống phân tán, sự nghi ngờ, bi quan, và hoang mang đều có ích.
Mạng Không Đáng Tin Cậy
Như đã thảo luận trong “Kiến Trúc Bộ Nhớ Chung, Đĩa Chung, và Không Chia Sẻ Gì”, các hệ thống phân tán mà chúng ta tập trung vào trong cuốn sách này chủ yếu là shared-nothing systems (hệ thống không chia sẻ gì): tức là, một tập hợp các máy được kết nối bởi một mạng. Mạng là cách duy nhất để các máy đó giao tiếp, chúng ta giả định rằng mỗi máy có bộ nhớ và đĩa riêng của mình, và một máy không thể truy cập bộ nhớ hoặc đĩa của máy khác (ngoại trừ bằng cách gửi yêu cầu đến một dịch vụ qua mạng). Ngay cả khi lưu trữ được chia sẻ, chẳng hạn như với Amazon S3, các máy giao tiếp với các dịch vụ lưu trữ chia sẻ qua mạng.
Internet và hầu hết các mạng nội bộ trong các trung tâm dữ liệu (thường là Ethernet) là asynchronous packet networks (mạng gói không đồng bộ). Trong loại mạng này, một node có thể gửi một thông điệp (một gói tin) đến một node khác, nhưng mạng không đưa ra đảm bảo nào về thời điểm nó sẽ đến, hay liệu nó có đến hay không. Nếu bạn gửi một yêu cầu và mong đợi phản hồi, nhiều thứ có thể đi sai (một số trong số đó được minh họa trong Hình 9-1):
- Yêu cầu của bạn có thể đã bị mất (có lẽ ai đó đã rút một cáp mạng).
- Yêu cầu của bạn có thể đang chờ trong một hàng đợi và sẽ được giao sau (có lẽ mạng hoặc người nhận bị quá tải).
- Node từ xa có thể đã bị lỗi (có lẽ nó bị treo hoặc bị tắt nguồn).
- Node từ xa có thể đã tạm thời ngừng phản hồi (có lẽ nó đang trải qua khoảng dừng garbage collection dài; xem “Tạm Dừng Tiến Trình”), nhưng nó sẽ bắt đầu phản hồi lại sau.
- Node từ xa có thể đã xử lý yêu cầu của bạn, nhưng phản hồi đã bị mất trên mạng (có lẽ một switch mạng đã bị cấu hình sai).
- Node từ xa có thể đã xử lý yêu cầu của bạn, nhưng phản hồi bị trì hoãn và sẽ được giao sau (có lẽ mạng hoặc máy của chính bạn bị quá tải).
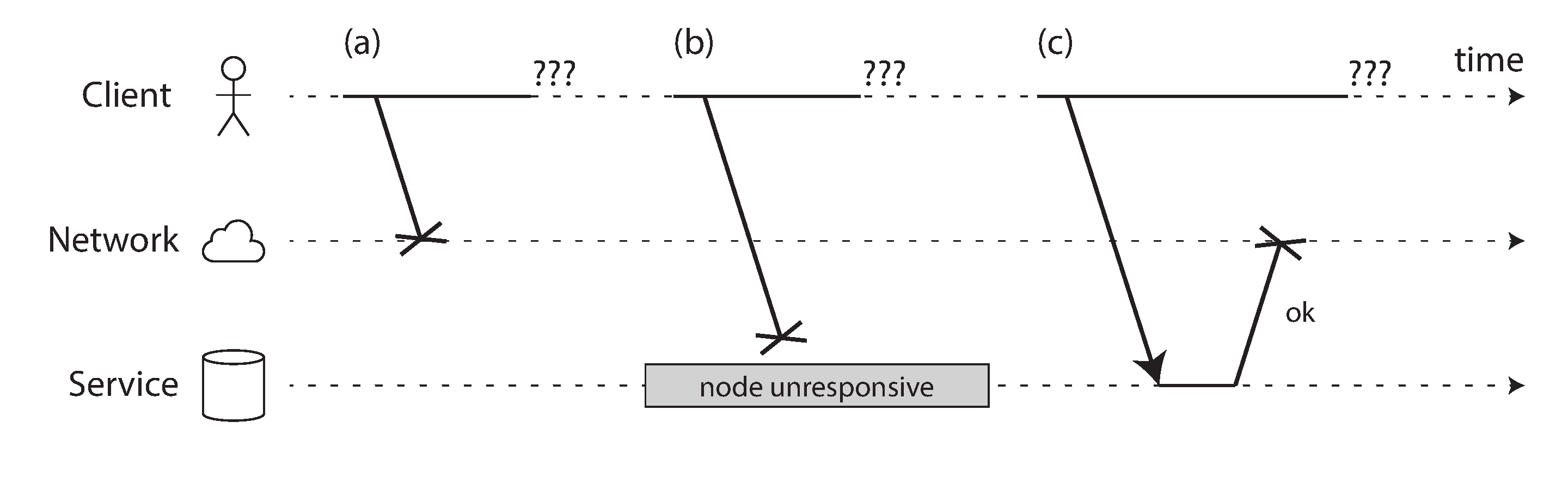
Người gửi thậm chí không thể biết liệu gói tin có được giao hay không: lựa chọn duy nhất là để người nhận gửi một thông điệp phản hồi, thứ mà lại có thể bị mất hoặc bị trì hoãn. Những vấn đề này không thể phân biệt được trong một mạng không đồng bộ: thông tin duy nhất bạn có là bạn chưa nhận được phản hồi. Nếu bạn gửi một yêu cầu đến một node khác và không nhận được phản hồi, không thể biết tại sao.
Cách thông thường để xử lý vấn đề này là timeout (hết thời gian chờ): sau một khoảng thời gian nhất định bạn từ bỏ việc chờ đợi và giả định rằng phản hồi sẽ không đến. Tuy nhiên, khi timeout xảy ra, bạn vẫn không biết liệu node từ xa có nhận được yêu cầu của bạn hay không (và nếu yêu cầu vẫn đang xếp hàng đâu đó, nó vẫn có thể được giao đến người nhận, ngay cả khi người gửi đã từ bỏ).
Giới Hạn Của TCP
Các gói tin mạng có kích thước tối đa (thường là vài kilobyte), nhưng nhiều ứng dụng cần gửi các thông điệp (yêu cầu, phản hồi) quá lớn để vừa trong một gói tin. Các ứng dụng này thường sử dụng TCP, Transmission Control Protocol (Giao Thức Kiểm Soát Truyền Tải), để thiết lập một kết nối chia nhỏ các luồng dữ liệu lớn thành các gói tin riêng lẻ và ghép chúng lại ở phía nhận.
Note
Hầu hết những gì chúng ta nói về TCP cũng áp dụng cho QUIC, phương án thay thế gần đây hơn, cũng như Stream Control Transmission Protocol (SCTP) được sử dụng trong WebRTC, giao thức BitTorrent uTP, và các giao thức truyền tải khác. Để so sánh với UDP, xem “TCP Versus UDP”.
TCP thường được mô tả là cung cấp khả năng giao hàng “đáng tin cậy”, theo nghĩa là nó phát hiện và truyền lại các gói tin bị rớt, phát hiện các gói tin bị đảo thứ tự và đặt chúng trở lại đúng thứ tự, và phát hiện hỏng hóc gói tin bằng cách sử dụng một checksum đơn giản. Nó cũng tính toán tốc độ gửi dữ liệu để dữ liệu được truyền nhanh nhất có thể, nhưng không làm quá tải mạng hoặc node nhận; điều này được gọi là congestion control (kiểm soát tắc nghẽn), flow control (kiểm soát luồng), hoặc backpressure (áp lực ngược) 5.
Khi bạn “gửi” một số dữ liệu bằng cách ghi nó vào một socket, thực ra nó không được gửi ngay lập tức, mà chỉ được đặt vào một bộ đệm do hệ điều hành của bạn quản lý. Khi thuật toán kiểm soát tắc nghẽn quyết định rằng nó có đủ khả năng để gửi một gói tin, nó lấy dữ liệu đủ cho gói tin tiếp theo từ bộ đệm đó và chuyển nó đến giao diện mạng. Gói tin đi qua một số switch và router, và cuối cùng hệ điều hành của node nhận đặt dữ liệu của gói tin vào bộ đệm nhận và gửi lại một gói tin acknowledgment (xác nhận) cho người gửi. Chỉ lúc đó hệ điều hành nhận mới thông báo cho ứng dụng rằng có thêm dữ liệu đã đến 6.
Vậy, nếu TCP cung cấp “độ tin cậy”, điều đó có nghĩa là chúng ta không cần lo lắng về mạng không đáng tin cậy nữa không? Tiếc là không. Nó quyết định rằng một gói tin phải bị mất nếu không có acknowledgment nào đến trong vòng một timeout nhất định, nhưng TCP cũng không thể biết liệu là gói tin đi hay gói tin acknowledgment đã bị mất. Mặc dù TCP có thể gửi lại gói tin, nhưng nó không thể đảm bảo rằng gói tin mới cũng sẽ đến được. Nếu cáp mạng bị rút ra, TCP không thể cắm lại cho bạn. Cuối cùng, sau một timeout có thể cấu hình, TCP từ bỏ và báo hiệu lỗi cho ứng dụng.
Nếu một kết nối TCP bị đóng với lỗi, có lẽ vì node từ xa bị treo, hoặc có lẽ vì mạng bị gián đoạn, thật không may bạn không có cách nào biết có bao nhiêu dữ liệu thực sự đã được xử lý bởi node từ xa 6. Ngay cả khi TCP xác nhận rằng một gói tin đã được giao, điều này chỉ có nghĩa là kernel hệ điều hành trên node từ xa đã nhận được nó, nhưng ứng dụng có thể đã bị treo trước khi nó xử lý dữ liệu đó. Nếu bạn muốn chắc chắn rằng một yêu cầu thành công, bạn cần một phản hồi tích cực từ chính ứng dụng 7.
Tuy nhiên, TCP rất hữu ích, vì nó cung cấp một cách thuận tiện để gửi và nhận các thông điệp quá lớn để vừa trong một gói tin. Khi một kết nối TCP được thiết lập, bạn cũng có thể sử dụng nó để gửi nhiều yêu cầu và phản hồi. Điều này thường được thực hiện bằng cách đầu tiên gửi một header cho biết độ dài của thông điệp tiếp theo tính bằng byte, sau đó là thông điệp thực tế. HTTP và nhiều giao thức RPC (xem “Luồng Dữ Liệu Qua Dịch Vụ: REST và RPC”) hoạt động theo cách này.
Lỗi Mạng Trong Thực Tế
Chúng ta đã xây dựng mạng máy tính trong nhiều thập kỷ, người ta có thể hy vọng rằng bây giờ chúng ta đã tìm ra cách làm cho chúng đáng tin cậy. Thật không may, chúng ta vẫn chưa thành công. Có một số nghiên cứu hệ thống và nhiều bằng chứng từ kinh nghiệm thực tế, cho thấy rằng các vấn đề mạng có thể phổ biến một cách đáng ngạc nhiên, ngay cả trong các môi trường được kiểm soát như một trung tâm dữ liệu được vận hành bởi một công ty 8:
- Một nghiên cứu tại một trung tâm dữ liệu cỡ trung bình phát hiện khoảng 12 lỗi mạng mỗi tháng, trong đó một nửa ngắt kết nối một máy duy nhất, và nửa còn lại ngắt kết nối toàn bộ một tủ rack 9.
- Một nghiên cứu khác đo tỷ lệ lỗi của các thành phần như switch top-of-rack (đỉnh tủ rack), switch tổng hợp, và bộ cân bằng tải 10. Nghiên cứu phát hiện ra rằng thêm thiết bị mạng dư thừa không làm giảm lỗi nhiều như bạn có thể kỳ vọng, vì nó không bảo vệ chống lại lỗi của con người (ví dụ: switch bị cấu hình sai), đây là nguyên nhân chính gây ra sự cố.
- Các sự cố gián đoạn đường cáp quang diện rộng đã bị đổ lỗi cho bò 11, hải ly 12, và cá mập 13 (mặc dù vết cắn của cá mập đã trở nên hiếm hơn do cáp ngầm được che chắn tốt hơn 14). Con người cũng có lỗi, do cấu hình sai ngẫu nhiên 15, tháo dỡ phế liệu 16, hay phá hoại 17.
- Trên các vùng cloud khác nhau, thời gian round-trip lên đến vài phút đã được quan sát tại các phân vị cao 18. Ngay cả trong một trung tâm dữ liệu duy nhất, độ trì hoãn gói tin hơn một phút có thể xảy ra trong quá trình tái cấu hình topology mạng, được kích hoạt bởi một vấn đề trong quá trình nâng cấp phần mềm cho một switch 19. Do đó, chúng ta phải giả định rằng các thông điệp có thể bị trì hoãn tùy ý.
- Đôi khi các liên lạc bị gián đoạn một phần, tùy thuộc vào đối tượng bạn đang nói chuyện: ví dụ, A và B có thể giao tiếp, B và C có thể giao tiếp, nhưng A và C thì không 20 21. Các lỗi đáng ngạc nhiên khác bao gồm một giao diện mạng đôi khi bỏ tất cả các gói tin đến nhưng gửi các gói tin đi thành công 22: chỉ vì một liên kết mạng hoạt động theo một chiều không đảm bảo rằng nó cũng hoạt động theo chiều ngược lại.
- Ngay cả một gián đoạn mạng ngắn cũng có thể có những hậu quả kéo dài lâu hơn nhiều so với vấn đề ban đầu 8 20 23.
NETWORK PARTITIONS
Khi một phần của mạng bị cắt đứt khỏi phần còn lại do lỗi mạng, đôi khi được gọi là network partition (phân vùng mạng) hoặc netsplit, nhưng về cơ bản không khác gì các loại gián đoạn mạng khác. Các network partition không liên quan đến sharding (phân mảnh) của hệ thống lưu trữ, đôi khi cũng được gọi là partitioning (xem Chương 7).
Ngay cả khi lỗi mạng hiếm khi xảy ra trong môi trường của bạn, thực tế là lỗi có thể xảy ra có nghĩa là phần mềm của bạn cần có khả năng xử lý chúng. Bất cứ khi nào có bất kỳ liên lạc nào xảy ra qua mạng, nó có thể thất bại, không có cách nào tránh khỏi điều đó.
Nếu việc xử lý lỗi mạng không được định nghĩa và kiểm thử, những điều tồi tệ tùy ý có thể xảy ra: ví dụ, cluster có thể bị deadlock và vĩnh viễn không thể phục vụ yêu cầu, ngay cả khi mạng phục hồi 24, hoặc thậm chí có thể xóa tất cả dữ liệu của bạn 25. Nếu phần mềm được đặt vào một tình huống không được dự đoán, nó có thể làm những điều bất ngờ tùy ý.
Xử lý lỗi mạng không nhất thiết có nghĩa là chịu đựng chúng: nếu mạng của bạn thường khá đáng tin cậy, một cách tiếp cận hợp lệ có thể là chỉ đơn giản là hiển thị thông báo lỗi cho người dùng trong khi mạng của bạn đang gặp vấn đề. Tuy nhiên, bạn cần biết cách phần mềm của bạn phản ứng với các vấn đề mạng và đảm bảo rằng hệ thống có thể phục hồi từ chúng. Có thể nên cố tình kích hoạt các vấn đề mạng và kiểm thử phản hồi của hệ thống (đây được gọi là fault injection, tức là tiêm lỗi; xem “Tiêm Lỗi”).
Phát Hiện Lỗi
Nhiều hệ thống cần tự động phát hiện các node bị lỗi. Ví dụ:
- Một bộ cân bằng tải cần ngừng gửi yêu cầu đến một node đã chết (tức là, đưa nó ra khỏi vòng phục vụ).
- Trong một cơ sở dữ liệu phân tán với replication single-leader (một leader đơn), nếu leader bị lỗi, một trong số các follower cần được thăng cấp trở thành leader mới (xem “Xử Lý Sự Cố Node”).
Thật không may, sự không chắc chắn về mạng khiến khó có thể biết liệu một node có đang hoạt động hay không. Trong một số trường hợp cụ thể, bạn có thể nhận được một số phản hồi để cho bạn biết rõ ràng rằng điều gì đó không hoạt động:
- Nếu bạn có thể đến được máy mà node đáng lẽ đang chạy trên đó, nhưng không có tiến trình nào lắng nghe trên cổng đích (ví dụ: vì tiến trình bị treo), hệ điều hành sẽ hữu ích đóng hoặc từ chối các kết nối TCP bằng cách gửi gói tin
RSThoặcFINđể trả lời. - Nếu một tiến trình node bị treo (hoặc bị một quản trị viên kill) nhưng hệ điều hành của node vẫn đang chạy, một script có thể thông báo cho các node khác về sự cố để một node khác có thể tiếp quản nhanh chóng mà không cần chờ timeout hết hạn. Ví dụ, HBase làm điều này 26.
- Nếu bạn có quyền truy cập vào giao diện quản lý của các switch mạng trong trung tâm dữ liệu của bạn, bạn có thể truy vấn chúng để phát hiện lỗi liên kết ở mức phần cứng (ví dụ: nếu máy từ xa đã tắt nguồn). Tùy chọn này bị loại trừ nếu bạn đang kết nối qua internet, hoặc nếu bạn đang ở trong một trung tâm dữ liệu chia sẻ mà không có quyền truy cập vào các switch, hoặc nếu bạn không thể đến giao diện quản lý do sự cố mạng.
- Nếu một router chắc chắn rằng địa chỉ IP bạn đang cố kết nối không thể đến được, nó có thể trả lời bạn bằng một gói tin ICMP Destination Unreachable (Đích Không Thể Đến Được). Tuy nhiên, router cũng không có khả năng phát hiện lỗi kỳ diệu, nó phải chịu những giới hạn tương tự như các thành viên khác của mạng.
Phản hồi nhanh về việc một node từ xa đang bị lỗi là hữu ích, nhưng bạn không thể dựa vào nó. Nếu có gì đó xảy ra sai, bạn có thể nhận được phản hồi lỗi ở một mức nào đó của stack, nhưng nói chung bạn phải giả định rằng bạn sẽ không nhận được phản hồi gì cả. Bạn có thể thử lại vài lần, chờ timeout hết hạn, và cuối cùng tuyên bố node đã chết nếu bạn không nghe thấy gì trong vòng timeout.
Timeout và Độ Trì Hoãn Không Giới Hạn
Nếu timeout là cách duy nhất chắc chắn để phát hiện lỗi, thì timeout nên bao lâu? Thật không may không có câu trả lời đơn giản.
Một timeout dài có nghĩa là chờ lâu cho đến khi một node được tuyên bố chết (và trong thời gian này, người dùng có thể phải chờ hoặc thấy thông báo lỗi). Một timeout ngắn phát hiện lỗi nhanh hơn, nhưng mang rủi ro cao hơn là tuyên bố nhầm một node đã chết khi thực tế nó chỉ bị chậm tạm thời (ví dụ: do tăng tải đột biến trên node hoặc mạng).
Tuyên bố sớm một node đã chết là có vấn đề: nếu node thực sự vẫn sống và đang thực hiện một số hành động (ví dụ: gửi email), và một node khác tiếp quản, hành động đó có thể bị thực hiện hai lần. Chúng ta sẽ thảo luận về vấn đề này chi tiết hơn trong “Kiến Thức, Sự Thật, và Dối Trá”, Chương 10, và “Luận Điểm End-to-End Cho Cơ Sở Dữ Liệu”.
Khi một node được tuyên bố chết, các trách nhiệm của nó cần được chuyển giao cho các node khác, điều này đặt thêm tải trọng lên các node và mạng khác. Nếu hệ thống đã đang gặp khó khăn với tải cao, việc tuyên bố các node chết sớm có thể làm cho vấn đề tệ hơn. Đặc biệt, có thể xảy ra rằng node thực sự không chết mà chỉ phản hồi chậm do quá tải; việc chuyển tải của nó sang các node khác có thể gây ra thất bại theo dây chuyền (trong trường hợp cực đoan, tất cả các node tuyên bố nhau đã chết, và mọi thứ ngừng hoạt động, xem “Khi một hệ thống quá tải không thể phục hồi”).
Hãy tưởng tượng một hệ thống giả định với một mạng đảm bảo độ trì hoãn tối đa cho các gói tin, mỗi gói tin được giao trong vòng một khoảng thời gian d, hoặc nó bị mất, nhưng việc giao hàng không bao giờ mất lâu hơn d. Hơn nữa, giả sử rằng bạn có thể đảm bảo rằng một node không bị lỗi luôn xử lý một yêu cầu trong một khoảng thời gian r. Trong trường hợp này, bạn có thể đảm bảo rằng mọi yêu cầu thành công đều nhận được phản hồi trong vòng thời gian 2d + r, và nếu bạn không nhận được phản hồi trong khoảng thời gian đó, bạn biết rằng mạng hoặc node từ xa không hoạt động. Nếu điều này đúng, 2d + r sẽ là một timeout hợp lý để sử dụng.
Thật không may, hầu hết các hệ thống chúng ta làm việc cùng không có bất kỳ đảm bảo nào trong số đó: các mạng không đồng bộ có unbounded delays (độ trì hoãn không giới hạn), tức là chúng cố gắng giao gói tin nhanh nhất có thể, nhưng không có giới hạn trên về thời gian một gói tin có thể mất để đến nơi, và hầu hết các triển khai máy chủ không thể đảm bảo rằng chúng có thể xử lý các yêu cầu trong một khoảng thời gian tối đa nào đó (xem “Đảm Bảo Thời Gian Phản Hồi”). Để phát hiện lỗi, hệ thống không đủ để nhanh hầu hết thời gian: nếu timeout của bạn thấp, chỉ cần một đợt tăng tạm thời trong thời gian round-trip là đủ để hệ thống mất cân bằng.
Tắc nghẽn mạng và hàng đợi
Khi lái xe, thời gian di chuyển trên mạng lưới đường bộ thường biến đổi nhiều nhất do tắc nghẽn giao thông. Tương tự, sự biến đổi của độ trì hoãn gói tin trên các mạng máy tính thường là do hàng đợi 27:
- Nếu nhiều node khác nhau đồng thời cố gửi gói tin đến cùng một đích, switch mạng phải xếp hàng chúng và đưa chúng vào liên kết mạng đích từng cái một (như minh họa trong Hình 9-2). Trên một liên kết mạng bận rộn, một gói tin có thể phải chờ một lúc cho đến khi nó có thể có một slot (đây được gọi là network congestion, tắc nghẽn mạng). Nếu có quá nhiều dữ liệu đến đến mức hàng đợi switch bị đầy, gói tin bị rớt, do đó nó cần được gửi lại, mặc dù mạng hoạt động bình thường.
- Khi một gói tin đến máy đích, nếu tất cả các lõi CPU hiện đang bận, yêu cầu đến từ mạng được hệ điều hành xếp hàng cho đến khi ứng dụng sẵn sàng xử lý nó. Tùy thuộc vào tải trên máy, điều này có thể mất một khoảng thời gian tùy ý 28.
- Trong các môi trường ảo hóa, một hệ điều hành đang chạy thường bị tạm dừng trong hàng chục mili giây trong khi một máy ảo khác sử dụng một lõi CPU. Trong thời gian này, VM không thể tiêu thụ bất kỳ dữ liệu nào từ mạng, do đó dữ liệu đến được xếp hàng (đệm) bởi bộ giám sát máy ảo 29, càng làm tăng thêm sự biến đổi của độ trì hoãn mạng.
- Như đã đề cập trước đó, để tránh làm quá tải mạng, TCP giới hạn tốc độ gửi dữ liệu. Điều này có nghĩa là thêm hàng đợi tại người gửi trước khi dữ liệu thậm chí đi vào mạng.
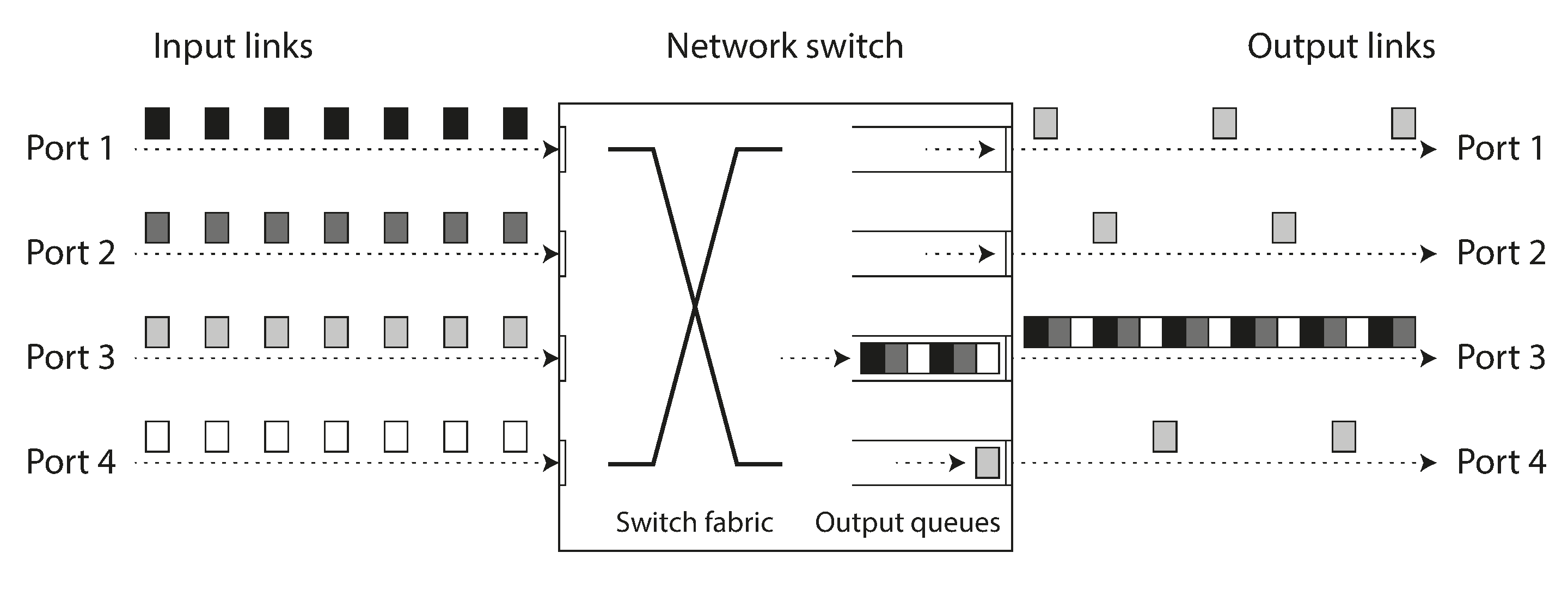
Hơn nữa, khi TCP phát hiện và tự động truyền lại một gói tin bị mất, mặc dù ứng dụng không thấy trực tiếp việc mất gói tin, nó thấy sự trì hoãn kết quả (chờ timeout hết hạn, và sau đó chờ gói tin được truyền lại được xác nhận).
TCP VERSUS UDP
Một số ứng dụng nhạy cảm với độ trễ, chẳng hạn như hội nghị video và Voice over IP (VoIP), sử dụng UDP thay vì TCP. Đây là sự đánh đổi giữa độ tin cậy và sự biến đổi của độ trì hoãn: vì UDP không thực hiện kiểm soát luồng và không truyền lại các gói tin bị mất, nó tránh được một số nguyên nhân gây ra sự biến đổi độ trì hoãn mạng (mặc dù nó vẫn dễ bị ảnh hưởng bởi hàng đợi switch và độ trì hoãn lập lịch).
UDP là lựa chọn tốt trong các tình huống mà dữ liệu bị trì hoãn là vô dụng. Ví dụ, trong cuộc gọi điện thoại VoIP, có lẽ không có đủ thời gian để truyền lại một gói tin bị mất trước khi dữ liệu của nó đến lúc phát qua loa. Trong trường hợp này, không có ý nghĩa gì trong việc truyền lại gói tin, ứng dụng phải thay vào đó lấp đầy khoảng thời gian của gói tin bị thiếu bằng im lặng (gây ra sự gián đoạn âm thanh ngắn) và tiếp tục luồng. Việc thử lại xảy ra ở tầng con người thay thế. (“Bạn có thể nhắc lại không? Âm thanh vừa bị ngắt một lúc.”)
Tất cả những yếu tố này góp phần vào sự biến đổi của độ trì hoãn mạng. Độ trì hoãn hàng đợi có phạm vi đặc biệt rộng khi một hệ thống gần đến công suất tối đa của nó: một hệ thống có nhiều dung lượng dự phòng có thể dễ dàng làm sạch hàng đợi, trong khi trong một hệ thống được sử dụng cao, các hàng đợi dài có thể tích tụ rất nhanh.
Trong các đám mây công cộng và các trung tâm dữ liệu đa thuê bao, tài nguyên được chia sẻ giữa nhiều khách hàng: các liên kết mạng và switch, và thậm chí giao diện mạng của mỗi máy và CPU (khi chạy trên máy ảo), đều được chia sẻ. Xử lý lượng lớn dữ liệu có thể sử dụng toàn bộ dung lượng của các liên kết mạng (bão hòa chúng). Vì bạn không kiểm soát hay có thể nhìn thấy việc sử dụng tài nguyên chia sẻ của các khách hàng khác, độ trì hoãn mạng có thể rất biến đổi nếu ai đó gần bạn (một noisy neighbor, hàng xóm ồn ào) đang sử dụng nhiều tài nguyên 30 31.
Trong những môi trường như vậy, bạn chỉ có thể chọn timeout bằng thực nghiệm: đo phân phối của thời gian round-trip mạng trong một khoảng thời gian dài, và trên nhiều máy, để xác định sự biến đổi dự kiến của độ trì hoãn. Sau đó, tính đến các đặc điểm của ứng dụng của bạn, bạn có thể xác định sự đánh đổi phù hợp giữa độ trì hoãn phát hiện lỗi và rủi ro timeout sớm.
Thậm chí tốt hơn, thay vì sử dụng các timeout hằng số được cấu hình, các hệ thống có thể liên tục đo thời gian phản hồi và sự biến đổi của chúng (jitter), và tự động điều chỉnh timeout theo phân phối thời gian phản hồi quan sát được. Bộ phát hiện lỗi Phi Accrual 32, được sử dụng ví dụ trong Akka và Cassandra 33, là một cách để làm điều này. Timeout truyền lại TCP cũng hoạt động theo cách tương tự 5.
Mạng Đồng Bộ Versus Không Đồng Bộ
Các hệ thống phân tán sẽ đơn giản hơn nhiều nếu chúng ta có thể dựa vào mạng để giao gói tin với một độ trì hoãn tối đa cố định, và không rớt gói tin. Tại sao chúng ta không thể giải quyết vấn đề này ở mức phần cứng và làm cho mạng đáng tin cậy để phần mềm không cần lo lắng về nó?
Để trả lời câu hỏi này, thật thú vị khi so sánh các mạng trung tâm dữ liệu với mạng điện thoại cố định truyền thống (không phải di động, không phải VoIP), thứ cực kỳ đáng tin cậy: các khung âm thanh bị trì hoãn và cuộc gọi bị ngắt rất hiếm. Một cuộc gọi điện thoại yêu cầu độ trễ end-to-end (đầu cuối đến đầu cuối) thấp liên tục và đủ băng thông để truyền các mẫu âm thanh giọng nói của bạn. Sẽ tuyệt vời nếu có độ tin cậy và khả năng đoán trước tương tự trong các mạng máy tính không?
Khi bạn thực hiện một cuộc gọi qua mạng điện thoại, nó thiết lập một circuit (mạch): một lượng băng thông cố định và được đảm bảo được phân bổ cho cuộc gọi, dọc theo toàn bộ tuyến đường giữa hai người gọi. Circuit này vẫn còn đó cho đến khi cuộc gọi kết thúc 34. Ví dụ, một mạng ISDN chạy ở tốc độ cố định 4.000 khung mỗi giây. Khi một cuộc gọi được thiết lập, nó được phân bổ 16 bit không gian trong mỗi khung (theo mỗi chiều). Do đó, trong suốt thời gian cuộc gọi, mỗi bên được đảm bảo có thể gửi chính xác 16 bit dữ liệu âm thanh mỗi 250 micro giây 35.
Loại mạng này là synchronous (đồng bộ): ngay cả khi dữ liệu đi qua một số router, nó không bị hàng đợi, vì 16 bit không gian cho cuộc gọi đã được dự trữ trong hop (bước nhảy) tiếp theo của mạng. Và vì không có hàng đợi, độ trễ end-to-end tối đa của mạng là cố định. Chúng ta gọi đây là bounded delay (độ trì hoãn có giới hạn).
Chúng ta không thể đơn giản làm cho độ trì hoãn mạng có thể đoán trước được sao?
Lưu ý rằng một circuit trong mạng điện thoại rất khác với một kết nối TCP: một circuit là một lượng băng thông dự trữ cố định mà không ai khác có thể sử dụng trong khi circuit được thiết lập, trong khi các gói tin của một kết nối TCP tận dụng cơ hội sử dụng bất kỳ băng thông mạng nào có sẵn. Bạn có thể cho TCP một khối dữ liệu có kích thước thay đổi (ví dụ: một email hoặc một trang web), và nó sẽ cố gắng truyền nó trong thời gian ngắn nhất có thể. Trong khi một kết nối TCP đang nhàn rỗi, nó không sử dụng bất kỳ băng thông nào (ngoại trừ có thể là một gói tin keepalive thỉnh thoảng).
Nếu các mạng trung tâm dữ liệu và internet là các mạng circuit-switched (chuyển mạch theo circuit), sẽ có thể thiết lập thời gian round-trip tối đa được đảm bảo khi một circuit được thiết lập. Tuy nhiên, chúng không phải vậy: Ethernet và IP là các giao thức packet-switched (chuyển mạch gói), thứ bị ảnh hưởng bởi hàng đợi và do đó độ trì hoãn không giới hạn trong mạng. Các giao thức này không có khái niệm về circuit.
Tại sao các mạng trung tâm dữ liệu và internet lại sử dụng chuyển mạch gói? Câu trả lời là chúng được tối ưu hóa cho bursty traffic (lưu lượng theo đợt). Một circuit phù hợp cho một cuộc gọi âm thanh hoặc video, thứ cần truyền một số bit khá ổn định mỗi giây trong suốt thời gian cuộc gọi. Mặt khác, yêu cầu một trang web, gửi email, hoặc truyền một tệp không có yêu cầu băng thông cụ thể nào, chúng ta chỉ muốn nó hoàn thành nhanh nhất có thể.
Nếu bạn muốn truyền một tệp qua một circuit, bạn sẽ phải đoán một phân bổ băng thông. Nếu bạn đoán quá thấp, việc truyền không cần thiết bị chậm, để lại dung lượng mạng không được sử dụng. Nếu bạn đoán quá cao, circuit không thể được thiết lập (vì mạng không thể cho phép một circuit được tạo nếu phân bổ băng thông của nó không thể được đảm bảo). Do đó, sử dụng circuit cho việc truyền dữ liệu theo đợt lãng phí dung lượng mạng và làm cho việc truyền không cần thiết bị chậm. Ngược lại, TCP tự động điều chỉnh tốc độ truyền dữ liệu theo dung lượng mạng có sẵn.
Đã có một số nỗ lực xây dựng các mạng lai hỗ trợ cả chuyển mạch theo circuit và chuyển mạch gói. Asynchronous Transfer Mode (ATM) là một đối thủ cạnh tranh với Ethernet vào những năm 1980, nhưng nó không được áp dụng nhiều ngoài các switch lõi mạng điện thoại. InfiniBand có một số điểm tương đồng 36: nó triển khai kiểm soát luồng end-to-end ở tầng liên kết, giảm nhu cầu xếp hàng trong mạng, mặc dù nó vẫn có thể bị trì hoãn do tắc nghẽn liên kết 37. Với việc sử dụng cẩn thận quality of service (QoS, ưu tiên hóa và lập lịch gói tin) và admission control (kiểm soát nhận vào, giới hạn tốc độ người gửi), có thể mô phỏng chuyển mạch theo circuit trên các mạng gói, hoặc cung cấp độ trì hoãn có giới hạn thống kê 27 34. Các thuật toán mạng mới như Low Latency, Low Loss, and Scalable Throughput (L4S) cố gắng giảm thiểu một số vấn đề kiểm soát xếp hàng và tắc nghẽn cả ở phía client và router. Bộ điều khiển lưu lượng của Linux (TC) cũng cho phép các ứng dụng ưu tiên lại các gói tin cho mục đích QoS.
ĐỘ TRỄ VÀ HIỆU SUẤT SỬ DỤNG TÀI NGUYÊN
Nói chung hơn, bạn có thể nghĩ về các độ trễ biến đổi như là hệ quả của việc phân vùng tài nguyên động (dynamic resource partitioning).
Giả sử bạn có một đường dây nối giữa hai tổng đài điện thoại có thể truyền tối đa 10.000 cuộc gọi đồng thời. Mỗi mạch được chuyển qua đường dây này chiếm một trong các khe cuộc gọi đó. Do đó, bạn có thể coi đường dây là một tài nguyên có thể được chia sẻ bởi tối đa 10.000 người dùng đồng thời. Tài nguyên được chia theo cách tĩnh (static): ngay cả khi bạn là cuộc gọi duy nhất trên đường dây ngay lúc này, và tất cả 9.999 khe khác không được sử dụng, mạch của bạn vẫn được phân bổ cùng một lượng băng thông cố định như khi đường dây được sử dụng hoàn toàn.
Ngược lại, internet chia sẻ băng thông mạng động (dynamically). Các bên gửi tranh nhau và chen lấn để đưa các gói tin của mình qua đường dây nhanh nhất có thể, và các bộ chuyển mạng quyết định gói tin nào sẽ được gửi (tức là phân bổ băng thông) từ thời điểm này sang thời điểm khác. Cách tiếp cận này có nhược điểm là xếp hàng (queueing), nhưng ưu điểm là tối đa hóa việc sử dụng đường dây. Đường dây có chi phí cố định, vì vậy nếu bạn sử dụng nó hiệu quả hơn, mỗi byte bạn gửi qua đường dây sẽ rẻ hơn.
Tình huống tương tự xảy ra với CPU: nếu bạn chia sẻ mỗi lõi CPU một cách động giữa nhiều luồng, một luồng đôi khi phải đợi trong hàng chờ chạy của hệ điều hành trong khi luồng khác đang chạy, vì vậy một luồng có thể bị tạm dừng trong các khoảng thời gian khác nhau 38. Tuy nhiên, điều này sử dụng phần cứng hiệu quả hơn so với việc bạn phân bổ số chu kỳ CPU tĩnh cho mỗi luồng (xem “Đảm bảo thời gian phản hồi”). Việc sử dụng phần cứng tốt hơn cũng là lý do tại sao các nền tảng đám mây chạy nhiều máy ảo từ các khách hàng khác nhau trên cùng một máy vật lý.
Đảm bảo độ trễ có thể đạt được trong một số môi trường nhất định, nếu tài nguyên được phân vùng tĩnh (ví dụ: phần cứng chuyên dụng và phân bổ băng thông độc quyền). Tuy nhiên, điều đó đến với cái giá của việc giảm hiệu suất sử dụng, nói cách khác, nó đắt hơn. Mặt khác, kiến trúc nhiều người thuê (multitenancy) với phân vùng tài nguyên động cung cấp hiệu suất sử dụng tốt hơn, vì vậy nó rẻ hơn, nhưng có nhược điểm là các độ trễ biến đổi.
Các độ trễ biến đổi trong mạng không phải là quy luật tự nhiên, mà đơn giản là kết quả của sự đánh đổi chi phí/lợi ích.
Tuy nhiên, chất lượng dịch vụ như vậy hiện tại không được kích hoạt trong các trung tâm dữ liệu nhiều người thuê và đám mây công cộng, hay khi giao tiếp qua internet. Công nghệ hiện tại được triển khai không cho phép chúng ta đưa ra bất kỳ đảm bảo nào về độ trễ hoặc độ tin cậy của mạng: chúng ta phải giả định rằng tắc nghẽn mạng, xếp hàng và độ trễ không giới hạn sẽ xảy ra. Do đó, không có giá trị “đúng” cho thời gian chờ (timeout), chúng cần được xác định bằng thực nghiệm.
Các thỏa thuận kết nối (peering agreements) giữa các nhà cung cấp dịch vụ internet và việc thiết lập các tuyến đường qua Giao thức Cổng Biên giới (Border Gateway Protocol, BGP), giống với chuyển mạch kênh (circuit switching) hơn là bản thân IP. Ở cấp độ này, có thể mua băng thông chuyên dụng. Tuy nhiên, định tuyến internet hoạt động ở cấp độ mạng, không phải các kết nối riêng lẻ giữa các máy chủ, và ở thang thời gian dài hơn nhiều.
Đồng Hồ Không Đáng Tin Cậy
Đồng hồ và thời gian rất quan trọng. Các ứng dụng phụ thuộc vào đồng hồ theo nhiều cách khác nhau để trả lời các câu hỏi như sau:
- Yêu cầu này đã hết thời gian chờ chưa?
- Thời gian phản hồi ở bách phân vị thứ 99 của dịch vụ này là bao nhiêu?
- Dịch vụ này xử lý trung bình bao nhiêu truy vấn mỗi giây trong năm phút vừa qua?
- Người dùng đã dành bao nhiêu thời gian trên trang web của chúng ta?
- Bài viết này được xuất bản khi nào?
- Email nhắc nhở nên được gửi vào ngày và giờ nào?
- Mục cache này hết hạn khi nào?
- Dấu thời gian trên thông báo lỗi này trong tệp nhật ký là gì?
Các ví dụ 1 đến 4 đo thời lượng (ví dụ: khoảng thời gian giữa khi một yêu cầu được gửi và khi nhận được phản hồi), trong khi các ví dụ 5 đến 8 mô tả điểm trong thời gian (các sự kiện xảy ra vào một ngày cụ thể, vào một thời điểm cụ thể).
Trong hệ thống phân tán, thời gian là vấn đề phức tạp, vì giao tiếp không phải là tức thì: cần thời gian để một tin nhắn di chuyển qua mạng từ máy này sang máy khác. Thời điểm khi một tin nhắn được nhận luôn muộn hơn thời điểm khi nó được gửi, nhưng do các độ trễ biến đổi trong mạng, chúng ta không biết muộn hơn bao nhiêu. Thực tế này đôi khi làm cho việc xác định thứ tự mà mọi thứ xảy ra trở nên khó khăn khi có nhiều máy tham gia.
Hơn nữa, mỗi máy trên mạng có đồng hồ riêng của mình, đây là thiết bị phần cứng thực sự: thường là bộ dao động tinh thể thạch anh (quartz crystal oscillator). Các thiết bị này không hoàn toàn chính xác, vì vậy mỗi máy có quan niệm riêng về thời gian, có thể nhanh hơn hoặc chậm hơn so với các máy khác một chút. Có thể đồng bộ hóa đồng hồ ở một mức độ nào đó: cơ chế được sử dụng phổ biến nhất là Giao thức Thời gian Mạng (Network Time Protocol, NTP), cho phép đồng hồ máy tính được điều chỉnh theo thời gian được báo cáo bởi một nhóm máy chủ 39. Các máy chủ lần lượt lấy thời gian từ nguồn thời gian chính xác hơn, chẳng hạn như bộ thu GPS.
Đồng Hồ Đơn điệu So Với Đồng Hồ Thực Tế
Máy tính hiện đại có ít nhất hai loại đồng hồ khác nhau: đồng hồ thực tế (time-of-day clock) và đồng hồ đơn điệu (monotonic clock). Mặc dù cả hai đều đo thời gian, điều quan trọng là phân biệt hai loại, vì chúng phục vụ các mục đích khác nhau.
Đồng hồ thực tế
Đồng hồ thực tế (time-of-day clock) làm những gì bạn trực giác mong đợi từ một đồng hồ: nó trả về ngày và
giờ hiện tại theo một lịch nào đó (còn được gọi là wall-clock time, thời gian đồng hồ tường). Ví dụ,
clock_gettime(CLOCK_REALTIME) trên Linux và
System.currentTimeMillis() trong Java trả về số giây (hoặc mili giây) kể từ
epoch: nửa đêm UTC vào ngày 1 tháng 1 năm 1970, theo lịch Gregorian, không tính giây nhuận.
Một số hệ thống sử dụng các ngày khác làm điểm tham chiếu.
(Mặc dù đồng hồ Linux được gọi là real-time, nó không liên quan gì đến các hệ điều hành real-time,
như được thảo luận trong “Đảm bảo thời gian phản hồi”.)
Đồng hồ thực tế thường được đồng bộ hóa với NTP, có nghĩa là dấu thời gian từ một máy (lý tưởng) có nghĩa giống với dấu thời gian trên một máy khác. Tuy nhiên, đồng hồ thực tế cũng có nhiều điểm kỳ lạ, như được mô tả trong phần tiếp theo. Đặc biệt, nếu đồng hồ cục bộ chạy quá nhanh hơn so với máy chủ NTP, nó có thể bị đặt lại bắt buộc và có vẻ như nhảy lùi về một điểm trước đó trong thời gian. Những cú nhảy này, cũng như các cú nhảy tương tự do giây nhuận (leap seconds), làm cho đồng hồ thực tế không phù hợp để đo thời gian đã trôi qua 40.
Đồng hồ thực tế có thể trải qua các cú nhảy do bắt đầu và kết thúc của Giờ Tiết kiệm Ánh sáng ban ngày (Daylight Saving Time, DST); những điều này có thể được tránh bằng cách luôn sử dụng UTC làm múi giờ, vì UTC không có DST. Đồng hồ thực tế cũng có độ phân giải thô khá thô trong lịch sử, ví dụ: tiến theo các bước 10 ms trên các hệ thống Windows cũ hơn 41. Trên các hệ thống gần đây, đây là vấn đề ít hơn.
Đồng hồ đơn điệu
Đồng hồ đơn điệu (monotonic clock) phù hợp để đo thời lượng (khoảng thời gian), chẳng hạn như thời gian chờ hoặc
thời gian phản hồi của một dịch vụ: clock_gettime(CLOCK_MONOTONIC) hoặc clock_gettime(CLOCK_BOOTTIME) trên Linux 42
và System.nanoTime() trong Java là các đồng hồ đơn điệu, ví dụ. Tên gọi bắt nguồn từ thực tế là
chúng được đảm bảo luôn tiến về phía trước (trong khi đồng hồ thực tế có thể nhảy ngược lại trong thời gian).
Bạn có thể kiểm tra giá trị của đồng hồ đơn điệu tại một thời điểm, làm gì đó, và sau đó kiểm tra đồng hồ lại vào một thời điểm sau. Chênh lệch giữa hai giá trị cho bạn biết đã trôi qua bao nhiêu thời gian giữa hai lần kiểm tra, giống như đồng hồ bấm giờ hơn là đồng hồ tường. Tuy nhiên, giá trị tuyệt đối của đồng hồ không có ý nghĩa: nó có thể là số nano giây kể từ khi máy tính được khởi động, hoặc điều gì đó tùy tiện tương tự. Đặc biệt, không có ý nghĩa gì khi so sánh các giá trị đồng hồ đơn điệu từ hai máy tính khác nhau, vì chúng không có nghĩa giống nhau.
Trên máy chủ có nhiều socket CPU, có thể có một bộ đếm thời gian riêng cho mỗi CPU, không nhất thiết được đồng bộ hóa với các CPU khác 43. Hệ điều hành bù đắp cho bất kỳ sự sai lệch nào và cố gắng trình bày một cái nhìn đơn điệu của đồng hồ cho các luồng ứng dụng, ngay cả khi chúng được lên lịch qua các CPU khác nhau. Tuy nhiên, sẽ khôn ngoan khi coi đảm bảo về tính đơn điệu này với một chút hoài nghi 44.
NTP có thể điều chỉnh tần số mà đồng hồ đơn điệu tiến về phía trước (điều này được gọi là slewing đồng hồ) nếu nó phát hiện ra rằng thạch anh cục bộ của máy tính đang chạy nhanh hơn hoặc chậm hơn so với máy chủ NTP. Theo mặc định, NTP cho phép tốc độ đồng hồ được tăng tốc hoặc chậm lại tới 0,05%, nhưng NTP không thể làm cho đồng hồ đơn điệu nhảy về phía trước hay phía sau. Độ phân giải của đồng hồ đơn điệu thường khá tốt: trên hầu hết các hệ thống, chúng có thể đo khoảng thời gian tính bằng micro giây hoặc ngắn hơn.
Trong hệ thống phân tán, sử dụng đồng hồ đơn điệu để đo thời gian đã trôi qua (ví dụ: thời gian chờ) là thường ổn, vì nó không giả định bất kỳ sự đồng bộ hóa nào giữa các đồng hồ của các nút khác nhau và không nhạy cảm với các sai lệch nhỏ trong phép đo.
Đồng Bộ Hóa và Độ Chính Xác của Đồng Hồ
Đồng hồ đơn điệu không cần đồng bộ hóa, nhưng đồng hồ thực tế cần được đặt theo một máy chủ NTP hoặc nguồn thời gian bên ngoài khác để có thể sử dụng. Thật không may, các phương pháp của chúng ta để làm cho đồng hồ cho biết thời gian chính xác không đáng tin cậy hoặc chính xác như bạn có thể hy vọng, đồng hồ phần cứng và NTP có thể là những sinh vật hay thay đổi. Để đưa ra một vài ví dụ:
- Đồng hồ thạch anh trong máy tính không rất chính xác: nó trôi dạt (drift) (chạy nhanh hơn hoặc chậm hơn so với mức cần thiết). Độ trôi dạt của đồng hồ thay đổi tùy thuộc vào nhiệt độ của máy. Google giả định độ trôi dạt đồng hồ tới 200 ppm (phần triệu) cho các máy chủ của mình 45, tương đương với 6 ms trôi dạt cho một đồng hồ được đồng bộ hóa lại với máy chủ mỗi 30 giây, hoặc 17 giây trôi dạt cho một đồng hồ được đồng bộ hóa lại mỗi ngày một lần. Độ trôi dạt này giới hạn độ chính xác tốt nhất có thể đạt được, ngay cả khi mọi thứ hoạt động chính xác.
- Nếu đồng hồ của máy tính khác quá nhiều so với máy chủ NTP, nó có thể từ chối đồng bộ hóa, hoặc đồng hồ cục bộ sẽ bị đặt lại bắt buộc 39. Bất kỳ ứng dụng nào quan sát thời gian trước và sau khi đặt lại này có thể thấy thời gian đi ngược lại hoặc đột ngột nhảy về phía trước.
- Nếu một nút vô tình bị tường lửa chặn khỏi các máy chủ NTP, cấu hình sai này có thể không được chú ý trong một thời gian, trong thời gian đó độ trôi dạt có thể tích lũy thành các sai lệch lớn giữa các đồng hồ của các nút khác nhau. Bằng chứng giai thoại cho thấy điều này thực sự xảy ra trong thực tế.
- Đồng bộ hóa NTP chỉ có thể tốt bằng độ trễ mạng, vì vậy có giới hạn về độ chính xác của nó khi bạn đang sử dụng mạng tắc nghẽn với độ trễ gói tin biến đổi. Một thí nghiệm cho thấy lỗi tối thiểu 35 ms có thể đạt được khi đồng bộ hóa qua internet 46, mặc dù các đợt tăng đột biến thỉnh thoảng về độ trễ mạng dẫn đến các lỗi khoảng một giây. Tùy thuộc vào cấu hình, các độ trễ mạng lớn có thể khiến máy khách NTP từ bỏ hoàn toàn.
- Một số máy chủ NTP bị sai hoặc cấu hình sai, báo cáo thời gian chênh lệch nhiều giờ 47 48. Các máy khách NTP giảm thiểu các lỗi như vậy bằng cách truy vấn nhiều máy chủ và bỏ qua các giá trị ngoại lệ. Tuy nhiên, khá đáng lo ngại khi đặt cược tính đúng đắn của các hệ thống vào thời gian bạn được thông báo bởi một người lạ trên internet.
- Giây nhuận (leap second) dẫn đến một phút có 59 giây hoặc 61 giây, làm rối các giả định về thời gian trong các hệ thống không được thiết kế với giây nhuận 49. Thực tế là giây nhuận đã làm sập nhiều hệ thống lớn 40 50 cho thấy dễ dàng đến mức nào để các giả định sai về đồng hồ lọt vào hệ thống. Cách tốt nhất để xử lý giây nhuận có thể là làm cho các máy chủ NTP “nói dối”, bằng cách thực hiện điều chỉnh giây nhuận dần dần trong suốt một ngày (điều này được gọi là smearing) 51 52, mặc dù hành vi máy chủ NTP thực tế khác nhau trong thực tế 53. Giây nhuận sẽ không còn được sử dụng từ năm 2035 trở đi, vì vậy may mắn là vấn đề này sẽ biến mất.
- Trong các máy ảo, đồng hồ phần cứng được ảo hóa, điều này đặt ra những thách thức bổ sung cho các ứng dụng cần giữ thời gian chính xác 54. Khi một lõi CPU được chia sẻ giữa các máy ảo, mỗi VM bị tạm dừng trong hàng chục mili giây trong khi một VM khác đang chạy. Từ góc độ của ứng dụng, sự tạm dừng này biểu hiện như đồng hồ đột ngột nhảy về phía trước 29. Nếu một VM tạm dừng trong vài giây, đồng hồ có thể chậm hơn thời gian thực tế vài giây, nhưng NTP có thể tiếp tục báo cáo rằng đồng hồ gần như hoàn toàn đồng bộ 55.
- Nếu bạn chạy phần mềm trên các thiết bị mà bạn không kiểm soát hoàn toàn (ví dụ: thiết bị di động hoặc nhúng), bạn có thể không tin tưởng đồng hồ phần cứng của thiết bị chút nào. Một số người dùng cố tình đặt đồng hồ phần cứng của họ về ngày và giờ không chính xác, ví dụ như để gian lận trong các trò chơi 56. Kết quả là, đồng hồ có thể được đặt về thời gian cách xa trong quá khứ hoặc tương lai.
Có thể đạt được độ chính xác đồng hồ rất tốt nếu bạn quan tâm đến nó đủ để đầu tư các nguồn lực đáng kể. Ví dụ, quy định MiFID II của châu Âu dành cho các tổ chức tài chính yêu cầu tất cả các quỹ giao dịch tần số cao đồng bộ hóa đồng hồ của họ trong vòng 100 micro giây so với UTC, nhằm giúp gỡ lỗi các bất thường thị trường như “flash crashes” và giúp phát hiện thao túng thị trường 57.
Độ chính xác như vậy có thể đạt được với một số phần cứng đặc biệt (bộ thu GPS và/hoặc đồng hồ nguyên tử), Giao thức Thời gian Chính xác (Precision Time Protocol, PTP) và triển khai cùng giám sát cẩn thận 58 59. Chỉ dựa vào GPS có thể rủi ro vì các tín hiệu GPS có thể dễ dàng bị nhiễu. Ở một số địa điểm, điều này xảy ra thường xuyên, ví dụ gần các cơ sở quân sự 60. Một số nhà cung cấp đám mây đã bắt đầu cung cấp đồng bộ hóa đồng hồ độ chính xác cao cho các máy ảo của họ 61. Tuy nhiên, đồng bộ hóa đồng hồ vẫn đòi hỏi nhiều sự cẩn thận. Nếu daemon NTP của bạn bị cấu hình sai, hoặc tường lửa đang chặn lưu lượng NTP, lỗi đồng hồ do trôi dạt có thể nhanh chóng trở nên lớn.
Phụ Thuộc vào Đồng Hồ Đồng Bộ Hóa
Vấn đề với đồng hồ là mặc dù chúng có vẻ đơn giản và dễ sử dụng, nhưng chúng có số lượng bẫy đáng ngạc nhiên: một ngày có thể không có đúng 86.400 giây, đồng hồ thực tế có thể di chuyển ngược lại trong thời gian, và thời gian theo đồng hồ của một nút có thể khá khác so với đồng hồ của một nút khác.
Trước đó trong chương này chúng ta đã thảo luận về các mạng bỏ rơi và trì hoãn các gói tin một cách tùy tiện. Mặc dù mạng hoạt động tốt hầu hết thời gian, phần mềm phải được thiết kế trên giả định rằng mạng đôi khi sẽ bị lỗi, và phần mềm phải xử lý các lỗi đó một cách thuận tiện. Điều tương tự cũng đúng với đồng hồ: mặc dù chúng hoạt động khá tốt hầu hết thời gian, phần mềm mạnh mẽ cần phải chuẩn bị để đối phó với các đồng hồ không chính xác.
Một phần của vấn đề là các đồng hồ không chính xác dễ dàng không được chú ý. Nếu CPU của máy bị lỗi hoặc mạng của nó bị cấu hình sai, rất có khả năng nó sẽ hoàn toàn không hoạt động, vì vậy nó sẽ nhanh chóng được chú ý và sửa chữa. Mặt khác, nếu đồng hồ thạch anh của nó bị lỗi hoặc máy khách NTP của nó bị cấu hình sai, hầu hết mọi thứ có vẻ hoạt động tốt, mặc dù đồng hồ của nó dần dần trôi dạt ngày càng xa khỏi thực tế. Nếu một phần phần mềm nào đó đang phụ thuộc vào một đồng hồ được đồng bộ hóa chính xác, kết quả là nhiều khả năng là mất dữ liệu âm thầm và tinh tế hơn là sự cố thảm khốc 62 63.
Do đó, nếu bạn sử dụng phần mềm yêu cầu đồng hồ được đồng bộ hóa, điều cần thiết là bạn cũng phải cẩn thận giám sát các độ lệch đồng hồ giữa tất cả các máy. Bất kỳ nút nào có đồng hồ trôi dạt quá xa so với các nút khác nên được khai báo là chết và bị xóa khỏi cụm. Giám sát như vậy đảm bảo rằng bạn chú ý đến các đồng hồ bị hỏng trước khi chúng có thể gây ra quá nhiều thiệt hại.
Dấu thời gian để sắp xếp các sự kiện
Hãy xem xét một tình huống cụ thể trong đó việc dựa vào đồng hồ rất hấp dẫn, nhưng nguy hiểm: sắp xếp các sự kiện trên nhiều nút 64. Ví dụ, nếu hai máy khách ghi vào cơ sở dữ liệu phân tán, ai đến trước? Ghi nào là gần đây hơn?
Hình 9-3 minh họa việc sử dụng nguy hiểm của đồng hồ thực tế trong cơ sở dữ liệu với sao chép nhiều leader (ví dụ tương tự như Hình 6-8). Máy khách A ghi x = 1 trên nút 1; việc ghi được sao chép đến nút 3; máy khách B tăng x trên nút 3 (bây giờ chúng ta có x = 2); và cuối cùng, cả hai lần ghi được sao chép đến nút 2.
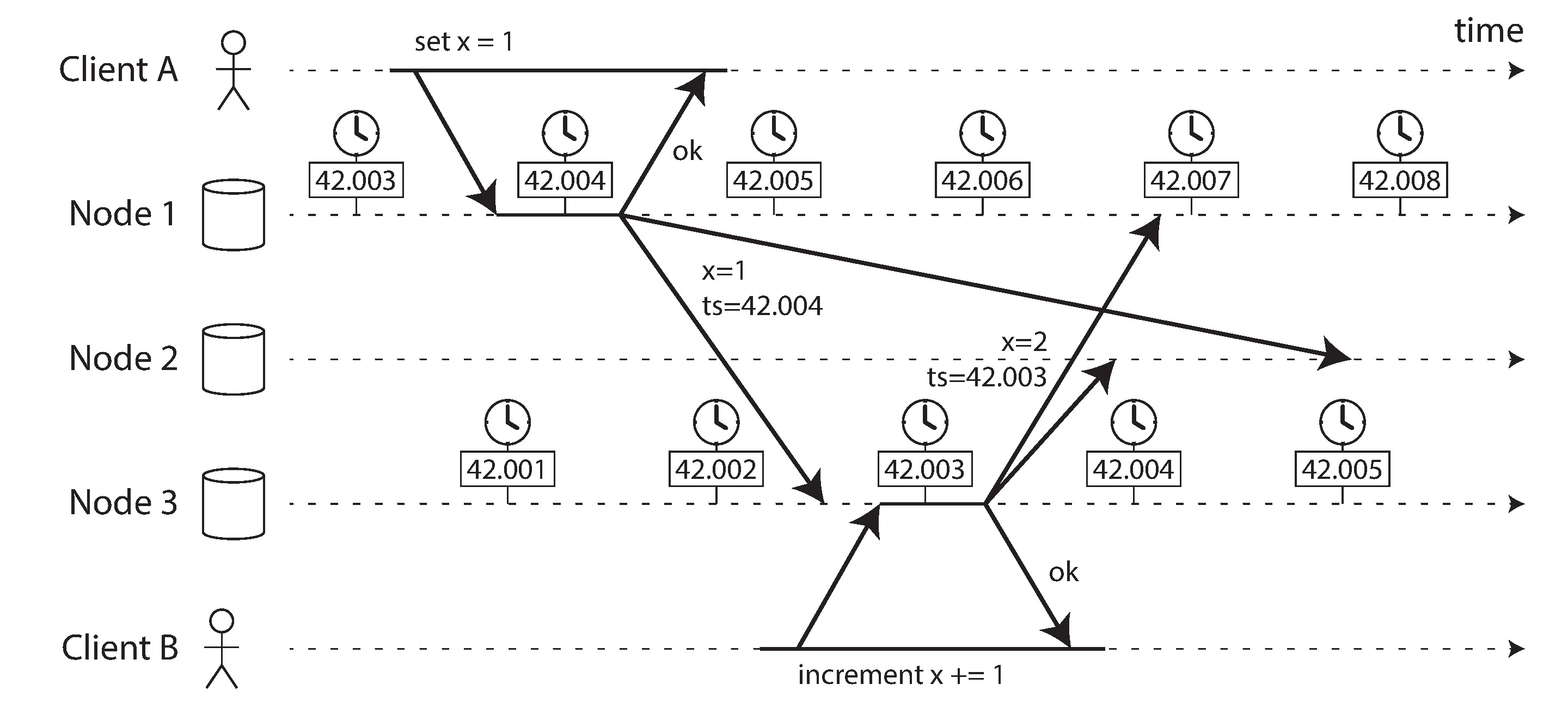
Trong Hình 9-3, khi một lần ghi được sao chép đến các nút khác, nó được gắn thẻ với một dấu thời gian theo đồng hồ thực tế trên nút nơi lần ghi bắt nguồn. Đồng bộ hóa đồng hồ rất tốt trong ví dụ này: độ lệch giữa nút 1 và nút 3 nhỏ hơn 3 ms, có lẽ tốt hơn những gì bạn có thể mong đợi trong thực tế.
Vì lần tăng xây dựng dựa trên lần ghi trước đó của x = 1, chúng ta có thể mong đợi rằng lần ghi x = 2 sẽ có dấu thời gian lớn hơn trong hai lần. Thật không may, đó không phải là điều xảy ra trong Hình 9-3: lần ghi x = 1 có dấu thời gian là 42,004 giây, nhưng lần ghi x = 2 có dấu thời gian là 42,003 giây.
Như đã thảo luận trong “Lần ghi cuối cùng thắng (loại bỏ các ghi đồng thời)”, một cách giải quyết xung đột giữa các giá trị được ghi đồng thời trên các nút khác nhau là last write wins (LWW, lần ghi cuối cùng thắng), có nghĩa là giữ lần ghi với dấu thời gian lớn nhất cho một khóa nhất định và loại bỏ tất cả các lần ghi với dấu thời gian cũ hơn. Trong ví dụ của Hình 9-3, khi nút 2 nhận được hai sự kiện này, nó sẽ không chính xác kết luận rằng x = 1 là giá trị gần đây hơn và bỏ lần ghi x = 2, vì vậy lần tăng bị mất.
Vấn đề này có thể được ngăn chặn bằng cách đảm bảo rằng khi một giá trị bị ghi đè, giá trị mới luôn có dấu thời gian cao hơn giá trị bị ghi đè, ngay cả khi dấu thời gian đó vượt trước đồng hồ cục bộ của người ghi. Tuy nhiên, điều đó phát sinh chi phí của việc đọc thêm để tìm dấu thời gian hiện có lớn nhất. Một số hệ thống, bao gồm Cassandra và ScyllaDB, muốn ghi vào tất cả các bản sao trong một vòng chuyến đi, và do đó họ chỉ đơn giản là sử dụng dấu thời gian của đồng hồ máy khách cùng với chính sách last write wins 62. Cách tiếp cận này có một số vấn đề nghiêm trọng:
- Các ghi cơ sở dữ liệu có thể biến mất một cách bí ẩn: một nút có đồng hồ chậm không thể ghi đè các giá trị trước đó được ghi bởi một nút có đồng hồ nhanh cho đến khi độ lệch đồng hồ giữa các nút đã trôi qua 63 65. Tình huống này có thể khiến lượng dữ liệu tùy ý bị bỏ âm thầm mà không có bất kỳ lỗi nào được báo cáo cho ứng dụng.
- LWW không thể phân biệt giữa các lần ghi xảy ra tuần tự liên tiếp nhanh chóng (trong Hình 9-3, lần tăng của máy khách B chắc chắn xảy ra sau lần ghi của máy khách A) và các lần ghi thực sự đồng thời (cả hai người ghi đều không biết về nhau). Các cơ chế theo dõi nhân quả bổ sung, chẳng hạn như vector phiên bản (version vectors), là cần thiết để ngăn ngừa các vi phạm về nhân quả (xem “Phát hiện các ghi đồng thời”).
- Có thể hai nút độc lập tạo ra các lần ghi với cùng dấu thời gian, đặc biệt khi đồng hồ chỉ có độ phân giải mili giây. Một giá trị phân xử bổ sung (có thể đơn giản là một số ngẫu nhiên lớn) là cần thiết để giải quyết các xung đột như vậy, nhưng cách tiếp cận này cũng có thể dẫn đến các vi phạm về nhân quả 62.
Do đó, mặc dù thật hấp dẫn khi giải quyết xung đột bằng cách giữ giá trị “gần đây” nhất và loại bỏ các giá trị khác, điều quan trọng là phải nhận thức rằng định nghĩa về “gần đây” phụ thuộc vào đồng hồ thực tế cục bộ, điều đó có thể sai. Ngay cả với các đồng hồ được đồng bộ hóa chặt chẽ bởi NTP, bạn có thể gửi một gói tin lúc dấu thời gian 100 ms (theo đồng hồ của người gửi) và có nó đến lúc dấu thời gian 99 ms (theo đồng hồ của người nhận), vì vậy có vẻ như gói tin đến trước khi nó được gửi, điều đó là không thể.
Liệu đồng bộ hóa NTP có thể được thực hiện đủ chính xác để các thứ tự sai như vậy không thể xảy ra không? Có lẽ không, vì độ chính xác đồng bộ hóa của NTP bản thân bị giới hạn bởi thời gian khứ hồi mạng, ngoài ra các nguồn lỗi khác như trôi dạt thạch anh. Để đảm bảo thứ tự chính xác, bạn cần lỗi đồng hồ thấp hơn đáng kể so với độ trễ mạng, điều này không thể thực hiện được.
Cái gọi là đồng hồ logic (logical clocks) 66, dựa trên các bộ đếm tăng dần thay vì tinh thể thạch anh dao động, là một giải pháp thay thế an toàn hơn để sắp xếp các sự kiện (xem “Phát hiện các ghi đồng thời”). Đồng hồ logic không đo thời gian trong ngày hay số giây đã trôi qua, chỉ đo thứ tự tương đối của các sự kiện (liệu một sự kiện xảy ra trước hay sau một sự kiện khác). Ngược lại, đồng hồ thực tế và đồng hồ đơn điệu, đo thời gian thực tế đã trôi qua, cũng được gọi là đồng hồ vật lý (physical clocks). Chúng ta sẽ xem xét đồng hồ logic trong chi tiết hơn trong “Bộ tạo ID và Đồng hồ Logic”.
Các lần đọc đồng hồ với khoảng tin cậy
Bạn có thể đọc đồng hồ thực tế của máy với độ phân giải micro giây hoặc thậm chí nano giây. Nhưng ngay cả khi bạn có thể có được phép đo chi tiết như vậy, điều đó không có nghĩa là giá trị là thực sự chính xác đến độ chính xác như vậy. Trên thực tế, rất có thể là không, như đã đề cập trước đó, độ trôi dạt trong một đồng hồ thạch anh không chính xác có thể dễ dàng là vài mili giây, ngay cả khi bạn đồng bộ hóa với một máy chủ NTP trên mạng cục bộ mỗi phút. Với máy chủ NTP trên internet công cộng, độ chính xác tốt nhất có thể là hàng chục mili giây, và lỗi có thể dễ dàng tăng đột biến lên hơn 100 ms khi có tắc nghẽn mạng.
Do đó, không có ý nghĩa khi nghĩ về một lần đọc đồng hồ như một điểm trong thời gian, mà là như một phạm vi thời gian, trong một khoảng tin cậy: ví dụ, một hệ thống có thể tự tin 95% rằng thời gian hiện tại nằm trong khoảng từ 10,3 đến 10,5 giây sau phút, nhưng nó không biết chính xác hơn thế 67. Nếu chúng ta chỉ biết thời gian +/- 100 ms, các chữ số micro giây trong dấu thời gian về cơ bản là vô nghĩa.
Giới hạn không chắc chắn có thể được tính toán dựa trên nguồn thời gian của bạn. Nếu bạn có bộ thu GPS hoặc đồng hồ nguyên tử được gắn trực tiếp vào máy tính của bạn, phạm vi lỗi dự kiến được xác định bởi thiết bị và, trong trường hợp GPS, bởi chất lượng tín hiệu từ các vệ tinh. Nếu bạn đang lấy thời gian từ một máy chủ, sự không chắc chắn dựa trên độ trôi dạt thạch anh dự kiến kể từ lần đồng bộ hóa cuối cùng với máy chủ, cộng với sự không chắc chắn của máy chủ NTP, cộng với thời gian khứ hồi mạng đến máy chủ (xấp xỉ đầu tiên, và giả sử bạn tin tưởng máy chủ).
Thật không may, hầu hết các hệ thống không để lộ sự không chắc chắn này: ví dụ, khi bạn gọi
clock_gettime(), giá trị trả về không cho bạn biết lỗi dự kiến của dấu thời gian, vì vậy bạn
không biết liệu khoảng tin cậy của nó là năm mili giây hay năm năm.
Có các ngoại lệ: API TrueTime trong Google’s Spanner 45 và Amazon’s ClockBound rõ ràng báo cáo
khoảng tin cậy trên đồng hồ cục bộ. Khi bạn yêu cầu thời gian hiện tại, bạn nhận được hai
giá trị: [earliest, latest], đây là dấu thời gian sớm nhất có thể và muộn nhất có thể.
Dựa trên các tính toán không chắc chắn của mình, đồng hồ biết rằng thời gian hiện tại thực tế nằm trong
khoảng đó. Độ rộng của khoảng phụ thuộc, trong số những thứ khác, vào thời gian kể từ khi đồng hồ thạch anh cục bộ được
đồng bộ hóa lần cuối với nguồn đồng hồ chính xác hơn.
Đồng hồ đồng bộ hóa cho các snapshot toàn cục
Trong “Cô lập Snapshot và Đọc Lặp lại” chúng ta đã thảo luận về kiểm soát đồng thời đa phiên bản (multi-version concurrency control, MVCC), đây là một tính năng rất hữu ích trong các cơ sở dữ liệu cần hỗ trợ cả các giao dịch đọc-ghi nhỏ, nhanh và các giao dịch chỉ đọc lớn, chạy lâu dài (ví dụ: cho sao lưu hoặc phân tích). Nó cho phép các giao dịch chỉ đọc thấy một snapshot của cơ sở dữ liệu, một trạng thái nhất quán tại một thời điểm cụ thể, mà không khóa và can thiệp vào các giao dịch đọc-ghi.
Thông thường, MVCC yêu cầu ID giao dịch tăng đơn điệu. Nếu một lần ghi xảy ra sau snapshot (tức là lần ghi có ID giao dịch lớn hơn snapshot), lần ghi đó là vô hình đối với giao dịch snapshot. Trên một cơ sở dữ liệu đơn nút, một bộ đếm đơn giản là đủ để tạo ID giao dịch.
Tuy nhiên, khi một cơ sở dữ liệu được phân tán trên nhiều máy, có thể trên nhiều trung tâm dữ liệu, một ID giao dịch toàn cục tăng đơn điệu (qua tất cả các shard) khó tạo, vì nó yêu cầu điều phối. ID giao dịch phải phản ánh nhân quả: nếu giao dịch B đọc hoặc ghi đè một giá trị trước đó được ghi bởi giao dịch A, thì B phải có ID giao dịch cao hơn A, nếu không, snapshot sẽ không nhất quán. Với nhiều giao dịch nhỏ, nhanh, việc tạo ID giao dịch trong hệ thống phân tán trở thành một điểm tắc nghẽn không thể chấp nhận. (Chúng ta sẽ thảo luận về các bộ tạo ID như vậy trong “Bộ tạo ID và Đồng hồ Logic”.)
Chúng ta có thể sử dụng các dấu thời gian từ các đồng hồ thực tế được đồng bộ hóa làm ID giao dịch không? Nếu chúng ta có thể thực hiện đồng bộ hóa đủ tốt, chúng sẽ có các thuộc tính đúng: các giao dịch sau có dấu thời gian cao hơn. Vấn đề, tất nhiên, là sự không chắc chắn về độ chính xác của đồng hồ.
Spanner triển khai cô lập snapshot qua các trung tâm dữ liệu theo cách này 68 69. Nó sử dụng khoảng tin cậy của đồng hồ được báo cáo bởi API TrueTime, và dựa trên quan sát sau: nếu bạn có hai khoảng tin cậy, mỗi khoảng bao gồm dấu thời gian sớm nhất và muộn nhất có thể (A = [Aearliest, Alatest] và B = [Bearliest, Blatest]), và hai khoảng đó không chồng lên nhau (tức là Aearliest < Alatest < Bearliest < Blatest), thì B chắc chắn xảy ra sau A, không thể có sự nghi ngờ. Chỉ khi các khoảng chồng lên nhau thì chúng ta mới không chắc chắn về thứ tự xảy ra của A và B.
Để đảm bảo các dấu thời gian giao dịch phản ánh nhân quả, Spanner cố ý đợi trong khoảng thời gian bằng khoảng tin cậy trước khi cam kết một giao dịch đọc-ghi. Bằng cách làm vậy, nó đảm bảo rằng bất kỳ giao dịch nào có thể đọc dữ liệu đều ở một thời điểm đủ sau, vì vậy các khoảng tin cậy của chúng không chồng lên nhau. Để giữ thời gian chờ càng ngắn càng tốt, Spanner cần giữ sự không chắc chắn của đồng hồ càng nhỏ càng tốt; với mục đích này, Google triển khai một bộ thu GPS hoặc đồng hồ nguyên tử trong mỗi trung tâm dữ liệu, cho phép các đồng hồ được đồng bộ hóa trong khoảng 7 ms 45.
Các đồng hồ nguyên tử và bộ thu GPS không nhất thiết cần thiết trong Spanner: điều quan trọng là có một khoảng tin cậy, và các nguồn đồng hồ chính xác chỉ giúp giữ khoảng đó nhỏ. Các hệ thống khác đang bắt đầu áp dụng các cách tiếp cận tương tự: ví dụ, YugabyteDB có thể tận dụng ClockBound khi chạy trên AWS 70, và một số hệ thống khác cũng dựa vào đồng bộ hóa đồng hồ ở các mức độ khác nhau 71 72.
Tạm Dừng Tiến Trình
Hãy xem xét một ví dụ khác về việc sử dụng đồng hồ nguy hiểm trong hệ thống phân tán. Giả sử bạn có một cơ sở dữ liệu với một leader duy nhất cho mỗi shard. Chỉ leader được phép chấp nhận ghi. Làm thế nào để một nút biết rằng nó vẫn là leader (rằng nó chưa bị các nút khác khai báo là chết), và rằng nó có thể chấp nhận ghi một cách an toàn?
Một tùy chọn là để leader lấy một lease (hợp đồng thuê) từ các nút khác, tương tự như một khóa với thời gian chờ 73. Chỉ một nút có thể giữ lease tại bất kỳ thời điểm nào, vì vậy khi một nút lấy được lease, nó biết rằng nó là leader trong một khoảng thời gian, cho đến khi lease hết hạn. Để duy trì là leader, nút phải định kỳ gia hạn lease trước khi nó hết hạn. Nếu nút bị hỏng, nó dừng gia hạn lease, vì vậy một nút khác có thể tiếp quản khi nó hết hạn.
Bạn có thể tưởng tượng vòng lặp xử lý yêu cầu trông giống như sau:
while (true) {
request = getIncomingRequest();
// Ensure that the lease always has at least 10 seconds remaining
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) {
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}Điều gì sai với đoạn code này? Đầu tiên, nó đang phụ thuộc vào các đồng hồ được đồng bộ hóa: thời gian hết hạn trên lease được đặt bởi một máy khác (nơi thời gian hết hạn có thể được tính là thời gian hiện tại cộng thêm 30 giây, ví dụ), và nó đang được so sánh với đồng hồ hệ thống cục bộ. Nếu các đồng hồ lệch nhau hơn một vài giây, code này sẽ bắt đầu làm những điều kỳ lạ.
Thứ hai, ngay cả khi chúng ta thay đổi giao thức để chỉ sử dụng đồng hồ đơn điệu cục bộ, có một vấn đề khác:
code giả định rằng rất ít thời gian trôi qua giữa điểm kiểm tra thời gian
(System.currentTimeMillis()) và thời điểm yêu cầu được xử lý (process(request)).
Thông thường code này chạy rất nhanh, vì vậy bộ đệm 10 giây là quá đủ để đảm bảo rằng
lease không hết hạn trong quá trình xử lý một yêu cầu.
Tuy nhiên, nếu có một sự dừng đột ngột trong quá trình thực thi chương trình thì sao? Ví dụ, hãy tưởng tượng
luồng dừng 15 giây quanh dòng lease.isValid() trước khi cuối cùng tiếp tục. Trong
trường hợp đó, có khả năng lease sẽ đã hết hạn vào thời điểm yêu cầu được xử lý, và
một nút khác đã tiếp quản là leader. Tuy nhiên, không có gì để nói với luồng này rằng nó
bị tạm dừng trong thời gian dài như vậy, vì vậy code này sẽ không nhận thấy rằng lease đã hết hạn cho đến lần lặp tiếp theo
của vòng lặp, vào lúc đó nó có thể đã làm điều gì đó không an toàn bằng cách xử lý
yêu cầu.
Liệu có hợp lý khi giả định rằng một luồng có thể bị tạm dừng trong thời gian lâu như vậy không? Thật không may là có. Có nhiều lý do tại sao điều này có thể xảy ra:
- Sự tranh chấp giữa các luồng truy cập một tài nguyên chia sẻ, chẳng hạn như khóa hoặc hàng đợi, có thể khiến các luồng dành nhiều thời gian để chờ đợi. Chuyển sang máy có nhiều lõi CPU hơn có thể làm cho các vấn đề như vậy tệ hơn, và các vấn đề tranh chấp có thể khó chẩn đoán 74.
- Nhiều runtime ngôn ngữ lập trình (chẳng hạn như Java Virtual Machine) có garbage collector (GC, bộ thu gom rác) đôi khi cần dừng tất cả các luồng đang chạy. Trong quá khứ, các “stop-the-world” GC pauses (tạm dừng GC dừng-thế-giới) đôi khi kéo dài vài phút 75! Với các thuật toán GC hiện đại, điều này là vấn đề ít hơn, nhưng các tạm dừng GC vẫn có thể đáng chú ý (xem “Giới hạn tác động của garbage collection”).
- Trong các môi trường ảo hóa, một máy ảo có thể bị tạm dừng (paused, dừng thực thi tất cả các tiến trình và lưu nội dung bộ nhớ vào đĩa) và tiếp tục (resumed, khôi phục nội dung bộ nhớ và tiếp tục thực thi). Sự tạm dừng này có thể xảy ra tại bất kỳ thời điểm nào trong quá trình thực thi và có thể kéo dài trong thời gian tùy ý. Tính năng này đôi khi được sử dụng để di chuyển trực tiếp (live migration) của các máy ảo từ máy chủ này sang máy chủ khác mà không cần khởi động lại, trong trường hợp đó độ dài của sự tạm dừng phụ thuộc vào tốc độ các tiến trình đang ghi vào bộ nhớ 76.
- Trên các thiết bị người dùng cuối như laptop và điện thoại, quá trình thực thi cũng có thể bị tạm dừng và tiếp tục một cách tùy tiện, ví dụ: khi người dùng đóng nắp laptop.
- Khi hệ điều hành chuyển ngữ cảnh sang một luồng khác, hoặc khi hypervisor chuyển sang một máy ảo khác (khi chạy trong máy ảo), luồng hiện đang chạy có thể bị tạm dừng tại bất kỳ điểm tùy tiện nào trong code. Trong trường hợp máy ảo, thời gian CPU dành cho các máy ảo khác được gọi là steal time (thời gian bị đánh cắp). Nếu máy đang chịu tải nặng, tức là nếu có một hàng đợi dài các luồng đang chờ chạy, có thể mất một khoảng thời gian trước khi luồng bị tạm dừng được chạy lại.
- Nếu ứng dụng thực hiện truy cập đĩa đồng bộ (synchronous disk access), một luồng có thể bị tạm dừng trong khi chờ thao tác I/O đĩa chậm hoàn thành 77. Trong nhiều ngôn ngữ lập trình, việc truy cập đĩa có thể xảy ra bất ngờ, ngay cả khi mã nguồn không đề cập đến việc truy cập tệp một cách tường minh, chẳng hạn như Java classloader tải lazily các tệp class khi chúng được sử dụng lần đầu, điều này có thể xảy ra bất kỳ lúc nào trong quá trình thực thi chương trình. Các lần tạm dừng I/O và GC có thể kết hợp với nhau để nhân đôi độ trễ 78. Nếu đĩa thực ra là một hệ thống tệp mạng (network filesystem) hoặc thiết bị khối mạng (network block device) như Amazon EBS, độ trễ I/O còn phụ thuộc thêm vào sự biến động của độ trễ mạng 31.
- Nếu hệ điều hành được cấu hình cho phép swapping to disk (paging, hoán đổi sang đĩa), một thao tác truy cập bộ nhớ đơn giản có thể gây ra lỗi trang (page fault) cần tải một trang từ đĩa vào bộ nhớ. Luồng bị tạm dừng trong suốt thời gian thao tác I/O chậm này diễn ra. Nếu bộ nhớ đang bị áp lực cao, điều này có thể dẫn đến việc một trang khác bị hoán đổi ra đĩa. Trong những trường hợp cực đoan, hệ điều hành có thể dành phần lớn thời gian của mình để hoán đổi các trang vào và ra bộ nhớ mà hầu như không thực hiện được công việc thực sự nào (hiện tượng này được gọi là thrashing). Để tránh vấn đề này, paging thường được tắt trên các máy chủ (vì tắt tiến trình để giải phóng bộ nhớ vẫn tốt hơn là để thrashing xảy ra).
- Một tiến trình Unix có thể bị tạm dừng bằng cách gửi tín hiệu
SIGSTOPcho nó, ví dụ như nhấn Ctrl-Z trong shell. Tín hiệu này ngay lập tức ngăn tiến trình nhận thêm bất kỳ chu kỳ CPU nào cho đến khi nó được tiếp tục vớiSIGCONT, lúc đó nó tiếp tục chạy từ nơi bị dừng lại. Ngay cả khi môi trường của bạn thường không sử dụngSIGSTOP, nó vẫn có thể được gửi nhầm bởi một kỹ sư vận hành.
Tất cả những sự kiện này đều có thể preempt (chiếm quyền kiểm soát) luồng đang chạy tại bất kỳ thời điểm nào và tiếp tục nó vào một thời điểm sau, mà luồng không hề hay biết. Vấn đề này tương tự như việc làm cho mã đa luồng (multi-threaded code) trên một máy đơn trở nên thread-safe: bạn không thể giả định bất cứ điều gì về thời gian, bởi vì việc chuyển ngữ cảnh (context switches) tùy ý và song song hóa có thể xảy ra bất kỳ lúc nào.
Khi viết mã đa luồng trên một máy đơn, chúng ta có những công cụ khá tốt để đảm bảo thread-safe: mutex, semaphore, atomic counter, cấu trúc dữ liệu lock-free, blocking queue, v.v. Thật không may, những công cụ này không thể áp dụng trực tiếp cho các hệ thống phân tán (distributed systems), bởi vì một hệ thống phân tán không có bộ nhớ dùng chung, mà chỉ có các tin nhắn được gửi qua một mạng không đáng tin cậy.
Một nút trong hệ thống phân tán phải giả định rằng quá trình thực thi của nó có thể bị tạm dừng trong một khoảng thời gian đáng kể tại bất kỳ thời điểm nào, ngay cả ở giữa một hàm. Trong thời gian tạm dừng, phần còn lại của thế giới tiếp tục vận hành và thậm chí có thể tuyên bố nút đang tạm dừng là đã chết vì nó không phản hồi. Cuối cùng, nút đang tạm dừng có thể tiếp tục chạy, thậm chí không nhận ra rằng nó đã “ngủ” cho đến khi kiểm tra đồng hồ của mình vào lúc sau.
Đảm bảo thời gian phản hồi
Trong nhiều ngôn ngữ lập trình và hệ điều hành, các luồng và tiến trình có thể bị tạm dừng trong khoảng thời gian không giới hạn, như đã thảo luận. Những lý do gây ra sự tạm dừng đó có thể được loại bỏ nếu bạn cố gắng đủ mức.
Một số phần mềm chạy trong các môi trường mà việc không phản hồi trong thời gian quy định có thể gây ra thiệt hại nghiêm trọng: các máy tính điều khiển máy bay, tên lửa, robot, ô tô và các vật thể vật lý khác phải phản hồi nhanh và có thể dự đoán được với các đầu vào cảm biến. Trong những hệ thống này, có một deadline (thời hạn) quy định mà phần mềm phải phản hồi; nếu không đáp ứng được thời hạn, điều đó có thể gây ra sự cố toàn bộ hệ thống. Đây được gọi là các hệ thống hard real-time (thời gian thực cứng).
Note
Trong các hệ thống nhúng, real-time (thời gian thực) có nghĩa là hệ thống được thiết kế và kiểm thử cẩn thận để đáp ứng các đảm bảo về thời gian được chỉ định trong mọi hoàn cảnh. Ý nghĩa này trái ngược với cách dùng mơ hồ hơn của thuật ngữ real-time trên web, nơi nó mô tả các máy chủ đẩy dữ liệu đến client và xử lý luồng (stream processing) mà không có ràng buộc thời gian phản hồi cứng (xem Chương 12).
Ví dụ, nếu các cảm biến trên xe của bạn phát hiện rằng bạn đang trải qua một vụ tai nạn, bạn sẽ không muốn việc bung túi khí bị trì hoãn do một lần tạm dừng GC không đúng lúc trong hệ thống bung túi khí.
Cung cấp các đảm bảo thời gian thực trong một hệ thống đòi hỏi sự hỗ trợ từ tất cả các tầng của ngăn xếp phần mềm: cần có một real-time operating system (RTOS, hệ điều hành thời gian thực) cho phép các tiến trình được lên lịch với phân bổ thời gian CPU đảm bảo trong các khoảng thời gian quy định; các hàm thư viện phải ghi lại thời gian thực thi tệ nhất của chúng; phân bổ bộ nhớ động có thể bị hạn chế hoặc hoàn toàn không được phép (garbage collector thời gian thực tồn tại, nhưng ứng dụng vẫn phải đảm bảo rằng nó không giao quá nhiều việc cho GC); và một lượng lớn kiểm thử và đo lường phải được thực hiện để đảm bảo các đảm bảo đang được đáp ứng.
Tất cả những điều này đòi hỏi một lượng công việc bổ sung lớn và hạn chế nghiêm trọng phạm vi ngôn ngữ lập trình, thư viện và công cụ có thể được sử dụng (vì hầu hết các ngôn ngữ và công cụ không cung cấp đảm bảo thời gian thực). Vì những lý do này, việc phát triển các hệ thống thời gian thực rất tốn kém, và chúng thường được sử dụng nhất trong các thiết bị nhúng quan trọng về an toàn. Hơn nữa, “real-time” không giống với “high-performance” (hiệu suất cao): thực tế, các hệ thống thời gian thực có thể có throughput thấp hơn, vì chúng phải ưu tiên phản hồi kịp thời trên tất cả (xem thêm “Latency and Resource Utilization”).
Đối với hầu hết các hệ thống xử lý dữ liệu phía máy chủ, các đảm bảo thời gian thực đơn giản là không khả thi về mặt kinh tế hoặc không phù hợp. Do đó, những hệ thống này phải chịu đựng các lần tạm dừng và sự không ổn định của đồng hồ đến từ việc hoạt động trong môi trường không thời gian thực.
Giới hạn tác động của garbage collection
Garbage collection (thu gom rác) từng là một trong những lý do lớn nhất gây ra tạm dừng tiến trình 79, nhưng may mắn thay, các thuật toán GC đã cải thiện rất nhiều: một bộ thu gom được điều chỉnh đúng cách bây giờ thường chỉ tạm dừng không quá vài mili giây. Java runtime cung cấp các bộ thu gom như concurrent mark sweep (CMS), garbage-first (G1), Z garbage collector (ZGC), Epsilon và Shenandoah. Mỗi cái trong số này được tối ưu hóa cho các hồ sơ bộ nhớ khác nhau như tạo đối tượng tần số cao, heap lớn, v.v. Ngược lại, Go cung cấp một garbage collector concurrent mark sweep đơn giản hơn cố gắng tự tối ưu hóa bản thân.
Nếu bạn cần tránh hoàn toàn các lần tạm dừng GC, một lựa chọn là sử dụng một ngôn ngữ không có garbage collector. Ví dụ, Swift sử dụng automatic reference counting (đếm tham chiếu tự động) để xác định khi nào bộ nhớ có thể được giải phóng; Rust và Mojo theo dõi vòng đời của các đối tượng bằng hệ thống kiểu (type system) để compiler có thể xác định bộ nhớ cần được phân bổ trong bao lâu.
Cũng có thể sử dụng ngôn ngữ có garbage collector trong khi giảm thiểu tác động của các lần tạm dừng. Một cách tiếp cận là coi các lần tạm dừng GC như các sự cố ngắn theo kế hoạch của một nút, và để các nút khác xử lý các yêu cầu từ client trong khi một nút đang thu gom rác. Nếu runtime có thể cảnh báo ứng dụng rằng một nút sắp cần tạm dừng GC, ứng dụng có thể ngừng gửi yêu cầu mới đến nút đó, chờ nó hoàn thành các yêu cầu đang chờ xử lý, và sau đó thực hiện GC trong khi không có yêu cầu nào đang tiến hành. Thủ thuật này ẩn các lần tạm dừng GC khỏi client và giảm các phần trăm cao của thời gian phản hồi 80 81.
Một biến thể của ý tưởng này là chỉ sử dụng garbage collector cho các đối tượng tồn tại ngắn (vốn thu gom nhanh) và khởi động lại các tiến trình định kỳ, trước khi chúng tích lũy đủ đối tượng tồn tại lâu để yêu cầu GC đầy đủ của các đối tượng tồn tại lâu 79 82. Mỗi lần chỉ khởi động lại một nút, và lưu lượng có thể được chuyển khỏi nút đó trước khi khởi động lại theo kế hoạch, giống như trong quá trình nâng cấp cuốn chiếu (rolling upgrade) (xem Chương 5).
Những biện pháp này không thể ngăn chặn hoàn toàn các lần tạm dừng garbage collection, nhưng chúng có thể giảm hữu ích tác động của chúng lên ứng dụng.
Kiến Thức, Sự Thật và Sự Dối Trá
Cho đến nay trong chương này, chúng ta đã khám phá những cách mà các hệ thống phân tán khác với các chương trình chạy trên một máy tính đơn: không có bộ nhớ dùng chung, chỉ có truyền thông điệp (message passing) qua mạng không đáng tin cậy với độ trễ biến đổi, và các hệ thống có thể gặp phải các lỗi từng phần (partial failures), đồng hồ không đáng tin cậy và các lần tạm dừng xử lý.
Hậu quả của những vấn đề này rất mất phương hướng nếu bạn chưa quen với các hệ thống phân tán. Một nút trong mạng không thể biết chắc chắn bất cứ điều gì về các nút khác, nó chỉ có thể đưa ra các phỏng đoán dựa trên các tin nhắn nó nhận được (hoặc không nhận được). Một nút chỉ có thể biết trạng thái của một nút từ xa là gì (nó đã lưu trữ dữ liệu gì, liệu nó có hoạt động đúng không, v.v.) bằng cách trao đổi tin nhắn với nó. Nếu một nút từ xa không phản hồi, không có cách nào để biết trạng thái của nó là gì, bởi vì các vấn đề trong mạng không thể phân biệt đáng tin cậy với các vấn đề tại một nút.
Các cuộc thảo luận về những hệ thống này tiếp cận ranh giới triết học: Chúng ta biết gì là đúng hay sai trong hệ thống của mình? Chúng ta có thể chắc chắn đến mức nào về kiến thức đó, nếu các cơ chế nhận thức và đo lường không đáng tin cậy 83? Các hệ thống phần mềm có nên tuân theo các quy luật mà chúng ta mong đợi từ thế giới vật lý, như nhân quả không?
May mắn thay, chúng ta không cần phải đi xa đến mức tìm ra ý nghĩa của cuộc sống. Trong một hệ thống phân tán, chúng ta có thể phát biểu các giả định mà chúng ta đang đưa ra về hành vi (còn gọi là system model, mô hình hệ thống) và thiết kế hệ thống thực tế theo cách đáp ứng những giả định đó. Các thuật toán có thể được chứng minh là hoạt động đúng trong một mô hình hệ thống nhất định. Điều này có nghĩa là hành vi đáng tin cậy là có thể đạt được, ngay cả khi mô hình hệ thống cơ bản cung cấp rất ít đảm bảo.
Tuy nhiên, mặc dù có thể làm cho phần mềm hoạt động tốt trong một mô hình hệ thống không đáng tin cậy, nhưng điều đó không hề đơn giản. Trong phần còn lại của chương này, chúng ta sẽ tiếp tục khám phá các khái niệm về kiến thức và sự thật trong các hệ thống phân tán, điều này sẽ giúp chúng ta suy nghĩ về các loại giả định mà chúng ta có thể đưa ra và các đảm bảo mà chúng ta có thể muốn cung cấp. Trong Chương 10, chúng ta sẽ tiếp tục xem xét một số ví dụ về các thuật toán phân tán cung cấp các đảm bảo cụ thể trong các giả định cụ thể.
Quy Tắc Đa Số
Hãy tưởng tượng một mạng với một lỗi bất đối xứng (asymmetric fault): một nút có thể nhận được tất cả các tin nhắn gửi đến nó, nhưng bất kỳ tin nhắn đi nào từ nút đó đều bị loại bỏ hoặc trì hoãn 22. Mặc dù nút đó đang hoạt động hoàn toàn tốt, và đang nhận yêu cầu từ các nút khác, nhưng các nút khác không thể nghe thấy phản hồi của nó. Sau một thời gian chờ, các nút khác tuyên bố nó đã chết, vì họ không nghe thấy gì từ nút đó. Tình huống diễn ra như một cơn ác mộng: nút nửa bị ngắt kết nối bị kéo đến nghĩa địa, đang đá đạp và kêu la “Tôi không chết!” nhưng vì không ai có thể nghe tiếng kêu của nó, đoàn đưa ma tiếp tục với sự kiên quyết stoic.
Trong một kịch bản ít kinh dị hơn một chút, nút nửa bị ngắt kết nối có thể nhận ra rằng các tin nhắn nó đang gửi không được xác nhận bởi các nút khác, và do đó nhận ra rằng chắc chắn có lỗi trong mạng. Tuy nhiên, nút đó bị các nút khác tuyên bố sai là đã chết, và nút nửa bị ngắt kết nối không thể làm gì về điều đó.
Trong kịch bản thứ ba, hãy tưởng tượng một nút tạm dừng thực thi trong một phút. Trong thời gian đó, không có yêu cầu nào được xử lý và không có phản hồi nào được gửi đi. Các nút khác chờ đợi, thử lại, mất kiên nhẫn và cuối cùng tuyên bố nút đó đã chết và đưa lên xe tang. Cuối cùng, lần tạm dừng kết thúc và các luồng của nút tiếp tục như thể không có gì xảy ra. Các nút khác bị bất ngờ khi nút được cho là đã chết đột nhiên ngẩng đầu ra khỏi quan tài, trong tình trạng hoàn toàn khỏe mạnh, và bắt đầu trò chuyện vui vẻ với những người xung quanh. Lúc đầu, nút đang tạm dừng thậm chí không nhận ra rằng cả một phút đã trôi qua và nó đã bị tuyên bố là đã chết, từ góc độ của nó, hầu như không có thời gian nào trôi qua kể từ khi nó lần cuối trò chuyện với các nút khác.
Bài học từ những câu chuyện này là một nút không nhất thiết có thể tin tưởng vào phán đoán của chính nó về một tình huống. Một hệ thống phân tán không thể phụ thuộc hoàn toàn vào một nút duy nhất, vì một nút có thể bị lỗi bất kỳ lúc nào, có thể khiến hệ thống bị kẹt và không thể phục hồi. Thay vào đó, nhiều thuật toán phân tán dựa vào một quorum (túc số), tức là bỏ phiếu giữa các nút (xem “Quorums for reading and writing”): các quyết định yêu cầu một số lượng phiếu tối thiểu từ nhiều nút để giảm sự phụ thuộc vào bất kỳ nút cụ thể nào.
Điều đó bao gồm cả các quyết định về việc tuyên bố nút đã chết. Nếu một quorum các nút tuyên bố một nút khác đã chết, thì nó phải được coi là đã chết, ngay cả khi nút đó vẫn cảm thấy còn sống. Nút cá nhân phải tuân theo quyết định của quorum và rút lui.
Thông thường nhất, quorum là đa số tuyệt đối của hơn một nửa số nút (mặc dù các loại quorum khác cũng có thể). Quorum đa số cho phép hệ thống tiếp tục hoạt động nếu một thiểu số nút bị lỗi (với ba nút, có thể chịu đựng một nút lỗi; với năm nút, có thể chịu đựng hai nút lỗi). Tuy nhiên, nó vẫn an toàn, vì chỉ có thể có một đa số trong hệ thống, không thể có hai đa số với các quyết định xung đột cùng một lúc. Chúng ta sẽ thảo luận chi tiết hơn về việc sử dụng quorum khi đến phần consensus algorithms (thuật toán đồng thuận) trong Chương 10.
Khóa Phân Tán và Lease
Khóa (locks) và lease trong ứng dụng phân tán dễ bị sử dụng sai và là nguồn gốc phổ biến của các lỗi 84. Hãy xem xét một trường hợp cụ thể về cách chúng có thể bị sai.
Trong “Process Pauses”, chúng ta đã thấy rằng lease là một loại khóa có thời hạn và có thể được giao cho chủ sở hữu mới nếu chủ sở hữu cũ ngừng phản hồi (có thể vì nó bị crash, tạm dừng quá lâu hoặc bị ngắt kết nối khỏi mạng). Bạn có thể sử dụng lease trong các tình huống mà hệ thống yêu cầu chỉ có một thứ gì đó. Ví dụ:
- Chỉ một nút được phép là leader cho một database shard, để tránh split brain (xem “Handling Node Outages”).
- Chỉ một giao dịch hoặc client được phép cập nhật một tài nguyên hoặc đối tượng cụ thể, để ngăn chặn nó bị hỏng do các lần ghi đồng thời.
- Chỉ một nút nên xử lý một tệp đầu vào nhất định cho một công việc xử lý lớn, để tránh lãng phí tài nguyên do nhiều nút thực hiện cùng một công việc một cách dư thừa.
Đáng để suy nghĩ cẩn thận về điều gì sẽ xảy ra nếu nhiều nút đồng thời tin rằng họ đang giữ lease, có thể do tạm dừng tiến trình. Trong ví dụ thứ ba, hậu quả chỉ là một số tài nguyên tính toán bị lãng phí, điều này không phải là vấn đề lớn. Nhưng trong hai trường hợp đầu tiên, hậu quả có thể là dữ liệu bị mất hoặc bị hỏng, điều này nghiêm trọng hơn nhiều.
Ví dụ, Hình 9-4 cho thấy một lỗi gây hỏng dữ liệu do triển khai khóa không đúng. (Lỗi này không chỉ là lý thuyết: HBase từng có vấn đề này 85 86.) Giả sử bạn muốn đảm bảo rằng một tệp trong dịch vụ lưu trữ chỉ có thể được truy cập bởi một client tại một thời điểm, vì nếu nhiều client cố gắng ghi vào nó, tệp sẽ bị hỏng. Bạn cố gắng triển khai điều này bằng cách yêu cầu client phải lấy lease từ dịch vụ khóa (lock service) trước khi truy cập tệp. Dịch vụ khóa như vậy thường được triển khai bằng thuật toán đồng thuận; chúng ta sẽ thảo luận thêm về điều này trong Chương 10.
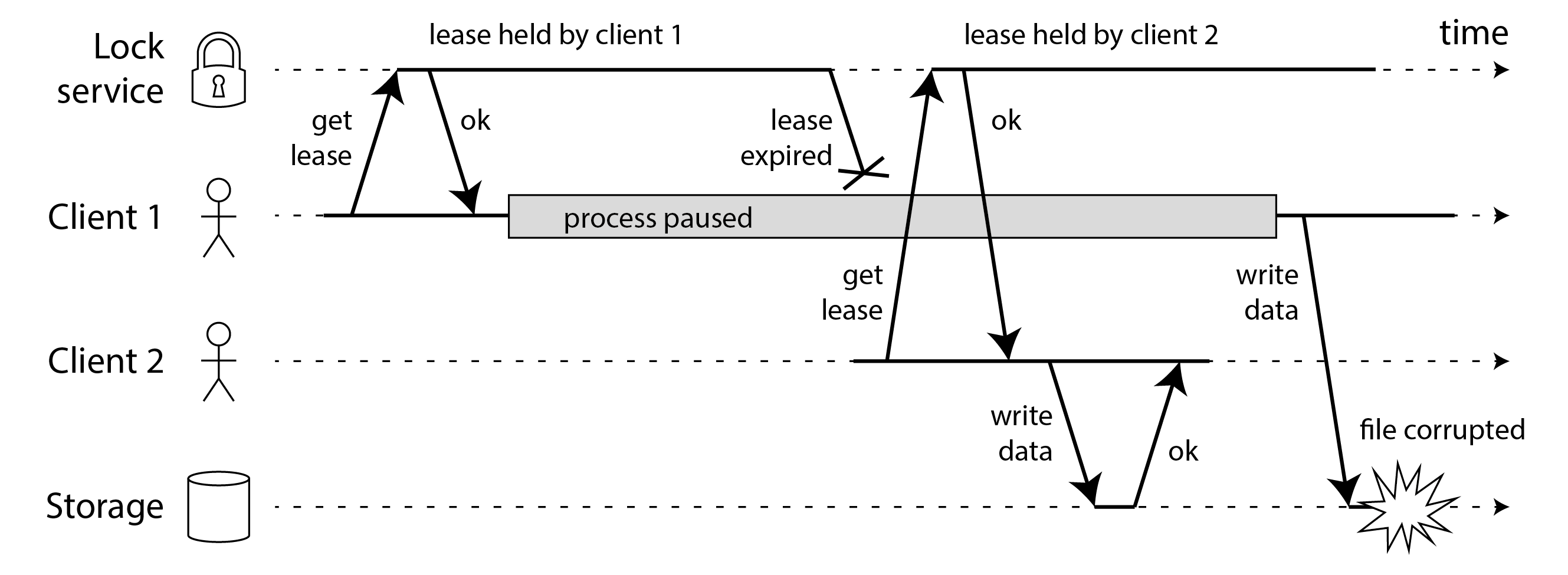
Vấn đề là một ví dụ về những gì chúng ta đã thảo luận trong “Process Pauses”: nếu client đang giữ lease bị tạm dừng quá lâu, lease của nó hết hạn. Một client khác có thể lấy lease cho cùng tệp và bắt đầu ghi vào tệp. Khi client đang tạm dừng quay trở lại, nó tin (sai lầm) rằng nó vẫn có lease hợp lệ và tiếp tục ghi vào tệp. Bây giờ chúng ta có tình huống split brain: các lần ghi của client xung đột và làm hỏng tệp.
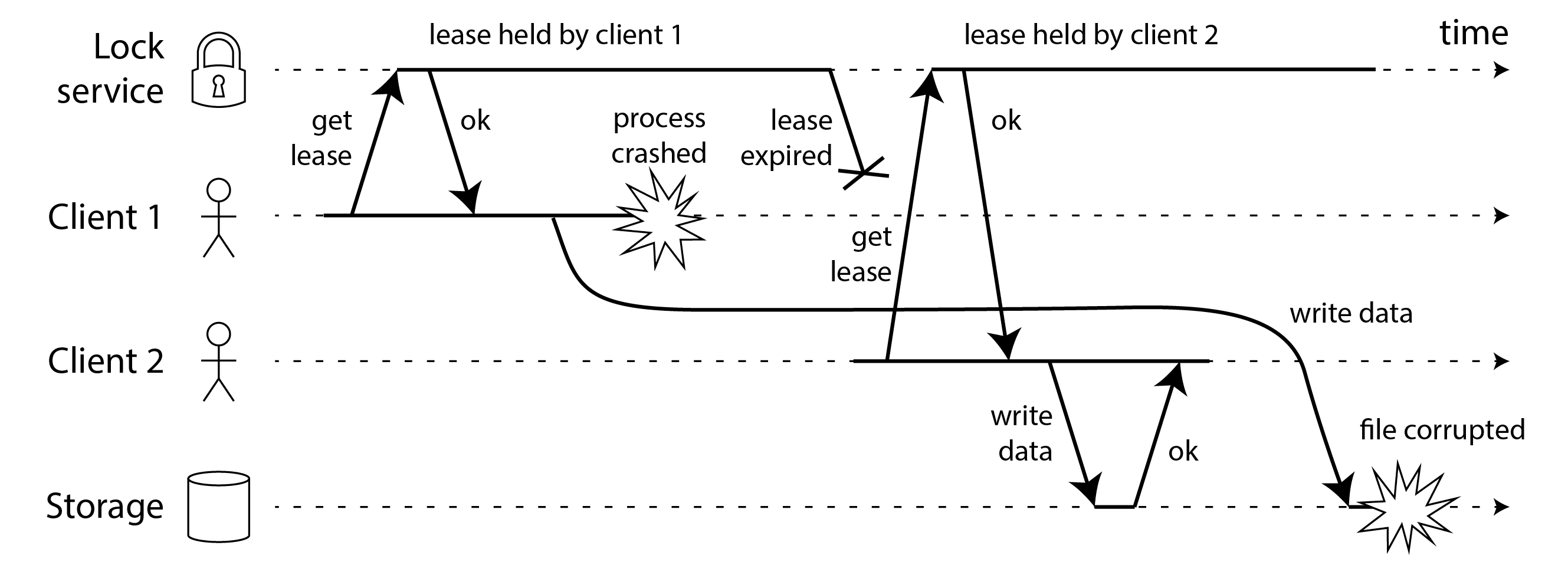
Hình 9-5 cho thấy một vấn đề khác có hậu quả tương tự. Trong ví dụ này không có tạm dừng tiến trình, chỉ có crash của client 1. Ngay trước khi client 1 crash, nó gửi một yêu cầu ghi đến dịch vụ lưu trữ, nhưng yêu cầu này bị trì hoãn lâu trong mạng. (Hãy nhớ từ “Network Faults in Practice” rằng các gói tin đôi khi có thể bị trì hoãn một phút hoặc hơn.) Khi yêu cầu ghi đến dịch vụ lưu trữ, lease đã hết hạn, cho phép client 2 lấy nó và thực hiện lần ghi của riêng mình. Kết quả là sự hỏng hóc tương tự như Hình 9-4.
Rào chắn zombie và yêu cầu bị trì hoãn
Thuật ngữ zombie đôi khi được sử dụng để mô tả chủ sở hữu lease cũ chưa nhận ra rằng nó đã mất lease, và vẫn đang hành động như thể nó là chủ sở hữu lease hiện tại. Vì chúng ta không thể loại trừ hoàn toàn zombie, chúng ta phải đảm bảo rằng chúng không thể gây hại dưới dạng split brain. Điều này được gọi là fencing off (rào chắn) zombie.
Một số hệ thống cố gắng rào chắn zombie bằng cách tắt chúng, ví dụ bằng cách ngắt kết nối chúng khỏi mạng 9, tắt VM qua giao diện quản lý của nhà cung cấp đám mây, hoặc thậm chí ngắt điện vật lý của máy 87. Cách tiếp cận này được gọi là Shoot The Other Node In The Head hay STONITH. Thật không may, nó có một số vấn đề: nó không bảo vệ chống lại độ trễ mạng lớn như trong Hình 9-5; có thể xảy ra tình huống tất cả các nút tắt lẫn nhau 19; và khi zombie đã được phát hiện và tắt, có thể đã quá muộn và dữ liệu có thể đã bị hỏng rồi.
Một giải pháp rào chắn mạnh mẽ hơn, bảo vệ chống lại cả zombie lẫn các yêu cầu bị trì hoãn, được minh họa trong Hình 9-6.
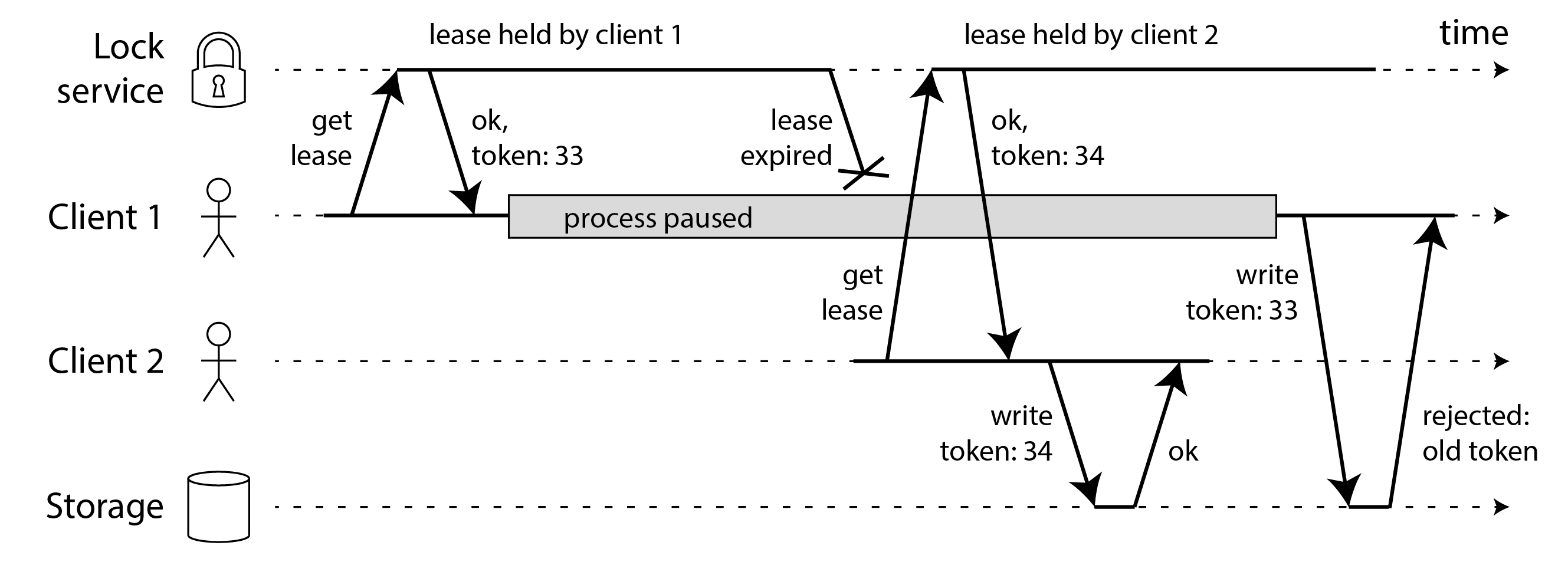
Giả sử rằng mỗi khi dịch vụ khóa cấp một khóa hoặc lease, nó cũng trả về một fencing token (mã thẻ rào chắn), là một số tăng mỗi khi một khóa được cấp (ví dụ: được tăng bởi dịch vụ khóa). Sau đó, chúng ta có thể yêu cầu rằng mỗi khi một client gửi yêu cầu ghi đến dịch vụ lưu trữ, nó phải bao gồm fencing token hiện tại của mình.
Note
Có một số tên thay thế cho fencing token. Trong Chubby, dịch vụ khóa của Google, chúng được gọi là sequencer 88, và trong Kafka, chúng được gọi là epoch number. Trong các thuật toán đồng thuận, mà chúng ta sẽ thảo luận trong Chương 10, ballot number (Paxos) hoặc term number (Raft) phục vụ mục đích tương tự.
Trong Hình 9-6, client 1 lấy lease với token 33, nhưng sau đó nó đi vào một lần tạm dừng dài và lease hết hạn. Client 2 lấy lease với token 34 (số luôn tăng) và sau đó gửi yêu cầu ghi đến dịch vụ lưu trữ, bao gồm token 34. Sau đó, client 1 quay trở lại và gửi lần ghi của nó đến dịch vụ lưu trữ, bao gồm giá trị token 33. Tuy nhiên, dịch vụ lưu trữ nhớ rằng nó đã xử lý một lần ghi với số token cao hơn (34), và do đó từ chối yêu cầu có token 33. Một client vừa lấy được lease phải ngay lập tức thực hiện một lần ghi vào dịch vụ lưu trữ, và sau khi lần ghi đó hoàn tất, bất kỳ zombie nào cũng bị rào chắn.
Nếu ZooKeeper là dịch vụ khóa của bạn, bạn có thể sử dụng transaction ID zxid hoặc phiên bản nút cversion làm fencing token 85. Với etcd, số revision cùng với lease ID phục vụ mục đích tương tự 89. FencedLock API trong Hazelcast tạo ra fencing token một cách tường minh 90.
Cơ chế này yêu cầu dịch vụ lưu trữ có cách kiểm tra xem một lần ghi có dựa trên token lỗi thời không. Ngoài ra, cũng đủ để dịch vụ hỗ trợ một lần ghi chỉ thành công nếu đối tượng chưa được ghi bởi một client khác kể từ khi client hiện tại đọc nó lần cuối, tương tự như thao tác atomic compare-and-set (CAS). Ví dụ, các dịch vụ lưu trữ đối tượng hỗ trợ kiểm tra như vậy: Amazon S3 gọi nó là conditional writes (ghi có điều kiện), Azure Blob Storage gọi là conditional headers (tiêu đề có điều kiện), và Google Cloud Storage gọi là request preconditions (điều kiện tiên quyết cho yêu cầu).
Rào chắn với nhiều bản sao
Nếu client của bạn chỉ cần ghi vào một dịch vụ lưu trữ hỗ trợ ghi có điều kiện như vậy, dịch vụ khóa có phần dư thừa 91 92, vì việc gán lease có thể được triển khai trực tiếp dựa trên dịch vụ lưu trữ đó 93. Tuy nhiên, một khi bạn có fencing token, bạn cũng có thể sử dụng nó với nhiều dịch vụ hoặc bản sao, và đảm bảo rằng chủ sở hữu lease cũ bị rào chắn trên tất cả những dịch vụ đó.
Ví dụ, hãy tưởng tượng dịch vụ lưu trữ là một kho khóa-giá trị (key-value store) được nhân bản không có leader (leaderless) với giải quyết xung đột last-write-wins (xem “Leaderless Replication”). Trong hệ thống như vậy, client gửi các lần ghi trực tiếp đến mỗi bản sao, và mỗi bản sao độc lập quyết định có chấp nhận một lần ghi hay không dựa trên timestamp được gán bởi client.
Như minh họa trong Hình 9-7, bạn có thể đặt fencing token của writer vào các bit hoặc chữ số có nghĩa cao nhất của timestamp. Sau đó, bạn có thể chắc chắn rằng bất kỳ timestamp nào được tạo bởi chủ sở hữu lease mới sẽ lớn hơn bất kỳ timestamp nào từ chủ sở hữu lease cũ, ngay cả khi các lần ghi của chủ sở hữu lease cũ xảy ra sau.
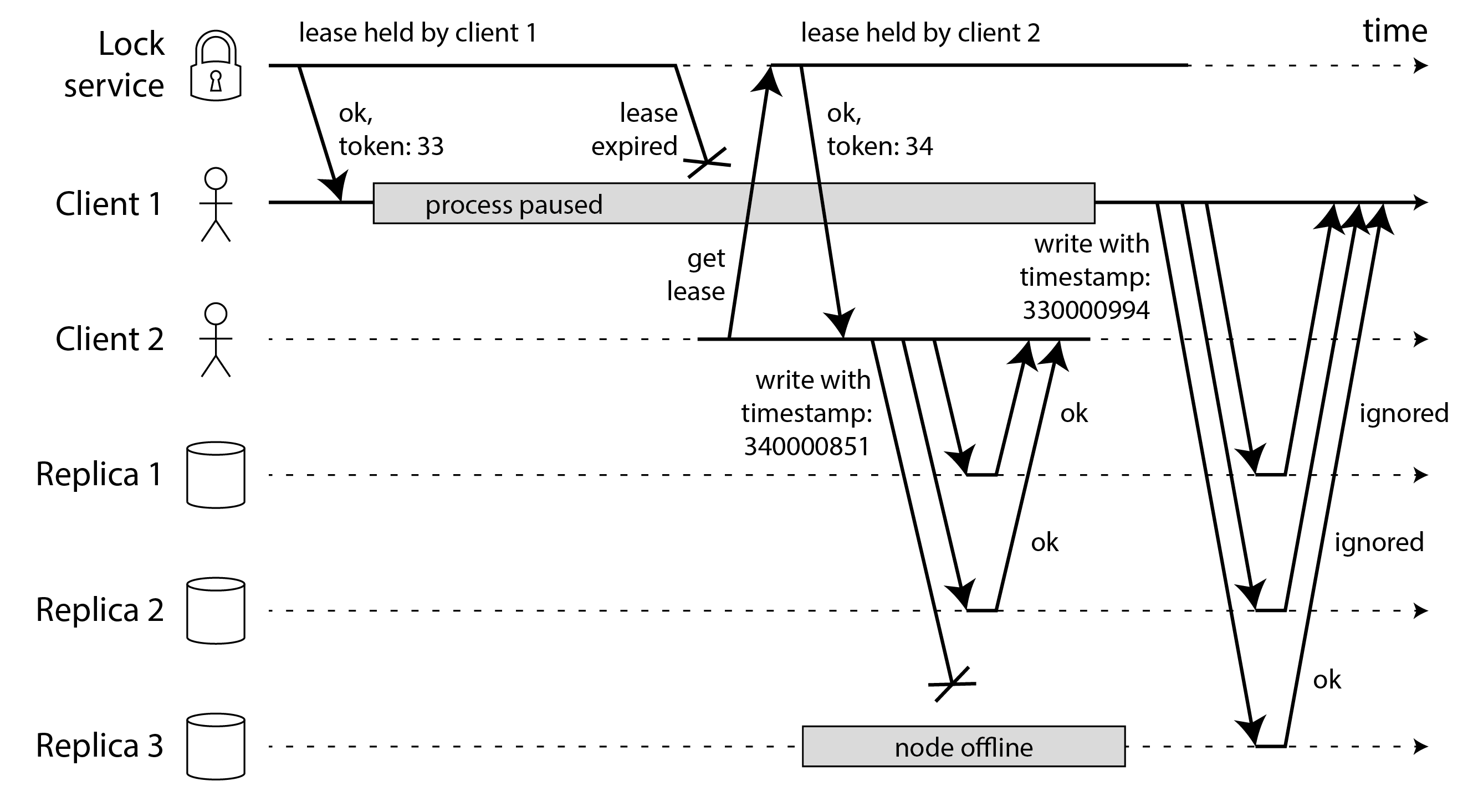
Trong Hình 9-7, Client 2 có fencing token là 34, vì vậy tất cả timestamp của nó bắt đầu bằng 34… đều lớn hơn bất kỳ timestamp nào bắt đầu bằng 33… được tạo bởi Client 1. Client 2 ghi vào một quorum các bản sao nhưng không thể tiếp cận Replica 3. Điều này có nghĩa là khi zombie Client 1 sau đó cố gắng ghi, lần ghi của nó có thể thành công tại Replica 3 mặc dù bị bỏ qua bởi bản sao 1 và 2. Đây không phải là vấn đề, vì một lần đọc quorum tiếp theo sẽ ưu tiên lần ghi từ Client 2 với timestamp lớn hơn, và read repair hoặc anti-entropy cuối cùng sẽ ghi đè giá trị được viết bởi Client 1.
Như bạn có thể thấy từ những ví dụ này, không an toàn khi giả định rằng chỉ có một nút đang giữ lease tại bất kỳ thời điểm nào. May mắn thay, với một chút cẩn thận, bạn có thể sử dụng fencing token để ngăn zombie và các yêu cầu bị trì hoãn gây ra bất kỳ thiệt hại nào.
Lỗi Byzantine
Fencing token có thể phát hiện và chặn một nút đang vô tình hành động sai (ví dụ vì nó chưa phát hiện ra lease của mình đã hết hạn). Tuy nhiên, nếu nút cố tình muốn phá vỡ các đảm bảo của hệ thống, nó có thể dễ dàng làm vậy bằng cách gửi tin nhắn với fencing token giả.
Trong cuốn sách này, chúng ta giả định rằng các nút không đáng tin cậy nhưng trung thực: chúng có thể chậm hoặc không bao giờ phản hồi (do lỗi), và trạng thái của chúng có thể đã lỗi thời (do tạm dừng GC hoặc độ trễ mạng), nhưng chúng ta giả định rằng nếu một nút có phản hồi, nó đang nói “sự thật”: theo hiểu biết tốt nhất của mình, nó đang tuân theo các quy tắc của giao thức.
Các vấn đề hệ thống phân tán trở nên khó khăn hơn nhiều nếu có nguy cơ các nút có thể “nói dối” (gửi các phản hồi tùy ý bị lỗi hoặc bị hỏng), ví dụ: nó có thể bỏ nhiều phiếu mâu thuẫn trong cùng một cuộc bầu cử. Hành vi như vậy được gọi là Byzantine fault (lỗi Byzantine), và vấn đề đạt được sự đồng thuận trong môi trường không tin tưởng này được gọi là Byzantine Generals Problem (Vấn đề Tướng Byzantine) 94.
THE BYZANTINE GENERALS PROBLEM
Vấn đề Tướng Byzantine là sự tổng quát hóa của bài toán gọi là Two Generals Problem (Vấn đề Hai Tướng) 95, tưởng tượng một tình huống mà hai vị tướng quân đội cần thống nhất về một kế hoạch trận đánh. Vì họ đã cắm trại ở hai địa điểm khác nhau, họ chỉ có thể liên lạc qua sứ giả, và các sứ giả đôi khi bị trì hoãn hoặc bị mất (như các gói tin trong mạng). Chúng ta sẽ thảo luận về vấn đề đồng thuận (consensus) này trong Chương 10.
Trong phiên bản Byzantine của bài toán, có n vị tướng cần thống nhất, và nỗ lực của họ bị cản trở bởi thực tế là có một số kẻ phản bội trong số họ. Hầu hết các tướng đều trung thành, và do đó gửi các thông điệp trung thực, nhưng những kẻ phản bội có thể cố gắng lừa dối và gây nhầm lẫn cho những người khác bằng cách gửi các thông điệp giả hoặc không trung thực. Không biết trước ai là kẻ phản bội.
Byzantium là một thành phố Hy Lạp cổ đại sau này trở thành Constantinople, ở nơi hiện nay là Istanbul ở Thổ Nhĩ Kỳ. Không có bằng chứng lịch sử nào cho thấy các tướng của Byzantium dễ âm mưu và tham gia vào các kế hoạch hơn những người ở nơi khác. Thay vào đó, cái tên xuất phát từ Byzantine theo nghĩa cực kỳ phức tạp, quan liêu, xảo quyệt, vốn được sử dụng trong chính trị từ lâu trước khi có máy tính 96. Lamport muốn chọn một quốc tịch không làm xúc phạm bất kỳ độc giả nào, và ông được khuyên rằng việc gọi nó là The Albanian Generals Problem không phải là ý tưởng hay 97.
Một hệ thống là Byzantine fault-tolerant (chịu lỗi Byzantine) nếu nó tiếp tục hoạt động đúng ngay cả khi một số nút bị trục trặc và không tuân theo giao thức, hoặc nếu những kẻ tấn công độc hại đang can thiệp vào mạng. Mối quan tâm này có liên quan trong một số trường hợp cụ thể. Ví dụ:
- Trong các môi trường hàng không vũ trụ, dữ liệu trong bộ nhớ máy tính hoặc thanh ghi CPU có thể bị hỏng do bức xạ, khiến nó phản hồi với các nút khác theo những cách không thể dự đoán tùy tiện. Vì lỗi hệ thống sẽ rất tốn kém (ví dụ: máy bay rơi và giết chết tất cả mọi người trên tàu, hoặc tên lửa va chạm với Trạm Vũ trụ Quốc tế), các hệ thống điều khiển bay phải chịu lỗi Byzantine 98 99.
- Trong một hệ thống có nhiều bên tham gia, một số người tham gia có thể cố gắng gian lận hoặc lừa đảo người khác. Trong những trường hợp như vậy, không an toàn khi một nút đơn giản tin tưởng vào thông điệp của nút khác, vì chúng có thể được gửi với ý định độc hại. Ví dụ, các loại tiền điện tử như Bitcoin và các blockchain khác có thể được coi là một cách để các bên không tin tưởng lẫn nhau thống nhất xem liệu một giao dịch có xảy ra hay không, mà không phụ thuộc vào cơ quan trung ương 100.
Tuy nhiên, trong các loại hệ thống chúng ta thảo luận trong cuốn sách này, chúng ta thường có thể an toàn giả định rằng không có lỗi Byzantine. Trong một trung tâm dữ liệu, tất cả các nút đều được kiểm soát bởi tổ chức của bạn (vì vậy chúng có thể được tin tưởng) và mức độ bức xạ đủ thấp để hỏng hóc bộ nhớ không phải là vấn đề lớn (mặc dù các trung tâm dữ liệu trên quỹ đạo đang được xem xét 101). Các hệ thống đa người thuê (multitenant) có các người thuê không tin tưởng lẫn nhau, nhưng họ bị cô lập với nhau bằng tường lửa, ảo hóa và chính sách kiểm soát truy cập, không phải bằng khả năng chịu lỗi Byzantine. Các giao thức làm cho hệ thống chịu lỗi Byzantine khá đắt tiền 102, và các hệ thống nhúng chịu lỗi phụ thuộc vào sự hỗ trợ từ cấp độ phần cứng 98. Trong hầu hết các hệ thống dữ liệu phía máy chủ, chi phí triển khai các giải pháp chịu lỗi Byzantine khiến chúng không thực tế.
Các ứng dụng web cần chuẩn bị cho hành vi tùy tiện và độc hại của các client do người dùng cuối kiểm soát, chẳng hạn như trình duyệt web. Đây là lý do tại sao xác thực đầu vào (input validation), làm sạch (sanitization) và thoát đầu ra (output escaping) rất quan trọng: để ngăn chặn SQL injection và cross-site scripting, ví dụ vậy. Tuy nhiên, chúng ta thường không sử dụng các giao thức chịu lỗi Byzantine ở đây, mà đơn giản là làm cho máy chủ trở thành cơ quan quyết định hành vi nào của client được phép hay không. Trong các mạng ngang hàng (peer-to-peer networks), nơi không có cơ quan trung ương như vậy, khả năng chịu lỗi Byzantine phù hợp hơn 103 104.
Một lỗi trong phần mềm có thể được coi là một lỗi Byzantine, nhưng nếu bạn triển khai cùng một phần mềm lên tất cả các nút, thì một thuật toán chịu lỗi Byzantine không thể cứu bạn. Hầu hết các thuật toán chịu lỗi Byzantine yêu cầu siêu đa số của hơn hai phần ba số nút hoạt động đúng (ví dụ: nếu bạn có bốn nút, tối đa một nút có thể bị trục trặc). Để sử dụng cách tiếp cận này chống lại các lỗi, bạn sẽ phải có bốn triển khai độc lập của cùng một phần mềm và hy vọng rằng một lỗi chỉ xuất hiện trong một trong bốn triển khai.
Tương tự, sẽ hấp dẫn nếu một giao thức có thể bảo vệ chúng ta khỏi các lỗ hổng, xâm phạm bảo mật và các cuộc tấn công độc hại. Thật không may, điều này cũng không thực tế: trong hầu hết các hệ thống, nếu kẻ tấn công có thể xâm phạm một nút, họ có thể xâm phạm tất cả chúng, vì chúng có thể đang chạy cùng một phần mềm. Do đó, các cơ chế truyền thống (xác thực, kiểm soát truy cập, mã hóa, tường lửa, v.v.) vẫn là sự bảo vệ chính chống lại những kẻ tấn công.
Các dạng yếu của sự dối trá
Mặc dù chúng ta giả định rằng các nút nói chung là trung thực, nhưng có thể đáng thêm các cơ chế vào phần mềm để bảo vệ chống lại các dạng “dối trá” yếu, ví dụ như các tin nhắn không hợp lệ do sự cố phần cứng, lỗi phần mềm và cấu hình sai. Các cơ chế bảo vệ như vậy không phải là khả năng chịu lỗi Byzantine đầy đủ, vì chúng không thể chống lại một đối thủ có chủ đích, nhưng chúng vẫn là những bước đơn giản và thực tế hướng tới độ tin cậy tốt hơn. Ví dụ:
- Các gói tin mạng đôi khi bị hỏng do sự cố phần cứng hoặc lỗi trong hệ điều hành, driver, router, v.v. Thông thường, các gói tin bị hỏng được phát hiện bởi các checksum được tích hợp vào TCP và UDP, nhưng đôi khi chúng vượt qua được phát hiện 105 106 107. Các biện pháp đơn giản thường đủ để bảo vệ chống lại sự hỏng hóc như vậy, chẳng hạn như checksum trong giao thức cấp ứng dụng. Các kết nối mã hóa TLS cũng cung cấp sự bảo vệ chống lại hỏng hóc.
- Một ứng dụng có thể truy cập công khai phải cẩn thận làm sạch bất kỳ đầu vào nào từ người dùng, ví dụ kiểm tra rằng một giá trị nằm trong phạm vi hợp lý và giới hạn kích thước chuỗi để ngăn chặn từ chối dịch vụ (denial of service) thông qua phân bổ bộ nhớ lớn. Một dịch vụ nội bộ sau tường lửa có thể thoát khỏi việc kiểm tra đầu vào ít nghiêm ngặt hơn, nhưng các kiểm tra cơ bản trong bộ phân tích cú pháp giao thức vẫn là ý tưởng tốt 105.
- NTP client có thể được cấu hình với nhiều địa chỉ máy chủ. Khi đồng bộ hóa, client liên hệ tất cả chúng, ước tính lỗi của chúng và kiểm tra rằng đa số máy chủ đồng ý về một phạm vi thời gian nào đó. Miễn là hầu hết các máy chủ đều ổn, một máy chủ NTP được cấu hình sai đang báo cáo thời gian không chính xác sẽ được phát hiện là ngoại lệ và bị loại khỏi đồng bộ hóa 39. Việc sử dụng nhiều máy chủ làm NTP mạnh mẽ hơn so với khi nó chỉ sử dụng một máy chủ duy nhất.
Mô Hình Hệ Thống và Thực Tế
Nhiều thuật toán đã được thiết kế để giải quyết các vấn đề hệ thống phân tán, ví dụ chúng ta sẽ xem xét các giải pháp cho vấn đề đồng thuận trong Chương 10. Để hữu ích, những thuật toán này cần chịu đựng các lỗi khác nhau của hệ thống phân tán mà chúng ta đã thảo luận trong chương này.
Các thuật toán cần được viết theo cách không phụ thuộc quá nhiều vào chi tiết về cấu hình phần cứng và phần mềm mà chúng chạy trên đó. Điều này đòi hỏi chúng ta phải hình thức hóa theo một cách nào đó các loại lỗi mà chúng ta mong đợi xảy ra trong một hệ thống. Chúng ta làm điều này bằng cách định nghĩa một system model (mô hình hệ thống), là một sự trừu tượng hóa mô tả những điều mà một thuật toán có thể giả định.
Về các giả định thời gian, ba mô hình hệ thống thường được sử dụng:
- Mô hình đồng bộ (Synchronous model)
- Mô hình đồng bộ giả định độ trễ mạng có giới hạn, tạm dừng tiến trình có giới hạn và lỗi đồng hồ có giới hạn. Điều này không có nghĩa là đồng hồ đồng bộ chính xác hoặc độ trễ mạng bằng không; nó chỉ có nghĩa là bạn biết rằng độ trễ mạng, tạm dừng và trôi dạt đồng hồ sẽ không bao giờ vượt quá một giới hạn trên cố định 108. Mô hình đồng bộ không phải là mô hình thực tế của hầu hết các hệ thống thực tế, vì (như đã thảo luận trong chương này) các độ trễ và tạm dừng không giới hạn thực sự xảy ra.
- Mô hình đồng bộ từng phần (Partially synchronous model)
- Đồng bộ từng phần có nghĩa là một hệ thống hoạt động như một hệ thống đồng bộ hầu hết thời gian, nhưng đôi khi vượt quá các giới hạn cho độ trễ mạng, tạm dừng tiến trình và trôi dạt đồng hồ 108. Đây là một mô hình thực tế của nhiều hệ thống: hầu hết thời gian, mạng và các tiến trình hoạt động khá tốt, nếu không chúng ta sẽ không bao giờ có thể hoàn thành bất cứ điều gì, nhưng chúng ta phải tính đến thực tế là bất kỳ giả định thời gian nào cũng có thể bị phá vỡ đôi khi. Khi điều này xảy ra, độ trễ mạng, tạm dừng và lỗi đồng hồ có thể trở nên tùy ý lớn.
- Mô hình bất đồng bộ (Asynchronous model)
- Trong mô hình này, một thuật toán không được phép đưa ra bất kỳ giả định thời gian nào, thực tế nó thậm chí không có đồng hồ (vì vậy nó không thể sử dụng timeout). Một số thuật toán có thể được thiết kế cho mô hình bất đồng bộ, nhưng nó rất hạn chế.
Hơn nữa, ngoài các vấn đề về thời gian, chúng ta phải xem xét các lỗi nút. Một số mô hình hệ thống phổ biến cho các nút là:
- Lỗi crash-stop
- Trong mô hình crash-stop (hay fail-stop), một thuật toán có thể giả định rằng một nút chỉ có thể bị lỗi theo một cách, đó là bị crash 109. Điều này có nghĩa là nút có thể đột ngột ngừng phản hồi tại bất kỳ thời điểm nào, và sau đó nút đó biến mất mãi mãi, không bao giờ quay trở lại.
- Lỗi crash-recovery
- Chúng ta giả định rằng các nút có thể crash tại bất kỳ thời điểm nào, và có thể bắt đầu phản hồi lại sau một thời gian không xác định. Trong mô hình crash-recovery, các nút được giả định có bộ nhớ ổn định (tức là bộ nhớ đĩa không bay hơi) được giữ nguyên qua các lần crash, trong khi trạng thái trong bộ nhớ được giả định là bị mất.
- Hiệu suất giảm sút và chức năng từng phần
- Ngoài việc crash và khởi động lại, các nút có thể chạy chậm: chúng vẫn có thể phản hồi các yêu cầu kiểm tra sức khỏe (health check), trong khi quá chậm để hoàn thành bất kỳ công việc thực sự nào. Ví dụ, một giao diện mạng Gigabit có thể đột ngột giảm xuống throughput 1 Kb/s do lỗi driver 110; một tiến trình đang chịu áp lực bộ nhớ có thể dành phần lớn thời gian thực hiện garbage collection 111; các SSD đã mòn có thể có hiệu suất thất thường; và phần cứng có thể bị ảnh hưởng bởi nhiệt độ cao, đầu nối lỏng, rung động cơ học, sự cố nguồn điện, lỗi firmware và nhiều hơn nữa 112. Tình huống như vậy được gọi là limping node (nút đang khập khiễng), gray failure (lỗi xám) hoặc fail-slow (lỗi chậm) 113, và nó có thể còn khó đối phó hơn so với một nút lỗi sạch. Một vấn đề liên quan là khi một tiến trình ngừng thực hiện một số điều mà nó được cho là làm trong khi các khía cạnh khác tiếp tục hoạt động, ví dụ vì một luồng nền bị crash hoặc deadlock 114.
- Lỗi Byzantine (tùy tiện)
- Các nút có thể làm bất cứ điều gì, bao gồm cả cố gắng lừa dối và đánh lừa các nút khác, như được mô tả Đối với việc mô hình hóa các hệ thống thực tế, mô hình đồng bộ một phần (partially synchronous) với các lỗi crash-recovery thường là mô hình hữu ích nhất. Nó cho phép độ trễ mạng không giới hạn, các tiến trình bị tạm dừng và các node chậm. Nhưng các thuật toán phân tán đối phó với mô hình đó như thế nào?
Định nghĩa tính đúng đắn của một thuật toán
Để định nghĩa ý nghĩa của việc một thuật toán là đúng đắn (correct), chúng ta có thể mô tả các thuộc tính (properties) của nó. Ví dụ, đầu ra của một thuật toán sắp xếp có thuộc tính là với bất kỳ hai phần tử khác nhau nào trong danh sách đầu ra, phần tử nằm ở phía bên trái sẽ nhỏ hơn phần tử nằm ở phía bên phải. Đây chỉ là cách diễn đạt hình thức của ý nghĩa khi một danh sách được sắp xếp.
Tương tự, chúng ta có thể viết ra các thuộc tính mà chúng ta muốn có ở một thuật toán phân tán để định nghĩa ý nghĩa của việc đúng đắn. Ví dụ, nếu chúng ta đang tạo các fencing token cho một khóa (lock) (xem “Fencing off zombies and delayed requests”), chúng ta có thể yêu cầu thuật toán có các thuộc tính sau:
- Uniqueness (Tính duy nhất)
- Không có hai yêu cầu về fencing token nào trả về cùng một giá trị.
- Monotonic sequence (Dãy đơn điệu tăng)
- Nếu yêu cầu x trả về token t**x, và yêu cầu y trả về token t**y, và x hoàn thành trước khi y bắt đầu, thì t**x < t**y.
- Availability (Tính khả dụng)
- Một node yêu cầu fencing token và không bị sập thì cuối cùng sẽ nhận được phản hồi.
Một thuật toán là đúng đắn trong một mô hình hệ thống nào đó nếu nó luôn thỏa mãn các thuộc tính của mình trong mọi tình huống mà chúng ta giả định có thể xảy ra trong mô hình hệ thống đó. Tuy nhiên, nếu tất cả các node đều sập, hoặc tất cả độ trễ mạng đột ngột trở nên vô hạn dài, thì không có thuật toán nào có thể hoàn thành bất cứ điều gì. Làm thế nào chúng ta vẫn có thể đưa ra các đảm bảo hữu ích ngay cả trong một mô hình hệ thống cho phép lỗi hoàn toàn?
Safety và liveness
Để làm rõ tình huống này, cần phân biệt hai loại thuộc tính khác nhau: các thuộc tính safety (an toàn) và liveness (sống động). Trong ví dụ vừa nêu, uniqueness và monotonic sequence là các thuộc tính safety, nhưng availability là một thuộc tính liveness.
Điều gì phân biệt hai loại thuộc tính? Một dấu hiệu nhận biết là các thuộc tính liveness thường có từ “eventually” (cuối cùng) trong định nghĩa của chúng. (Và đúng vậy, bạn đoán được rồi: eventual consistency là một thuộc tính liveness 115.)
Safety thường được định nghĩa không chính thức là không có gì tồi tệ xảy ra, và liveness là điều gì đó tốt đẹp cuối cùng sẽ xảy ra. Tuy nhiên, tốt nhất là không nên hiểu quá nhiều vào những định nghĩa không chính thức đó, vì “tốt đẹp” và “tồi tệ” là những phán xét giá trị không áp dụng tốt cho các thuật toán. Các định nghĩa thực tế về safety và liveness chính xác hơn 116:
- Nếu một thuộc tính safety bị vi phạm, chúng ta có thể chỉ ra một thời điểm cụ thể mà nó bị phá vỡ (ví dụ, nếu thuộc tính uniqueness bị vi phạm, chúng ta có thể xác định thao tác cụ thể mà fencing token bị trùng lặp được trả về). Sau khi một thuộc tính safety bị vi phạm, sự vi phạm đó không thể bị hoàn tác, thiệt hại đã xảy ra rồi.
- Một thuộc tính liveness hoạt động theo chiều ngược lại: nó có thể không thỏa mãn tại một thời điểm nào đó (ví dụ, một node có thể đã gửi yêu cầu nhưng chưa nhận được phản hồi), nhưng luôn có hy vọng rằng nó có thể được thỏa mãn trong tương lai (cụ thể là bằng cách nhận được phản hồi).
Một lợi thế của việc phân biệt giữa các thuộc tính safety và liveness là nó giúp chúng ta xử lý các mô hình hệ thống khó khăn. Đối với các thuật toán phân tán, điều phổ biến là yêu cầu các thuộc tính safety luôn được thỏa mãn, trong mọi tình huống có thể của một mô hình hệ thống 108. Nghĩa là, ngay cả khi tất cả các node đều sập, hoặc toàn bộ mạng bị lỗi, thuật toán vẫn phải đảm bảo rằng nó không trả về kết quả sai (tức là các thuộc tính safety vẫn được thỏa mãn).
Tuy nhiên, với các thuộc tính liveness, chúng ta được phép đặt ra các điều kiện: ví dụ, chúng ta có thể nói rằng một yêu cầu chỉ cần nhận được phản hồi nếu đa số các node không bị sập, và chỉ nếu mạng cuối cùng phục hồi sau sự cố. Định nghĩa của mô hình đồng bộ một phần yêu cầu rằng cuối cùng hệ thống sẽ trở lại trạng thái đồng bộ, tức là bất kỳ giai đoạn gián đoạn mạng nào cũng chỉ kéo dài trong một khoảng thời gian hữu hạn và sau đó được khắc phục.
Ánh xạ các mô hình hệ thống vào thế giới thực
Các thuộc tính safety và liveness và các mô hình hệ thống rất hữu ích để suy luận về tính đúng đắn của một thuật toán phân tán. Tuy nhiên, khi triển khai một thuật toán trong thực tế, những sự thật lộn xộn của thực tế lại quay trở lại làm phiền bạn, và rõ ràng là mô hình hệ thống là một sự trừu tượng hóa đơn giản hóa của thực tế.
Ví dụ, các thuật toán trong mô hình crash-recovery thường giả định rằng dữ liệu trong bộ lưu trữ ổn định (stable storage) sống sót qua các lần sập. Nhưng điều gì xảy ra nếu dữ liệu trên đĩa bị hỏng, hoặc dữ liệu bị xóa sạch do lỗi phần cứng hoặc cấu hình sai 117? Điều gì xảy ra nếu một máy chủ có lỗi firmware và không nhận ra các ổ cứng của nó khi khởi động lại, mặc dù các ổ đĩa được kết nối đúng cách với máy chủ 118?
Các thuật toán quorum (xem “Quorums for reading and writing”) dựa vào khả năng một node nhớ dữ liệu mà nó tuyên bố đã lưu trữ. Nếu một node có thể bị mất trí nhớ và quên dữ liệu đã lưu trữ trước đó, điều đó phá vỡ điều kiện quorum, và do đó phá vỡ tính đúng đắn của thuật toán. Có thể cần một mô hình hệ thống mới, trong đó chúng ta giả định rằng bộ lưu trữ ổn định hầu hết sống sót qua các lần sập, nhưng đôi khi có thể bị mất. Nhưng mô hình đó sẽ trở nên khó lý luận hơn.
Mô tả lý thuyết của một thuật toán có thể tuyên bố rằng một số điều đơn giản được giả định là không xảy ra, và trong các hệ thống không Byzantine, chúng ta phải đưa ra một số giả định về các lỗi có thể và không thể xảy ra. Tuy nhiên, một triển khai thực tế vẫn có thể phải bao gồm mã để xử lý trường hợp điều gì đó xảy ra mà được giả định là không thể xảy ra, ngay cả khi việc xử lý đó chỉ là
printf("Sucks to be you") và exit(666), tức là để người vận hành con người dọn dẹp mớ hỗn độn 119.
(Đây là một sự khác biệt giữa khoa học máy tính và kỹ thuật phần mềm.)
Điều đó không có nghĩa là các mô hình hệ thống lý thuyết, trừu tượng là vô giá trị, hoàn toàn ngược lại. Chúng cực kỳ hữu ích trong việc chắt lọc độ phức tạp của các hệ thống thực tế thành một tập hợp các lỗi có thể quản lý được mà chúng ta có thể lý luận, để chúng ta có thể hiểu vấn đề và cố gắng giải quyết nó một cách có hệ thống.
Các Phương Pháp Hình Thức và Kiểm Thử Ngẫu Nhiên
Làm thế nào chúng ta biết rằng một thuật toán thỏa mãn các thuộc tính yêu cầu? Do tính đồng thời, các lỗi một phần và độ trễ mạng, có một số lượng khổng lồ các trạng thái tiềm năng. Chúng ta cần đảm bảo rằng các thuộc tính được thỏa mãn ở mọi trạng thái có thể, và đảm bảo rằng chúng ta không bỏ sót bất kỳ trường hợp biên nào.
Một cách tiếp cận là xác minh một thuật toán một cách hình thức bằng cách mô tả nó bằng toán học, và sử dụng các kỹ thuật chứng minh để chứng tỏ rằng nó thỏa mãn các thuộc tính yêu cầu trong tất cả các tình huống mà mô hình hệ thống cho phép. Việc chứng minh một thuật toán đúng đắn không có nghĩa là triển khai của nó trên một hệ thống thực tế sẽ luôn hoạt động đúng. Nhưng đó là một bước đầu tiên rất tốt, vì phân tích lý thuyết có thể phát hiện các vấn đề trong một thuật toán mà có thể vẫn ẩn trong một thời gian dài trong một hệ thống thực tế, và chỉ xuất hiện gây rắc rối khi các giả định của bạn (ví dụ về thời gian) bị phá vỡ do các trường hợp bất thường.
Thận trọng là kết hợp phân tích lý thuyết với kiểm thử thực nghiệm để xác minh rằng các triển khai hoạt động như mong đợi. Các kỹ thuật như property-based testing (kiểm thử dựa trên thuộc tính), fuzzing (kiểm thử mờ) và deterministic simulation testing (kiểm thử mô phỏng xác định, DST) sử dụng tính ngẫu nhiên để kiểm tra một hệ thống trong nhiều tình huống khác nhau. Các công ty như Amazon Web Services đã sử dụng thành công kết hợp các kỹ thuật này trên nhiều sản phẩm của họ 120 121.
Model checking và các ngôn ngữ đặc tả
Model checker là các công cụ giúp xác minh rằng một thuật toán hoặc hệ thống hoạt động như mong đợi. Đặc tả thuật toán được viết bằng một ngôn ngữ chuyên dụng như TLA+, Gallina, hoặc FizzBee. Các ngôn ngữ này giúp dễ dàng tập trung vào hành vi của thuật toán mà không lo lắng về các chi tiết triển khai mã. Các model checker sau đó sử dụng các mô hình này để xác minh rằng các bất biến (invariants) được thỏa mãn ở tất cả các trạng thái của thuật toán bằng cách thử một cách có hệ thống tất cả những gì có thể xảy ra.
Model checking thực ra không thể chứng minh rằng các bất biến của một thuật toán được thỏa mãn cho mọi trạng thái có thể vì hầu hết các thuật toán trong thế giới thực có không gian trạng thái vô hạn. Một xác minh thực sự của tất cả các trạng thái sẽ đòi hỏi một chứng minh hình thức, điều này có thể thực hiện được, nhưng thường khó khăn hơn so với việc chạy một model checker. Thay vào đó, các model checker khuyến khích bạn giảm mô hình của thuật toán thành một xấp xỉ có thể được xác minh đầy đủ, hoặc giới hạn quá trình thực thi đến một giới hạn trên nào đó (ví dụ, bằng cách đặt số lượng tối đa các tin nhắn có thể được gửi). Bất kỳ lỗi nào chỉ xảy ra với các lần thực thi dài hơn sẽ không được tìm thấy.
Dù vậy, các model checker đạt được sự cân bằng tốt giữa sự dễ sử dụng và khả năng tìm ra các lỗi không hiển nhiên. CockroachDB, TiDB, Kafka và nhiều hệ thống phân tán khác sử dụng các đặc tả mô hình để tìm và sửa lỗi 122 123 124. Ví dụ, sử dụng TLA+, các nhà nghiên cứu đã có thể chứng minh khả năng mất dữ liệu trong viewstamped replication (VR) gây ra bởi sự mơ hồ trong mô tả bằng văn xuôi của thuật toán 125.
Theo thiết kế, các model checker không chạy mã thực tế của bạn, mà là một mô hình đơn giản hóa chỉ chỉ định các ý tưởng cốt lõi của giao thức của bạn. Điều này làm cho việc khám phá không gian trạng thái một cách có hệ thống dễ dàng hơn, nhưng nó có nguy cơ khiến đặc tả và triển khai của bạn không đồng bộ với nhau 126. Có thể kiểm tra xem mô hình và triển khai thực tế có hành vi tương đương hay không, nhưng điều này đòi hỏi phải gắn công cụ đo lường vào triển khai thực tế 127.
Fault injection (Tiêm lỗi)
Nhiều lỗi được kích hoạt khi xảy ra sự cố máy móc và mạng. Fault injection là một kỹ thuật hiệu quả (và đôi khi đáng sợ) để xác minh liệu triển khai của hệ thống có hoạt động như mong đợi khi mọi thứ trở nên sai hay không. Ý tưởng rất đơn giản: tiêm các lỗi vào môi trường của một hệ thống đang chạy và xem nó hoạt động như thế nào. Các lỗi có thể là lỗi mạng, sập máy, hỏng đĩa, các tiến trình bị tạm dừng, bất cứ điều gì bạn có thể tưởng tượng xảy ra sai với một máy tính.
Các bài kiểm thử fault injection thường được chạy trong một môi trường gần giống với môi trường sản xuất nơi hệ thống sẽ chạy. Một số thậm chí tiêm lỗi trực tiếp vào môi trường sản xuất của họ. Netflix đã phổ biến cách tiếp cận này với công cụ Chaos Monkey của họ 128. Fault injection trong môi trường sản xuất thường được gọi là chaos engineering (kỹ thuật hỗn loạn), mà chúng ta đã thảo luận trong “Reliability and Fault Tolerance”.
Để chạy các bài kiểm thử fault injection, hệ thống được kiểm thử trước tiên được triển khai cùng với các fault injection coordinator (điều phối viên tiêm lỗi) và các script. Các coordinator chịu trách nhiệm quyết định những lỗi nào cần thực thi và khi nào thực thi chúng. Các script cục bộ hoặc từ xa chịu trách nhiệm tiêm các lỗi vào các node hoặc tiến trình riêng lẻ. Các script tiêm lỗi sử dụng nhiều công cụ khác nhau để kích hoạt lỗi. Một tiến trình Linux có thể bị tạm dừng hoặc kết thúc bằng lệnh kill của Linux, một đĩa có thể được unmount bằng umount, và các kết nối mạng có thể bị gián đoạn thông qua cài đặt tường lửa. Bạn có thể kiểm tra hành vi của hệ thống trong và sau khi các lỗi được tiêm vào để đảm bảo mọi thứ hoạt động như mong đợi.
Vô số công cụ cần thiết để kích hoạt các lỗi khiến các bài kiểm thử fault injection trở nên cồng kềnh khi viết. Thông thường người ta áp dụng một framework fault injection như Jepsen để chạy các bài kiểm thử fault injection nhằm đơn giản hóa quá trình. Các framework như vậy đi kèm với các tích hợp cho nhiều hệ điều hành khác nhau và nhiều fault injector được xây dựng sẵn 129. Jepsen đã hiệu quả đáng kể trong việc tìm ra các lỗi nghiêm trọng trong nhiều hệ thống được sử dụng rộng rãi 130 131.
Deterministic simulation testing (Kiểm thử mô phỏng xác định)
Deterministic simulation testing (DST) cũng đã trở thành một bổ sung phổ biến cho model checking và fault injection. Nó sử dụng quá trình khám phá không gian trạng thái tương tự như một model checker, nhưng nó kiểm thử mã thực tế của bạn, không phải một mô hình.
Trong DST, một mô phỏng tự động chạy qua một số lượng lớn các lần thực thi ngẫu nhiên của hệ thống. Giao tiếp mạng, I/O và thời gian đồng hồ trong quá trình mô phỏng đều được thay thế bằng các mock (giả lập) cho phép bộ mô phỏng kiểm soát thứ tự chính xác mà các sự kiện xảy ra, bao gồm các thời gian và kịch bản lỗi khác nhau. Điều này cho phép bộ mô phỏng khám phá nhiều tình huống hơn so với các bài kiểm thử viết tay hoặc fault injection. Nếu một bài kiểm thử thất bại, nó có thể được chạy lại vì bộ mô phỏng biết thứ tự chính xác của các thao tác đã kích hoạt lỗi, trái ngược với fault injection, không có quyền kiểm soát chi tiết như vậy đối với hệ thống.
DST yêu cầu bộ mô phỏng có thể kiểm soát tất cả các nguồn không xác định (nondeterminism), chẳng hạn như độ trễ mạng. Thường áp dụng một trong ba chiến lược để làm cho mã trở nên xác định:
- Application-level (Cấp ứng dụng)
- Một số hệ thống được xây dựng từ đầu để dễ dàng thực thi mã theo cách xác định. Ví dụ, FoundationDB, một trong những tiên phong trong lĩnh vực DST, được xây dựng bằng một thư viện giao tiếp bất đồng bộ gọi là Flow. Flow cung cấp điểm để các nhà phát triển tiêm một mô phỏng mạng xác định vào hệ thống 132. Tương tự, TigerBeetle là một cơ sở dữ liệu xử lý giao dịch trực tuyến (OLTP) với hỗ trợ DST hạng nhất. Trạng thái của hệ thống được mô hình hóa như một máy trạng thái (state machine), với tất cả các biến đổi xảy ra trong một event loop duy nhất. Khi kết hợp với các nguyên thủy xác định mock như đồng hồ, kiến trúc như vậy có thể chạy theo cách xác định 133.
- Runtime-level (Cấp runtime)
- Các ngôn ngữ với các runtime bất đồng bộ và các thư viện thường được sử dụng cung cấp một điểm chèn để giới thiệu tính xác định. Một runtime đơn luồng được sử dụng để buộc tất cả mã bất đồng bộ chạy tuần tự. Ví dụ, FrostDB vá runtime của Go để thực thi goroutine tuần tự [^134]. Thư viện madsim của Rust hoạt động theo cách tương tự. Madsim cung cấp các triển khai xác định của API runtime bất đồng bộ Tokio, thư viện S3 của AWS, thư viện Rust của Kafka và nhiều thứ khác. Các ứng dụng có thể hoán đổi các thư viện và runtime xác định để có các lần thực thi kiểm thử xác định mà không cần thay đổi mã của chúng.
- Machine-level (Cấp máy)
- Thay vì vá mã tại runtime, toàn bộ một máy có thể được làm cho xác định. Đây là một quá trình tinh tế đòi hỏi một máy phải phản hồi tất cả các lệnh gọi thông thường không xác định bằng các phản hồi xác định. Các công cụ như Antithesis thực hiện điều này bằng cách xây dựng một hypervisor tùy chỉnh thay thế các thao tác thông thường không xác định bằng các thao tác xác định. Mọi thứ từ đồng hồ đến mạng và lưu trữ đều cần được tính đến. Tuy nhiên, khi hoàn thành, các nhà phát triển có thể chạy toàn bộ hệ thống phân tán của họ trong một tập hợp các container trong hypervisor và có được một hệ thống phân tán hoàn toàn xác định.
DST cung cấp một số ưu điểm ngoài khả năng phát lại. Các công cụ như Antithesis cố gắng khám phá nhiều đường dẫn mã khác nhau trong mã ứng dụng bằng cách phân nhánh một lần thực thi kiểm thử thành nhiều lần thực thi phụ khi nó phát hiện ra hành vi ít phổ biến hơn. Và vì các bài kiểm thử xác định thường sử dụng các đồng hồ mock và các lệnh gọi mạng, các bài kiểm thử như vậy có thể chạy nhanh hơn thời gian thực. Ví dụ, sự trừu tượng hóa thời gian của TigerBeetle cho phép các mô phỏng giả lập độ trễ mạng và timeout mà không thực sự mất toàn bộ thời gian để kích hoạt timeout. Các kỹ thuật như vậy cho phép bộ mô phỏng khám phá nhiều đường dẫn mã hơn và nhanh hơn.
Sức mạnh của Tính Xác Định
Tính không xác định (nondeterminism) là cốt lõi của tất cả các thách thức của hệ thống phân tán mà chúng ta đã thảo luận trong chương này: tính đồng thời, độ trễ mạng, các tiến trình bị tạm dừng, các bước nhảy đồng hồ và sự cố đều xảy ra theo những cách không thể đoán trước, thay đổi từ lần chạy này sang lần chạy khác của hệ thống. Ngược lại, nếu bạn có thể làm cho một hệ thống xác định, điều đó có thể đơn giản hóa mọi thứ rất nhiều.
Trên thực tế, việc làm cho mọi thứ trở nên xác định là một ý tưởng đơn giản nhưng mạnh mẽ xuất hiện đi xuất hiện lại trong thiết kế hệ thống phân tán. Ngoài deterministic simulation testing, chúng ta đã thấy một số cách sử dụng tính xác định trong các chương trước:
- Một lợi thế chính của event sourcing (xem “Event Sourcing and CQRS”) là bạn có thể phát lại theo cách xác định một log các sự kiện để tái tạo các materialized view dẫn xuất.
- Các workflow engine (xem “Durable Execution and Workflows”) dựa vào các định nghĩa workflow xác định để cung cấp ngữ nghĩa thực thi bền vững (durable execution semantics).
- State machine replication (nhân bản máy trạng thái), mà chúng ta sẽ thảo luận trong “Using shared logs”, nhân bản dữ liệu bằng cách độc lập thực thi cùng một chuỗi các giao dịch xác định trên mỗi bản sao. Chúng ta đã thấy hai biến thể của ý tưởng đó: statement-based replication (xem “Implementation of Replication Logs”) và thực thi giao dịch tuần tự sử dụng stored procedure (xem “Pros and cons of stored procedures”).
Tuy nhiên, việc làm cho mã hoàn toàn xác định đòi hỏi sự cẩn thận. Ngay cả khi bạn đã loại bỏ tất cả tính đồng thời và thay thế I/O, giao tiếp mạng, đồng hồ và bộ tạo số ngẫu nhiên bằng các mô phỏng xác định, các yếu tố không xác định vẫn có thể còn lại. Ví dụ, trong một số ngôn ngữ lập trình, thứ tự mà bạn lặp qua các phần tử của một bảng băm (hash table) có thể là không xác định. Việc bạn có gặp phải giới hạn tài nguyên hay không (lỗi cấp phát bộ nhớ, tràn ngăn xếp) cũng là không xác định.
Tóm Tắt
Trong chương này, chúng ta đã thảo luận về một loạt rộng các vấn đề có thể xảy ra trong các hệ thống phân tán, bao gồm:
- Bất cứ khi nào bạn cố gắng gửi một gói tin qua mạng, nó có thể bị mất hoặc bị trễ tùy tiện. Tương tự, phản hồi có thể bị mất hoặc bị trễ, vì vậy nếu bạn không nhận được phản hồi, bạn không biết liệu tin nhắn có đến nơi hay không.
- Đồng hồ của một node có thể không đồng bộ đáng kể với các node khác (dù bạn có cố gắng thiết lập NTP tốt đến đâu), nó có thể đột ngột nhảy tiến hoặc lùi theo thời gian, và việc dựa vào nó là nguy hiểm vì rất có thể bạn không có thước đo tốt về khoảng tin cậy của đồng hồ.
- Một tiến trình có thể tạm dừng trong một khoảng thời gian đáng kể tại bất kỳ điểm nào trong quá trình thực thi của nó, bị các node khác tuyên bố là đã chết, và sau đó quay trở lại hoạt động mà không nhận ra rằng nó đã bị tạm dừng.
Thực tế là các partial failure (lỗi một phần) như vậy có thể xảy ra là đặc điểm xác định của các hệ thống phân tán. Bất cứ khi nào phần mềm cố gắng thực hiện bất cứ điều gì liên quan đến các node khác, có khả năng nó đôi khi có thể thất bại, hoặc ngẫu nhiên chậm lại, hoặc không phản hồi gì cả (và cuối cùng hết thời gian chờ). Trong các hệ thống phân tán, chúng ta cố gắng xây dựng khả năng chịu đựng các partial failure vào phần mềm, để toàn bộ hệ thống có thể tiếp tục hoạt động ngay cả khi một số thành phần của nó bị hỏng.
Để chịu đựng các lỗi, bước đầu tiên là phát hiện chúng, nhưng ngay cả điều đó cũng khó. Hầu hết các hệ thống không có cơ chế chính xác để phát hiện liệu một node có bị lỗi hay không, vì vậy hầu hết các thuật toán phân tán dựa vào timeout để xác định liệu một node từ xa có còn khả dụng hay không. Tuy nhiên, timeout không thể phân biệt giữa lỗi mạng và lỗi node, và độ trễ mạng thay đổi đôi khi khiến một node bị nghi ngờ sai là đã sập. Xử lý các limping node (node đang khập khiễng), những node đang phản hồi nhưng quá chậm để thực hiện bất cứ điều gì hữu ích, thậm chí còn khó hơn.
Khi một lỗi được phát hiện, việc làm cho hệ thống chịu đựng nó cũng không dễ dàng: không có biến toàn cục, không có bộ nhớ dùng chung, không có kiến thức chung hoặc bất kỳ loại trạng thái dùng chung nào khác giữa các máy 83. Các node thậm chí không thể đồng ý về thời gian, chứ chưa nói đến bất cứ điều gì sâu sắc hơn. Cách duy nhất thông tin có thể chạy từ node này sang node khác là gửi nó qua mạng không đáng tin cậy. Các quyết định quan trọng không thể được thực hiện an toàn bởi một node duy nhất, vì vậy chúng ta cần các giao thức kêu gọi sự giúp đỡ từ các node khác và cố gắng đạt được quorum để đồng ý.
Nếu bạn quen với việc viết phần mềm trong sự hoàn hảo toán học lý tưởng của một máy tính đơn, nơi cùng một thao tác luôn trả về cùng một kết quả theo cách xác định, thì việc chuyển sang thực tế vật lý lộn xộn của các hệ thống phân tán có thể là một cú sốc. Ngược lại, các kỹ sư hệ thống phân tán thường coi một vấn đề là tầm thường nếu nó có thể được giải quyết trên một máy tính đơn 4, và thực sự một máy tính đơn ngày nay có thể làm được rất nhiều. Nếu bạn có thể tránh mở hộp Pandora và đơn giản là giữ mọi thứ trên một máy duy nhất, ví dụ bằng cách sử dụng một storage engine nhúng (xem “Embedded storage engines”), thì thường đáng làm như vậy.
Tuy nhiên, như đã thảo luận trong “Distributed versus Single-Node Systems”, khả năng mở rộng không phải là lý do duy nhất để muốn sử dụng một hệ thống phân tán. Khả năng chịu lỗi và độ trễ thấp (bằng cách đặt dữ liệu gần về mặt địa lý với người dùng) cũng là các mục tiêu quan trọng như nhau, và những điều đó không thể đạt được với một node đơn. Sức mạnh của các hệ thống phân tán là về nguyên tắc, chúng có thể chạy mãi mà không bị gián đoạn ở cấp độ dịch vụ, vì tất cả các lỗi và bảo trì có thể được xử lý ở cấp độ node. (Trên thực tế, nếu một thay đổi cấu hình xấu được triển khai đến tất cả các node, điều đó vẫn sẽ làm sụp đổ một hệ thống phân tán.)
Trong chương này chúng ta cũng đã đi lạc sang một số hướng để khám phá liệu sự không đáng tin cậy của mạng, đồng hồ và tiến trình có phải là quy luật không thể tránh khỏi của tự nhiên hay không. Chúng ta thấy rằng không phải: có thể đưa ra các đảm bảo phản hồi thời gian thực cứng (hard real-time response guarantees) và độ trễ giới hạn trong mạng, nhưng làm như vậy rất tốn kém và dẫn đến việc sử dụng tài nguyên phần cứng thấp hơn. Hầu hết các hệ thống không quan trọng về an toàn chọn rẻ và không đáng tin cậy hơn là đắt và đáng tin cậy.
Chương này hoàn toàn nói về các vấn đề và đã cho chúng ta một cái nhìn ảm đạm. Trong chương tiếp theo, chúng ta sẽ chuyển sang các giải pháp và thảo luận về một số thuật toán được thiết kế để đối phó với các vấn đề trong hệ thống phân tán.
Tài liệu tham khảo
Mark Cavage. There’s Just No Getting Around It: You’re Building a Distributed System. ACM Queue, volume 11, issue 4, pages 80-89, April 2013. doi:10.1145/2466486.2482856 ↩︎
Jay Kreps. Getting Real About Distributed System Reliability. blog.empathybox.com, March 2012. Archived at perma.cc/9B5Q-AEBW ↩︎
Coda Hale. You Can’t Sacrifice Partition Tolerance. codahale.com, October 2010. https://perma.cc/6GJU-X4G5 ↩︎
Jeff Hodges. Notes on Distributed Systems for Young Bloods. somethingsimilar.com, January 2013. Archived at perma.cc/B636-62CE ↩︎ ↩︎
Van Jacobson. Congestion Avoidance and Control. At ACM Symposium on Communications Architectures and Protocols (SIGCOMM), August 1988. doi:10.1145/52324.52356 ↩︎ ↩︎
Bert Hubert. The Ultimate SO_LINGER Page, or: Why Is My TCP Not Reliable. blog.netherlabs.nl, January 2009. Archived at perma.cc/6HDX-L2RR ↩︎ ↩︎
Jerome H. Saltzer, David P. Reed, and David D. Clark. End-To-End Arguments in System Design. ACM Transactions on Computer Systems, volume 2, issue 4, pages 277–288, November 1984. doi:10.1145/357401.357402 ↩︎
Peter Bailis and Kyle Kingsbury. The Network Is Reliable. ACM Queue, volume 12, issue 7, pages 48-55, July 2014. doi:10.1145/2639988.2639988 ↩︎ ↩︎
Joshua B. Leners, Trinabh Gupta, Marcos K. Aguilera, and Michael Walfish. Taming Uncertainty in Distributed Systems with Help from the Network. At 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741976 ↩︎ ↩︎
Phillipa Gill, Navendu Jain, and Nachiappan Nagappan. Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications. At ACM SIGCOMM Conference, August 2011. doi:10.1145/2018436.2018477 ↩︎
Urs Hölzle. But recently a farmer had started grazing a herd of cows nearby. And whenever they stepped on the fiber link, they bent it enough to cause a blip. x.com, May 2020. Archived at perma.cc/WX8X-ZZA5 ↩︎
CBC News. Hundreds lose internet service in northern B.C. after beaver chews through cable. cbc.ca, April 2021. Archived at perma.cc/UW8C-H2MY ↩︎
Will Oremus. The Global Internet Is Being Attacked by Sharks, Google Confirms. slate.com, August 2014. Archived at perma.cc/P6F3-C6YG ↩︎
Jess Auerbach Jahajeeah. Down to the wire: The ship fixing our internet. continent.substack.com, November 2023. Archived at perma.cc/DP7B-EQ7S ↩︎
Santosh Janardhan. More details about the October 4 outage. engineering.fb.com, October 2021. Archived at perma.cc/WW89-VSXH ↩︎
Tom Parfitt. Georgian woman cuts off web access to whole of Armenia. theguardian.com, April 2011. Archived at perma.cc/KMC3-N3NZ ↩︎
Antonio Voce, Tural Ahmedzade and Ashley Kirk. ‘Shadow fleets’ and subaquatic sabotage: are Europe’s undersea internet cables under attack? theguardian.com, March 2025. Archived at perma.cc/HA7S-ZDBV ↩︎
Shengyun Liu, Paolo Viotti, Christian Cachin, Vivien Quéma, and Marko Vukolić. XFT: Practical Fault Tolerance beyond Crashes. At 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), November 2016. ↩︎
Mark Imbriaco. Downtime last Saturday. github.blog, December 2012. Archived at perma.cc/M7X5-E8SQ ↩︎ ↩︎
Tom Lianza and Chris Snook. A Byzantine failure in the real world. blog.cloudflare.com, November 2020. Archived at perma.cc/83EZ-ALCY ↩︎ ↩︎
Mohammed Alfatafta, Basil Alkhatib, Ahmed Alquraan, and Samer Al-Kiswany. Toward a Generic Fault Tolerance Technique for Partial Network Partitioning. At 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI), November 2020. ↩︎
Marc A. Donges. Re: bnx2 cards Intermittantly Going Offline. Message to Linux netdev mailing list, spinics.net, September 2012. Archived at perma.cc/TXP6-H8R3 ↩︎ ↩︎
Troy Toman. Inside a CODE RED: Network Edition. signalvnoise.com, September 2020. Archived at perma.cc/BET6-FY25 ↩︎
Kyle Kingsbury. Call Me Maybe: Elasticsearch. aphyr.com, June 2014. perma.cc/JK47-S89J ↩︎
Salvatore Sanfilippo. A Few Arguments About Redis Sentinel Properties and Fail Scenarios. antirez.com, October 2014. perma.cc/8XEU-CLM8 ↩︎
Nicolas Liochon. CAP: If All You Have Is a Timeout, Everything Looks Like a Partition. blog.thislongrun.com, May 2015. Archived at perma.cc/FS57-V2PZ ↩︎
Matthew P. Grosvenor, Malte Schwarzkopf, Ionel Gog, Robert N. M. Watson, Andrew W. Moore, Steven Hand, and Jon Crowcroft. Queues Don’t Matter When You Can JUMP Them! At 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015. ↩︎ ↩︎
Theo Julienne. Debugging network stalls on Kubernetes. github.blog, November 2019. Archived at perma.cc/K9M8-XVGL ↩︎
Guohui Wang and T. S. Eugene Ng. The Impact of Virtualization on Network Performance of Amazon EC2 Data Center. At 29th IEEE International Conference on Computer Communications (INFOCOM), March 2010. doi:10.1109/INFCOM.2010.5461931 ↩︎ ↩︎
Brandon Philips. etcd: Distributed Locking and Service Discovery. At Strange Loop, September 2014. ↩︎
Steve Newman. A Systematic Look at EC2 I/O. blog.scalyr.com, October 2012. Archived at perma.cc/FL4R-H2VE ↩︎ ↩︎
Naohiro Hayashibara, Xavier Défago, Rami Yared, and Takuya Katayama. The ϕ Accrual Failure Detector. Japan Advanced Institute of Science and Technology, School of Information Science, Technical Report IS-RR-2004-010, May 2004. Archived at perma.cc/NSM2-TRYA ↩︎
Jeffrey Wang. Phi Accrual Failure Detector. ternarysearch.blogspot.co.uk, August 2013. perma.cc/L452-AMLV ↩︎
Srinivasan Keshav. An Engineering Approach to Computer Networking: ATM Networks, the Internet, and the Telephone Network. Addison-Wesley Professional, May 1997. ISBN: 978-0-201-63442-6 ↩︎ ↩︎
Othmar Kyas. ATM Networks. International Thomson Publishing, 1995. ISBN: 978-1-850-32128-6 ↩︎
Mellanox Technologies. InfiniBand FAQ, Rev 1.3. network.nvidia.com, December 2014. Archived at perma.cc/LQJ4-QZVK ↩︎
Jose Renato Santos, Yoshio Turner, and G. (John) Janakiraman. End-to-End Congestion Control for InfiniBand. At 22nd Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM), April 2003. Also published by HP Laboratories Palo Alto, Tech Report HPL-2002-359. doi:10.1109/INFCOM.2003.1208949 ↩︎
Jialin Li, Naveen Kr. Sharma, Dan R. K. Ports, and Steven D. Gribble. Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency. At ACM Symposium on Cloud Computing (SOCC), November 2014. doi:10.1145/2670979.2670988 ↩︎
Ulrich Windl, David Dalton, Marc Martinec, and Dale R. Worley. The NTP FAQ and HOWTO. ntp.org, November 2006. ↩︎ ↩︎ ↩︎
John Graham-Cumming. How and why the leap second affected Cloudflare DNS. blog.cloudflare.com, January 2017. Archived at archive.org ↩︎ ↩︎
David Holmes. Inside the Hotspot VM: Clocks, Timers and Scheduling Events – Part I – Windows. blogs.oracle.com, October 2006. Archived at archive.org ↩︎
Joran Dirk Greef. Three Clocks are Better than One. tigerbeetle.com, August 2021. Archived at perma.cc/5RXG-EU6B ↩︎
Oliver Yang. Pitfalls of TSC usage. oliveryang.net, September 2015. Archived at perma.cc/Z2QY-5FRA ↩︎
Steve Loughran. Time on Multi-Core, Multi-Socket Servers. steveloughran.blogspot.co.uk, September 2015. Archived at perma.cc/7M4S-D4U6 ↩︎
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s Globally-Distributed Database. At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012. ↩︎ ↩︎ ↩︎
M. Caporaloni and R. Ambrosini. How Closely Can a Personal Computer Clock Track the UTC Timescale Via the Internet? European Journal of Physics, volume 23, issue 4, pages L17–L21, June 2012. doi:10.1088/0143-0807/23/4/103 ↩︎
Nelson Minar. A Survey of the NTP Network. alumni.media.mit.edu, December 1999. Archived at perma.cc/EV76-7ZV3 ↩︎
Viliam Holub. Synchronizing Clocks in a Cassandra Cluster Pt. 1 – The Problem. blog.rapid7.com, March 2014. Archived at perma.cc/N3RV-5LNL ↩︎
Poul-Henning Kamp. The One-Second War (What Time Will You Die?) ACM Queue, volume 9, issue 4, pages 44–48, April 2011. doi:10.1145/1966989.1967009 ↩︎
Nelson Minar. Leap Second Crashes Half the Internet. somebits.com, July 2012. Archived at perma.cc/2WB8-D6EU ↩︎
Christopher Pascoe. Time, Technology and Leaping Seconds. googleblog.blogspot.co.uk, September 2011. Archived at perma.cc/U2JL-7E74 ↩︎
Mingxue Zhao and Jeff Barr. Look Before You Leap – The Coming Leap Second and AWS. aws.amazon.com, May 2015. Archived at perma.cc/KPE9-XMFM ↩︎
Darryl Veitch and Kanthaiah Vijayalayan. Network Timing and the 2015 Leap Second. At 17th International Conference on Passive and Active Measurement (PAM), April 2016. doi:10.1007/978-3-319-30505-9_29 ↩︎
VMware, Inc. Timekeeping in VMware Virtual Machines. vmware.com, October 2008. Archived at perma.cc/HM5R-T5NF ↩︎
Victor Yodaiken. Clock Synchronization in Finance and Beyond. yodaiken.com, November 2017. Archived at perma.cc/9XZD-8ZZN ↩︎
Mustafa Emre Acer, Emily Stark, Adrienne Porter Felt, Sascha Fahl, Radhika Bhargava, Bhanu Dev, Matt Braithwaite, Ryan Sleevi, and Parisa Tabriz. Where the Wild Warnings Are: Root Causes of Chrome HTTPS Certificate Errors. At ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 1407–1420, October 2017. doi:10.1145/3133956.3134007 ↩︎
European Securities and Markets Authority. MiFID II / MiFIR: Regulatory Technical and Implementing Standards – Annex I. esma.europa.eu, Report ESMA/2015/1464, September 2015. Archived at perma.cc/ZLX9-FGQ3 ↩︎
Luke Bigum. Solving MiFID II Clock Synchronisation With Minimum Spend (Part 1). catach.blogspot.com, November 2015. Archived at perma.cc/4J5W-FNM4 ↩︎
Oleg Obleukhov and Ahmad Byagowi. How Precision Time Protocol is being deployed at Meta. engineering.fb.com, November 2022. Archived at perma.cc/29G6-UJNW ↩︎
John Wiseman. gpsjam.org, July 2022. ↩︎
Josh Levinson, Julien Ridoux, and Chris Munns. It’s About Time: Microsecond-Accurate Clocks on Amazon EC2 Instances. aws.amazon.com, November 2023. Archived at perma.cc/56M6-5VMZ ↩︎
Kyle Kingsbury. Call Me Maybe: Cassandra. aphyr.com, September 2013. Archived at perma.cc/4MBR-J96V ↩︎ ↩︎ ↩︎
John Daily. Clocks Are Bad, or, Welcome to the Wonderful World of Distributed Systems. riak.com, November 2013. Archived at perma.cc/4XB5-UCXY ↩︎ ↩︎
Marc Brooker. It’s About Time! brooker.co.za, November 2023. Archived at perma.cc/N6YK-DRPA ↩︎
Kyle Kingsbury. The Trouble with Timestamps. aphyr.com, October 2013. Archived at perma.cc/W3AM-5VAV ↩︎
Leslie Lamport. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, volume 21, issue 7, pages 558–565, July 1978. doi:10.1145/359545.359563 ↩︎
Justin Sheehy. There Is No Now: Problems With Simultaneity in Distributed Systems. ACM Queue, volume 13, issue 3, pages 36–41, March 2015. doi:10.1145/2733108 ↩︎
Murat Demirbas. Spanner: Google’s Globally-Distributed Database. muratbuffalo.blogspot.co.uk, July 2013. Archived at perma.cc/6VWR-C9WB ↩︎
Dahlia Malkhi and Jean-Philippe Martin. Spanner’s Concurrency Control. ACM SIGACT News, volume 44, issue 3, pages 73–77, September 2013. doi:10.1145/2527748.2527767 ↩︎
Franck Pachot. Achieving Precise Clock Synchronization on AWS. yugabyte.com, December 2024. Archived at perma.cc/UYM6-RNBS ↩︎
Spencer Kimball. Living Without Atomic Clocks: Where CockroachDB and Spanner diverge. cockroachlabs.com, January 2022. Archived at perma.cc/AWZ7-RXFT ↩︎
Murat Demirbas. Use of Time in Distributed Databases (part 4): Synchronized clocks in production databases. muratbuffalo.blogspot.com, January 2025. Archived at perma.cc/9WNX-Q9U3 ↩︎
Cary G. Gray and David R. Cheriton. Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency. At 12th ACM Symposium on Operating Systems Principles (SOSP), December 1989. doi:10.1145/74850.74870 ↩︎
Daniel Sturman, Scott Delap, Max Ross, et al. Roblox Return to Service. corp.roblox.com, January 2022. Archived at perma.cc/8ALT-WAS4 ↩︎
Todd Lipcon. Avoiding Full GCs with MemStore-Local Allocation Buffers. slideshare.net, February 2011. Archived at https://perma.cc/CH62-2EWJ ↩︎
Christopher Clark, Keir Fraser, Steven Hand, Jacob Gorm Hansen, Eric Jul, Christian Limpach, Ian Pratt, and Andrew Warfield. Live Migration of Virtual Machines. At 2nd USENIX Symposium on Symposium on Networked Systems Design & Implementation (NSDI), May 2005. ↩︎
Mike Shaver. fsyncers and Curveballs. shaver.off.net, May 2008. Archived at archive.org ↩︎
Zhenyun Zhuang and Cuong Tran. Eliminating Large JVM GC Pauses Caused by Background IO Traffic. engineering.linkedin.com, February 2016. Archived at perma.cc/ML2M-X9XT ↩︎
Martin Thompson. Java Garbage Collection Distilled. mechanical-sympathy.blogspot.co.uk, July 2013. Archived at perma.cc/DJT3-NQLQ ↩︎ ↩︎
David Terei and Amit Levy. Blade: A Data Center Garbage Collector. arXiv:1504.02578, April 2015. ↩︎
Martin Maas, Tim Harris, Krste Asanović, and John Kubiatowicz. Trash Day: Coordinating Garbage Collection in Distributed Systems. At 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎
Martin Fowler. The LMAX Architecture. martinfowler.com, July 2011. Archived at perma.cc/5AV4-N6RJ ↩︎
Joseph Y. Halpern and Yoram Moses. Knowledge and common knowledge in a distributed environment. Journal of the ACM (JACM), volume 37, issue 3, pages 549–587, July 1990. doi:10.1145/79147.79161 ↩︎ ↩︎
Chuzhe Tang, Zhaoguo Wang, Xiaodong Zhang, Qianmian Yu, Binyu Zang, Haibing Guan, and Haibo Chen. Ad Hoc Transactions in Web Applications: The Good, the Bad, and the Ugly. At ACM International Conference on Management of Data (SIGMOD), June 2022. doi:10.1145/3514221.3526120 ↩︎
Flavio P. Junqueira and Benjamin Reed. ZooKeeper: Distributed Process Coordination. O’Reilly Media, 2013. ISBN: 978-1-449-36130-3 ↩︎ ↩︎
Enis Söztutar. HBase and HDFS: Understanding Filesystem Usage in HBase. At HBaseCon, June 2013. Archived at perma.cc/4DXR-9P88 ↩︎
SUSE LLC. SUSE Linux Enterprise High Availability 15 SP6 Administration Guide, Section 12: Fencing and STONITH. documentation.suse.com, March 2025. Archived at perma.cc/8LAR-EL9D ↩︎
Mike Burrows. The Chubby Lock Service for Loosely-Coupled Distributed Systems. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩︎
Kyle Kingsbury. etcd 3.4.3. jepsen.io, January 2020. Archived at perma.cc/2P3Y-MPWU ↩︎
Ensar Basri Kahveci. Distributed Locks are Dead; Long Live Distributed Locks! hazelcast.com, April 2019. Archived at perma.cc/7FS5-LDXE ↩︎
Martin Kleppmann. How to do distributed locking. martin.kleppmann.com, February 2016. Archived at perma.cc/Y24W-YQ5L ↩︎
Salvatore Sanfilippo. Is Redlock safe? antirez.com, February 2016. Archived at perma.cc/B6GA-9Q6A ↩︎
Gunnar Morling. Leader Election With S3 Conditional Writes. www.morling.dev, August 2024. Archived at perma.cc/7V2N-J78Y ↩︎
Leslie Lamport, Robert Shostak, and Marshall Pease. The Byzantine Generals Problem. ACM Transactions on Programming Languages and Systems (TOPLAS), volume 4, issue 3, pages 382–401, July 1982. doi:10.1145/357172.357176 ↩︎
Jim N. Gray. Notes on Data Base Operating Systems. in Operating Systems: An Advanced Course, Lecture Notes in Computer Science, volume 60, edited by R. Bayer, R. M. Graham, and G. Seegmüller, pages 393–481, Springer-Verlag, 1978. ISBN: 978-3-540-08755-7. Archived at perma.cc/7S9M-2LZU ↩︎
Brian Palmer. How Complicated Was the Byzantine Empire? slate.com, October 2011. Archived at perma.cc/AN7X-FL3N ↩︎
Leslie Lamport. My Writings. lamport.azurewebsites.net, December 2014. Archived at perma.cc/5NNM-SQGR ↩︎
John Rushby. Bus Architectures for Safety-Critical Embedded Systems. At 1st International Workshop on Embedded Software (EMSOFT), October 2001. doi:10.1007/3-540-45449-7_22 ↩︎ ↩︎
Jake Edge. ELC: SpaceX Lessons Learned. lwn.net, March 2013. Archived at perma.cc/AYX8-QP5X ↩︎
Shehar Bano, Alberto Sonnino, Mustafa Al-Bassam, Sarah Azouvi, Patrick McCorry, Sarah Meiklejohn, and George Danezis. SoK: Consensus in the Age of Blockchains. At 1st ACM Conference on Advances in Financial Technologies (AFT), October 2019. doi:10.1145/3318041.3355458 ↩︎
Ezra Feilden, Adi Oltean, and Philip Johnston. Why we should train AI in space. White Paper, starcloud.com, September 2024. Archived at perma.cc/7Y3S-8UB6 ↩︎
James Mickens. The Saddest Moment. USENIX ;login, May 2013. Archived at perma.cc/T7BZ-XCFR ↩︎
Martin Kleppmann and Heidi Howard. Byzantine Eventual Consistency and the Fundamental Limits of Peer-to-Peer Databases. arxiv.org, December 2020. doi:10.48550/arXiv.2012.00472 ↩︎
Martin Kleppmann. Making CRDTs Byzantine Fault Tolerant. At 9th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC), April 2022. doi:10.1145/3517209.3524042 ↩︎
Evan Gilman. The Discovery of Apache ZooKeeper’s Poison Packet. pagerduty.com, May 2015. Archived at perma.cc/RV6L-Y5CQ ↩︎ ↩︎
Jonathan Stone and Craig Partridge. When the CRC and TCP Checksum Disagree. At ACM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM), August 2000. doi:10.1145/347059.347561 ↩︎
Evan Jones. How Both TCP and Ethernet Checksums Fail. evanjones.ca, October 2015. Archived at perma.cc/9T5V-B8X5 ↩︎
Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer. Consensus in the Presence of Partial Synchrony. Journal of the ACM, volume 35, issue 2, pages 288–323, April 1988. doi:10.1145/42282.42283 ↩︎ ↩︎ ↩︎
Richard D. Schlichting and Fred B. Schneider. Fail-stop processors: an approach to designing fault-tolerant computing systems. ACM Transactions on Computer Systems (TOCS), volume 1, issue 3, pages 222–238, August 1983. doi:10.1145/357369.357371 ↩︎
Thanh Do, Mingzhe Hao, Tanakorn Leesatapornwongsa, Tiratat Patana-anake, and Haryadi S. Gunawi. Limplock: Understanding the Impact of Limpware on Scale-out Cloud Systems. At 4th ACM Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523627 ↩︎
Josh Snyder and Joseph Lynch. Garbage collecting unhealthy JVMs, a proactive approach. Netflix Technology Blog, netflixtechblog.medium.com, November 2019. Archived at perma.cc/8BTA-N3YB ↩︎
Haryadi S. Gunawi, Riza O. Suminto, Russell Sears, Casey Golliher, Swaminathan Sundararaman, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, Gary Grider, Parks M. Fields, Kevin Harms, Robert B. Ross, Andree Jacobson, Robert Ricci, Kirk Webb, Peter Alvaro, H. Birali Runesha, Mingzhe Hao, and Huaicheng Li. Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. At 16th USENIX Conference on File and Storage Technologies, February 2018. ↩︎
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. At 16th Workshop on Hot Topics in Operating Systems (HotOS), May 2017. doi:10.1145/3102980.3103005 ↩︎
Chang Lou, Peng Huang, and Scott Smith. Understanding, Detecting and Localizing Partial Failures in Large System Software. At 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), February 2020. ↩︎
Peter Bailis and Ali Ghodsi. Eventual Consistency Today: Limitations, Extensions, and Beyond. ACM Queue, volume 11, issue 3, pages 55-63, March 2013. doi:10.1145/2460276.2462076 ↩︎
Bowen Alpern and Fred B. Schneider. Defining Liveness. Information Processing Letters, volume 21, issue 4, pages 181–185, October 1985. doi:10.1016/0020-0190(85)90056-0 ↩︎
Flavio P. Junqueira. Dude, Where’s My Metadata? fpj.me, May 2015. Archived at perma.cc/D2EU-Y9S5 ↩︎
Scott Sanders. January 28th Incident Report. github.com, February 2016. Archived at perma.cc/5GZR-88TV ↩︎
Jay Kreps. A Few Notes on Kafka and Jepsen. blog.empathybox.com, September 2013. perma.cc/XJ5C-F583 ↩︎
Marc Brooker and Ankush Desai. Systems Correctness Practices at AWS. Queue, Volume 22, Issue 6, November/December 2024. doi:10.1145/3712057 ↩︎
Andrey Satarin. Testing Distributed Systems: Curated list of resources on testing distributed systems. asatarin.github.io. Archived at perma.cc/U5V8-XP24 ↩︎
Jack Vanlightly. Verifying Kafka transactions - Diary entry 2 - Writing an initial TLA+ spec. jack-vanlightly.com, December 2024. Archived at perma.cc/NSQ8-MQ5N ↩︎
Siddon Tang. From Chaos to Order — Tools and Techniques for Testing TiDB, A Distributed NewSQL Database. pingcap.com, April 2018. Archived at perma.cc/5EJB-R29F ↩︎
Nathan VanBenschoten. Parallel Commits: An atomic commit protocol for globally distributed transactions. cockroachlabs.com, November 2019. Archived at perma.cc/5FZ7-QK6J ↩︎
Jack Vanlightly. Paper: VR Revisited - State Transfer (part 3). jack-vanlightly.com, December 2022. Archived at perma.cc/KNK3-K6WS ↩︎
Hillel Wayne. What if the spec doesn’t match the code? buttondown.com, March 2024. Archived at perma.cc/8HEZ-KHER ↩︎
Lingzhi Ouyang, Xudong Sun, Ruize Tang, Yu Huang, Madhav Jivrajani, Xiaoxing Ma, Tianyin Xu. Multi-Grained Specifications for Distributed System Model Checking and Verification. At 20th European Conference on Computer Systems (EuroSys), March 2025. doi:10.1145/3689031.3696069 ↩︎
Yury Izrailevsky and Ariel Tseitlin. The Netflix Simian Army. netflixtechblog.com, July, 2011. Archived at perma.cc/M3NY-FJW6 ↩︎
Kyle Kingsbury. Jepsen: On the perils of network partitions. aphyr.com, May, 2013. Archived at perma.cc/W98G-6HQP ↩︎
Kyle Kingsbury. Jepsen Analyses. jepsen.io, 2024. Archived at perma.cc/8LDN-D2T8 ↩︎
Rupak Majumdar and Filip Niksic. Why is random testing effective for partition tolerance bugs? Proceedings of the ACM on Programming Languages (PACMPL), volume 2, issue POPL, article no. 46, December 2017. doi:10.1145/3158134 ↩︎
FoundationDB project authors. Simulation and Testing. apple.github.io. Archived at perma.cc/NQ3L-PM4C ↩︎
Alex Kladov. Simulation Testing For Liveness. tigerbeetle.com, July 2023. Archived at perma.cc/RKD4-HGCR ↩︎