8. Transactions
Một số tác giả cho rằng two-phase commit (cam kết hai giai đoạn) tổng quát quá tốn kém để hỗ trợ, vì những vấn đề về hiệu năng hoặc tính khả dụng mà nó mang lại. Chúng tôi cho rằng tốt hơn là để các lập trình viên ứng dụng tự xử lý các vấn đề hiệu năng do sử dụng quá nhiều transaction khi xuất hiện điểm nghẽn, thay vì luôn phải lập trình vòng quanh sự thiếu vắng của transaction.
James Corbett et al., Spanner: Google’s Globally-Distributed Database (2012)
Trong thực tế khắc nghiệt của các hệ thống dữ liệu, nhiều điều có thể xảy ra sai:
- Phần mềm hoặc phần cứng cơ sở dữ liệu có thể gặp sự cố bất cứ lúc nào (kể cả giữa chừng một thao tác ghi).
- Ứng dụng có thể bị treo bất cứ lúc nào (kể cả giữa chừng một chuỗi thao tác).
- Gián đoạn mạng có thể đột ngột ngắt kết nối ứng dụng khỏi cơ sở dữ liệu, hoặc ngắt kết nối giữa các node cơ sở dữ liệu với nhau.
- Nhiều client có thể ghi vào cơ sở dữ liệu cùng lúc, ghi đè lên thay đổi của nhau.
- Một client có thể đọc dữ liệu không hợp lệ vì dữ liệu đó mới chỉ được cập nhật một phần.
- Race condition (điều kiện tranh chấp) giữa các client có thể gây ra những lỗi bất ngờ.
Để đảm bảo độ tin cậy, một hệ thống phải xử lý được các lỗi này và đảm bảo chúng không gây ra sự cố nghiêm trọng cho toàn bộ hệ thống. Tuy nhiên, việc triển khai cơ chế chịu lỗi là rất nhiều công sức. Cần phải suy nghĩ cẩn thận về tất cả những gì có thể xảy ra sai, và kiểm thử nhiều để đảm bảo giải pháp thực sự hoạt động.
Hàng thập kỷ qua, transaction (giao dịch) là cơ chế được ưu tiên để đơn giản hóa những vấn đề này. Transaction là cách để một ứng dụng nhóm nhiều thao tác đọc và ghi lại thành một đơn vị logic. Về mặt khái niệm, tất cả các thao tác đọc và ghi trong một transaction được thực thi như một thao tác duy nhất: hoặc toàn bộ transaction thành công (commit, cam kết) hoặc thất bại (abort, hủy bỏ, hay rollback, khôi phục). Nếu thất bại, ứng dụng có thể thử lại một cách an toàn. Với transaction, việc xử lý lỗi trở nên đơn giản hơn nhiều cho ứng dụng, vì nó không cần lo lắng về lỗi từng phần, tức là trường hợp một số thao tác thành công và một số thất bại (vì bất kỳ lý do gì).
Nếu bạn đã làm việc với transaction nhiều năm, chúng có vẻ hiển nhiên, nhưng chúng ta không nên coi chúng là điều đương nhiên. Transaction không phải là quy luật tự nhiên; chúng được tạo ra với một mục đích cụ thể, đó là đơn giản hóa mô hình lập trình cho các ứng dụng truy cập cơ sở dữ liệu. Bằng cách sử dụng transaction, ứng dụng có thể bỏ qua một số kịch bản lỗi tiềm ẩn và các vấn đề đồng thời, vì cơ sở dữ liệu tự xử lý thay (chúng ta gọi đây là safety guarantees, đảm bảo an toàn).
Không phải mọi ứng dụng đều cần transaction, và đôi khi có lợi thế khi yếu hóa các đảm bảo của transaction hoặc từ bỏ chúng hoàn toàn (ví dụ, để đạt hiệu năng cao hơn hoặc tính khả dụng cao hơn). Một số tính chất an toàn có thể đạt được mà không cần transaction. Mặt khác, transaction có thể ngăn chặn nhiều rắc rối: ví dụ, nguyên nhân kỹ thuật đằng sau vụ bê bối Post Office Horizon (xem “How Important Is Reliability?”) có lẽ là do thiếu ACID transaction trong hệ thống kế toán cơ bản 1.
Làm thế nào để biết mình có cần transaction không? Để trả lời câu hỏi đó, trước tiên chúng ta cần hiểu chính xác những đảm bảo an toàn mà transaction có thể cung cấp, và những chi phí liên quan đến chúng. Mặc dù transaction trông có vẻ đơn giản ngay từ cái nhìn đầu tiên, thực tế có rất nhiều chi tiết tinh tế nhưng quan trọng.
Trong chương này, chúng ta sẽ xem xét nhiều ví dụ về những điều có thể xảy ra sai, và khám phá các thuật toán mà cơ sở dữ liệu sử dụng để bảo vệ khỏi những vấn đề đó. Chúng ta sẽ đi sâu đặc biệt vào lĩnh vực kiểm soát đồng thời (concurrency control), thảo luận về các loại race condition có thể xảy ra và cách cơ sở dữ liệu triển khai các mức độ isolation (cô lập) như read committed, snapshot isolation, và serializability.
Kiểm soát đồng thời có liên quan đến cả cơ sở dữ liệu đơn node lẫn phân tán. Ở phần sau trong chương này, trong “Distributed Transactions”, chúng ta sẽ xem xét giao thức two-phase commit (cam kết hai giai đoạn) và thách thức của việc đảm bảo tính nguyên tử trong một distributed transaction (giao dịch phân tán).
What Exactly Is a Transaction?
Hầu hết tất cả các cơ sở dữ liệu quan hệ hiện nay, và một số cơ sở dữ liệu phi quan hệ, đều hỗ trợ transaction. Phần lớn trong số chúng tuân theo phong cách được giới thiệu vào năm 1975 bởi IBM System R, cơ sở dữ liệu SQL đầu tiên 2 3 4. Mặc dù một số chi tiết triển khai đã thay đổi, ý tưởng chung hầu như vẫn giữ nguyên trong 50 năm qua: hỗ trợ transaction trong MySQL, PostgreSQL, Oracle, SQL Server, v.v. có sự tương đồng đáng kinh ngạc với System R.
Vào cuối những năm 2000, các cơ sở dữ liệu phi quan hệ (NoSQL) bắt đầu được ưa chuộng. Chúng nhắm đến việc cải thiện hiện trạng của cơ sở dữ liệu quan hệ bằng cách cung cấp nhiều mô hình dữ liệu mới (xem Chương 3), và tích hợp sẵn replication (sao chép) (Chương 6) và sharding (phân mảnh) (Chương 7) theo mặc định. Transaction là nạn nhân chính của phong trào này: nhiều cơ sở dữ liệu thế hệ này đã từ bỏ transaction hoàn toàn, hoặc định nghĩa lại từ này để mô tả một tập đảm bảo yếu hơn nhiều so với trước đây.
Sự cường điệu xung quanh các cơ sở dữ liệu NoSQL phân tán đã dẫn đến niềm tin phổ biến rằng transaction về cơ bản không thể mở rộng được, và bất kỳ hệ thống quy mô lớn nào cũng phải từ bỏ transaction để duy trì hiệu năng tốt và tính khả dụng cao. Gần đây hơn, niềm tin đó đã được chứng minh là sai. Các cơ sở dữ liệu “NewSQL” như CockroachDB 5, TiDB 6, Spanner 7, FoundationDB 8, và Yugabyte đã chứng minh rằng các hệ thống transactional có thể mở rộng quy mô với lượng dữ liệu lớn và thông lượng cao. Các hệ thống này kết hợp sharding với consensus protocol (giao thức đồng thuận) (Chương 10) để cung cấp đảm bảo ACID mạnh ở quy mô lớn.
Tuy nhiên, điều đó không có nghĩa là mọi hệ thống đều phải có transaction: giống như mọi lựa chọn thiết kế kỹ thuật khác, transaction có ưu điểm và hạn chế. Để hiểu những đánh đổi đó, hãy đi sâu vào chi tiết các đảm bảo mà transaction có thể cung cấp, cả trong hoạt động bình thường lẫn trong các hoàn cảnh cực đoan (nhưng thực tế).
The Meaning of ACID
Các đảm bảo an toàn do transaction cung cấp thường được mô tả bằng từ viết tắt nổi tiếng ACID, viết tắt của Atomicity (tính nguyên tử), Consistency (tính nhất quán), Isolation (tính cô lập) và Durability (tính bền vững). Nó được đặt ra vào năm 1983 bởi Theo Härder và Andreas Reuter 9 trong nỗ lực thiết lập thuật ngữ chính xác cho các cơ chế chịu lỗi trong cơ sở dữ liệu.
Tuy nhiên, trong thực tế, triển khai ACID của cơ sở dữ liệu này không bằng triển khai của cơ sở dữ liệu khác. Ví dụ, như chúng ta sẽ thấy, có rất nhiều sự mơ hồ xung quanh ý nghĩa của isolation 10. Ý tưởng tổng quát là đúng, nhưng chi tiết mới là điều quan trọng. Ngày nay, khi một hệ thống tuyên bố “tuân thủ ACID,” không rõ ràng những đảm bảo nào bạn thực sự có thể mong đợi. ACID đáng tiếc đã trở thành một thuật ngữ marketing.
(Các hệ thống không đáp ứng tiêu chí ACID đôi khi được gọi là BASE, viết tắt của Basically Available (cơ bản khả dụng), Soft state (trạng thái mềm) và Eventual consistency (nhất quán sau cùng) 11. Điều này còn mơ hồ hơn cả định nghĩa của ACID. Có vẻ như định nghĩa hợp lý duy nhất của BASE là “không phải ACID,” tức là nó có thể có nghĩa là hầu hết bất cứ điều gì bạn muốn.)
Hãy đi sâu vào các định nghĩa của atomicity, consistency, isolation và durability, vì điều này sẽ giúp chúng ta tinh chỉnh khái niệm về transaction.
Atomicity
Nói chung, atomic (nguyên tử) đề cập đến thứ gì đó không thể chia nhỏ thành các phần nhỏ hơn. Từ này có ý nghĩa tương tự nhưng tinh tế khác nhau trong các lĩnh vực khác nhau của điện toán. Ví dụ, trong lập trình đa luồng, nếu một thread thực thi một thao tác atomic, điều đó có nghĩa là không có cách nào để một thread khác nhìn thấy kết quả chưa hoàn chỉnh của thao tác đó. Hệ thống chỉ có thể ở trạng thái trước thao tác hoặc sau thao tác, không ở giữa chừng.
Ngược lại, trong ngữ cảnh ACID, atomicity không liên quan đến đồng thời. Nó không mô tả điều gì xảy ra nếu nhiều tiến trình cố gắng truy cập cùng một dữ liệu cùng lúc, vì điều đó được bao gồm trong chữ I, cho isolation (xem “Isolation”).
Thay vào đó, ACID atomicity mô tả điều gì xảy ra nếu một client muốn thực hiện nhiều thao tác ghi, nhưng một lỗi xảy ra sau khi một số thao tác ghi đã được xử lý, chẳng hạn như một tiến trình bị crash, một kết nối mạng bị gián đoạn, một đĩa bị đầy, hoặc một ràng buộc toàn vẹn bị vi phạm. Nếu các thao tác ghi được nhóm lại thành một atomic transaction, và transaction không thể hoàn thành (committed, cam kết) do lỗi, thì transaction sẽ bị aborted (hủy bỏ) và cơ sở dữ liệu phải hủy hoặc hoàn tác bất kỳ thao tác ghi nào nó đã thực hiện cho đến nay trong transaction đó.
Nếu không có atomicity, khi xảy ra lỗi giữa chừng khi thực hiện nhiều thay đổi, rất khó để biết thay đổi nào đã có hiệu lực và thay đổi nào chưa. Ứng dụng có thể thử lại, nhưng điều đó có nguy cơ thực hiện cùng một thay đổi hai lần, dẫn đến dữ liệu trùng lặp hoặc sai. Atomicity đơn giản hóa vấn đề này: nếu một transaction bị abort, ứng dụng có thể chắc chắn rằng nó không thay đổi gì cả, vì vậy có thể thử lại một cách an toàn.
Khả năng abort một transaction khi có lỗi và hủy bỏ tất cả các thao tác ghi từ transaction đó là đặc điểm xác định của ACID atomicity. Có lẽ abortability (khả năng hủy bỏ) sẽ là thuật ngữ tốt hơn so với atomicity, nhưng chúng ta sẽ tiếp tục dùng atomicity vì đó là từ thông dụng.
Consistency
Từ consistency (nhất quán) bị dùng quá nhiều nghĩa:
- Trong Chương 6 chúng ta đã thảo luận về replica consistency (nhất quán bản sao) và vấn đề eventual consistency (nhất quán sau cùng) xuất hiện trong các hệ thống replicated bất đồng bộ (xem “Problems with Replication Lag”).
- Một consistent snapshot (ảnh chụp nhất quán) của cơ sở dữ liệu, ví dụ để sao lưu, là một ảnh chụp của toàn bộ cơ sở dữ liệu như nó tồn tại tại một thời điểm. Chính xác hơn, nó nhất quán với quan hệ happens-before (xem “The “happens-before” relation and concurrency”): tức là, nếu ảnh chụp chứa một giá trị được ghi tại một thời điểm cụ thể, thì nó cũng phản ánh tất cả các thao tác ghi xảy ra trước giá trị đó.
- Consistent hashing (băm nhất quán) là cách tiếp cận sharding mà một số hệ thống sử dụng để tái cân bằng (xem “Consistent hashing”).
- Trong định lý CAP (xem Chương 10), từ consistency được dùng để có nghĩa là linearizability (xem “Linearizability”).
- Trong ngữ cảnh ACID, consistency đề cập đến khái niệm dành riêng cho ứng dụng về cơ sở dữ liệu đang ở “trạng thái tốt.”
Thật không may khi cùng một từ được dùng với ít nhất năm nghĩa khác nhau.
Ý tưởng của ACID consistency là bạn có những phát biểu nhất định về dữ liệu của mình (invariants, bất biến) phải luôn đúng, ví dụ, trong một hệ thống kế toán, các khoản ghi có và ghi nợ trên tất cả các tài khoản phải luôn cân bằng. Nếu một transaction bắt đầu với một cơ sở dữ liệu hợp lệ theo các bất biến này, và bất kỳ thao tác ghi nào trong transaction đều bảo toàn tính hợp lệ đó, thì bạn có thể chắc chắn rằng các bất biến luôn được thỏa mãn. (Một bất biến có thể bị vi phạm tạm thời trong quá trình thực thi transaction, nhưng phải được thỏa mãn lại khi transaction commit.)
Nếu bạn muốn cơ sở dữ liệu thực thi các bất biến của mình, bạn cần khai báo chúng là constraints (ràng buộc) như một phần của schema. Ví dụ, foreign key constraint (ràng buộc khóa ngoại), uniqueness constraint (ràng buộc duy nhất), hoặc check constraint (ràng buộc kiểm tra, hạn chế các giá trị có thể xuất hiện trong một hàng riêng lẻ) thường được sử dụng để mô hình hóa các loại bất biến cụ thể. Các yêu cầu nhất quán phức tạp hơn đôi khi có thể được mô hình hóa bằng trigger hoặc materialized view 12.
Tuy nhiên, các bất biến phức tạp có thể khó hoặc không thể mô hình hóa bằng các ràng buộc mà cơ sở dữ liệu thường cung cấp. Trong trường hợp đó, trách nhiệm của ứng dụng là định nghĩa các transaction của mình đúng cách để chúng bảo toàn nhất quán. Nếu bạn ghi dữ liệu xấu vi phạm các bất biến của mình, nhưng bạn chưa khai báo các bất biến đó, cơ sở dữ liệu không thể ngăn bạn. Do đó, chữ C trong ACID thường phụ thuộc vào cách ứng dụng sử dụng cơ sở dữ liệu, và nó không phải là thuộc tính của cơ sở dữ liệu đơn thuần.
Isolation
Hầu hết các cơ sở dữ liệu được truy cập bởi nhiều client cùng một lúc. Điều đó không phải là vấn đề nếu chúng đọc và ghi các phần khác nhau của cơ sở dữ liệu, nhưng nếu chúng truy cập cùng các bản ghi cơ sở dữ liệu, bạn có thể gặp phải vấn đề đồng thời (race condition).
Hình 8-1 là một ví dụ đơn giản về loại vấn đề này. Giả sử bạn có hai client đồng thời tăng một bộ đếm được lưu trữ trong cơ sở dữ liệu. Mỗi client cần đọc giá trị hiện tại, cộng thêm 1, và ghi giá trị mới trở lại (giả sử không có thao tác increment tích hợp trong cơ sở dữ liệu). Trong Hình 8-1 bộ đếm lẽ ra phải tăng từ 42 lên 44, vì hai thao tác increment đã xảy ra, nhưng thực tế chỉ tăng lên 43 do race condition.
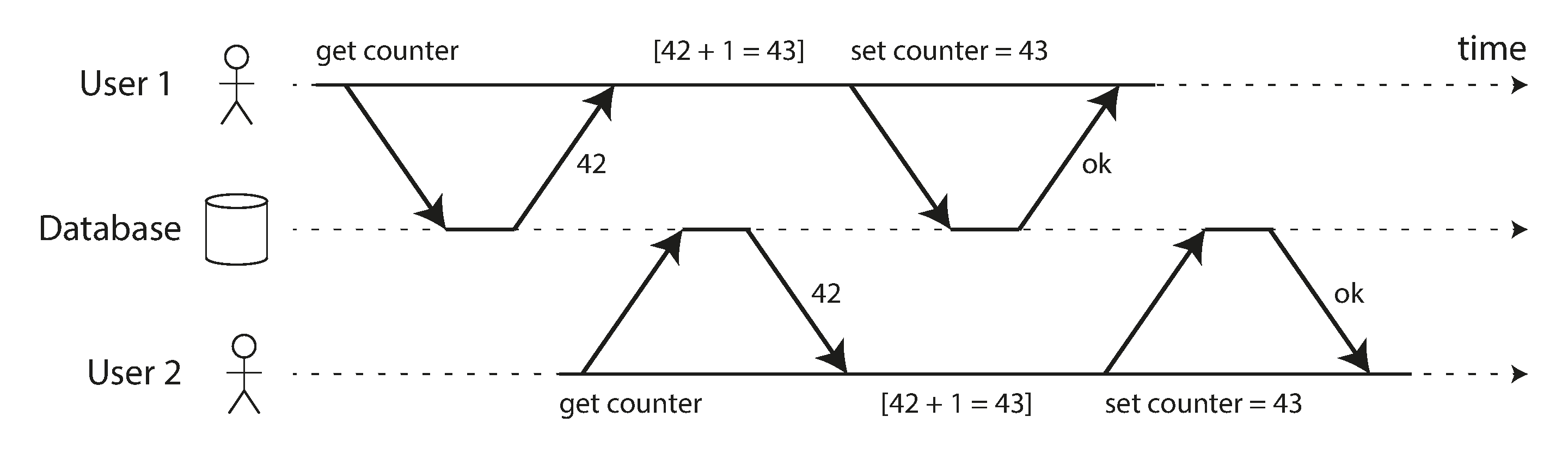
Isolation (cô lập) theo nghĩa ACID có nghĩa là các transaction thực thi đồng thời được cô lập với nhau: chúng không thể giẫm lên chân nhau. Các sách giáo khoa cơ sở dữ liệu cổ điển hình thức hóa isolation là serializability (khả năng tuần tự hóa), có nghĩa là mỗi transaction có thể giả vờ rằng nó là transaction duy nhất đang chạy trên toàn bộ cơ sở dữ liệu. Cơ sở dữ liệu đảm bảo rằng khi các transaction đã commit, kết quả giống như thể chúng đã chạy serially (tuần tự, lần lượt từng cái), mặc dù trên thực tế chúng có thể đã chạy đồng thời 13.
Tuy nhiên, serializability có chi phí hiệu năng. Trong thực tế, nhiều cơ sở dữ liệu sử dụng các dạng isolation yếu hơn serializability: tức là, chúng cho phép các transaction đồng thời can thiệp vào nhau theo những cách hạn chế. Một số cơ sở dữ liệu phổ biến, chẳng hạn như Oracle, thậm chí không triển khai nó (Oracle có mức isolation được gọi là “serializable,” nhưng thực tế nó triển khai snapshot isolation, một đảm bảo yếu hơn serializability 10 14). Điều này có nghĩa là một số loại race condition vẫn có thể xảy ra. Chúng ta sẽ khám phá snapshot isolation và các dạng isolation khác trong “Weak Isolation Levels”.
Durability
Mục đích của một hệ thống cơ sở dữ liệu là cung cấp nơi lưu trữ dữ liệu an toàn mà không lo mất mát. Durability (bền vững) là cam kết rằng một khi transaction đã commit thành công, bất kỳ dữ liệu nào nó đã ghi sẽ không bị mất, kể cả khi có lỗi phần cứng hoặc cơ sở dữ liệu bị crash.
Trong cơ sở dữ liệu đơn node, durability thường có nghĩa là dữ liệu đã được ghi vào bộ nhớ không bay hơi (nonvolatile storage) như ổ cứng hoặc SSD. Các thao tác ghi file thông thường thường được đệm trong bộ nhớ trước khi được gửi lên đĩa sau đó, nghĩa là chúng sẽ bị mất nếu có mất điện đột ngột; do đó nhiều cơ sở dữ liệu sử dụng lệnh gọi hệ thống fsync() để đảm bảo dữ liệu thực sự đã được ghi vào đĩa. Cơ sở dữ liệu thường cũng có write-ahead log hoặc tương tự (xem “Making B-trees reliable”), cho phép chúng phục hồi trong trường hợp crash xảy ra giữa chừng một thao tác ghi.
Trong cơ sở dữ liệu replicated, durability có thể có nghĩa là dữ liệu đã được sao chép thành công đến một số node nhất định. Để cung cấp đảm bảo durability, cơ sở dữ liệu phải đợi cho đến khi các thao tác ghi hoặc sao chép này hoàn thành trước khi báo cáo một transaction đã commit thành công. Tuy nhiên, như đã thảo luận trong “Reliability and Fault Tolerance”, durability hoàn hảo không tồn tại: nếu tất cả ổ cứng và tất cả các bản sao lưu của bạn bị phá hủy cùng một lúc, rõ ràng cơ sở dữ liệu không thể làm gì để cứu bạn.
REPLICATION AND DURABILITY
Trong lịch sử, durability có nghĩa là ghi vào băng lưu trữ. Sau đó nó được hiểu là ghi vào đĩa hoặc SSD. Gần đây hơn, nó được điều chỉnh để có nghĩa là replication. Triển khai nào tốt hơn?
Sự thật là, không có gì hoàn hảo:
- Nếu bạn ghi vào đĩa và máy bị hỏng, mặc dù dữ liệu không bị mất, nó không thể truy cập cho đến khi bạn sửa máy hoặc chuyển đĩa sang máy khác. Các hệ thống replicated có thể duy trì tính khả dụng.
- Một correlated fault (lỗi tương quan), ví dụ mất điện hoặc một bug làm crash mọi node trên một đầu vào cụ thể, có thể làm tắt tất cả các replica cùng lúc (xem “Reliability and Fault Tolerance”), mất bất kỳ dữ liệu nào chỉ có trong bộ nhớ. Do đó, ghi vào đĩa vẫn có liên quan đối với các cơ sở dữ liệu replicated.
- Trong một hệ thống replicated bất đồng bộ, các thao tác ghi gần đây có thể bị mất khi leader (nút chính) không khả dụng (xem “Handling Node Outages”).
- Khi điện bị cắt đột ngột, SSD đặc biệt đã được chứng minh là đôi khi vi phạm các đảm bảo mà chúng được cho là cung cấp: ngay cả
fsynccũng không được đảm bảo hoạt động đúng 15. Firmware ổ đĩa có thể có lỗi, giống như bất kỳ phần mềm nào khác 16 17, ví dụ gây ra ổ đĩa bị lỗi chính xác sau 32.768 giờ hoạt động 18. Vàfsynckhó sử dụng đúng cách; ngay cả PostgreSQL cũng sử dụng nó không đúng trong hơn 20 năm 19 20 21. - Các tương tác tinh tế giữa storage engine (bộ máy lưu trữ) và triển khai filesystem có thể dẫn đến các lỗi khó theo dõi, và có thể gây ra các file trên đĩa bị hỏng sau khi crash 22 23. Lỗi filesystem trên một replica đôi khi có thể lan sang các replica khác 24.
- Dữ liệu trên đĩa có thể dần bị hỏng mà không bị phát hiện 25. Nếu dữ liệu đã bị hỏng một thời gian, các replica và các bản sao lưu gần đây cũng có thể bị hỏng. Trong trường hợp này, bạn sẽ cần cố gắng khôi phục dữ liệu từ một bản sao lưu lịch sử.
- Một nghiên cứu về SSD cho thấy giữa 30% và 80% ổ đĩa phát triển ít nhất một bad block trong bốn năm đầu hoạt động, và chỉ một số trong số đó có thể được sửa chữa bởi firmware 26. Ổ cứng từ tính có tỷ lệ bad sector thấp hơn, nhưng tỷ lệ hỏng hoàn toàn cao hơn so với SSD.
- Khi một SSD đã qua sử dụng nhiều (đã trải qua nhiều chu kỳ ghi/xóa) bị ngắt điện, nó có thể bắt đầu mất dữ liệu trong khoảng thời gian từ vài tuần đến vài tháng, tùy thuộc vào nhiệt độ 27. Điều này ít là vấn đề hơn đối với các ổ đĩa có mức mòn thấp hơn 28.
Trong thực tế, không có một kỹ thuật nào có thể cung cấp đảm bảo tuyệt đối. Chỉ có các kỹ thuật giảm thiểu rủi ro khác nhau, bao gồm ghi vào đĩa, sao chép đến các máy từ xa, và sao lưu, và chúng có thể và nên được sử dụng kết hợp với nhau. Như thường lệ, sáng suốt là đón nhận bất kỳ “đảm bảo” lý thuyết nào với một chút hoài nghi.
Single-Object and Multi-Object Operations
Tóm lại, trong ACID, atomicity và isolation mô tả những gì cơ sở dữ liệu nên làm nếu một client thực hiện nhiều thao tác ghi trong cùng một transaction:
- Atomicity
- Nếu xảy ra lỗi giữa chừng một chuỗi thao tác ghi, transaction phải bị abort, và các thao tác ghi đã thực hiện cho đến thời điểm đó phải bị hủy bỏ. Nói cách khác, cơ sở dữ liệu giải phóng bạn khỏi việc lo lắng về lỗi từng phần, bằng cách đưa ra đảm bảo tất cả hoặc không gì cả (all-or-nothing).
- Isolation
- Các transaction chạy đồng thời không nên can thiệp vào nhau. Ví dụ, nếu một transaction thực hiện nhiều thao tác ghi, thì một transaction khác sẽ thấy hoặc tất cả hoặc không có thao tác ghi nào, nhưng không phải một tập con.
Những định nghĩa này giả định rằng bạn muốn sửa đổi nhiều đối tượng (hàng, tài liệu, bản ghi) cùng một lúc. Các multi-object transaction (giao dịch đa đối tượng) như vậy thường cần thiết nếu nhiều phần dữ liệu cần được giữ đồng bộ. Hình 8-2 cho thấy một ví dụ từ ứng dụng email. Để hiển thị số lượng tin nhắn chưa đọc cho một người dùng, bạn có thể truy vấn như sau:
SELECT COUNT(*) FROM emails WHERE recipient_id = 2 AND unread_flag = true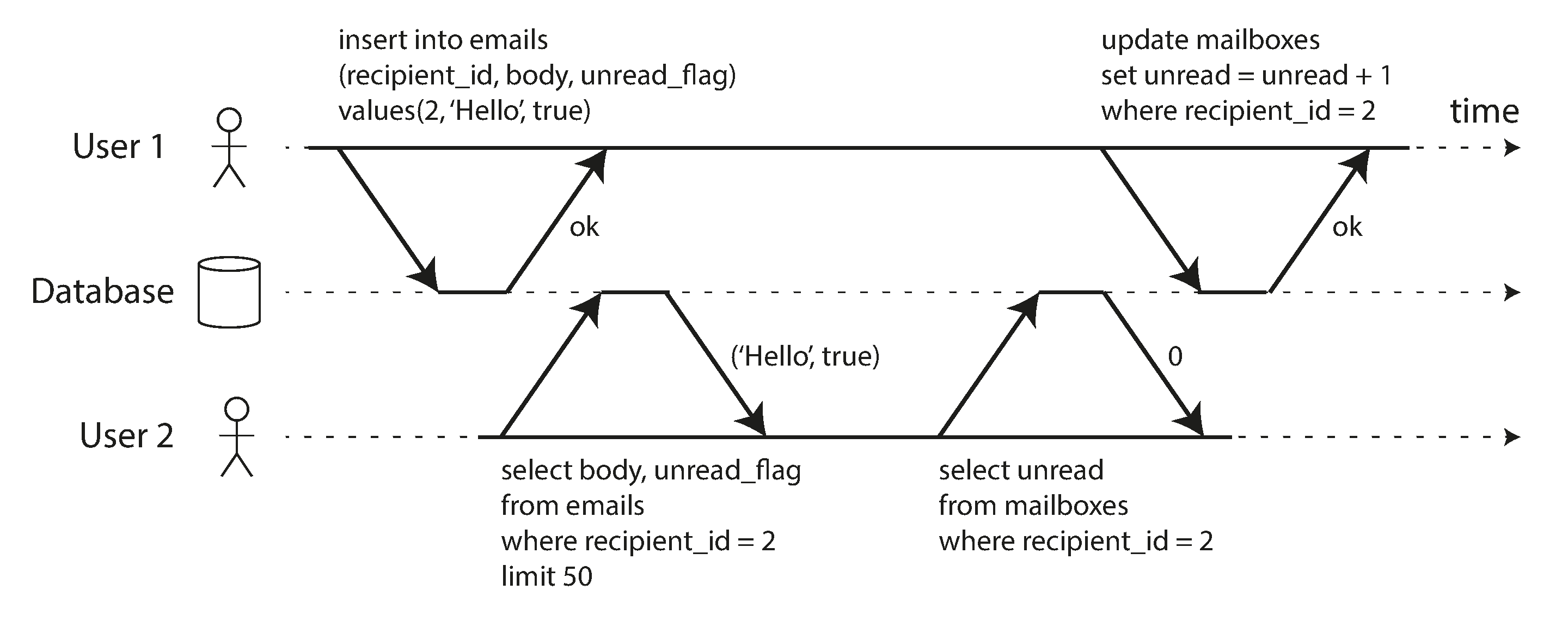
Tuy nhiên, bạn có thể thấy truy vấn này quá chậm nếu có nhiều email, và quyết định lưu trữ số lượng tin nhắn chưa đọc trong một trường riêng biệt (một dạng denormalization, được chúng ta thảo luận trong “Normalization, Denormalization, and Joins”). Bây giờ, mỗi khi có tin nhắn mới đến, bạn phải tăng bộ đếm chưa đọc, và mỗi khi một tin nhắn được đánh dấu là đã đọc, bạn cũng phải giảm bộ đếm chưa đọc.
Trong Hình 8-2, người dùng 2 gặp phải bất thường: danh sách hộp thư hiển thị có tin nhắn chưa đọc, nhưng bộ đếm hiển thị không có tin nhắn chưa đọc vì việc tăng bộ đếm chưa xảy ra. (Nếu bộ đếm không chính xác trong ứng dụng email có vẻ quá nhỏ nhặt, hãy nghĩ đến số dư tài khoản khách hàng thay vì bộ đếm chưa đọc, và một giao dịch thanh toán thay vì email.) Isolation sẽ ngăn chặn vấn đề này bằng cách đảm bảo người dùng 2 thấy cả email đã chèn và bộ đếm đã cập nhật, hoặc không thấy gì cả, nhưng không phải một điểm giữa chừng không nhất quán.
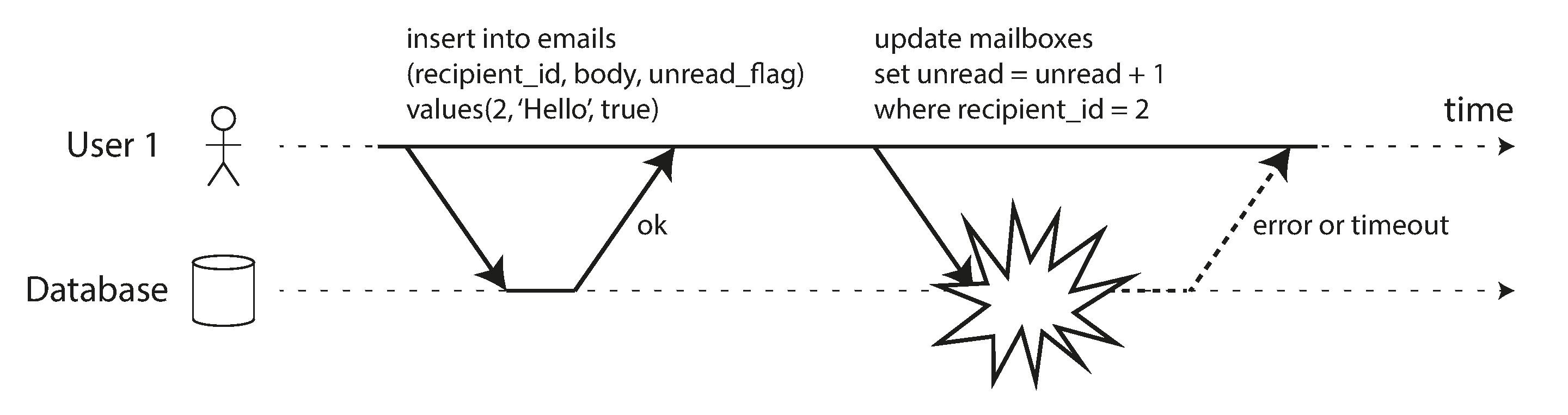
Hình 8-3 minh họa sự cần thiết của atomicity: nếu xảy ra lỗi trong quá trình transaction, nội dung hộp thư và bộ đếm chưa đọc có thể không đồng bộ. Trong một atomic transaction, nếu việc cập nhật bộ đếm thất bại, transaction bị abort và email đã chèn được rollback.
Multi-object transaction yêu cầu có cách xác định các thao tác đọc và ghi nào thuộc về cùng một transaction. Trong cơ sở dữ liệu quan hệ, điều đó thường được thực hiện dựa trên kết nối TCP của client đến máy chủ cơ sở dữ liệu: trên bất kỳ kết nối cụ thể nào, mọi thứ giữa câu lệnh BEGIN TRANSACTION và COMMIT được coi là thuộc cùng một transaction. Nếu kết nối TCP bị gián đoạn, transaction phải bị abort.
Mặt khác, nhiều cơ sở dữ liệu phi quan hệ không có cách nhóm các thao tác lại với nhau như vậy. Ngay cả khi có API đa đối tượng (ví dụ, một key-value store có thể có thao tác multi-put cập nhật nhiều khóa trong một thao tác), điều đó không nhất thiết có nghĩa là nó có ngữ nghĩa transaction: lệnh có thể thành công với một số khóa và thất bại với các khóa khác, để lại cơ sở dữ liệu ở trạng thái được cập nhật một phần.
Single-object writes
Atomicity và isolation cũng áp dụng khi một đối tượng đơn đang được thay đổi. Ví dụ, hãy tưởng tượng bạn đang ghi một tài liệu JSON 20 KB vào cơ sở dữ liệu:
- Nếu kết nối mạng bị gián đoạn sau khi 10 KB đầu tiên đã được gửi, liệu cơ sở dữ liệu có lưu đoạn 10 KB JSON không thể parse đó không?
- Nếu điện bị cắt trong khi cơ sở dữ liệu đang ghi đè giá trị cũ trên đĩa, bạn có kết thúc với giá trị cũ và mới bị ghép lẫn không?
- Nếu một client khác đọc tài liệu đó trong khi thao tác ghi đang diễn ra, nó có thấy một giá trị được cập nhật một phần không?
Những vấn đề đó sẽ cực kỳ khó hiểu, vì vậy các storage engine gần như phổ biến nhằm cung cấp atomicity và isolation ở cấp độ một đối tượng đơn (như một cặp key-value) trên một node. Atomicity có thể được triển khai bằng cách sử dụng log để khôi phục sau crash (xem “Making B-trees reliable”), và isolation có thể được triển khai bằng cách sử dụng lock trên mỗi đối tượng (chỉ cho phép một thread truy cập một đối tượng tại một thời điểm).
Một số cơ sở dữ liệu cũng cung cấp các thao tác atomic phức tạp hơn, chẳng hạn như thao tác increment, loại bỏ sự cần thiết của chu kỳ read-modify-write như trong Hình 8-1. Cũng phổ biến không kém là thao tác conditional write (ghi có điều kiện), cho phép một thao tác ghi chỉ xảy ra nếu giá trị chưa bị thay đổi đồng thời bởi ai đó khác (xem “Conditional writes (compare-and-set)”), tương tự như thao tác compare-and-set hoặc compare-and-swap (CAS) trong đồng thời bộ nhớ dùng chung.
Note
Nói chính xác, thuật ngữ atomic increment sử dụng từ atomic theo nghĩa của lập trình đa luồng. Trong ngữ cảnh ACID, nó thực ra nên được gọi là isolated hoặc serializable increment, nhưng đó không phải là thuật ngữ thông thường.
Các thao tác single-object này rất hữu ích, vì chúng có thể ngăn chặn lost update (mất cập nhật) khi nhiều client cố gắng ghi vào cùng một đối tượng đồng thời (xem “Preventing Lost Updates”). Tuy nhiên, chúng không phải là transaction theo nghĩa thông thường. Ví dụ, tính năng “lightweight transactions” của Cassandra và ScyllaDB, và chế độ “strong consistency” của Aerospike cung cấp các thao tác đọc linearizable (xem “Linearizability”) và ghi có điều kiện trên một đối tượng đơn, nhưng không có đảm bảo nào trên nhiều đối tượng.
The need for multi-object transactions
Chúng ta có thực sự cần multi-object transaction không? Có thể triển khai bất kỳ ứng dụng nào chỉ với mô hình dữ liệu key-value và các thao tác single-object không?
Có một số trường hợp sử dụng trong đó các thao tác chèn, cập nhật và xóa single-object là đủ. Tuy nhiên, trong nhiều trường hợp khác, các thao tác ghi vào nhiều đối tượng khác nhau cần được phối hợp:
- Trong mô hình dữ liệu quan hệ, một hàng trong một bảng thường có tham chiếu khóa ngoại đến một hàng trong bảng khác. Tương tự, trong mô hình dữ liệu dạng đồ thị, một đỉnh có các cạnh đến các đỉnh khác. Multi-object transaction cho phép bạn đảm bảo rằng các tham chiếu này vẫn hợp lệ: khi chèn nhiều bản ghi tham chiếu đến nhau, các khóa ngoại phải chính xác và cập nhật, nếu không dữ liệu trở nên vô nghĩa.
- Trong mô hình dữ liệu tài liệu, các trường cần được cập nhật cùng nhau thường nằm trong cùng một tài liệu, được coi là một đối tượng đơn, không cần multi-object transaction khi cập nhật một tài liệu đơn. Tuy nhiên, các cơ sở dữ liệu tài liệu thiếu chức năng join cũng khuyến khích denormalization (xem “When to Use Which Model”). Khi thông tin được denormalize cần được cập nhật, như trong ví dụ của Hình 8-2, bạn cần cập nhật nhiều tài liệu cùng một lúc. Transaction rất hữu ích trong tình huống này để ngăn dữ liệu denormalize bị mất đồng bộ. dữ liệu phi chuẩn hóa (denormalized data) khỏi bị mất đồng bộ.
- Trong các cơ sở dữ liệu có secondary index (chỉ mục phụ) (gần như tất cả ngoại trừ các kho lưu trữ key-value thuần túy), các chỉ mục này cũng cần được cập nhật mỗi khi bạn thay đổi một giá trị. Các chỉ mục này là các đối tượng cơ sở dữ liệu khác nhau từ góc độ giao dịch: ví dụ, nếu không có transaction isolation (cách ly giao dịch), một bản ghi có thể xuất hiện trong chỉ mục này nhưng không xuất hiện trong chỉ mục kia, vì việc cập nhật chỉ mục thứ hai chưa xảy ra (xem “Sharding and Secondary Indexes”).
Các ứng dụng như vậy vẫn có thể được triển khai mà không cần giao dịch. Tuy nhiên, việc xử lý lỗi trở nên phức tạp hơn nhiều khi không có atomicity (tính nguyên tử), và thiếu isolation (cách ly) có thể gây ra các vấn đề về đồng thời (concurrency). Chúng ta sẽ thảo luận về những vấn đề đó trong “Weak Isolation Levels”, và khám phá các cách tiếp cận thay thế trong “Derived data versus distributed transactions”.
Xử lý lỗi và hủy bỏ
Một tính năng quan trọng của giao dịch là nó có thể bị hủy bỏ và thử lại một cách an toàn nếu xảy ra lỗi. Các cơ sở dữ liệu ACID được xây dựng dựa trên triết lý này: nếu cơ sở dữ liệu có nguy cơ vi phạm đảm bảo về atomicity, isolation, hoặc durability (tính bền vững), nó sẽ từ bỏ hoàn toàn giao dịch thay vì để nó ở trạng thái hoàn thành một nửa.
Tuy nhiên, không phải tất cả các hệ thống đều tuân theo triết lý đó. Đặc biệt, các kho dữ liệu với leaderless replication (sao chép không có leader) (xem “Leaderless Replication”) hoạt động nhiều hơn theo cơ chế “nỗ lực tối đa” (best effort), có thể được tóm tắt là “cơ sở dữ liệu sẽ làm hết sức có thể, và nếu gặp lỗi, nó sẽ không hoàn tác những gì đã làm”, vì vậy ứng dụng có trách nhiệm khôi phục sau lỗi.
Lỗi chắc chắn sẽ xảy ra, nhưng nhiều nhà phát triển phần mềm thích chỉ nghĩ đến trường hợp thành công (happy path) hơn là những phức tạp trong việc xử lý lỗi. Ví dụ, các framework ORM (object-relational mapping, ánh xạ đối tượng quan hệ) phổ biến như ActiveRecord của Rails và Django không thử lại các giao dịch bị hủy bỏ. Lỗi thường dẫn đến một exception nổi lên theo stack, vì vậy mọi đầu vào của người dùng đều bị loại bỏ và người dùng nhận được thông báo lỗi. Điều này thật đáng tiếc, vì toàn bộ mục đích của việc hủy bỏ là để có thể thử lại một cách an toàn.
Mặc dù việc thử lại một giao dịch bị hủy bỏ là cơ chế xử lý lỗi đơn giản và hiệu quả, nhưng nó không hoàn hảo:
- Nếu giao dịch thực sự thành công, nhưng mạng bị gián đoạn trong khi máy chủ cố gắng xác nhận việc commit thành công với client (và client bị timeout), thì việc thử lại giao dịch sẽ khiến nó được thực hiện hai lần, trừ khi bạn có cơ chế deduplication (loại bỏ trùng lặp) ở tầng ứng dụng.
- Nếu lỗi xảy ra do quá tải hoặc tranh chấp cao giữa các giao dịch đồng thời, việc thử lại giao dịch sẽ làm cho vấn đề tệ hơn, không phải tốt hơn. Để tránh các vòng phản hồi như vậy, bạn có thể giới hạn số lần thử lại, sử dụng exponential backoff (giãn cách mũ), và xử lý các lỗi liên quan đến quá tải khác với các lỗi khác (xem “When an overloaded system won’t recover”).
- Chỉ đáng thử lại sau các lỗi tạm thời (ví dụ do deadlock, vi phạm isolation, gián đoạn mạng tạm thời, và failover); sau một lỗi vĩnh viễn (ví dụ: vi phạm ràng buộc) thì việc thử lại là vô nghĩa.
- Nếu giao dịch cũng có các tác dụng phụ ngoài cơ sở dữ liệu, những tác dụng phụ đó có thể xảy ra ngay cả khi giao dịch bị hủy bỏ. Ví dụ, nếu bạn đang gửi email, bạn không muốn gửi email lại mỗi lần thử lại giao dịch. Nếu bạn muốn đảm bảo rằng một số hệ thống khác nhau cùng commit hoặc cùng hủy bỏ, two-phase commit (cam kết hai giai đoạn) có thể giúp ích (chúng ta sẽ thảo luận về điều này trong “Two-Phase Commit (2PC)”).
- Nếu tiến trình client gặp sự cố trong khi thử lại, mọi dữ liệu mà nó đang cố gắng ghi vào cơ sở dữ liệu đều bị mất.
Các Mức Cách Ly Yếu
Nếu hai giao dịch không truy cập cùng một dữ liệu, hoặc nếu cả hai đều chỉ đọc, chúng có thể được chạy song song một cách an toàn, vì không giao dịch nào phụ thuộc vào giao dịch kia. Các vấn đề đồng thời (race condition) chỉ xuất hiện khi một giao dịch đọc dữ liệu đang được giao dịch khác sửa đổi đồng thời, hoặc khi hai giao dịch cố gắng sửa đổi cùng một dữ liệu.
Lỗi đồng thời rất khó phát hiện bằng kiểm thử, vì những lỗi như vậy chỉ xảy ra khi bạn gặp đúng thời điểm không may mắn. Những vấn đề thời điểm như vậy có thể xảy ra rất hiếm, và thường khó tái hiện. Đồng thời cũng rất khó lý luận, đặc biệt trong một ứng dụng lớn nơi bạn không nhất thiết biết những phần code nào khác đang truy cập cơ sở dữ liệu. Phát triển ứng dụng đã đủ khó nếu bạn chỉ có một người dùng tại một thời điểm; có nhiều người dùng đồng thời làm cho nó khó hơn nhiều, vì bất kỳ dữ liệu nào cũng có thể thay đổi bất ngờ bất kỳ lúc nào.
Vì lý do đó, các cơ sở dữ liệu đã cố gắng che giấu các vấn đề đồng thời khỏi các nhà phát triển ứng dụng bằng cách cung cấp transaction isolation (cách ly giao dịch). Về lý thuyết, isolation sẽ giúp cuộc sống của bạn dễ dàng hơn bằng cách cho phép bạn giả vờ rằng không có đồng thời nào xảy ra: serializable isolation (cách ly tuần tự) có nghĩa là cơ sở dữ liệu đảm bảo rằng các giao dịch có cùng hiệu quả như thể chúng chạy serially (tuần tự, tức là từng giao dịch một, không có đồng thời).
Trong thực tế, isolation không may là không đơn giản như vậy. Serializable isolation có chi phí hiệu năng, và nhiều cơ sở dữ liệu không muốn trả giá đó 10. Do đó, các hệ thống thường sử dụng các mức isolation yếu hơn, bảo vệ chống lại một số vấn đề đồng thời, nhưng không phải tất cả. Những mức isolation đó khó hiểu hơn nhiều và có thể dẫn đến các lỗi tinh vi, nhưng chúng vẫn được sử dụng trong thực tế 29.
Các lỗi đồng thời gây ra bởi transaction isolation yếu không chỉ là vấn đề lý thuyết. Chúng đã gây ra thiệt hại tài chính đáng kể 30 31 32, dẫn đến điều tra bởi các kiểm toán viên tài chính 33, và làm hỏng dữ liệu khách hàng 34. Một bình luận phổ biến về những tiết lộ về các vấn đề như vậy là “Hãy dùng cơ sở dữ liệu ACID nếu bạn xử lý dữ liệu tài chính!”, nhưng điều đó bỏ qua vấn đề cốt lõi. Ngay cả nhiều hệ thống cơ sở dữ liệu quan hệ phổ biến (thường được coi là “ACID”) cũng sử dụng isolation yếu, vì vậy chúng không nhất thiết ngăn được những lỗi này.
Note
Tình cờ là, phần lớn hệ thống ngân hàng dựa vào các tệp văn bản được trao đổi qua FTP an toàn 35. Trong bối cảnh này, có audit trail (vết kiểm toán) và một số biện pháp phòng chống gian lận ở cấp độ con người thực sự quan trọng hơn các thuộc tính ACID.
Những ví dụ đó cũng làm nổi bật một điểm quan trọng: ngay cả khi các vấn đề đồng thời hiếm xảy ra trong hoạt động bình thường, bạn phải xem xét khả năng kẻ tấn công cố tình gửi một lượng lớn các yêu cầu đồng thời đến API của bạn nhằm khai thác các lỗi đồng thời 30. Do đó, để xây dựng các ứng dụng đáng tin cậy và bảo mật, bạn phải đảm bảo rằng các lỗi như vậy được ngăn chặn một cách có hệ thống.
Trong phần này, chúng ta sẽ xem xét một số mức isolation yếu (không tuần tự hóa) được sử dụng trong thực tế, và thảo luận chi tiết về các loại race condition có thể và không thể xảy ra, để bạn có thể quyết định mức nào phù hợp với ứng dụng của mình. Sau khi hoàn thành điều đó, chúng ta sẽ thảo luận chi tiết về serializability (xem “Serializability”). Thảo luận của chúng ta về các mức isolation sẽ không chính thức, sử dụng các ví dụ. Nếu bạn muốn các định nghĩa và phân tích chặt chẽ về các thuộc tính của chúng, bạn có thể tìm thấy trong tài liệu học thuật 36 37 38 39.
Read Committed
Mức cơ bản nhất của transaction isolation là read committed (đọc đã cam kết). Nó đưa ra hai đảm bảo:
- Khi đọc từ cơ sở dữ liệu, bạn chỉ thấy dữ liệu đã được commit (không có dirty reads, đọc bẩn).
- Khi ghi vào cơ sở dữ liệu, bạn chỉ ghi đè dữ liệu đã được commit (không có dirty writes, ghi bẩn).
Một số cơ sở dữ liệu hỗ trợ mức isolation yếu hơn nữa gọi là read uncommitted (đọc chưa cam kết). Nó ngăn dirty writes, nhưng không ngăn dirty reads. Hãy thảo luận chi tiết hơn về hai đảm bảo này.
Không có dirty reads
Hãy tưởng tượng một giao dịch đã ghi một số dữ liệu vào cơ sở dữ liệu, nhưng giao dịch đó chưa commit hoặc hủy bỏ. Liệu giao dịch khác có thể thấy dữ liệu chưa commit đó không? Nếu có, điều đó được gọi là dirty read (đọc bẩn) 3.
Các giao dịch chạy ở mức cách ly read committed phải ngăn dirty reads. Điều này có nghĩa là mọi thao tác ghi của một giao dịch chỉ trở nên hiển thị với các giao dịch khác khi giao dịch đó commit (và sau đó tất cả các thao tác ghi của nó trở nên hiển thị cùng lúc). Điều này được minh họa trong Hình 8-4, nơi người dùng 1 đã đặt x = 3, nhưng lệnh get x của người dùng 2 vẫn trả về giá trị cũ là 2, trong khi người dùng 1 chưa commit.
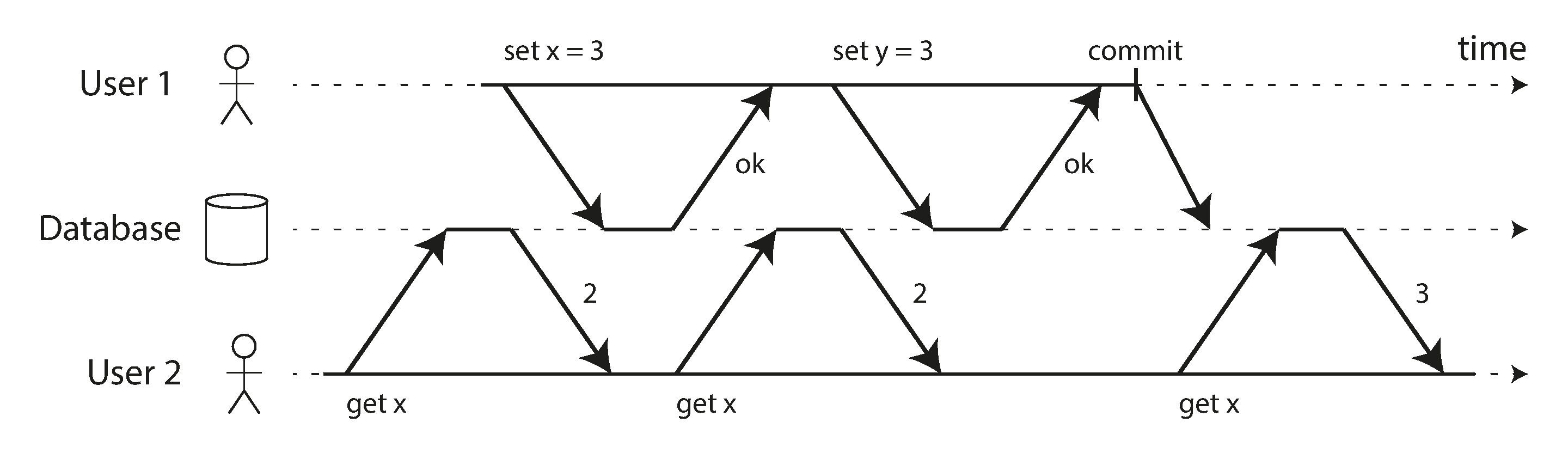
Có một vài lý do tại sao việc ngăn dirty reads là hữu ích:
- Nếu một giao dịch cần cập nhật nhiều hàng, dirty read có nghĩa là giao dịch khác có thể thấy một số cập nhật nhưng không thấy tất cả. Ví dụ, trong Hình 8-2, người dùng thấy email chưa đọc mới nhưng không thấy bộ đếm đã cập nhật. Đây là dirty read của email. Thấy cơ sở dữ liệu ở trạng thái được cập nhật một phần gây nhầm lẫn cho người dùng và có thể khiến các giao dịch khác đưa ra quyết định không chính xác.
- Nếu một giao dịch hủy bỏ, mọi thao tác ghi mà nó đã thực hiện cần được rollback (hoàn tác) (như trong Hình 8-3). Nếu cơ sở dữ liệu cho phép dirty reads, điều đó có nghĩa là một giao dịch có thể thấy dữ liệu sau này bị rollback, tức là dữ liệu không bao giờ thực sự được commit vào cơ sở dữ liệu. Bất kỳ giao dịch nào đọc dữ liệu chưa commit cũng cần bị hủy bỏ, dẫn đến vấn đề gọi là cascading aborts (hủy bỏ dây chuyền).
Không có dirty writes
Điều gì xảy ra nếu hai giao dịch đồng thời cố gắng cập nhật cùng một hàng trong cơ sở dữ liệu? Chúng ta không biết thứ tự các thao tác ghi sẽ xảy ra theo thứ tự nào, nhưng thông thường chúng ta giả định rằng thao tác ghi sau sẽ ghi đè thao tác ghi trước.
Tuy nhiên, điều gì xảy ra nếu thao tác ghi trước là một phần của giao dịch chưa commit, vì vậy thao tác ghi sau sẽ ghi đè một giá trị chưa commit? Điều này được gọi là dirty write (ghi bẩn) 36. Các giao dịch chạy ở mức cách ly read committed phải ngăn dirty writes, thường bằng cách trì hoãn thao tác ghi thứ hai cho đến khi giao dịch của thao tác ghi đầu tiên đã commit hoặc hủy bỏ.
Bằng cách ngăn dirty writes, mức cách ly này tránh được một số loại vấn đề đồng thời:
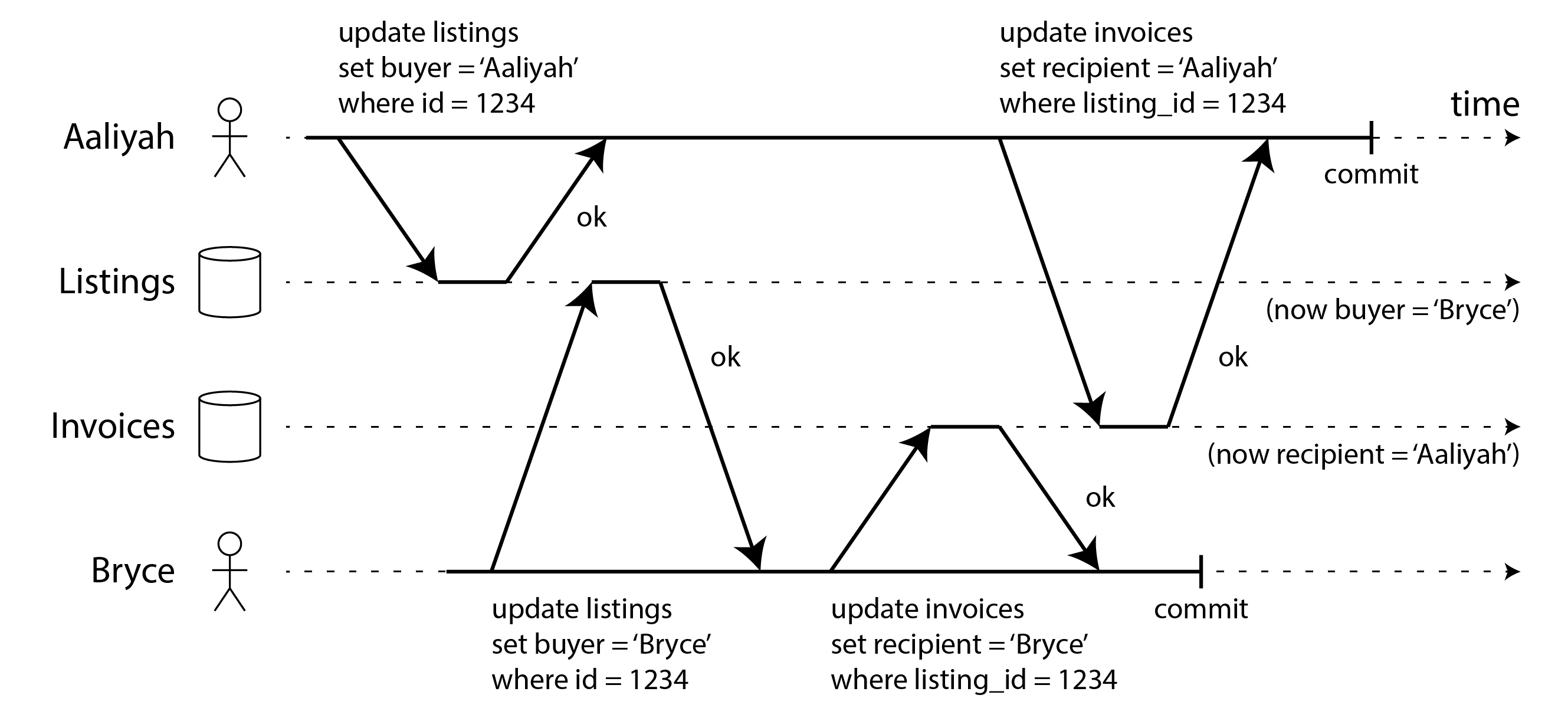
- Nếu các giao dịch cập nhật nhiều hàng, dirty writes có thể dẫn đến kết quả xấu. Ví dụ, hãy xem xét Hình 8-5, minh họa một trang web bán xe đã qua sử dụng nơi hai người, Aaliyah và Bryce, đang đồng thời cố gắng mua cùng một chiếc xe. Mua xe yêu cầu hai thao tác ghi vào cơ sở dữ liệu: danh sách trên trang web cần được cập nhật để phản ánh người mua, và hóa đơn bán hàng cần được gửi đến người mua. Trong trường hợp Hình 8-5, việc bán được trao cho Bryce (vì anh ấy thực hiện thao tác ghi thắng vào bảng
listings), nhưng hóa đơn được gửi cho Aaliyah (vì cô ấy thực hiện thao tác ghi thắng vào bảnginvoices). Read committed ngăn chặn những sự cố như vậy. - Tuy nhiên, read committed không ngăn race condition giữa hai lần tăng bộ đếm trong Hình 8-1. Trong trường hợp này, thao tác ghi thứ hai xảy ra sau khi giao dịch đầu tiên đã commit, vì vậy đây không phải là dirty write. Nó vẫn không chính xác, nhưng vì lý do khác, trong “Preventing Lost Updates” chúng ta sẽ thảo luận về cách làm cho các lần tăng bộ đếm như vậy an toàn.
Triển khai read committed
Read committed là một mức cách ly rất phổ biến. Đây là cài đặt mặc định trong Oracle Database, PostgreSQL, SQL Server và nhiều cơ sở dữ liệu khác 10.
Thông thường nhất, các cơ sở dữ liệu ngăn dirty writes bằng cách sử dụng row-level lock (khóa cấp hàng): khi một giao dịch muốn sửa đổi một hàng cụ thể (hoặc tài liệu hoặc một số đối tượng khác), nó phải trước tiên thu được khóa trên hàng đó. Sau đó nó phải giữ khóa đó cho đến khi giao dịch được commit hoặc hủy bỏ. Chỉ một giao dịch có thể giữ khóa cho bất kỳ hàng nào; nếu giao dịch khác muốn ghi vào cùng một hàng, nó phải đợi cho đến khi giao dịch đầu tiên commit hoặc hủy bỏ trước khi có thể thu được khóa và tiếp tục. Việc khóa này được thực hiện tự động bởi các cơ sở dữ liệu ở chế độ read committed (hoặc các mức cách ly mạnh hơn).
Làm thế nào để chúng ta ngăn dirty reads? Một tùy chọn sẽ là sử dụng cùng một khóa, và yêu cầu bất kỳ giao dịch nào muốn đọc một hàng phải tạm thời thu được khóa và sau đó giải phóng nó ngay lập tức sau khi đọc. Điều này sẽ đảm bảo rằng việc đọc không thể xảy ra trong khi một hàng có giá trị bẩn, chưa commit (vì trong thời gian đó khóa sẽ được giữ bởi giao dịch đã thực hiện thao tác ghi).
Tuy nhiên, cách tiếp cận yêu cầu read lock (khóa đọc) không hoạt động tốt trong thực tế, vì một giao dịch ghi chạy lâu có thể buộc nhiều giao dịch khác phải đợi cho đến khi giao dịch chạy lâu hoàn thành, ngay cả khi các giao dịch khác chỉ đọc và không ghi bất cứ thứ gì vào cơ sở dữ liệu. Điều này làm hại thời gian phản hồi của các giao dịch chỉ đọc và không tốt cho khả năng vận hành: sự chậm lại ở một phần của ứng dụng có thể có tác động dây chuyền ở một phần hoàn toàn khác của ứng dụng do chờ đợi khóa.
Tuy nhiên, các khóa được sử dụng để ngăn dirty reads trong một số cơ sở dữ liệu, chẳng hạn như IBM Db2 và Microsoft SQL Server với cài đặt read_committed_snapshot=off 29.
Một cách tiếp cận được sử dụng phổ biến hơn để ngăn dirty reads là cách được minh họa trong Hình 8-4: đối với mỗi hàng được ghi, cơ sở dữ liệu ghi nhớ cả giá trị cũ đã commit và giá trị mới được đặt bởi giao dịch hiện đang giữ write lock. Trong khi giao dịch đang diễn ra, bất kỳ giao dịch nào khác đọc hàng đó đều chỉ được cung cấp giá trị cũ. Chỉ khi giá trị mới được commit, các giao dịch mới chuyển sang đọc giá trị mới (xem “Multi-version concurrency control (MVCC)” để biết thêm chi tiết).
Snapshot Isolation và Repeatable Read
Nếu bạn nhìn nông cạn vào read committed isolation, bạn có thể được tha thứ khi nghĩ rằng nó làm mọi thứ mà một giao dịch cần làm: nó cho phép hủy bỏ (cần thiết cho atomicity), nó ngăn việc đọc kết quả chưa hoàn chỉnh của các giao dịch, và nó ngăn các thao tác ghi đồng thời bị trộn lẫn. Thực sự, đây là những tính năng hữu ích, và là những đảm bảo mạnh hơn nhiều so với những gì bạn có thể nhận được từ một hệ thống không có giao dịch.
Tuy nhiên, vẫn còn rất nhiều cách bạn có thể gặp lỗi đồng thời khi sử dụng mức cách ly này. Ví dụ, Hình 8-6 minh họa một vấn đề có thể xảy ra với read committed.
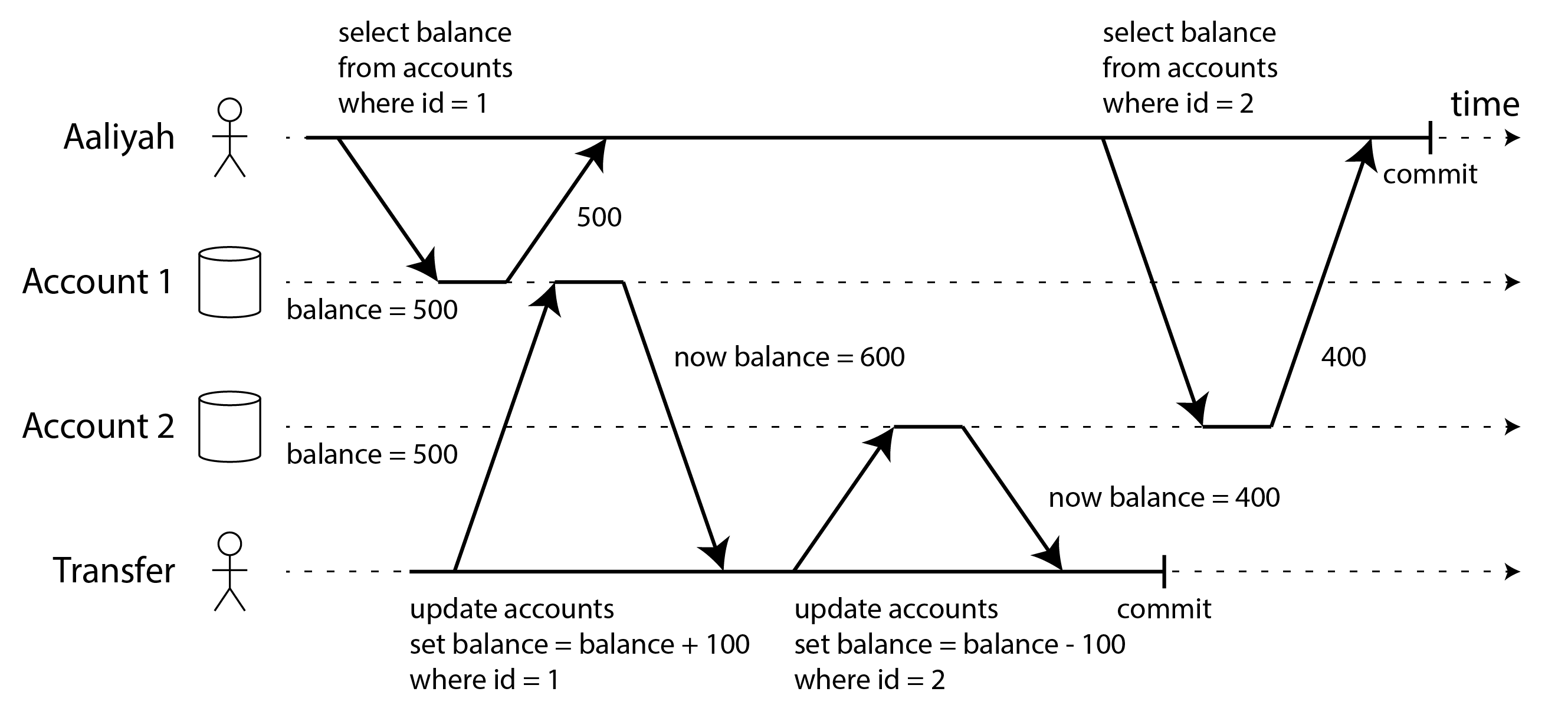
Giả sử Aaliyah có 1.000 đô la tiết kiệm tại một ngân hàng, chia thành hai tài khoản mỗi tài khoản 500 đô la. Bây giờ một giao dịch chuyển 100 đô la từ một trong các tài khoản của cô sang tài khoản kia. Nếu cô ấy không may nhìn vào danh sách số dư tài khoản của mình đúng vào thời điểm giao dịch đó đang được xử lý, cô ấy có thể thấy số dư của một tài khoản trước khi khoản tiền đến (với số dư 500 đô la), và tài khoản kia sau khi khoản chuyển ra đã được thực hiện (số dư mới là 400 đô la). Với Aaliyah, bây giờ có vẻ như cô ấy chỉ có tổng cộng 900 đô la trong các tài khoản của mình, dường như 100 đô la đã biến mất vào không khí.
Hiện tượng này được gọi là read skew (lệch đọc), và đây là một ví dụ về nonrepeatable read (đọc không thể lặp lại): nếu Aaliyah đọc lại số dư của tài khoản 1 vào cuối giao dịch, cô ấy sẽ thấy một giá trị khác (600 đô la) so với những gì cô ấy thấy trong truy vấn trước đó. Read skew được coi là chấp nhận được theo read committed isolation: các số dư tài khoản mà Aaliyah thấy thực sự đã được commit tại thời điểm cô ấy đọc chúng.
Note
Thuật ngữ skew (lệch) không may bị quá tải: trước đó chúng ta đã sử dụng nó theo nghĩa khối lượng công việc mất cân bằng với các điểm nóng (xem “Skewed Workloads and Relieving Hot Spots”), trong khi ở đây nó có nghĩa là hiện tượng thời gian bất thường.
Trong trường hợp của Aaliyah, đây không phải là vấn đề lâu dài, vì cô ấy rất có thể sẽ thấy số dư tài khoản nhất quán nếu cô ấy tải lại trang web ngân hàng trực tuyến sau vài giây. Tuy nhiên, một số tình huống không thể chịu đựng sự không nhất quán tạm thời như vậy:
- Sao lưu (Backups)
- Việc sao lưu yêu cầu tạo bản sao của toàn bộ cơ sở dữ liệu, có thể mất nhiều giờ trên một cơ sở dữ liệu lớn. Trong thời gian quá trình sao lưu đang chạy, các thao tác ghi sẽ tiếp tục được thực hiện vào cơ sở dữ liệu. Do đó, bạn có thể kết thúc với một số phần của bản sao lưu chứa phiên bản cũ hơn của dữ liệu, và các phần khác chứa phiên bản mới hơn. Nếu bạn cần khôi phục từ bản sao lưu như vậy, các sự không nhất quán (chẳng hạn như tiền biến mất) trở thành vĩnh viễn.
- Các truy vấn phân tích và kiểm tra tính toàn vẹn
- Đôi khi, bạn có thể muốn chạy một truy vấn quét qua các phần lớn của cơ sở dữ liệu. Các truy vấn như vậy phổ biến trong analytics (phân tích) (xem “Analytical versus Operational Systems”), hoặc có thể là một phần của kiểm tra tính toàn vẹn định kỳ rằng mọi thứ đều theo thứ tự (giám sát để phát hiện hỏng dữ liệu). Các truy vấn này có thể trả về kết quả vô nghĩa nếu chúng quan sát các phần của cơ sở dữ liệu tại các thời điểm khác nhau.
Snapshot isolation (cách ly bản chụp) 36 là giải pháp phổ biến nhất cho vấn đề này. Ý tưởng là mỗi giao dịch đọc từ một consistent snapshot (bản chụp nhất quán) của cơ sở dữ liệu, tức là giao dịch thấy tất cả dữ liệu đã được commit trong cơ sở dữ liệu tại thời điểm bắt đầu giao dịch. Ngay cả khi dữ liệu sau đó được thay đổi bởi giao dịch khác, mỗi giao dịch chỉ thấy dữ liệu cũ từ thời điểm cụ thể đó.
Snapshot isolation là một lợi ích lớn cho các truy vấn chỉ đọc chạy lâu như sao lưu và phân tích. Rất khó để lý luận về ý nghĩa của một truy vấn nếu dữ liệu mà nó hoạt động đang thay đổi đồng thời với khi truy vấn đang thực thi. Khi một giao dịch có thể thấy bản chụp nhất quán của cơ sở dữ liệu, được đóng băng tại một thời điểm cụ thể, điều đó dễ hiểu hơn nhiều.
Snapshot isolation là tính năng phổ biến: các biến thể của nó được hỗ trợ bởi PostgreSQL, MySQL với storage engine InnoDB, Oracle, SQL Server và những cái khác, mặc dù hành vi chi tiết khác nhau từ hệ thống này sang hệ thống khác 29 40 41. Một số cơ sở dữ liệu, chẳng hạn như Oracle, TiDB và Aurora DSQL, thậm chí chọn snapshot isolation làm mức isolation cao nhất của họ.
Multi-version concurrency control (MVCC)
Giống như read committed isolation, các triển khai snapshot isolation thường sử dụng write lock để ngăn dirty writes (xem “Implementing read committed”), có nghĩa là một giao dịch thực hiện thao tác ghi có thể chặn tiến trình của giao dịch khác ghi vào cùng một hàng. Tuy nhiên, việc đọc không yêu cầu bất kỳ khóa nào. Từ góc độ hiệu năng, nguyên tắc chính của snapshot isolation là reader không bao giờ chặn writer, và writer không bao giờ chặn reader. Điều này cho phép cơ sở dữ liệu xử lý các truy vấn đọc chạy lâu trên một bản chụp nhất quán cùng lúc với việc xử lý các thao tác ghi bình thường, mà không có bất kỳ tranh chấp khóa nào giữa hai bên.
Để triển khai snapshot isolation, các cơ sở dữ liệu sử dụng sự tổng quát hóa của cơ chế chúng ta đã thấy để ngăn dirty reads trong Hình 8-4. Thay vì hai phiên bản của mỗi hàng (phiên bản đã commit và phiên bản đã ghi đè nhưng chưa commit), cơ sở dữ liệu phải có khả năng giữ nhiều phiên bản đã commit khác nhau của một hàng, vì các giao dịch đang trong tiến trình khác nhau có thể cần thấy trạng thái của cơ sở dữ liệu tại các thời điểm khác nhau. Vì nó duy trì nhiều phiên bản của một hàng song song, kỹ thuật này được gọi là multi-version concurrency control (MVCC, kiểm soát đồng thời nhiều phiên bản).
Hình 8-7 minh họa cách triển khai snapshot isolation dựa trên MVCC trong PostgreSQL 40 42 43 (các triển khai khác tương tự). Khi một giao dịch được bắt đầu, nó được cấp một transaction ID (txid) duy nhất, luôn tăng. Bất cứ khi nào một giao dịch ghi bất cứ thứ gì vào cơ sở dữ liệu, dữ liệu nó ghi được gắn thẻ với transaction ID của người ghi. (Để chính xác, transaction ID trong PostgreSQL là số nguyên 32-bit, vì vậy chúng tràn sau khoảng 4 tỷ giao dịch. Quá trình vacuum thực hiện dọn dẹp để đảm bảo rằng sự tràn không ảnh hưởng đến dữ liệu.)
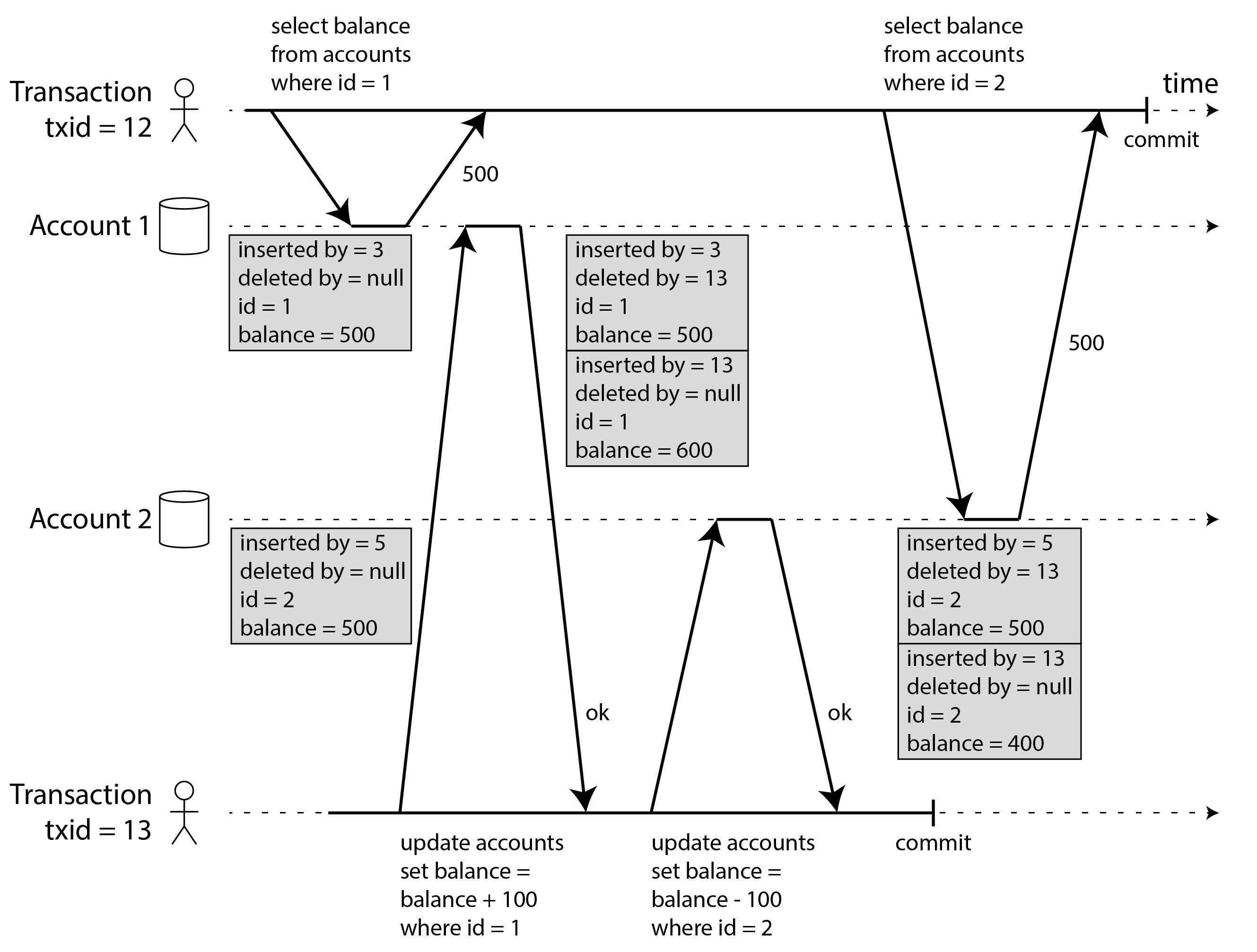
Mỗi hàng trong bảng có trường inserted_by, chứa ID của giao dịch đã chèn hàng này vào bảng. Hơn nữa, mỗi hàng có trường deleted_by, ban đầu trống. Nếu một giao dịch xóa một hàng, hàng đó không thực sự bị xóa khỏi cơ sở dữ liệu, nhưng nó được đánh dấu để xóa bằng cách đặt trường deleted_by thành ID của giao dịch đã yêu cầu xóa. Tại một thời điểm nào đó sau đó, khi chắc chắn rằng không có giao dịch nào có thể truy cập dữ liệu đã xóa nữa, một quá trình garbage collection trong cơ sở dữ liệu sẽ xóa các hàng được đánh dấu để xóa và giải phóng không gian của chúng.
Một thao tác cập nhật được dịch nội bộ thành xóa và chèn 44. Ví dụ, trong Hình 8-7, giao dịch 13 trừ 100 đô la từ tài khoản 2, thay đổi số dư từ 500 đô la thành 400 đô la. Bảng accounts hiện thực sự chứa hai hàng cho tài khoản 2: một hàng có số dư 500 đô la được đánh dấu là đã xóa bởi giao dịch 13, và một hàng có số dư 400 đô la được chèn bởi giao dịch 13.
Tất cả các phiên bản của một hàng được lưu trữ trong cùng một database heap (vùng heap cơ sở dữ liệu) (xem “Storing values within the index”), bất kể liệu các giao dịch đã ghi chúng đã commit hay chưa. Các phiên bản của cùng một hàng tạo thành một danh sách liên kết, đi từ phiên bản mới nhất đến phiên bản cũ nhất hoặc theo chiều ngược lại, để các truy vấn có thể lặp qua nội bộ tất cả các phiên bản của một hàng 45 46.
Quy tắc hiển thị để quan sát bản chụp nhất quán
Khi một giao dịch đọc từ cơ sở dữ liệu, transaction ID được sử dụng để quyết định phiên bản hàng nào nó có thể thấy và phiên bản nào vô hình. Bằng cách định nghĩa cẩn thận các quy tắc hiển thị, cơ sở dữ liệu có thể trình bày một bản chụp nhất quán của cơ sở dữ liệu cho ứng dụng. Điều này hoạt động đại khái như sau 43:
- Tại thời điểm bắt đầu mỗi giao dịch, cơ sở dữ liệu tạo danh sách tất cả các giao dịch khác đang trong tiến trình (chưa commit hoặc hủy bỏ) tại thời điểm đó. Mọi thao tác ghi mà những giao dịch đó đã thực hiện đều bị bỏ qua, ngay cả khi các giao dịch sau đó commit. Điều này đảm bảo rằng chúng ta thấy bản chụp nhất quán không bị ảnh hưởng bởi giao dịch khác commit.
- Mọi thao tác ghi được thực hiện bởi các giao dịch có transaction ID muộn hơn (tức là bắt đầu sau khi giao dịch hiện tại bắt đầu, và do đó không có trong danh sách các giao dịch đang trong tiến trình) đều bị bỏ qua, bất kể liệu những giao dịch đó đã commit hay chưa.
- Mọi thao tác ghi được thực hiện bởi các giao dịch bị hủy bỏ đều bị bỏ qua, bất kể thời điểm hủy bỏ đó xảy ra. Điều này có ưu điểm là khi một giao dịch hủy bỏ, chúng ta không cần ngay lập tức xóa các hàng mà nó đã ghi khỏi bộ lưu trữ, vì quy tắc hiển thị sẽ lọc chúng ra. Quá trình garbage collection có thể xóa chúng sau.
- Tất cả các thao tác ghi khác đều hiển thị với các truy vấn của ứng dụng.
Các quy tắc này áp dụng cho cả chèn và xóa hàng. Trong Hình 8-7, khi giao dịch 12 đọc từ tài khoản 2, nó thấy số dư 500 đô la vì việc xóa số dư 500 đô la được thực hiện bởi giao dịch 13 (theo quy tắc 2, giao dịch 12 không thể thấy việc xóa được thực hiện bởi giao dịch 13), và việc chèn số dư 400 đô la chưa hiển thị (theo cùng quy tắc).
Nói cách khác, một hàng hiển thị nếu cả hai điều kiện sau đây đúng:
- Tại thời điểm giao dịch của người đọc bắt đầu, giao dịch đã chèn hàng đó đã commit.
- Hàng không được đánh dấu để xóa, hoặc nếu có, giao dịch đã yêu cầu xóa chưa commit tại thời điểm giao dịch của người đọc bắt đầu.
Một giao dịch chạy lâu có thể tiếp tục sử dụng một bản chụp trong một thời gian dài, tiếp tục đọc các giá trị mà (từ góc độ của các giao dịch khác) đã bị ghi đè hoặc xóa từ lâu. Bằng cách không bao giờ cập nhật các giá trị tại chỗ mà thay vào đó chèn một phiên bản mới mỗi khi một giá trị được thay đổi, cơ sở dữ liệu có thể cung cấp bản chụp nhất quán trong khi chỉ phát sinh một chi phí nhỏ.
Chỉ mục và snapshot isolation
Các chỉ mục hoạt động như thế nào trong một cơ sở dữ liệu đa phiên bản? Cách tiếp cận phổ biến nhất là mỗi mục nhập chỉ mục trỏ đến một trong các phiên bản của hàng khớp với mục nhập (phiên bản cũ nhất hoặc mới nhất). Mỗi phiên bản hàng có thể chứa tham chiếu đến phiên bản cũ nhất tiếp theo hoặc mới nhất tiếp theo. Một truy vấn sử dụng chỉ mục sau đó phải lặp qua các hàng để tìm hàng hiển thị và giá trị khớp với những gì truy vấn đang tìm kiếm. Khi garbage collection xóa các phiên bản hàng cũ không còn hiển thị với bất kỳ giao dịch nào, các mục nhập chỉ mục tương ứng cũng có thể được xóa.
Nhiều chi tiết triển khai ảnh hưởng đến hiệu năng của multi-version concurrency control 45 46. Ví dụ, PostgreSQL có các tối ưu hóa để tránh cập nhật chỉ mục nếu các phiên bản khác nhau của cùng một hàng có thể vừa trên cùng một trang 40. Một số cơ sở dữ liệu khác tránh lưu trữ bản sao đầy đủ của các hàng được sửa đổi, và chỉ lưu trữ sự khác biệt giữa các phiên bản để tiết kiệm không gian.
Một cách tiếp cận khác được sử dụng trong CouchDB, Datomic và LMDB. Mặc dù chúng cũng sử dụng B-tree (xem “B-Trees”), chúng sử dụng biến thể bất biến (copy-on-write) không ghi đè các trang của cây khi chúng được cập nhật, mà thay vào đó tạo bản sao mới của mỗi trang được sửa đổi. Các trang cha, lên đến gốc của cây, được sao chép và cập nhật để trỏ đến các phiên bản mới của các trang con của chúng. Bất kỳ trang nào không bị ảnh hưởng bởi thao tác ghi không cần được sao chép, và có thể được chia sẻ với cây mới 47.
Với B-tree bất biến, mỗi giao dịch ghi (hoặc lô giao dịch) tạo ra một gốc B-tree mới, và một gốc cụ thể là bản chụp nhất quán của cơ sở dữ liệu tại thời điểm nó được tạo. Không cần lọc các hàng dựa trên transaction ID vì các thao tác ghi tiếp theo không thể sửa đổi B-tree hiện có; chúng chỉ có thể tạo gốc cây mới. Cách tiếp cận này cũng yêu cầu một quá trình nền để compaction (nén) và garbage collection.
Snapshot isolation, repeatable read và sự nhầm lẫn về tên gọi
MVCC là kỹ thuật triển khai thường được sử dụng cho các cơ sở dữ liệu, và thường nó được sử dụng để triển khai snapshot isolation. Tuy nhiên, các cơ sở dữ liệu khác nhau đôi khi sử dụng các thuật ngữ khác nhau để chỉ cùng một thứ: ví dụ, snapshot isolation được gọi là “repeatable read” trong PostgreSQL và “serializable” trong Oracle 29. Đôi khi các hệ thống khác nhau dùng cùng một thuật ngữ để chỉ những thứ khác nhau: chẳng hạn, trong PostgreSQL “repeatable read” có nghĩa là snapshot isolation, còn trong MySQL nó chỉ một cài đặt MVCC có tính nhất quán yếu hơn snapshot isolation 41.
Lý do dẫn đến sự nhầm lẫn về tên gọi này là chuẩn SQL không có khái niệm snapshot isolation, vì chuẩn được xây dựng dựa trên định nghĩa các mức cô lập của System R từ năm 1975 3 và snapshot isolation chưa được phát minh vào thời điểm đó. Thay vào đó, chuẩn định nghĩa repeatable read, trông bề ngoài tương tự với snapshot isolation. PostgreSQL gọi mức snapshot isolation của mình là “repeatable read” vì nó đáp ứng các yêu cầu của chuẩn, và nhờ vậy họ có thể tuyên bố tuân thủ chuẩn.
Đáng tiếc là định nghĩa các mức cô lập trong chuẩn SQL còn nhiều thiếu sót: nó mơ hồ, thiếu chính xác, và không độc lập với cài đặt như một chuẩn nên có 36. Dù nhiều cơ sở dữ liệu cài đặt repeatable read, những đảm bảo thực tế mà chúng cung cấp khác nhau đáng kể, dù về danh nghĩa đã được chuẩn hóa 29. Trong tài liệu nghiên cứu có tồn tại một định nghĩa chính thức về repeatable read 37 38, nhưng hầu hết các cài đặt không thỏa mãn định nghĩa chính thức đó. Thêm vào đó, IBM Db2 dùng “repeatable read” để chỉ serializability 10.
Kết quả là, không ai thực sự biết repeatable read có nghĩa là gì.
Ngăn chặn Lost Update (Cập nhật bị mất)
Các mức cô lập read committed và snapshot isolation mà chúng ta đã thảo luận chủ yếu nói về những đảm bảo về những gì một giao dịch chỉ đọc có thể thấy khi có các ghi đồng thời. Chúng ta hầu như bỏ qua vấn đề về hai giao dịch ghi đồng thời, chỉ thảo luận về dirty write (xem “No dirty writes”), một dạng xung đột ghi-ghi cụ thể có thể xảy ra.
Có nhiều loại xung đột thú vị khác có thể xảy ra giữa các giao dịch ghi đồng thời. Nổi tiếng nhất trong số đó là vấn đề lost update (cập nhật bị mất), được minh họa trong Hình 8-1 với ví dụ về hai lần tăng bộ đếm đồng thời.
Vấn đề lost update có thể xảy ra khi một ứng dụng đọc một giá trị từ cơ sở dữ liệu, sửa đổi nó, và ghi lại giá trị đã sửa (một chu kỳ đọc-sửa-ghi). Nếu hai giao dịch thực hiện điều này đồng thời, một trong những sửa đổi có thể bị mất, vì lần ghi thứ hai không bao gồm sửa đổi đầu tiên. (Đôi khi chúng ta nói rằng lần ghi sau ghi đè lần ghi trước.) Mẫu này xuất hiện trong nhiều tình huống khác nhau:
- Tăng bộ đếm hoặc cập nhật số dư tài khoản (đòi hỏi đọc giá trị hiện tại, tính toán giá trị mới, và ghi lại giá trị đã cập nhật)
- Thực hiện thay đổi cục bộ trong một giá trị phức tạp, ví dụ, thêm một phần tử vào danh sách trong một tài liệu JSON (đòi hỏi phân tích tài liệu, thực hiện thay đổi, và ghi lại tài liệu đã sửa đổi)
- Hai người dùng chỉnh sửa cùng một trang wiki vào cùng thời điểm, mỗi người lưu thay đổi bằng cách gửi toàn bộ nội dung trang lên server, ghi đè bất cứ thứ gì hiện có trong cơ sở dữ liệu
Vì đây là vấn đề rất phổ biến, nhiều giải pháp đã được phát triển 48.
Thao tác ghi nguyên tử (Atomic write operations)
Nhiều cơ sở dữ liệu cung cấp các thao tác cập nhật nguyên tử, giúp loại bỏ nhu cầu cài đặt chu kỳ đọc-sửa-ghi trong code ứng dụng. Đây thường là giải pháp tốt nhất nếu code của bạn có thể được biểu đạt bằng những thao tác đó. Ví dụ, lệnh sau đây an toàn với tính đồng thời trong hầu hết các cơ sở dữ liệu quan hệ:
UPDATE counters SET value = value + 1 WHERE key = 'foo';Tương tự, các cơ sở dữ liệu tài liệu như MongoDB cung cấp các thao tác nguyên tử để thực hiện sửa đổi cục bộ trên một phần của tài liệu JSON, và Redis cung cấp các thao tác nguyên tử để sửa đổi các cấu trúc dữ liệu như hàng ưu tiên (priority queue). Không phải tất cả các lần ghi đều có thể dễ dàng biểu đạt bằng các thao tác nguyên tử, ví dụ, cập nhật trang wiki liên quan đến chỉnh sửa văn bản tùy ý, có thể được xử lý bằng các thuật toán được thảo luận trong “CRDTs and Operational Transformation”, nhưng trong những tình huống mà thao tác nguyên tử có thể được sử dụng, chúng thường là lựa chọn tốt nhất.
Các thao tác nguyên tử thường được cài đặt bằng cách khóa độc quyền (exclusive lock) trên đối tượng khi đọc để không có giao dịch nào khác có thể đọc nó cho đến khi bản cập nhật được áp dụng. Một lựa chọn khác là đơn giản buộc tất cả các thao tác nguyên tử được thực thi trên một luồng đơn.
Đáng tiếc là các framework object-relational mapping (ORM) khiến dễ dàng vô tình viết code thực hiện chu kỳ đọc-sửa-ghi không an toàn thay vì sử dụng các thao tác nguyên tử do cơ sở dữ liệu cung cấp 49 50 51. Đây có thể là nguồn gốc của các lỗi tinh tế khó phát hiện qua kiểm thử.
Khóa tường minh (Explicit locking)
Một lựa chọn khác để ngăn chặn lost update, khi các thao tác nguyên tử tích hợp của cơ sở dữ liệu không cung cấp chức năng cần thiết, là để ứng dụng tường minh khóa các đối tượng sắp được cập nhật. Sau đó ứng dụng có thể thực hiện chu kỳ đọc-sửa-ghi, và nếu bất kỳ giao dịch nào khác cố gắng đồng thời cập nhật hoặc khóa cùng đối tượng đó, nó bị buộc phải chờ cho đến khi chu kỳ đọc-sửa-ghi đầu tiên hoàn thành.
Ví dụ, hãy xét một trò chơi nhiều người trong đó nhiều người chơi có thể di chuyển cùng một quân cờ đồng thời. Trong trường hợp này, một thao tác nguyên tử có thể không đủ, vì ứng dụng còn cần đảm bảo nước đi của người chơi tuân theo luật chơi, điều này liên quan đến một số logic mà bạn không thể cài đặt hợp lý dưới dạng truy vấn cơ sở dữ liệu. Thay vào đó, bạn có thể sử dụng khóa để ngăn hai người chơi di chuyển cùng một quân cờ đồng thời, như được minh họa trong Ví dụ 8-1.
Ví dụ 8-1. Khóa tường minh các hàng để ngăn chặn lost update
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE; ❶
-- Check whether move is valid, then update the position
-- of the piece that was returned by the previous SELECT.
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;❶: Mệnh đề FOR UPDATE chỉ ra rằng cơ sở dữ liệu nên khóa tất cả các hàng được trả về bởi truy vấn này.
Cách này hoạt động, nhưng để làm đúng, bạn cần suy nghĩ cẩn thận về logic ứng dụng. Rất dễ quên thêm khóa cần thiết ở đâu đó trong code, từ đó tạo ra race condition (điều kiện tranh chấp).
Hơn nữa, nếu bạn khóa nhiều đối tượng, có rủi ro xảy ra deadlock (khóa chết), khi hai hoặc nhiều giao dịch đang chờ nhau giải phóng khóa. Nhiều cơ sở dữ liệu tự động phát hiện deadlock và hủy bỏ một trong các giao dịch liên quan để hệ thống có thể tiếp tục. Bạn có thể xử lý tình huống này ở tầng ứng dụng bằng cách thử lại giao dịch đã bị hủy.
Tự động phát hiện lost update
Thao tác nguyên tử và khóa là các cách ngăn chặn lost update bằng cách buộc các chu kỳ đọc-sửa-ghi thực hiện tuần tự. Một lựa chọn khác là cho phép chúng thực thi song song và, nếu bộ quản lý giao dịch phát hiện một lost update, hủy bỏ giao dịch và buộc nó thử lại chu kỳ đọc-sửa-ghi.
Ưu điểm của cách tiếp cận này là cơ sở dữ liệu có thể thực hiện kiểm tra này hiệu quả kết hợp với snapshot isolation. Thực vậy, repeatable read của PostgreSQL, serializable của Oracle, và snapshot isolation của SQL Server tự động phát hiện khi một lost update đã xảy ra và hủy bỏ giao dịch vi phạm. Tuy nhiên, repeatable read của MySQL/InnoDB không phát hiện lost update 29 41. Một số tác giả 36 38 lập luận rằng cơ sở dữ liệu phải ngăn chặn lost update để đủ tiêu chuẩn cung cấp snapshot isolation, vì vậy MySQL không cung cấp snapshot isolation theo định nghĩa này.
Phát hiện lost update là một tính năng tuyệt vời, vì nó không yêu cầu code ứng dụng sử dụng bất kỳ tính năng cơ sở dữ liệu đặc biệt nào: bạn có thể quên sử dụng khóa hoặc thao tác nguyên tử và từ đó tạo ra lỗi, nhưng phát hiện lost update xảy ra tự động và do đó ít dễ xảy ra lỗi hơn. Tuy nhiên, bạn cũng phải thử lại các giao dịch bị hủy ở tầng ứng dụng.
Ghi có điều kiện (Conditional writes, compare-and-set)
Trong các cơ sở dữ liệu không cung cấp giao dịch, đôi khi bạn tìm thấy một thao tác conditional write (ghi có điều kiện) có thể ngăn chặn lost update bằng cách chỉ cho phép cập nhật xảy ra nếu giá trị chưa thay đổi kể từ lần bạn đọc nó lần cuối (đã đề cập trước đó trong “Single-object writes”). Nếu giá trị hiện tại không khớp với những gì bạn đọc trước đó, bản cập nhật không có tác dụng, và chu kỳ đọc-sửa-ghi phải được thử lại. Đây là tương đương của cơ sở dữ liệu với lệnh nguyên tử compare-and-set hoặc compare-and-swap (CAS) được nhiều CPU hỗ trợ.
Ví dụ, để ngăn hai người dùng đồng thời cập nhật cùng một trang wiki, bạn có thể thử điều gì đó như sau, kỳ vọng rằng bản cập nhật chỉ xảy ra nếu nội dung trang chưa thay đổi kể từ khi người dùng bắt đầu chỉnh sửa:
-- This may or may not be safe, depending on the database implementation
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';Nếu nội dung đã thay đổi và không còn khớp với 'old content', bản cập nhật này sẽ không có tác dụng,
vì vậy bạn cần kiểm tra xem bản cập nhật có được thực hiện hay không và thử lại nếu cần. Thay vì so sánh
toàn bộ nội dung, bạn cũng có thể sử dụng một cột số phiên bản mà bạn tăng lên ở mỗi lần cập nhật, và
áp dụng bản cập nhật chỉ khi số phiên bản hiện tại chưa thay đổi. Cách tiếp cận này đôi khi
được gọi là optimistic locking (khóa lạc quan) 52.
Lưu ý rằng nếu một giao dịch khác đã đồng thời sửa đổi content, nội dung mới có thể không
hiển thị theo các quy tắc hiển thị MVCC (xem “Visibility rules for observing a consistent snapshot”). Nhiều
cài đặt MVCC có ngoại lệ đối với các quy tắc hiển thị cho tình huống này, nơi các giá trị
được ghi bởi các giao dịch khác hiển thị khi đánh giá mệnh đề WHERE của các truy vấn UPDATE và
DELETE, ngay cả khi những lần ghi đó không hiển thị trong snapshot theo cách khác.
Giải quyết xung đột và sao chép (Conflict resolution and replication)
Trong các cơ sở dữ liệu được sao chép (xem Chương 6), việc ngăn chặn lost update mang thêm một chiều kích khác: vì chúng có các bản sao dữ liệu trên nhiều nút, và dữ liệu có thể được sửa đổi đồng thời trên các nút khác nhau, cần thực hiện một số bước bổ sung để ngăn chặn lost update.
Khóa và thao tác ghi có điều kiện giả định rằng có một bản sao dữ liệu duy nhất đã được cập nhật. Tuy nhiên, các cơ sở dữ liệu với sao chép multi-leader hoặc leaderless thường cho phép nhiều lần ghi xảy ra đồng thời và sao chép chúng bất đồng bộ, vì vậy chúng không thể đảm bảo rằng có một bản sao dữ liệu duy nhất đã được cập nhật. Do đó, các kỹ thuật dựa trên khóa hoặc ghi có điều kiện không áp dụng trong ngữ cảnh này. (Chúng ta sẽ xem xét lại vấn đề này chi tiết hơn trong “Linearizability”.)
Thay vào đó, như đã thảo luận trong “Dealing with Conflicting Writes”, một cách tiếp cận phổ biến trong các cơ sở dữ liệu được sao chép như vậy là cho phép các lần ghi đồng thời tạo ra nhiều phiên bản xung đột của một giá trị (còn được gọi là siblings, tức các bản sao anh em), và sử dụng code ứng dụng hoặc cấu trúc dữ liệu đặc biệt để giải quyết và hợp nhất các phiên bản này sau đó.
Hợp nhất các giá trị xung đột có thể ngăn chặn lost update nếu các cập nhật có tính giao hoán (tức là bạn có thể áp dụng chúng theo thứ tự khác nhau trên các bản sao khác nhau và vẫn nhận được kết quả giống nhau). Ví dụ, tăng bộ đếm hoặc thêm một phần tử vào tập hợp là các thao tác giao hoán. Đó là ý tưởng đằng sau CRDTs, mà chúng ta đã gặp trong “CRDTs and Operational Transformation”. Tuy nhiên, một số thao tác như ghi có điều kiện không thể được tạo ra có tính giao hoán.
Mặt khác, phương thức giải quyết xung đột last write wins (LWW, thắng theo lần ghi cuối) dễ bị lost update, như đã thảo luận trong “Last write wins (discarding concurrent writes)”. Đáng tiếc là LWW là mặc định trong nhiều cơ sở dữ liệu được sao chép.
Write Skew và Phantom
Trong các phần trước chúng ta đã thấy dirty write và lost update, hai loại race condition có thể xảy ra khi các giao dịch khác nhau đồng thời cố ghi vào cùng các đối tượng. Để tránh hỏng dữ liệu, những race condition đó cần được ngăn chặn, hoặc tự động bởi cơ sở dữ liệu, hoặc bằng các biện pháp thủ công như sử dụng khóa hoặc thao tác ghi nguyên tử.
Tuy nhiên, đó chưa phải là hết các race condition tiềm ẩn có thể xảy ra giữa các lần ghi đồng thời. Trong phần này chúng ta sẽ thấy một số ví dụ tinh tế hơn về xung đột.
Để bắt đầu, hãy tưởng tượng ví dụ này: bạn đang viết ứng dụng cho các bác sĩ để quản lý ca trực của họ tại bệnh viện. Bệnh viện thường cố gắng có nhiều bác sĩ trực bất kỳ lúc nào, nhưng bắt buộc phải có ít nhất một bác sĩ trực. Các bác sĩ có thể từ bỏ ca trực của mình (ví dụ, nếu chính họ bị ốm), với điều kiện có ít nhất một đồng nghiệp vẫn còn trực trong ca đó 53 54.
Bây giờ hãy tưởng tượng Aaliyah và Bryce là hai bác sĩ trực cho một ca cụ thể. Cả hai cảm thấy không khỏe, vì vậy cả hai quyết định xin nghỉ. Đáng tiếc là họ tình cờ nhấp vào nút để rời ca trực vào khoảng cùng một thời điểm. Những gì xảy ra tiếp theo được minh họa trong Hình 8-8.
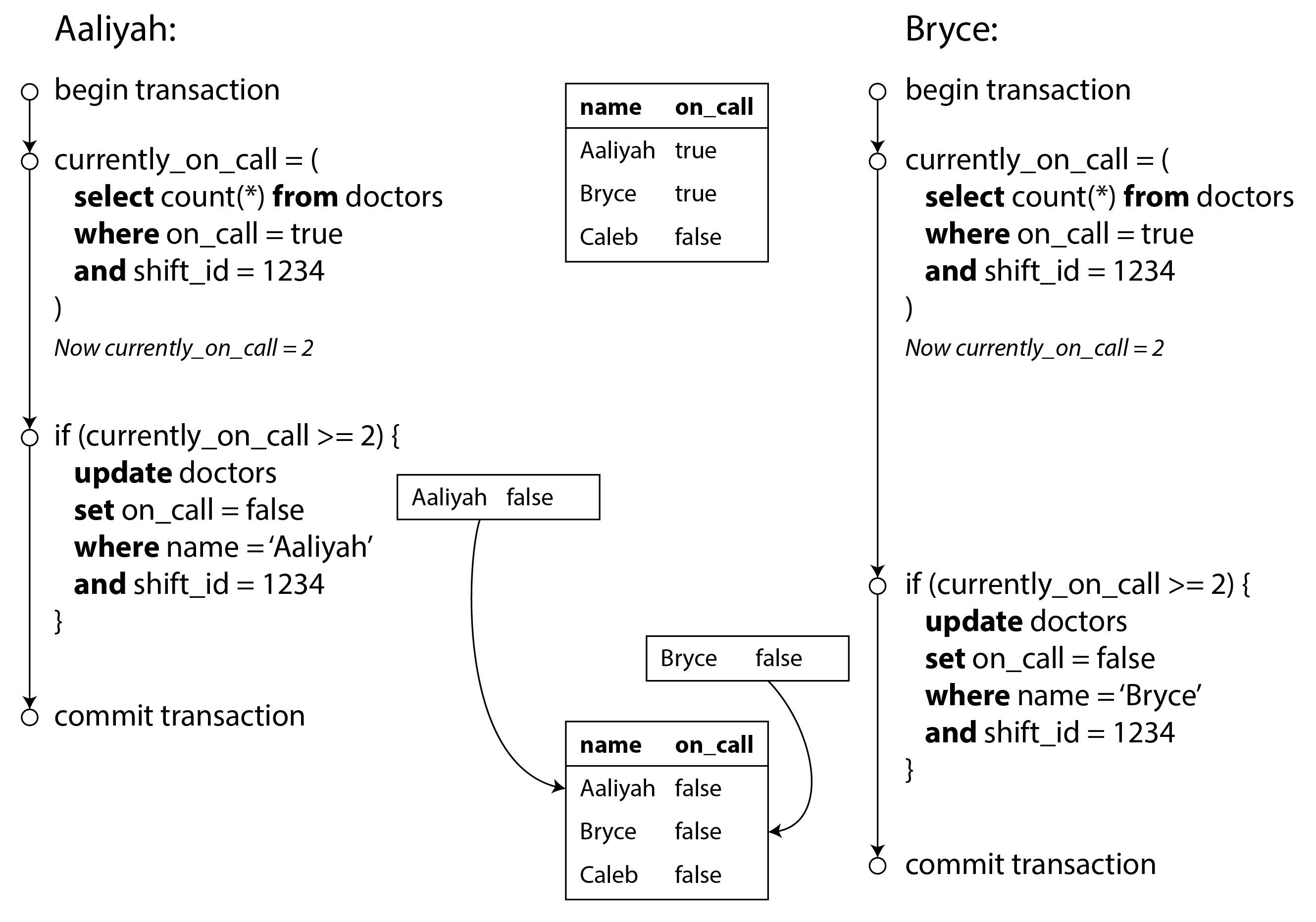
Trong mỗi giao dịch, ứng dụng của bạn trước tiên kiểm tra xem có hai bác sĩ trở lên đang trực hay không;
nếu có, nó cho rằng việc một bác sĩ rời ca trực là an toàn. Vì cơ sở dữ liệu đang sử dụng snapshot
isolation, cả hai kiểm tra đều trả về 2, vì vậy cả hai giao dịch tiến đến giai đoạn tiếp theo. Aaliyah cập nhật
bản ghi của mình để rời ca trực, và Bryce cập nhật bản ghi của mình tương tự. Cả hai giao dịch
commit, và bây giờ không có bác sĩ nào trực. Yêu cầu của bạn về việc có ít nhất một bác sĩ trực đã bị vi phạm.
Đặc điểm của write skew
Sự bất thường này được gọi là write skew (lệch ghi) 36. Nó không phải là dirty write cũng không phải lost update, vì hai giao dịch đang cập nhật hai đối tượng khác nhau (lần lượt là bản ghi trực của Aaliyah và Bryce). Ít rõ ràng hơn là một xung đột đã xảy ra ở đây, nhưng rõ ràng đây là một race condition: nếu hai giao dịch đã chạy lần lượt, thì bác sĩ thứ hai đã bị ngăn không cho rời ca trực. Hành vi bất thường chỉ xảy ra được vì các giao dịch chạy đồng thời.
Bạn có thể coi write skew là sự tổng quát hóa của vấn đề lost update. Write skew có thể xảy ra nếu hai giao dịch đọc cùng các đối tượng, và sau đó cập nhật một số đối tượng đó (các giao dịch khác nhau có thể cập nhật các đối tượng khác nhau). Trong trường hợp đặc biệt khi các giao dịch khác nhau cập nhật cùng một đối tượng, bạn sẽ gặp sự bất thường dirty write hoặc lost update (tùy thuộc vào thời điểm).
Chúng ta đã thấy rằng có nhiều cách khác nhau để ngăn chặn lost update. Với write skew, các lựa chọn của chúng ta bị hạn chế hơn:
Thao tác nguyên tử trên đối tượng đơn không giúp ích, vì nhiều đối tượng liên quan.
Tính năng tự động phát hiện lost update mà bạn thấy trong một số cài đặt snapshot isolation đáng tiếc cũng không giúp ích: write skew không được tự động phát hiện trong repeatable read của PostgreSQL, repeatable read của MySQL/InnoDB, serializable của Oracle, hay mức snapshot isolation của SQL Server 29. Tự động ngăn chặn write skew yêu cầu cô lập thực sự serializable (xem “Serializability”).
Một số cơ sở dữ liệu cho phép bạn cấu hình các ràng buộc, sau đó được cơ sở dữ liệu thực thi (ví dụ, tính duy nhất, ràng buộc khóa ngoại, hoặc hạn chế về một giá trị cụ thể). Tuy nhiên, để chỉ định rằng ít nhất một bác sĩ phải trực, bạn sẽ cần một ràng buộc liên quan đến nhiều đối tượng. Hầu hết các cơ sở dữ liệu không có hỗ trợ tích hợp cho các ràng buộc như vậy, nhưng bạn có thể có thể cài đặt chúng với trigger hoặc materialized view, như đã thảo luận trong “Consistency” 12.
Nếu bạn không thể sử dụng mức cô lập serializable, lựa chọn tốt thứ hai trong trường hợp này có lẽ là khóa tường minh các hàng mà giao dịch phụ thuộc vào. Trong ví dụ về bác sĩ, bạn có thể viết gì đó như sau:
BEGIN TRANSACTION; SELECT * FROM doctors WHERE on_call = true AND shift_id = 1234 FOR UPDATE; ❶ UPDATE doctors SET on_call = false WHERE name = 'Aaliyah' AND shift_id = 1234; COMMIT;
❶: Như trước đây, FOR UPDATE yêu cầu cơ sở dữ liệu khóa tất cả các hàng được trả về bởi truy vấn này.
Thêm ví dụ về write skew
Write skew thoạt đầu có vẻ là một vấn đề kỳ lạ, nhưng một khi bạn nhận thức được nó, bạn có thể nhận thấy nhiều tình huống hơn mà nó có thể xảy ra. Dưới đây là một số ví dụ khác:
- Hệ thống đặt phòng họp
- Giả sử bạn muốn đảm bảo rằng không thể có hai lần đặt chỗ cho cùng một phòng họp vào cùng thời điểm 55.
Khi ai đó muốn đặt chỗ, bạn trước tiên kiểm tra các lần đặt chỗ xung đột (tức là
các lần đặt chỗ cho cùng phòng với khoảng thời gian chồng lấp), và nếu không tìm thấy, bạn tạo
cuộc họp (xem Ví dụ 8-2).
Ví dụ 8-2. Hệ thống đặt phòng họp cố gắng tránh đặt chỗ trùng lặp (không an toàn dưới snapshot isolation)
BEGIN TRANSACTION; -- Check for any existing bookings that overlap with the period of noon-1pm SELECT COUNT(*) FROM bookings WHERE room_id = 123 AND end_time > '2025-01-01 12:00' AND start_time < '2025-01-01 13:00'; -- If the previous query returned zero: INSERT INTO bookings (room_id, start_time, end_time, user_id) VALUES (123, '2025-01-01 12:00', '2025-01-01 13:00', 666); COMMIT;Đáng tiếc là snapshot isolation không ngăn người dùng khác đồng thời chèn một cuộc họp xung đột. Để đảm bảo bạn sẽ không gặp xung đột lịch, bạn một lần nữa cần cô lập serializable.
- Trò chơi nhiều người
- Trong Ví dụ 8-1, chúng ta đã dùng khóa để ngăn chặn lost update (tức là đảm bảo rằng hai người chơi không thể di chuyển cùng một quân cờ vào cùng thời điểm). Tuy nhiên, khóa không ngăn người chơi di chuyển hai quân cờ khác nhau đến cùng một vị trí trên bàn cờ hoặc có thể thực hiện một nước đi nào đó vi phạm luật chơi. Tùy thuộc vào loại quy tắc bạn đang thực thi, bạn có thể sử dụng ràng buộc duy nhất, nhưng nếu không bạn dễ bị tổn thương bởi write skew.
- Đăng ký tên người dùng
- Trên một trang web nơi mỗi người dùng có tên người dùng duy nhất, hai người dùng có thể cố gắng tạo tài khoản với cùng tên người dùng vào cùng lúc. Bạn có thể sử dụng giao dịch để kiểm tra xem tên đã được lấy và nếu chưa, tạo tài khoản với tên đó. Tuy nhiên, như trong các ví dụ trước, điều đó không an toàn dưới snapshot isolation. May mắn là ràng buộc duy nhất là giải pháp đơn giản ở đây (giao dịch thứ hai cố gắng đăng ký tên người dùng sẽ bị hủy vì vi phạm ràng buộc).
- Ngăn chặn chi tiêu kép
- Một dịch vụ cho phép người dùng chi tiền hoặc điểm cần kiểm tra rằng người dùng không chi tiêu nhiều hơn số họ có. Bạn có thể cài đặt điều này bằng cách chèn một khoản chi tiêu tạm thời vào tài khoản người dùng, liệt kê tất cả các khoản trong tài khoản, và kiểm tra rằng tổng là dương. Với write skew, có thể xảy ra trường hợp hai khoản chi tiêu được chèn đồng thời mà cùng nhau khiến số dư âm, nhưng cả hai giao dịch đều không nhận ra giao dịch kia.
Phantom gây ra write skew
Tất cả các ví dụ này đều theo một mẫu tương tự:
Một truy vấn
SELECTkiểm tra xem một yêu cầu nào đó có được thỏa mãn hay không bằng cách tìm kiếm các hàng phù hợp với điều kiện tìm kiếm nào đó (có ít nhất hai bác sĩ trực, không có lần đặt chỗ nào hiện có cho phòng đó vào thời điểm đó, vị trí trên bàn cờ chưa có quân cờ khác, tên người dùng chưa được lấy, vẫn còn tiền trong tài khoản).Tùy thuộc vào kết quả của truy vấn đầu tiên, code ứng dụng quyết định cách tiếp tục (có thể tiến hành với thao tác, hoặc báo lỗi cho người dùng và hủy bỏ).
Nếu ứng dụng quyết định tiến hành, nó thực hiện một lần ghi (
INSERT,UPDATE, hoặcDELETE) vào cơ sở dữ liệu và commit giao dịch.Tác dụng của lần ghi này thay đổi điều kiện tiên quyết của quyết định ở bước 2. Nói cách khác, nếu bạn lặp lại truy vấn
SELECTtừ bước 1 sau khi commit lần ghi, bạn sẽ nhận được kết quả khác, vì lần ghi đã thay đổi tập hợp các hàng khớp với điều kiện tìm kiếm (bây giờ có một bác sĩ trực ít hơn, phòng họp hiện đã được đặt chỗ cho thời điểm đó, vị trí trên bàn cờ hiện đã bị chiếm bởi quân cờ đã được di chuyển, tên người dùng hiện đã bị lấy, hiện có ít tiền hơn trong tài khoản).
Các bước có thể xảy ra theo thứ tự khác nhau. Ví dụ, bạn có thể trước tiên thực hiện lần ghi, sau đó
truy vấn SELECT, và cuối cùng quyết định có hủy bỏ hay commit dựa trên kết quả của truy vấn.
Trong trường hợp ví dụ bác sĩ trực, hàng được sửa đổi ở bước 3 là một trong các hàng
được trả về ở bước 1, vì vậy chúng ta có thể làm cho giao dịch an toàn và tránh write skew bằng cách khóa các hàng
ở bước 1 (SELECT FOR UPDATE). Tuy nhiên, bốn ví dụ còn lại khác: chúng kiểm tra sự
vắng mặt của các hàng khớp với điều kiện tìm kiếm nào đó, và lần ghi thêm một hàng khớp với cùng
điều kiện. Nếu truy vấn ở bước 1 không trả về bất kỳ hàng nào, SELECT FOR UPDATE không thể gắn khóa vào
bất cứ thứ gì 56.
Hiệu ứng này, khi một lần ghi trong một giao dịch thay đổi kết quả của một truy vấn tìm kiếm trong giao dịch khác, được gọi là phantom (bóng ma) 4. Snapshot isolation tránh phantom trong các truy vấn chỉ đọc, nhưng trong các giao dịch đọc-ghi như các ví dụ chúng ta đã thảo luận, phantom có thể dẫn đến các trường hợp đặc biệt phức tạp của write skew. SQL được tạo ra bởi ORM cũng dễ bị write skew 50 51.
Vật chất hóa xung đột (Materializing conflicts)
Nếu vấn đề của phantom là không có đối tượng nào để chúng ta có thể gắn khóa vào, có lẽ chúng ta có thể giả tạo giới thiệu một đối tượng khóa vào cơ sở dữ liệu?
Ví dụ, trong trường hợp đặt phòng họp, bạn có thể tưởng tượng tạo một bảng các khe thời gian và phòng. Mỗi hàng trong bảng này tương ứng với một phòng cụ thể cho một khoảng thời gian cụ thể (giả sử 15 phút). Bạn tạo các hàng cho tất cả các kết hợp phòng và khoảng thời gian có thể trước, ví dụ cho sáu tháng tới.
Bây giờ một giao dịch muốn tạo một lần đặt chỗ có thể khóa (SELECT FOR UPDATE) các hàng trong
bảng tương ứng với phòng và khoảng thời gian mong muốn. Sau khi có được khóa, nó có thể
kiểm tra các lần đặt chỗ chồng lấp và chèn một lần đặt chỗ mới như trước. Lưu ý rằng bảng bổ sung
không được sử dụng để lưu trữ thông tin về lần đặt chỗ, mà hoàn toàn là một tập hợp khóa được dùng
để ngăn chặn các lần đặt chỗ trên cùng phòng và khoảng thời gian được sửa đổi đồng thời.
Cách tiếp cận này được gọi là materializing conflicts (vật chất hóa xung đột), vì nó lấy một phantom và biến nó thành một xung đột khóa trên một tập hợp hàng cụ thể tồn tại trong cơ sở dữ liệu 14. Đáng tiếc là có thể khó và dễ xảy ra lỗi khi tìm ra cách vật chất hóa xung đột, và thật xấu khi để cơ chế kiểm soát đồng thời lộ ra trong mô hình dữ liệu ứng dụng. Vì những lý do đó, materializing conflicts nên được coi là phương án cuối cùng khi không có lựa chọn nào khác. Mức cô lập serializable thì được ưa thích hơn nhiều trong hầu hết các trường hợp.
Serializability (Khả năng tuần tự hóa)
Trong chương này chúng ta đã thấy một số ví dụ về các giao dịch dễ bị race condition. Một số race condition được ngăn chặn bởi các mức cô lập read committed và snapshot isolation, nhưng các race condition khác thì không. Chúng ta đã gặp một số ví dụ đặc biệt phức tạp với write skew và phantom. Đây là tình huống đáng buồn:
- Các mức cô lập khó hiểu và được cài đặt không nhất quán trong các cơ sở dữ liệu khác nhau (ví dụ, ý nghĩa của “repeatable read” thay đổi đáng kể).
- Nếu bạn xem xét code ứng dụng của mình, thật khó để biết liệu nó có an toàn khi chạy ở một mức cô lập cụ thể hay không, đặc biệt là trong một ứng dụng lớn, nơi bạn có thể không biết tất cả những gì đang xảy ra đồng thời.
- Không có công cụ tốt nào giúp chúng ta phát hiện race condition. Về nguyên tắc, phân tích tĩnh có thể hữu ích 33, nhưng các kỹ thuật nghiên cứu vẫn chưa tìm được ứng dụng thực tiễn. Kiểm thử các vấn đề đồng thời rất khó, vì chúng là thường không mang tính xác định, các vấn đề chỉ xảy ra nếu bạn gặp đúng lúc không may.
Đây không phải vấn đề mới, nó đã tồn tại từ những năm 1970 khi các mức cô lập yếu lần đầu được giới thiệu 3. Suốt thời gian đó, câu trả lời từ các nhà nghiên cứu luôn đơn giản: hãy dùng cô lập serializable (tuần tự hóa)!
Cô lập serializable là mức cô lập mạnh nhất. Nó đảm bảo rằng dù các giao dịch có thể thực thi song song, kết quả cuối cùng vẫn giống như khi chúng thực thi lần lượt từng cái một, theo thứ tự tuần tự, không có bất kỳ sự đồng thời nào. Như vậy, cơ sở dữ liệu đảm bảo rằng nếu các giao dịch hoạt động đúng khi chạy riêng lẻ, chúng vẫn tiếp tục đúng khi chạy đồng thời, nói cách khác, cơ sở dữ liệu ngăn chặn tất cả các race condition (điều kiện tranh chấp) có thể xảy ra.
Nhưng nếu cô lập serializable tốt hơn nhiều so với mớ hỗn độn của các mức cô lập yếu, tại sao không phải ai cũng dùng nó? Để trả lời câu hỏi này, chúng ta cần xem xét các phương án triển khai serializability và hiệu năng của chúng. Hầu hết các cơ sở dữ liệu cung cấp serializability ngày nay dùng một trong ba kỹ thuật, mà chúng ta sẽ khám phá trong phần còn lại của chương này:
- Thực thi các giao dịch theo thứ tự tuần tự thực sự (xem “Actual Serial Execution”)
- Two-phase locking (khóa hai pha) (xem “Two-Phase Locking (2PL)”), vốn là lựa chọn khả thi duy nhất trong nhiều thập kỷ
- Các kỹ thuật kiểm soát đồng thời lạc quan như serializable snapshot isolation (xem “Serializable Snapshot Isolation (SSI)”)
Actual Serial Execution
Cách đơn giản nhất để tránh các vấn đề đồng thời là loại bỏ hoàn toàn sự đồng thời: chỉ thực thi một giao dịch tại một thời điểm, theo thứ tự tuần tự, trên một luồng đơn. Bằng cách đó, chúng ta hoàn toàn né tránh vấn đề phát hiện và ngăn chặn xung đột giữa các giao dịch: mức cô lập thu được theo định nghĩa là serializable.
Dù ý tưởng này có vẻ hiển nhiên, mãi đến những năm 2000 các nhà thiết kế cơ sở dữ liệu mới quyết định rằng một vòng lặp đơn luồng để thực thi giao dịch là khả thi 57. Nếu đồng thời đa luồng được xem là thiết yếu để đạt hiệu năng tốt trong suốt 30 năm trước đó, thì điều gì đã thay đổi để thực thi đơn luồng trở nên khả thi?
Hai bước phát triển đã tạo ra sự thay đổi tư duy này:
- RAM trở nên đủ rẻ để trong nhiều trường hợp sử dụng, toàn bộ tập dữ liệu đang hoạt động có thể được lưu trong bộ nhớ (xem “Keeping everything in memory”). Khi tất cả dữ liệu mà một giao dịch cần truy cập đều có trong bộ nhớ, giao dịch có thể thực thi nhanh hơn nhiều so với khi phải chờ dữ liệu được nạp từ đĩa.
- Các nhà thiết kế cơ sở dữ liệu nhận ra rằng các giao dịch OLTP thường ngắn và chỉ thực hiện một số lượng nhỏ các thao tác đọc và ghi (xem “Analytical versus Operational Systems”). Ngược lại, các truy vấn phân tích chạy dài thường chỉ đọc, do đó chúng có thể chạy trên một snapshot nhất quán (dùng snapshot isolation) bên ngoài vòng lặp thực thi tuần tự.
Phương pháp thực thi giao dịch tuần tự được triển khai trong VoltDB/H-Store, Redis và Datomic, chẳng hạn 58 59 60. Một hệ thống được thiết kế cho thực thi đơn luồng đôi khi có thể hoạt động tốt hơn hệ thống hỗ trợ đồng thời, vì nó tránh được chi phí điều phối của việc khóa. Tuy nhiên, thông lượng của nó bị giới hạn ở tốc độ của một lõi CPU duy nhất. Để tận dụng tối đa luồng đơn đó, các giao dịch cần được cấu trúc khác với dạng truyền thống.
Đóng gói giao dịch trong stored procedure
Trong những ngày đầu của cơ sở dữ liệu, ý định là một giao dịch cơ sở dữ liệu có thể bao gồm toàn bộ luồng hoạt động của người dùng. Ví dụ, đặt vé máy bay là một quy trình nhiều bước (tìm kiếm tuyến đường, giá vé và chỗ trống; quyết định hành trình; đặt chỗ trên từng chuyến bay của hành trình; nhập thông tin hành khách; thanh toán). Các nhà thiết kế cơ sở dữ liệu cho rằng sẽ gọn gàng nếu toàn bộ quy trình đó là một giao dịch để có thể được commit một cách atomic.
Thật không may, con người rất chậm trong việc đưa ra quyết định và phản hồi. Nếu một giao dịch cơ sở dữ liệu cần chờ đầu vào từ người dùng, cơ sở dữ liệu cần hỗ trợ một số lượng giao dịch đồng thời có khả năng rất lớn, hầu hết đang ở trạng thái rảnh. Hầu hết các cơ sở dữ liệu không thể làm điều đó hiệu quả, do đó hầu hết tất cả các ứng dụng OLTP giữ cho giao dịch ngắn bằng cách tránh chờ đợi tương tác từ người dùng trong một giao dịch. Trên web, điều này có nghĩa là một giao dịch được commit trong cùng một HTTP request, một giao dịch không kéo dài qua nhiều request. Một HTTP request mới bắt đầu một giao dịch mới.
Dù con người đã được đưa ra khỏi đường dẫn quan trọng, các giao dịch vẫn tiếp tục được thực thi theo kiểu tương tác client/server, từng câu lệnh một. Một ứng dụng thực hiện một truy vấn, đọc kết quả, có thể thực hiện một truy vấn khác tùy thuộc vào kết quả của truy vấn đầu tiên, và cứ thế tiếp tục. Các truy vấn và kết quả được gửi qua lại giữa code ứng dụng (chạy trên một máy) và máy chủ cơ sở dữ liệu (trên một máy khác).
Trong kiểu giao dịch tương tác này, rất nhiều thời gian được dành cho việc giao tiếp mạng giữa ứng dụng và cơ sở dữ liệu. Nếu bạn không cho phép đồng thời trong cơ sở dữ liệu và chỉ xử lý một giao dịch tại một thời điểm, thông lượng sẽ rất tệ vì cơ sở dữ liệu sẽ dành hầu hết thời gian chờ ứng dụng phát ra truy vấn tiếp theo cho giao dịch hiện tại. Trong loại cơ sở dữ liệu này, cần phải xử lý nhiều giao dịch đồng thời để đạt được hiệu năng hợp lý.
Vì lý do này, các hệ thống xử lý giao dịch tuần tự đơn luồng không cho phép các giao dịch đa câu lệnh tương tác. Thay vào đó, ứng dụng phải tự giới hạn trong các giao dịch chứa một câu lệnh duy nhất, hoặc gửi toàn bộ code giao dịch đến cơ sở dữ liệu trước, dưới dạng stored procedure (thủ tục lưu trữ) 61.
Sự khác biệt giữa các giao dịch tương tác và stored procedure được minh họa trong Hình 8-9. Với điều kiện tất cả dữ liệu cần thiết cho một giao dịch đều có trong bộ nhớ, stored procedure có thể thực thi rất nhanh, không cần chờ bất kỳ thao tác I/O mạng hay đĩa nào.
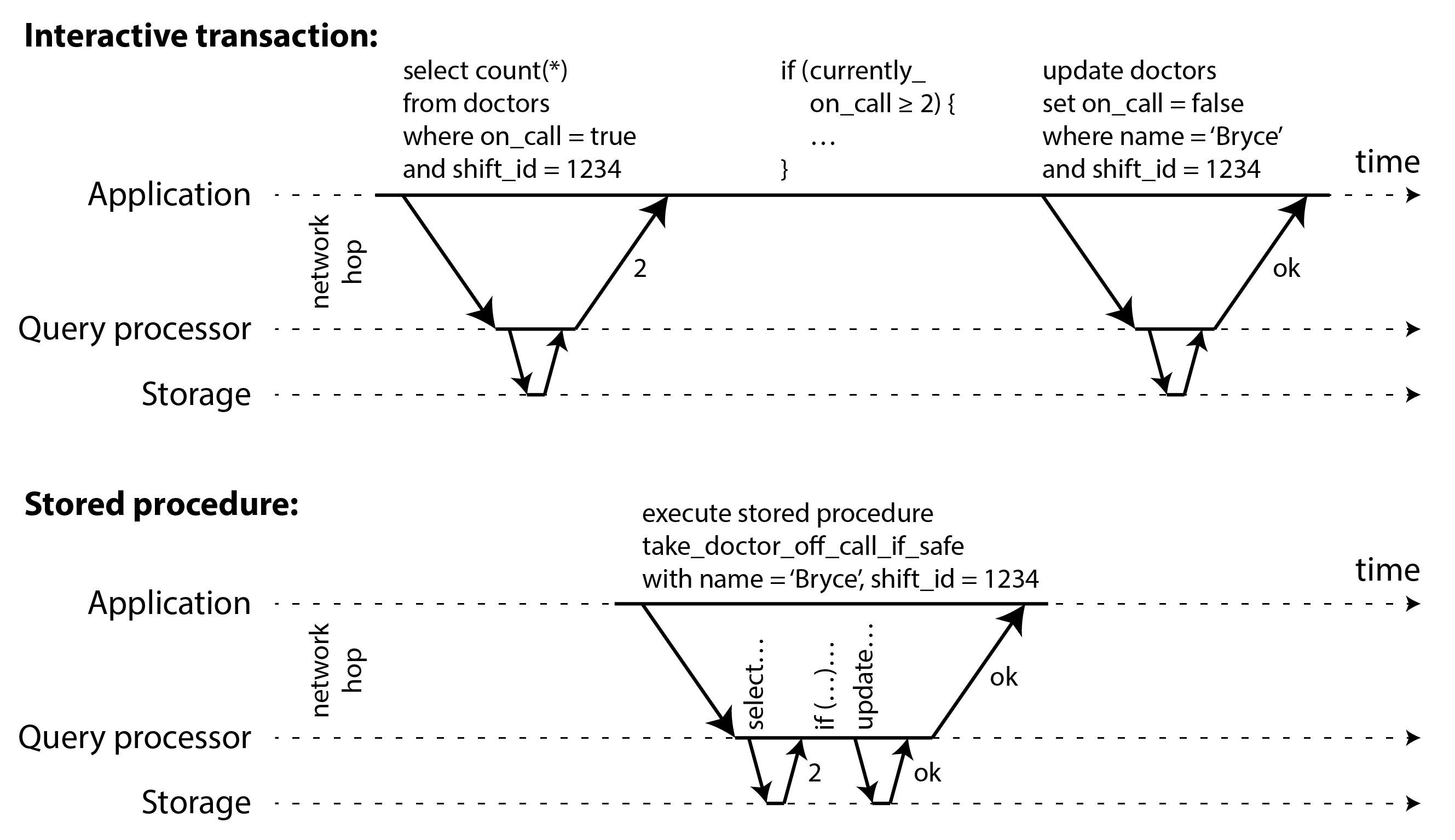
Ưu và nhược điểm của stored procedure
Stored procedure đã tồn tại một thời gian trong các cơ sở dữ liệu quan hệ và đã là một phần của tiêu chuẩn SQL (SQL/PSM) từ năm 1999. Chúng đã có tiếng xấu một phần vì nhiều lý do:
- Theo truyền thống, mỗi nhà cung cấp cơ sở dữ liệu có ngôn ngữ riêng cho stored procedure (Oracle có PL/SQL, SQL Server có T-SQL, PostgreSQL có PL/pgSQL, v.v.). Các ngôn ngữ này không theo kịp sự phát triển của các ngôn ngữ lập trình đa dụng, nên chúng trông khá xấu xí và lỗi thời theo quan điểm ngày nay, và thiếu hệ sinh thái thư viện mà bạn tìm thấy ở hầu hết các ngôn ngữ lập trình.
- Code chạy trong cơ sở dữ liệu khó quản lý hơn: so với máy chủ ứng dụng, nó khó debug hơn, khó duy trì trong version control và triển khai hơn, khó test hơn, và khó tích hợp với hệ thống thu thập metrics để giám sát hơn.
- Cơ sở dữ liệu thường nhạy cảm hơn nhiều về hiệu năng so với máy chủ ứng dụng, vì một phiên bản cơ sở dữ liệu duy nhất thường được chia sẻ bởi nhiều máy chủ ứng dụng. Một stored procedure viết kém (ví dụ dùng nhiều bộ nhớ hoặc thời gian CPU) trong cơ sở dữ liệu có thể gây ra nhiều rắc rối hơn nhiều so với code viết kém tương đương trong máy chủ ứng dụng.
- Trong một hệ thống multitenant (đa người thuê) cho phép người thuê viết stored procedure của riêng họ, thực thi code không đáng tin cậy trong cùng tiến trình với kernel cơ sở dữ liệu là một rủi ro bảo mật 62.
Tuy nhiên, những vấn đề đó có thể được khắc phục. Các triển khai hiện đại của stored procedure đã bỏ PL/SQL và thay vào đó dùng các ngôn ngữ lập trình đa dụng hiện có: VoltDB dùng Java hoặc Groovy, Datomic dùng Java hoặc Clojure, Redis dùng Lua, và MongoDB dùng JavaScript.
Stored procedure cũng hữu ích trong các trường hợp logic ứng dụng không thể dễ dàng được nhúng vào chỗ khác. Các ứng dụng dùng GraphQL, ví dụ, có thể trực tiếp expose cơ sở dữ liệu của họ thông qua một GraphQL proxy. Nếu proxy không hỗ trợ logic validation phức tạp, bạn có thể nhúng logic đó trực tiếp vào cơ sở dữ liệu dùng một stored procedure. Nếu cơ sở dữ liệu không hỗ trợ stored procedure, bạn sẽ phải triển khai một dịch vụ validation giữa proxy và cơ sở dữ liệu để thực hiện validation.
Với stored procedure và dữ liệu trong bộ nhớ, việc thực thi tất cả giao dịch trên một luồng đơn trở nên khả thi. Khi stored procedure không cần chờ I/O và tránh được chi phí của các cơ chế kiểm soát đồng thời khác, chúng có thể đạt được thông lượng khá tốt trên một luồng đơn.
VoltDB cũng dùng stored procedure để replication: thay vì sao chép các thao tác ghi của một giao dịch từ nút này sang nút khác, nó thực thi cùng một stored procedure trên mỗi bản sao. Do đó VoltDB yêu cầu rằng stored procedure phải deterministic (xác định, khi chạy trên các nút khác nhau, chúng phải cho ra cùng kết quả). Ví dụ, nếu một giao dịch cần dùng ngày và giờ hiện tại, nó phải thực hiện thông qua các API deterministic đặc biệt (xem “Durable Execution and Workflows” để biết thêm chi tiết về các thao tác deterministic). Phương pháp này được gọi là state machine replication (sao chép máy trạng thái), và chúng ta sẽ trở lại với nó trong Chương 10.
Sharding
Thực thi tất cả giao dịch theo thứ tự tuần tự giúp kiểm soát đồng thời đơn giản hơn nhiều, nhưng giới hạn thông lượng giao dịch của cơ sở dữ liệu ở tốc độ của một lõi CPU duy nhất trên một máy duy nhất. Các giao dịch chỉ đọc có thể thực thi ở nơi khác, dùng snapshot isolation, nhưng đối với các ứng dụng có thông lượng ghi cao, bộ xử lý giao dịch đơn luồng có thể trở thành một nút thắt cổ chai nghiêm trọng.
Để mở rộng sang nhiều lõi CPU và nhiều nút, bạn có thể phân mảnh (shard) dữ liệu của mình (xem Chương 7), được hỗ trợ trong VoltDB. Nếu bạn có thể tìm cách phân mảnh tập dữ liệu sao cho mỗi giao dịch chỉ cần đọc và ghi dữ liệu trong một shard duy nhất, thì mỗi shard có thể có luồng xử lý giao dịch riêng chạy độc lập với các shard khác. Trong trường hợp này, bạn có thể dành mỗi lõi CPU cho một shard, cho phép thông lượng giao dịch của bạn tăng tuyến tính theo số lõi CPU 59.
Tuy nhiên, đối với bất kỳ giao dịch nào cần truy cập nhiều shard, cơ sở dữ liệu phải điều phối giao dịch trên tất cả các shard mà nó chạm vào. Stored procedure cần được thực hiện đồng bộ (lock-step) trên tất cả các shard để đảm bảo serializability trên toàn hệ thống.
Vì các giao dịch cross-shard có thêm chi phí điều phối, chúng chậm hơn rất nhiều so với các giao dịch đơn shard. VoltDB báo cáo thông lượng khoảng 1.000 lần ghi cross-shard mỗi giây, thấp hơn nhiều bậc so với thông lượng đơn shard của nó và không thể tăng bằng cách thêm máy 61. Các nghiên cứu gần đây hơn đã khám phá các cách làm cho các giao dịch đa shard có thể mở rộng hơn 63.
Liệu các giao dịch có thể là đơn shard hay không phụ thuộc rất nhiều vào cấu trúc dữ liệu được ứng dụng sử dụng. Dữ liệu key-value đơn giản thường có thể được phân mảnh dễ dàng, nhưng dữ liệu có nhiều secondary index (chỉ mục phụ) có khả năng cần nhiều điều phối cross-shard (xem “Sharding and Secondary Indexes”).
Tóm tắt về thực thi tuần tự
Thực thi giao dịch tuần tự đã trở thành một cách khả thi để đạt được cô lập serializable trong một số ràng buộc nhất định:
- Mỗi giao dịch phải nhỏ và nhanh, vì chỉ cần một giao dịch chậm là có thể làm đình trệ toàn bộ việc xử lý giao dịch.
- Phù hợp nhất trong các tình huống mà tập dữ liệu đang hoạt động có thể vừa vào bộ nhớ. Dữ liệu ít được truy cập có thể được chuyển sang đĩa, nhưng nếu cần truy cập trong một giao dịch đơn luồng, hệ thống sẽ rất chậm.
- Thông lượng ghi phải đủ thấp để được xử lý trên một lõi CPU duy nhất, nếu không các giao dịch cần được phân mảnh mà không cần điều phối cross-shard.
- Các giao dịch cross-shard là có thể, nhưng thông lượng của chúng khó mở rộng.
Two-Phase Locking (2PL)
Trong khoảng 30 năm, chỉ có một thuật toán được sử dụng rộng rãi cho serializability trong cơ sở dữ liệu: two-phase locking (khóa hai pha, 2PL), đôi khi được gọi là strong strict two-phase locking (SS2PL) để phân biệt với các biến thể khác của 2PL.
2PL IS NOT 2PC
Two-phase locking (2PL) và two-phase commit (2PC) là hai thứ rất khác nhau. 2PL cung cấp cô lập serializable, trong khi 2PC cung cấp commit nguyên tử trong cơ sở dữ liệu phân tán (xem “Two-Phase Commit (2PC)”). Để tránh nhầm lẫn, tốt nhất hãy coi chúng là các khái niệm hoàn toàn riêng biệt và bỏ qua sự tương đồng đáng tiếc trong tên gọi.
Chúng ta đã thấy trước đó rằng các khóa thường được dùng để ngăn chặn dirty write (ghi bẩn) (xem “No dirty writes”): nếu hai giao dịch đồng thời cố gắng ghi vào cùng một đối tượng, khóa đảm bảo rằng bên ghi thứ hai phải chờ cho đến khi bên đầu tiên đã hoàn thành giao dịch của mình (hủy bỏ hoặc commit) trước khi có thể tiếp tục.
Two-phase locking tương tự, nhưng làm cho các yêu cầu khóa mạnh hơn nhiều. Nhiều giao dịch được phép đọc đồng thời cùng một đối tượng miễn là không có ai đang ghi vào nó. Nhưng ngay khi có ai muốn ghi (sửa đổi hoặc xóa) một đối tượng, quyền truy cập độc quyền là bắt buộc:
- Nếu giao dịch A đã đọc một đối tượng và giao dịch B muốn ghi vào đối tượng đó, B phải chờ cho đến khi A commit hoặc hủy bỏ trước khi có thể tiếp tục. (Điều này đảm bảo rằng B không thể thay đổi đối tượng một cách bất ngờ sau lưng A.)
- Nếu giao dịch A đã ghi một đối tượng và giao dịch B muốn đọc đối tượng đó, B phải chờ cho đến khi A commit hoặc hủy bỏ trước khi có thể tiếp tục. (Đọc một phiên bản cũ của đối tượng, như trong Hình 8-4, là không chấp nhận được trong 2PL.)
Trong 2PL, bên ghi không chỉ chặn các bên ghi khác mà còn chặn cả bên đọc và ngược lại. Snapshot isolation có phương châm bên đọc không bao giờ chặn bên ghi, và bên ghi không bao giờ chặn bên đọc (xem “Multi-version concurrency control (MVCC)”), điều này nắm bắt được sự khác biệt chính giữa snapshot isolation và two-phase locking. Mặt khác, vì 2PL cung cấp serializability, nó bảo vệ chống lại tất cả các race condition đã thảo luận trước đó, bao gồm cả lost update và write skew.
Triển khai two-phase locking
2PL được dùng bởi mức cô lập serializable trong MySQL (InnoDB) và SQL Server, và mức cô lập repeatable read trong Db2 29.
Việc chặn bên đọc và bên ghi được triển khai bằng cách có một khóa trên mỗi đối tượng trong cơ sở dữ liệu. Khóa có thể ở chế độ chia sẻ hoặc chế độ độc quyền (còn được gọi là khóa multi-reader single-writer). Khóa được dùng như sau:
- Nếu một giao dịch muốn đọc một đối tượng, nó phải trước tiên lấy khóa ở chế độ chia sẻ. Nhiều giao dịch được phép giữ khóa ở chế độ chia sẻ đồng thời, nhưng nếu một giao dịch khác đã có khóa độc quyền trên đối tượng, các giao dịch này phải chờ.
- Nếu một giao dịch muốn ghi vào một đối tượng, nó phải trước tiên lấy khóa ở chế độ độc quyền. Không có giao dịch nào khác có thể giữ khóa cùng lúc (ở chế độ chia sẻ hay độc quyền), vì vậy nếu có bất kỳ khóa nào đang tồn tại trên đối tượng, giao dịch phải chờ.
- Nếu một giao dịch trước tiên đọc rồi sau đó ghi một đối tượng, nó có thể nâng cấp khóa chia sẻ của mình lên khóa độc quyền. Việc nâng cấp hoạt động giống như lấy khóa độc quyền trực tiếp.
- Sau khi một giao dịch đã lấy được khóa, nó phải tiếp tục giữ khóa đó cho đến cuối giao dịch (commit hoặc hủy bỏ). Đây là lý do tên gọi “two-phase” (hai pha): pha đầu (trong khi giao dịch đang thực thi) là khi các khóa được lấy, và pha thứ hai (ở cuối giao dịch) là khi tất cả các khóa được giải phóng.
Vì có quá nhiều khóa đang được dùng, có thể dễ dàng xảy ra trường hợp giao dịch A đang chờ giao dịch B giải phóng khóa của nó, và ngược lại. Tình huống này được gọi là deadlock (khóa chết). Cơ sở dữ liệu tự động phát hiện deadlock giữa các giao dịch và hủy bỏ một trong số chúng để các giao dịch khác có thể tiếp tục. Giao dịch bị hủy bỏ cần được ứng dụng thử lại.
Hiệu năng của two-phase locking
Nhược điểm lớn của two-phase locking, và lý do tại sao nó không được mọi người sử dụng từ những năm 1970, là hiệu năng: thông lượng giao dịch và thời gian phản hồi của các truy vấn kém hơn đáng kể dưới two-phase locking so với dưới cô lập yếu.
Điều này một phần do chi phí lấy và giải phóng tất cả các khóa đó, nhưng quan trọng hơn là do giảm tính đồng thời. Theo thiết kế, nếu hai giao dịch đồng thời cố gắng làm bất cứ điều gì có thể dẫn đến race condition theo bất kỳ cách nào, một giao dịch phải chờ giao dịch kia hoàn thành.
Ví dụ, nếu bạn có một giao dịch cần đọc toàn bộ bảng (ví dụ: backup, truy vấn phân tích, hoặc kiểm tra tính toàn vẹn, như đã thảo luận trong “Snapshot Isolation and Repeatable Read”), giao dịch đó phải lấy khóa chia sẻ trên toàn bộ bảng. Do đó, giao dịch đọc trước tiên phải chờ cho đến khi tất cả các giao dịch đang ghi vào bảng đó hoàn thành; sau đó, trong khi toàn bộ bảng đang được đọc (có thể mất nhiều thời gian trên một bảng lớn), tất cả các giao dịch khác muốn ghi vào bảng đó đều bị chặn cho đến khi giao dịch chỉ đọc lớn đó commit. Trên thực tế, cơ sở dữ liệu trở nên không khả dụng cho các thao tác ghi trong một khoảng thời gian dài.
Vì lý do này, các cơ sở dữ liệu chạy 2PL có thể có độ trễ khá không ổn định, và chúng có thể rất chậm ở các percentile cao (xem “Describing Performance”) nếu có tranh chấp trong khối lượng công việc. Chỉ cần một giao dịch chậm, hoặc một giao dịch truy cập nhiều dữ liệu và lấy nhiều khóa, là có thể khiến phần còn lại của hệ thống tê liệt.
Dù deadlock có thể xảy ra với mức cô lập read committed dựa trên khóa, chúng xảy ra thường xuyên hơn nhiều dưới cô lập serializable 2PL (tùy thuộc vào các mẫu truy cập của giao dịch). Đây có thể là một vấn đề hiệu năng bổ sung: khi một giao dịch bị hủy bỏ do deadlock và được thử lại, nó cần làm lại toàn bộ công việc của mình. Nếu deadlock xảy ra thường xuyên, điều này có thể gây ra lãng phí công sức đáng kể.
Predicate lock
Trong mô tả trước về các khóa, chúng ta đã bỏ qua một chi tiết tinh tế nhưng quan trọng. Trong “Phantoms causing write skew” chúng ta đã thảo luận về vấn đề phantom (bóng ma), nghĩa là một giao dịch thay đổi kết quả của truy vấn tìm kiếm của giao dịch khác. Một cơ sở dữ liệu với cô lập serializable phải ngăn chặn phantom.
Trong ví dụ đặt phòng họp, điều này có nghĩa là nếu một giao dịch đã tìm kiếm các đặt chỗ hiện có cho một phòng trong một khoảng thời gian nhất định (xem Ví dụ 8-2), một giao dịch khác không được phép đồng thời chèn hoặc cập nhật một đặt chỗ khác cho cùng phòng và khoảng thời gian đó. (Việc đồng thời chèn đặt chỗ cho các phòng khác, hoặc cùng phòng nhưng ở thời điểm khác không ảnh hưởng đến đặt chỗ được đề xuất, là được.)
Làm thế nào để triển khai điều này? Về mặt khái niệm, chúng ta cần một predicate lock (khóa vị từ) 4. Nó hoạt động tương tự như khóa chia sẻ/độc quyền đã mô tả trước đó, nhưng thay vì thuộc về một đối tượng cụ thể (ví dụ: một hàng trong bảng), nó thuộc về tất cả các đối tượng phù hợp với một điều kiện tìm kiếm nào đó, chẳng hạn như:
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2025-01-01 12:00' AND
start_time < '2025-01-01 13:00';Một predicate lock hạn chế truy cập như sau:
- Nếu giao dịch A muốn đọc các đối tượng khớp với một điều kiện nào đó, như trong truy vấn
SELECTđó, nó phải lấy khóa predicate chế độ chia sẻ trên các điều kiện của truy vấn. Nếu một giao dịch B khác hiện đang có khóa độc quyền trên bất kỳ đối tượng nào khớp với các điều kiện đó, A phải chờ cho đến khi B giải phóng khóa của nó trước khi được phép thực hiện truy vấn. - Nếu giao dịch A muốn chèn, cập nhật hoặc xóa bất kỳ đối tượng nào, trước tiên nó phải kiểm tra xem giá trị cũ hay mới có khớp với bất kỳ predicate lock hiện có nào không. Nếu có predicate lock khớp được giữ bởi giao dịch B, thì A phải chờ cho đến khi B đã commit hoặc hủy bỏ trước khi có thể tiếp tục.
Ý tưởng chính ở đây là predicate lock áp dụng ngay cả với các đối tượng chưa tồn tại trong cơ sở dữ liệu nhưng có thể được thêm vào trong tương lai (phantom). Nếu two-phase locking bao gồm predicate lock, cơ sở dữ liệu ngăn chặn mọi dạng write skew và race condition khác, và do đó mức cô lập của nó trở thành serializable.
Index-range lock
Thật không may, predicate lock hoạt động không hiệu quả: nếu có nhiều khóa do các giao dịch đang hoạt động, việc kiểm tra các khóa khớp trở nên tốn thời gian. Vì lý do đó, hầu hết các cơ sở dữ liệu với 2PL thực sự triển khai index-range locking (khóa phạm vi chỉ mục, còn được gọi là next-key locking), là một xấp xỉ đơn giản hóa của predicate locking 54 64.
Việc đơn giản hóa một predicate bằng cách cho nó khớp với một tập đối tượng lớn hơn là an toàn. Ví dụ, nếu bạn có predicate lock cho các đặt chỗ phòng 123 từ 12 giờ đến 13 giờ, bạn có thể xấp xỉ nó bằng cách khóa tất cả đặt chỗ phòng 123 vào bất kỳ thời điểm nào, hoặc bạn có thể xấp xỉ nó bằng cách khóa tất cả các phòng (không chỉ phòng 123) từ 12 giờ đến 13 giờ. Điều này an toàn vì bất kỳ thao tác ghi nào khớp với predicate ban đầu chắc chắn cũng sẽ khớp với các xấp xỉ.
Trong cơ sở dữ liệu đặt phòng, bạn có thể có một chỉ mục trên cột room_id, và/hoặc các chỉ mục trên start_time và end_time (nếu không thì truy vấn trước đó sẽ rất chậm trên cơ sở dữ liệu lớn):
- Giả sử chỉ mục của bạn trên
room_id, và cơ sở dữ liệu dùng chỉ mục này để tìm các đặt chỗ hiện có cho phòng 123. Bây giờ cơ sở dữ liệu có thể đơn giản đính kèm khóa chia sẻ vào mục chỉ mục này, chỉ ra rằng một giao dịch đã tìm kiếm các đặt chỗ của phòng 123. - Hoặc nếu cơ sở dữ liệu dùng chỉ mục dựa trên thời gian để tìm các đặt chỗ hiện có, nó có thể đính kèm khóa chia sẻ vào một phạm vi giá trị trong chỉ mục đó, chỉ ra rằng một giao dịch đã tìm kiếm các đặt chỗ chồng lên khoảng thời gian từ 12 giờ đến 13 giờ ngày 1 tháng 1 năm 2025.
Dù bằng cách nào, một xấp xỉ của điều kiện tìm kiếm được đính kèm vào một trong các chỉ mục. Bây giờ, nếu một giao dịch khác muốn chèn, cập nhật hoặc xóa một đặt chỗ cho cùng phòng và/hoặc khoảng thời gian chồng nhau, nó sẽ phải cập nhật cùng phần của chỉ mục. Trong quá trình làm như vậy, nó sẽ gặp khóa chia sẻ và sẽ bị buộc phải chờ cho đến khi khóa được giải phóng.
Điều này cung cấp sự bảo vệ hiệu quả chống lại phantom và write skew. Index-range lock không chính xác như predicate lock (chúng có thể khóa phạm vi đối tượng lớn hơn mức thực sự cần thiết để duy trì serializability), nhưng vì chúng có chi phí thấp hơn nhiều, chúng là một sự đánh đổi tốt.
Nếu không có chỉ mục phù hợp để đính kèm range lock, cơ sở dữ liệu có thể dùng khóa chia sẻ trên toàn bộ bảng như phương án dự phòng. Điều này sẽ không tốt cho hiệu năng, vì nó sẽ ngăn tất cả các giao dịch khác ghi vào bảng, nhưng đây là vị trí dự phòng an toàn.
Serializable Snapshot Isolation (SSI)
Chương này đã vẽ nên một bức tranh ảm đạm về kiểm soát đồng thời trong cơ sở dữ liệu. Một mặt, chúng ta có các triển khai serializability hoạt động không tốt (two-phase locking) hoặc không mở rộng tốt (thực thi tuần tự). Mặt khác, chúng ta có các mức cô lập yếu có hiệu năng tốt, nhưng dễ bị các race condition khác nhau (lost update, write skew, phantom, v.v.). Liệu cô lập serializable và hiệu năng tốt có thực sự mâu thuẫn với nhau không?
Có vẻ không: một thuật toán gọi là serializable snapshot isolation (SSI) cung cấp serializability đầy đủ với chỉ một mức phạt hiệu năng nhỏ so với snapshot isolation. SSI tương đối mới: nó được mô tả lần đầu vào năm 2008 53 65.
Ngày nay SSI và các thuật toán tương tự được dùng trong các cơ sở dữ liệu đơn nút (mức cô lập serializable trong PostgreSQL 54, SQL Server’s In-Memory OLTP/Hekaton 66, và HyPer 67), các cơ sở dữ liệu phân tán (CockroachDB 5 và FoundationDB 8), và các storage engine nhúng như BadgerDB.
Kiểm soát đồng thời bi quan và lạc quan
Two-phase locking là cơ chế kiểm soát đồng thời bi quan (pessimistic): nó dựa trên nguyên tắc rằng nếu có bất cứ điều gì có thể xảy ra sai (như được chỉ ra bởi khóa được giữ bởi một giao dịch khác), tốt hơn là chờ cho đến khi tình huống an toàn trở lại trước khi làm bất cứ điều gì. Nó giống như mutual exclusion (loại trừ tương hỗ), được dùng để bảo vệ các cấu trúc dữ liệu trong lập trình đa luồng.
Thực thi tuần tự, theo một nghĩa nào đó, là bi quan đến mức cực đoan: về cơ bản nó tương đương với việc mỗi giao dịch có khóa độc quyền trên toàn bộ cơ sở dữ liệu (hoặc một shard của cơ sở dữ liệu) trong suốt thời gian giao dịch. Chúng ta bù đắp cho sự bi quan bằng cách làm cho mỗi giao dịch thực thi rất nhanh, để nó chỉ cần giữ “khóa” trong một thời gian ngắn.
Ngược lại, serializable snapshot isolation là kỹ thuật kiểm soát đồng thời lạc quan (optimistic). Lạc quan trong ngữ cảnh này có nghĩa là thay vì chặn khi có điều gì đó có khả năng nguy hiểm xảy ra, các giao dịch vẫn tiếp tục, với hy vọng rằng mọi thứ sẽ ổn. Khi một giao dịch muốn commit, cơ sở dữ liệu kiểm tra xem có điều gì xấu đã xảy ra không (nghĩa là liệu sự cô lập có bị vi phạm không); nếu có, giao dịch bị hủy bỏ và phải được thử lại. Chỉ các giao dịch đã thực thi một cách serializable mới được phép commit.
Kiểm soát đồng thời lạc quan là một ý tưởng cũ 68, và các ưu điểm và nhược điểm của nó đã được tranh luận trong một thời gian dài 69. Nó hoạt động kém nếu có tranh chấp cao (nhiều giao dịch cố gắng truy cập cùng một đối tượng), vì điều này dẫn đến tỷ lệ cao các giao dịch cần hủy bỏ. Nếu hệ thống đã gần đến thông lượng tối đa của nó, tải giao dịch bổ sung từ các giao dịch được thử lại có thể làm cho hiệu năng tệ hơn.
Tuy nhiên, nếu có đủ công suất dự phòng, và nếu tranh chấp giữa các giao dịch không quá cao, các kỹ thuật kiểm soát đồng thời lạc quan có xu hướng hoạt động tốt hơn các kỹ thuật bi quan. Tranh chấp có thể được giảm bằng các thao tác atomic giao hoán (commutative): ví dụ, nếu nhiều giao dịch đồng thời muốn tăng một bộ đếm, thứ tự áp dụng các lần tăng không quan trọng (miễn là bộ đếm không được đọc trong cùng giao dịch), vì vậy các lần tăng đồng thời có thể được áp dụng mà không xung đột.
Như tên gợi ý, SSI dựa trên snapshot isolation, nghĩa là tất cả các lần đọc trong một giao dịch được thực hiện từ một snapshot nhất quán của cơ sở dữ liệu (xem “Snapshot Isolation and Repeatable Read”). Trên nền snapshot isolation, SSI thêm một thuật toán để phát hiện các xung đột serialization (tuần tự hóa) giữa các lần đọc và ghi, và xác định giao dịch nào cần hủy bỏ.
Quyết định dựa trên tiền đề lỗi thời
Khi chúng ta thảo luận về write skew (độ lệch ghi) trong snapshot isolation (xem “Write Skew and Phantoms”), chúng ta quan sát thấy một mẫu lặp đi lặp lại: một giao dịch đọc một số dữ liệu từ cơ sở dữ liệu, kiểm tra kết quả của truy vấn, và quyết định thực hiện một hành động (ghi vào cơ sở dữ liệu) dựa trên kết quả mà nó đã thấy. Tuy nhiên, trong snapshot isolation, kết quả từ truy vấn gốc có thể không còn cập nhật vào thời điểm giao dịch commit, vì dữ liệu có thể đã bị sửa đổi trong thời gian đó.
Nói cách khác, giao dịch đang thực hiện một hành động dựa trên một premise (tiền đề, tức là sự kiện đúng vào đầu giao dịch, ví dụ: “Hiện tại có hai bác sĩ đang trực”). Về sau, khi giao dịch muốn commit, dữ liệu gốc có thể đã thay đổi, tiền đề có thể không còn đúng nữa.
Khi ứng dụng thực hiện một truy vấn (ví dụ: “Hiện có bao nhiêu bác sĩ đang trực?”), cơ sở dữ liệu không biết logic ứng dụng sử dụng kết quả truy vấn đó như thế nào. Để an toàn, cơ sở dữ liệu cần giả định rằng bất kỳ thay đổi nào trong kết quả truy vấn (tiền đề) đều có nghĩa là các lần ghi trong giao dịch đó có thể không hợp lệ. Nói cách khác, có thể có một causal dependency (phụ thuộc nhân quả) giữa các truy vấn và các lần ghi trong giao dịch. Để cung cấp serializable isolation (cô lập khả tuần tự), cơ sở dữ liệu phải phát hiện các tình huống mà giao dịch có thể đã hành động dựa trên tiền đề lỗi thời và hủy bỏ giao dịch trong trường hợp đó.
Làm thế nào để cơ sở dữ liệu biết nếu kết quả truy vấn có thể đã thay đổi? Có hai trường hợp cần xem xét:
- Phát hiện lần đọc phiên bản đối tượng MVCC cũ (lần ghi chưa commit xảy ra trước khi đọc)
- Phát hiện các lần ghi ảnh hưởng đến các lần đọc trước đó (lần ghi xảy ra sau khi đọc)
Phát hiện lần đọc MVCC cũ
Hãy nhớ lại rằng snapshot isolation thường được triển khai bằng multi-version concurrency control (MVCC, kiểm soát đồng thời đa phiên bản; xem “Multi-version concurrency control (MVCC)”). Khi một giao dịch đọc từ một snapshot nhất quán trong cơ sở dữ liệu MVCC, nó bỏ qua các lần ghi được thực hiện bởi bất kỳ giao dịch nào khác chưa commit vào thời điểm snapshot được tạo.
Trong Hình 8-10, giao dịch 43 thấy
Aaliyah có on_call = true, vì giao dịch 42 (đã sửa đổi trạng thái trực của Aaliyah) chưa
commit. Tuy nhiên, vào thời điểm giao dịch 43 muốn commit, giao dịch 42 đã
commit rồi. Điều này có nghĩa là lần ghi đã bị bỏ qua khi đọc từ snapshot nhất quán nay
đã có hiệu lực, và tiền đề của giao dịch 43 không còn đúng nữa. Mọi thứ trở nên phức tạp hơn
khi một writer chèn dữ liệu chưa từng tồn tại trước đó (xem “Phantoms causing write skew”). Chúng ta sẽ
thảo luận về việc phát hiện phantom writes cho SSI trong “Detecting writes that affect prior reads”.
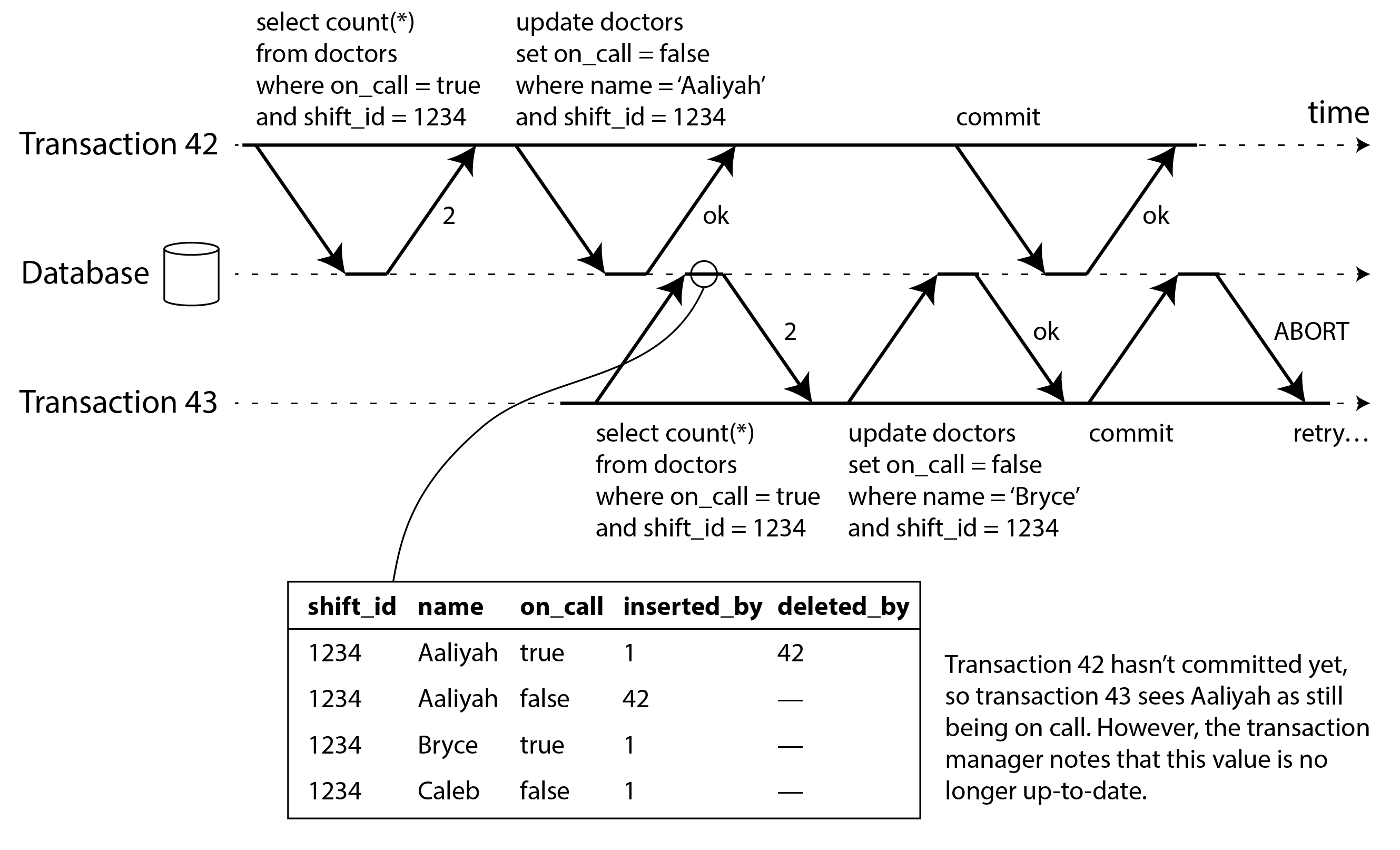
Để ngăn chặn hiện tượng bất thường này, cơ sở dữ liệu cần theo dõi khi nào giao dịch bỏ qua các lần ghi của giao dịch khác do quy tắc hiển thị MVCC. Khi giao dịch muốn commit, cơ sở dữ liệu kiểm tra xem có lần ghi nào bị bỏ qua đã được commit chưa. Nếu có, giao dịch phải bị hủy bỏ.
Tại sao phải đợi đến khi commit? Tại sao không hủy bỏ giao dịch 43 ngay khi phát hiện lần đọc cũ? Vì nếu giao dịch 43 là giao dịch chỉ đọc, nó sẽ không cần bị hủy bỏ, vì không có nguy cơ write skew. Vào thời điểm giao dịch 43 thực hiện lần đọc, cơ sở dữ liệu chưa biết liệu giao dịch đó có thực hiện ghi sau này không. Hơn nữa, giao dịch 42 có thể vẫn bị hủy bỏ hoặc vẫn chưa commit vào thời điểm giao dịch 43 commit, do đó lần đọc có thể cuối cùng hóa ra không cũ. Bằng cách tránh các lần hủy bỏ không cần thiết, SSI bảo toàn hỗ trợ của snapshot isolation cho các lần đọc chạy dài từ một snapshot nhất quán.
Phát hiện các lần ghi ảnh hưởng đến các lần đọc trước đó
Trường hợp thứ hai cần xem xét là khi một giao dịch khác sửa đổi dữ liệu sau khi nó đã được đọc. Trường hợp này được minh họa trong Hình 8-11.
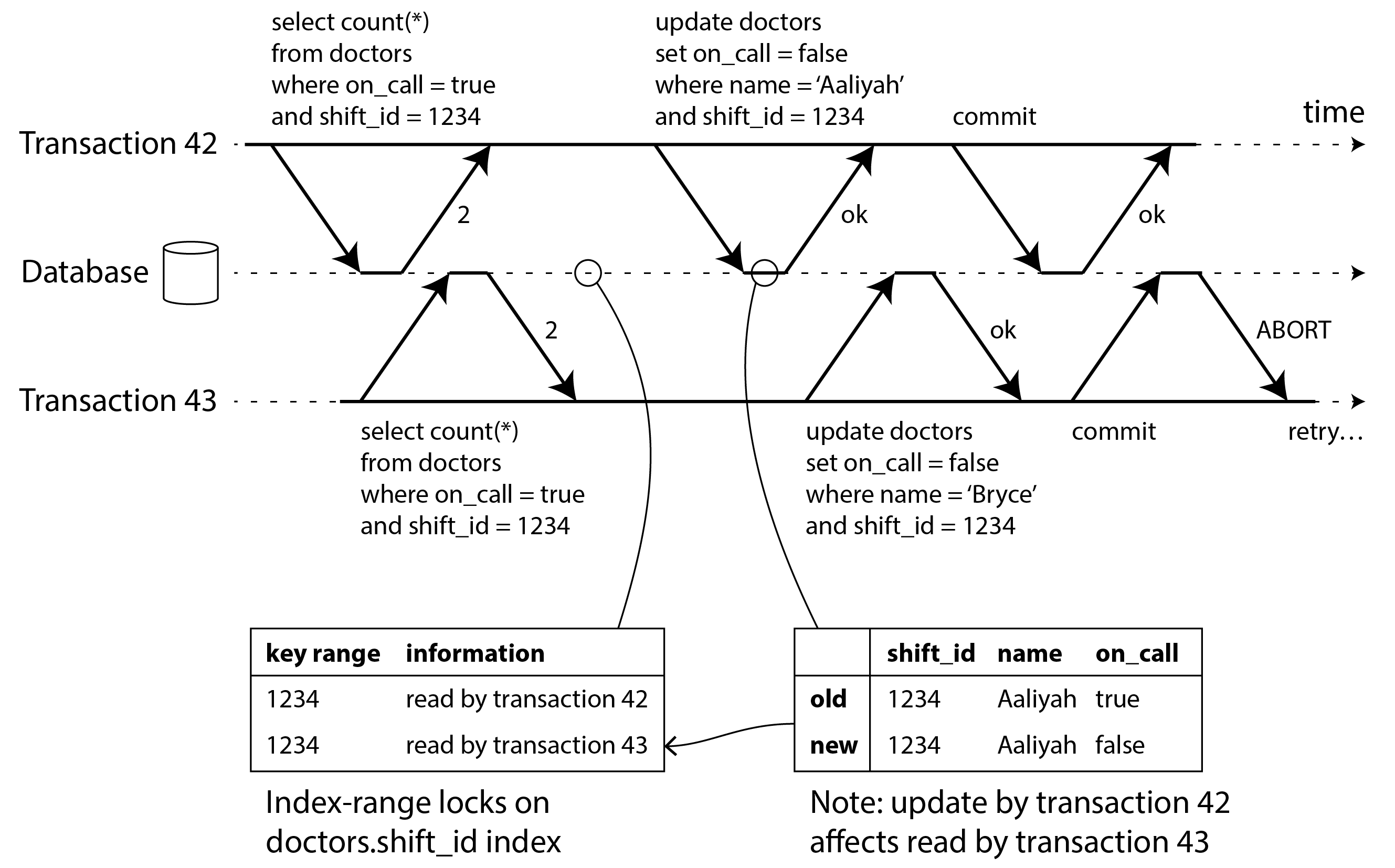
Trong bối cảnh two-phase locking (khóa hai giai đoạn), chúng ta đã thảo luận về index-range locks (khóa phạm vi chỉ mục) (xem
“Index-range locks”), cho phép cơ sở dữ liệu khóa quyền truy cập vào tất cả các hàng khớp với một số
truy vấn tìm kiếm, chẳng hạn như WHERE shift_id = 1234. Chúng ta có thể sử dụng một kỹ thuật tương tự ở đây, ngoại trừ rằng SSI
locks không chặn các giao dịch khác.
Trong Hình 8-11, giao dịch 42 và 43 đều tìm kiếm bác sĩ trực
trong ca 1234. Nếu có index trên shift_id, cơ sở dữ liệu có thể sử dụng mục index 1234 để
ghi lại thực tế là giao dịch 42 và 43 đã đọc dữ liệu này. (Nếu không có index, thông tin này
có thể được theo dõi ở cấp bảng.) Thông tin này chỉ cần được lưu giữ trong một thời gian: sau khi một
giao dịch đã hoàn thành (commit hoặc hủy bỏ), và tất cả các giao dịch đồng thời đã hoàn thành, cơ sở dữ liệu
có thể quên dữ liệu mà nó đã đọc.
Khi một giao dịch ghi vào cơ sở dữ liệu, nó phải tìm trong các index xem có giao dịch nào khác đã đọc gần đây dữ liệu bị ảnh hưởng không. Quá trình này tương tự như việc lấy write lock trên key range bị ảnh hưởng, nhưng thay vì chặn cho đến khi các reader commit, lock này hoạt động như một bẫy cảnh báo: nó chỉ đơn giản là thông báo cho các giao dịch rằng dữ liệu chúng đã đọc có thể không còn cập nhật.
Trong Hình 8-11, giao dịch 43 thông báo cho giao dịch 42 rằng lần đọc trước đó của nó đã lỗi thời, và ngược lại. Giao dịch 42 là giao dịch đầu tiên commit, và nó thành công: mặc dù lần ghi của giao dịch 43 ảnh hưởng đến 42, nhưng 43 chưa commit, nên lần ghi đó chưa có hiệu lực. Tuy nhiên, khi giao dịch 43 muốn commit, lần ghi xung đột từ 42 đã được commit, nên 43 phải bị hủy bỏ.
Hiệu suất của serializable snapshot isolation
Như thường lệ, nhiều chi tiết kỹ thuật ảnh hưởng đến mức độ hoạt động tốt của một thuật toán trong thực tế. Ví dụ, một đánh đổi là độ chi tiết mà tại đó các lần đọc và ghi của giao dịch được theo dõi. Nếu cơ sở dữ liệu theo dõi chi tiết hoạt động của từng giao dịch, nó có thể chính xác về việc giao dịch nào cần hủy bỏ, nhưng chi phí bookkeeping (lưu sổ sách) có thể trở nên đáng kể. Theo dõi ít chi tiết hơn sẽ nhanh hơn, nhưng có thể dẫn đến nhiều giao dịch bị hủy bỏ hơn mức cần thiết.
Trong một số trường hợp, không sao nếu một giao dịch đọc thông tin đã bị giao dịch khác ghi đè: tùy thuộc vào những gì đã xảy ra khác, đôi khi có thể chứng minh rằng kết quả của việc thực thi vẫn là serializable. PostgreSQL sử dụng lý thuyết này để giảm số lượng lần hủy bỏ không cần thiết 14 54.
So với two-phase locking, lợi thế lớn của serializable snapshot isolation là một giao dịch không cần chặn chờ các lock được giữ bởi giao dịch khác. Giống như trong snapshot isolation, writer không chặn reader, và ngược lại. Nguyên tắc thiết kế này làm cho độ trễ truy vấn dễ dự đoán hơn nhiều và ít biến động hơn. Đặc biệt, các truy vấn chỉ đọc có thể chạy trên một snapshot nhất quán mà không cần lock nào, điều này rất hấp dẫn đối với các workload (khối lượng công việc) đọc nhiều.
So với serial execution (thực thi tuần tự), serializable snapshot isolation không bị giới hạn bởi thông lượng của một CPU core duy nhất: ví dụ, FoundationDB phân phối việc phát hiện xung đột serialization trên nhiều máy, cho phép nó mở rộng đến thông lượng rất cao. Mặc dù dữ liệu có thể được phân mảnh trên nhiều máy, các giao dịch có thể đọc và ghi dữ liệu trên nhiều shard trong khi vẫn đảm bảo serializable isolation.
So với non-serializable snapshot isolation, nhu cầu kiểm tra các vi phạm serializability giới thiệu một số overhead hiệu suất. Mức độ đáng kể của các overhead này là vấn đề còn tranh luận: một số người cho rằng kiểm tra serializability không đáng 70, trong khi những người khác tin rằng hiệu suất của serializability hiện nay tốt đến mức không cần sử dụng snapshot isolation yếu hơn nữa 67.
Tỷ lệ hủy bỏ ảnh hưởng đáng kể đến hiệu suất tổng thể của SSI. Ví dụ, một giao dịch đọc và ghi dữ liệu trong một khoảng thời gian dài có khả năng gặp xung đột và bị hủy bỏ, do đó SSI yêu cầu các giao dịch đọc-ghi phải khá ngắn (các giao dịch chỉ đọc chạy dài là ổn). Tuy nhiên, SSI ít nhạy cảm hơn với các giao dịch chậm so với two-phase locking hoặc serial execution.
Distributed Transactions (Giao dịch phân tán)
Một vài phần vừa qua tập trung vào kiểm soát đồng thời cho isolation (cô lập), chữ I trong ACID. Các thuật toán chúng ta đã xem áp dụng cho cả cơ sở dữ liệu đơn node và phân tán: mặc dù có thách thức trong việc làm cho các thuật toán kiểm soát đồng thời có thể mở rộng (ví dụ: thực hiện distributed serializability checking cho SSI), các ý tưởng cấp cao cho kiểm soát đồng thời phân tán tương tự như kiểm soát đồng thời đơn node 8.
Tính nhất quán (consistency) và độ bền (durability) cũng không thay đổi nhiều khi chúng ta chuyển sang distributed transactions. Tuy nhiên, atomicity (tính nguyên tử) đòi hỏi sự cẩn thận hơn.
Đối với các giao dịch thực thi tại một database node duy nhất, atomicity thường được triển khai bởi storage engine. Khi client yêu cầu database node commit giao dịch, cơ sở dữ liệu làm cho các lần ghi của giao dịch trở nên bền vững (thường trong write-ahead log; xem “Making B-trees reliable”) và sau đó thêm một commit record vào log trên đĩa. Nếu cơ sở dữ liệu gặp sự cố ở giữa quá trình này, giao dịch được phục hồi từ log khi node khởi động lại: nếu commit record đã được ghi thành công vào đĩa trước khi gặp sự cố, giao dịch được coi là đã commit; nếu không, bất kỳ lần ghi nào từ giao dịch đó đều bị rollback.
Do đó, trên một node duy nhất, việc commit giao dịch phụ thuộc then chốt vào thứ tự mà dữ liệu được ghi bền vững vào đĩa: đầu tiên là dữ liệu, sau đó là commit record 22. Thời điểm quyết định quan trọng về việc giao dịch commit hay hủy bỏ là thời điểm đĩa hoàn thành ghi commit record: trước thời điểm đó, vẫn có thể hủy bỏ (do gặp sự cố), nhưng sau thời điểm đó, giao dịch đã được commit (ngay cả khi cơ sở dữ liệu gặp sự cố). Do đó, chính một thiết bị duy nhất (bộ điều khiển của một ổ đĩa cụ thể, gắn với một node cụ thể) làm cho việc commit trở nên atomic.
Tuy nhiên, điều gì xảy ra nếu nhiều node tham gia vào một giao dịch? Ví dụ, có thể bạn có một multi-object transaction trong cơ sở dữ liệu phân mảnh, hoặc một global secondary index (chỉ mục phụ toàn cục) (trong đó mục index có thể nằm trên một node khác với dữ liệu chính; xem “Sharding and Secondary Indexes”). Hầu hết các datastore phân tán “NoSQL” không hỗ trợ distributed transactions như vậy, nhưng nhiều cơ sở dữ liệu quan hệ phân tán thì có.
Trong những trường hợp này, chỉ đơn giản gửi commit request đến tất cả các node và commit giao dịch độc lập trên mỗi node là không đủ. Có thể dễ dàng xảy ra rằng commit thành công trên một số node và thất bại trên các node khác, như được hiển thị trong Hình 8-12:
- Một số node có thể phát hiện vi phạm ràng buộc hoặc xung đột, khiến việc hủy bỏ là cần thiết, trong khi các node khác có thể commit thành công.
- Một số commit request có thể bị mất trong mạng, cuối cùng bị hủy bỏ do timeout, trong khi các commit request khác được thông qua.
- Một số node có thể gặp sự cố trước khi commit record được ghi đầy đủ và rollback khi phục hồi, trong khi các node khác commit thành công.
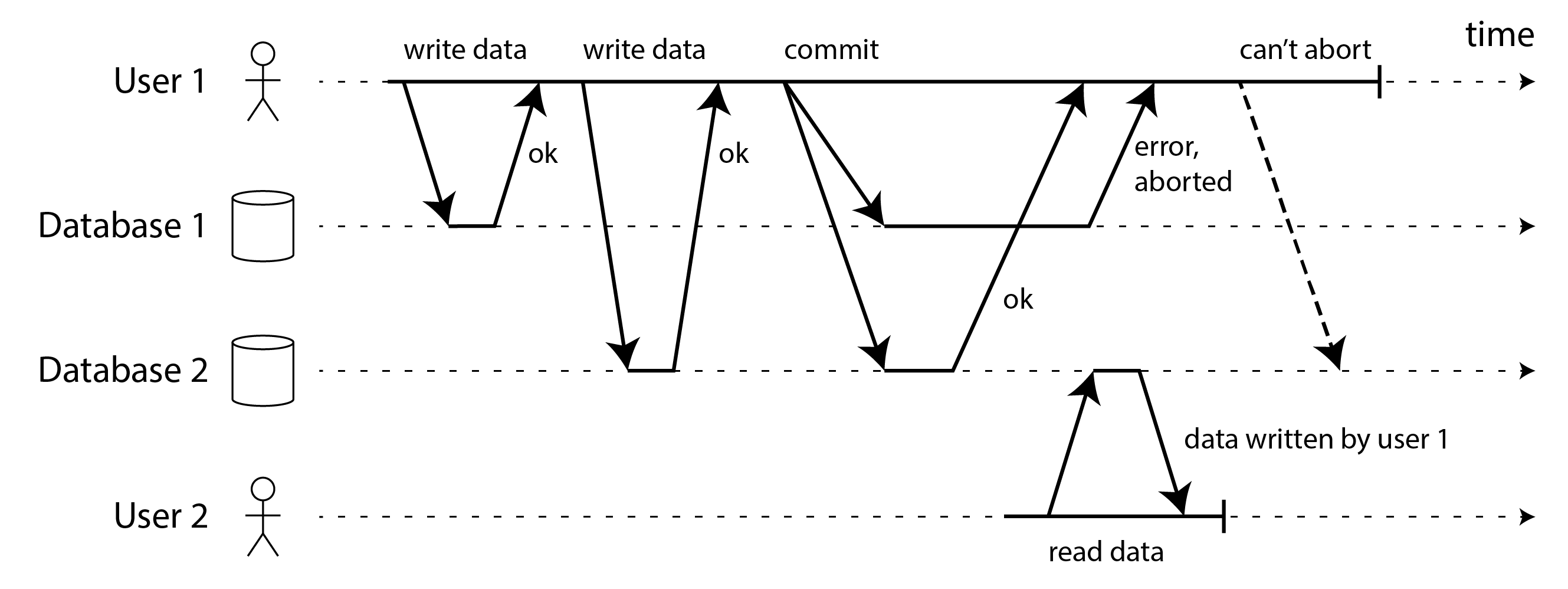
Nếu một số node commit giao dịch nhưng các node khác hủy bỏ nó, các node trở nên không nhất quán với nhau. Và một khi giao dịch đã được commit trên một node, nó không thể bị thu hồi lại nếu sau đó hóa ra nó đã bị hủy bỏ trên một node khác. Điều này là vì một khi dữ liệu đã được commit, nó trở nên hiển thị với các giao dịch khác trong read committed hoặc isolation mạnh hơn. Ví dụ, trong Hình 8-12, vào thời điểm user 1 nhận thấy commit của nó thất bại trên database 1, user 2 đã đọc dữ liệu từ cùng giao dịch trên database 2. Nếu giao dịch của user 1 sau đó bị hủy bỏ, giao dịch của user 2 cũng phải bị hoàn nguyên, vì nó dựa trên dữ liệu được tuyên bố là chưa bao giờ tồn tại.
Một cách tiếp cận tốt hơn là đảm bảo rằng các node tham gia vào một giao dịch đều commit hoặc đều hủy bỏ, và ngăn chặn sự pha trộn của cả hai. Đảm bảo điều này được gọi là vấn đề atomic commitment (cam kết nguyên tử).
Two-Phase Commit (2PC, Cam kết hai giai đoạn)
Two-phase commit là một thuật toán để đạt được commit giao dịch nguyên tử trên nhiều node. Đây là một thuật toán cổ điển trong cơ sở dữ liệu phân tán 13 71 72. 2PC được sử dụng nội bộ trong một số cơ sở dữ liệu và cũng được cung cấp cho ứng dụng dưới dạng XA transactions 73 (được hỗ trợ bởi Java Transaction API, ví dụ) hoặc thông qua WS-AtomicTransaction cho SOAP web services 74 75.
Luồng cơ bản của 2PC được minh họa trong Hình 8-13. Thay vì một commit request duy nhất, như với giao dịch đơn node, quá trình commit/hủy bỏ trong 2PC được chia thành hai giai đoạn (do đó có tên gọi này).
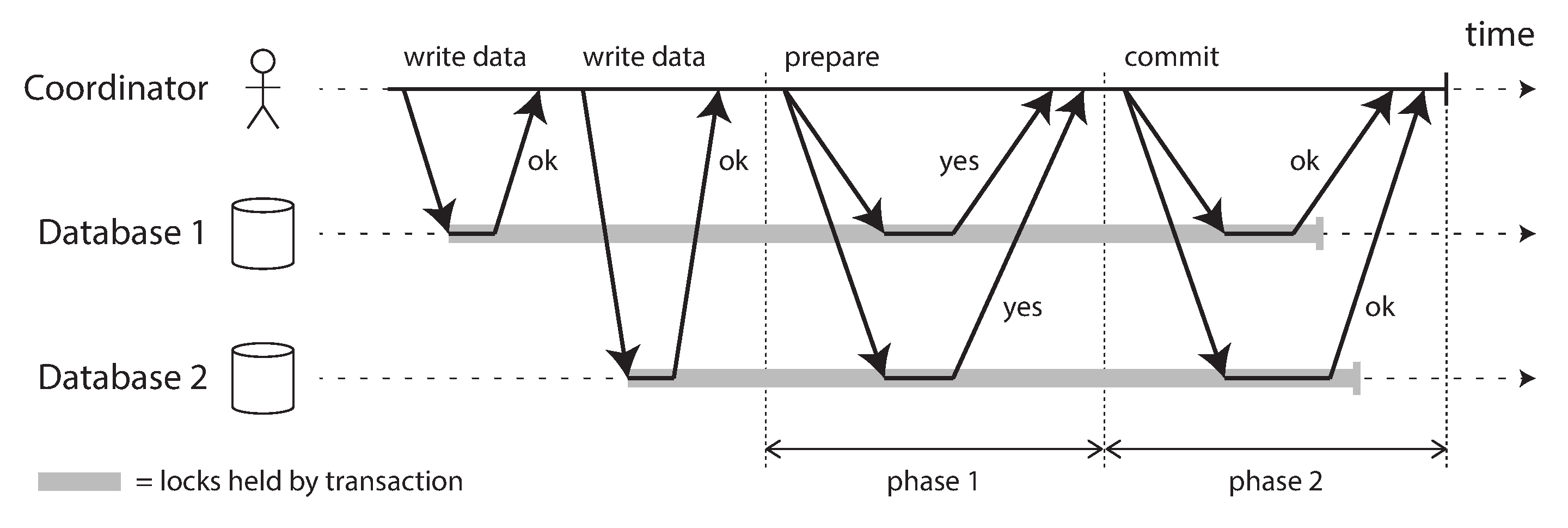
Figure 8-13. A successful execution of two-phase commit (2PC).
2PC sử dụng một thành phần mới thường không xuất hiện trong các giao dịch đơn node: một coordinator (điều phối viên, còn được gọi là transaction manager). Coordinator thường được triển khai như là một thư viện trong cùng tiến trình ứng dụng đang yêu cầu giao dịch (ví dụ: được nhúng trong một Java EE container), nhưng nó cũng có thể là một tiến trình hoặc dịch vụ riêng biệt. Các ví dụ về coordinator như vậy bao gồm Narayana, JOTM, BTM, hoặc MSDTC.
Khi 2PC được sử dụng, một distributed transaction bắt đầu với ứng dụng đọc và ghi dữ liệu trên nhiều database node, như bình thường. Chúng ta gọi các database node này là participants (người tham gia) trong giao dịch. Khi ứng dụng sẵn sàng commit, coordinator bắt đầu giai đoạn 1: nó gửi một prepare request đến mỗi node, hỏi liệu chúng có thể commit không. Coordinator sau đó theo dõi các phản hồi từ các participant:
- Nếu tất cả participant đều trả lời “yes,” cho biết họ sẵn sàng commit, thì coordinator gửi commit request ở giai đoạn 2, và việc commit thực sự diễn ra.
- Nếu bất kỳ participant nào trả lời “no,” coordinator gửi abort request đến tất cả các node ở giai đoạn 2.
Quá trình này có phần giống với buổi lễ kết hôn truyền thống trong các nền văn hóa phương Tây: linh mục hỏi riêng cô dâu và chú rể liệu mỗi người có muốn kết hôn với người kia không, và thông thường nhận được câu trả lời “Tôi đồng ý” từ cả hai. Sau khi nhận được cả hai xác nhận, linh mục tuyên bố cặp đôi là vợ chồng: giao dịch được commit, và sự kiện vui mừng được thông báo cho tất cả người tham dự. Nếu cô dâu hoặc chú rể không nói “yes,” buổi lễ bị hủy bỏ 76.
Hệ thống các lời hứa
Từ mô tả ngắn gọn này, có thể chưa rõ tại sao two-phase commit đảm bảo atomicity, trong khi one-phase commit trên nhiều node thì không. Chắc chắn các prepare và commit request có thể bị mất dễ dàng như nhau trong trường hợp hai giai đoạn. Điều gì làm cho 2PC khác biệt?
Để hiểu tại sao nó hoạt động, chúng ta phải phân tích quá trình chi tiết hơn một chút:
- Khi ứng dụng muốn bắt đầu một distributed transaction, nó yêu cầu một transaction ID từ coordinator. Transaction ID này là duy nhất trên toàn cục.
- Ứng dụng bắt đầu một giao dịch đơn node trên mỗi participant, và gắn globally unique transaction ID vào giao dịch đơn node đó. Tất cả các lần đọc và ghi được thực hiện trong một trong các giao dịch đơn node này. Nếu có gì đó xảy ra ở giai đoạn này (ví dụ: một node gặp sự cố hoặc một request timeout), coordinator hoặc bất kỳ participant nào đều có thể hủy bỏ.
- Khi ứng dụng sẵn sàng commit, coordinator gửi prepare request đến tất cả participant, được gắn thẻ với global transaction ID. Nếu bất kỳ request nào trong số này thất bại hoặc timeout, coordinator gửi abort request cho transaction ID đó đến tất cả participant.
- Khi một participant nhận được prepare request, nó đảm bảo rằng nó có thể commit giao dịch trong mọi trường hợp.
Điều này bao gồm việc ghi tất cả dữ liệu giao dịch vào đĩa (gặp sự cố, mất điện, hoặc hết dung lượng đĩa không phải là lý do chấp nhận được để từ chối commit sau này), và kiểm tra bất kỳ xung đột hoặc vi phạm ràng buộc nào. Bằng cách trả lời “yes” cho coordinator, node hứa sẽ commit giao dịch mà không có lỗi nếu được yêu cầu. Nói cách khác, participant từ bỏ quyền hủy bỏ giao dịch, nhưng không thực sự commit nó. 5. Khi coordinator đã nhận được phản hồi cho tất cả prepare request, nó đưa ra quyết định dứt khoát về việc commit hay hủy bỏ giao dịch (chỉ commit nếu tất cả participant đều bỏ phiếu “yes”). Coordinator phải ghi quyết định đó vào transaction log của nó trên đĩa để biết nó đã quyết định như thế nào trong trường hợp nó gặp sự cố sau đó. Đây được gọi là commit point (điểm cam kết). 6. Khi quyết định của coordinator đã được ghi vào đĩa, commit hoặc abort request được gửi đến tất cả participant. Nếu request này thất bại hoặc timeout, coordinator phải thử lại mãi cho đến khi thành công. Không còn có thể quay lại: nếu quyết định là commit, quyết định đó phải được thực thi, dù cần bao nhiêu lần thử lại. Nếu một participant đã gặp sự cố trong thời gian đó, giao dịch sẽ được commit khi nó phục hồi, vì participant đã bỏ phiếu “yes,” nó không thể từ chối commit khi phục hồi.
Do đó, giao thức chứa hai “điểm không thể quay lại” quan trọng: khi một participant bỏ phiếu “yes,” nó hứa rằng nó sẽ chắc chắn có thể commit sau này (mặc dù coordinator vẫn có thể chọn hủy bỏ); và một khi coordinator đã quyết định, quyết định đó là không thể đảo ngược. Những lời hứa đó đảm bảo atomicity của 2PC. (Single-node atomic commit gộp hai sự kiện này thành một: ghi commit record vào transaction log.)
Quay lại phép ẩn dụ về hôn nhân, trước khi nói “Tôi đồng ý,” bạn và cô dâu/chú rể của mình có tự do hủy bỏ giao dịch bằng cách nói “Không đời nào!” (hoặc điều gì đó tương tự). Tuy nhiên, sau khi nói “Tôi đồng ý,” bạn không thể rút lại tuyên bố đó. Nếu bạn ngất sau khi nói “Tôi đồng ý” và bạn không nghe linh mục nói những lời “Từ nay hai người là vợ chồng,” điều đó không thay đổi thực tế là giao dịch đã được commit. Khi bạn tỉnh lại sau, bạn có thể tìm hiểu xem mình có đã kết hôn hay không bằng cách hỏi linh mục về trạng thái global transaction ID của bạn, hoặc bạn có thể chờ lần thử lại tiếp theo của linh mục đối với commit request (vì các lần thử lại sẽ tiếp tục trong suốt thời gian bạn bất tỉnh).
Coordinator gặp sự cố
Chúng ta đã thảo luận về những gì xảy ra nếu một trong các participant hoặc mạng gặp sự cố trong 2PC: nếu bất kỳ prepare request nào thất bại hoặc timeout, coordinator hủy bỏ giao dịch; nếu bất kỳ commit hoặc abort request nào thất bại, coordinator thử lại chúng vô thời hạn. Tuy nhiên, ít rõ ràng hơn là những gì xảy ra nếu coordinator gặp sự cố.
Nếu coordinator gặp sự cố trước khi gửi prepare request, một participant có thể an toàn hủy bỏ giao dịch. Nhưng một khi participant đã nhận được prepare request và bỏ phiếu “yes,” nó không còn có thể hủy bỏ đơn phương, nó phải chờ để nghe lại từ coordinator xem giao dịch đã được commit hay hủy bỏ. Nếu coordinator gặp sự cố hoặc mạng gặp sự cố tại thời điểm này, participant không thể làm gì ngoài việc chờ đợi. Giao dịch của participant ở trạng thái này được gọi là in doubt (nghi ngờ) hoặc uncertain (không chắc chắn).
Tình huống này được minh họa trong Hình 8-14. Trong ví dụ cụ thể này, coordinator thực sự đã quyết định commit, và database 2 đã nhận được commit request. Tuy nhiên, coordinator đã gặp sự cố trước khi có thể gửi commit request đến database 1, và do đó database 1 không biết liệu có nên commit hay hủy bỏ. Ngay cả timeout cũng không giúp ích ở đây: nếu database 1 đơn phương hủy bỏ sau khi timeout, nó sẽ kết thúc không nhất quán với database 2 đã commit. Tương tự, không an toàn khi đơn phương commit, vì một participant khác có thể đã hủy bỏ.
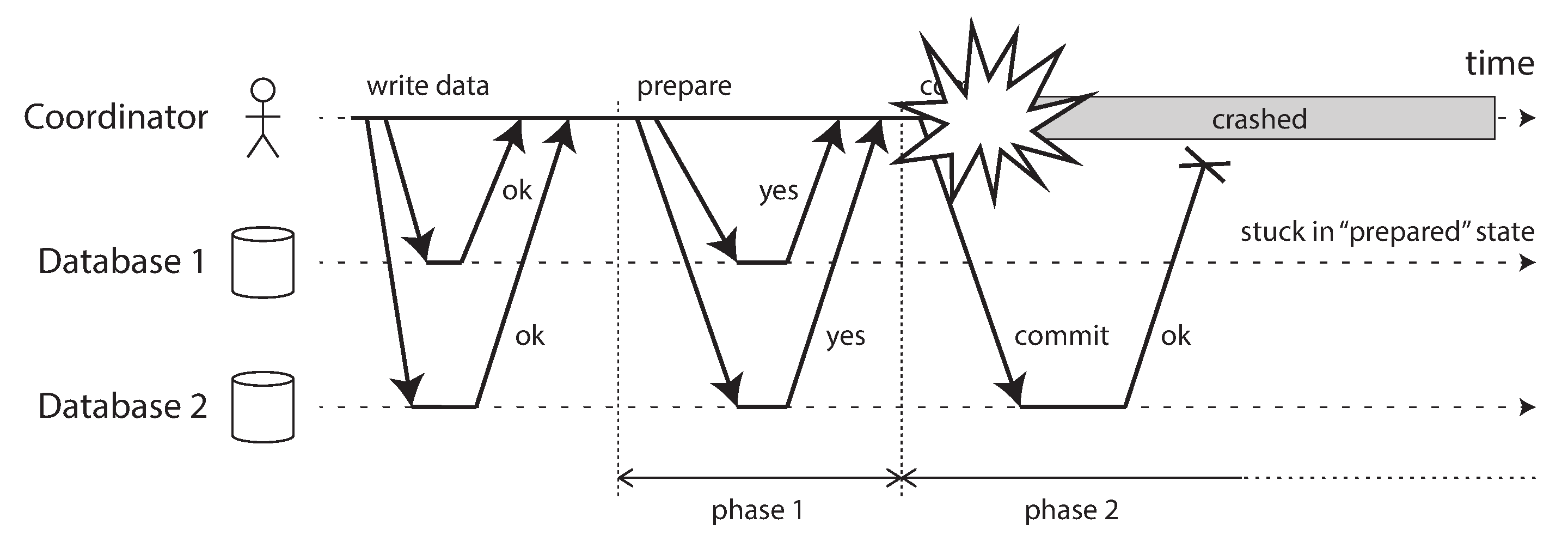
Figure 8-14. The coordinator crashes after participants vote "yes." Database 1 does not know whether to commit or abort.
Nếu không nghe từ coordinator, participant không có cách nào biết nên commit hay hủy bỏ. Về nguyên tắc, các participant có thể giao tiếp với nhau để tìm hiểu cách mỗi participant đã bỏ phiếu và đạt đến một thỏa thuận, nhưng đó không phải là một phần của giao thức 2PC.
Cách duy nhất 2PC có thể hoàn thành là chờ coordinator phục hồi. Đó là lý do tại sao coordinator phải ghi quyết định commit hoặc hủy bỏ của nó vào transaction log trên đĩa trước khi gửi commit hoặc abort request đến participant: khi coordinator phục hồi, nó xác định trạng thái của tất cả các giao dịch đang in doubt bằng cách đọc transaction log của nó. Bất kỳ giao dịch nào không có commit record trong log của coordinator đều bị hủy bỏ. Do đó, commit point của 2PC cuối cùng phụ thuộc vào single-node atomic commit thông thường trên coordinator.
Three-phase commit (Cam kết ba giai đoạn)
Two-phase commit được gọi là giao thức atomic commit blocking (chặn) do thực tế là 2PC có thể bị kẹt chờ coordinator phục hồi. Có thể tạo ra một giao thức atomic commit nonblocking (không chặn), để nó không bị kẹt nếu một node gặp sự cố. Tuy nhiên, làm cho điều này hoạt động trong thực tế không đơn giản như vậy.
Là một giải pháp thay thế cho 2PC, một thuật toán gọi là three-phase commit (3PC, cam kết ba giai đoạn) đã được đề xuất 13 77. Tuy nhiên, 3PC giả định một mạng với độ trễ có giới hạn và các node với thời gian phản hồi có giới hạn; trong hầu hết các hệ thống thực tế với độ trễ mạng không có giới hạn và các khoảng dừng tiến trình (xem Chương 9), nó không thể đảm bảo atomicity.
Một giải pháp tốt hơn trong thực tế là thay thế coordinator đơn node bằng một fault-tolerant consensus protocol (giao thức đồng thuận chịu lỗi). Chúng ta sẽ xem cách làm điều này trong Chương 10.
Distributed Transactions Across Different Systems (Giao dịch phân tán qua các hệ thống khác nhau)
Distributed transactions và two-phase commit có danh tiếng lẫn lộn. Một mặt, chúng được coi là cung cấp đảm bảo an toàn quan trọng mà nếu không thì khó đạt được; mặt khác, chúng bị chỉ trích vì gây ra vấn đề vận hành, làm giảm hiệu suất, và hứa hẹn nhiều hơn những gì chúng có thể thực hiện 78 79 80 81. Nhiều dịch vụ đám mây chọn không triển khai distributed transactions do các vấn đề vận hành mà chúng gây ra 82.
Một số triển khai distributed transactions mang lại chi phí hiệu suất nặng nề. Phần lớn
chi phí hiệu suất vốn có trong two-phase commit là do việc buộc đĩa (fsync) bổ sung
cần thiết cho crash recovery, và các vòng lặp mạng bổ sung.
Tuy nhiên, thay vì bác bỏ distributed transactions hoàn toàn, chúng ta nên xem xét chúng chi tiết hơn, vì có những bài học quan trọng cần học từ chúng. Để bắt đầu, chúng ta nên chính xác về những gì chúng ta muốn nói bằng “distributed transactions.” Hai loại distributed transactions khá khác nhau thường hay bị nhầm lẫn với nhau:
- Database-internal distributed transactions (Giao dịch phân tán nội bộ cơ sở dữ liệu)
- Một số cơ sở dữ liệu phân tán (tức là cơ sở dữ liệu sử dụng replication và sharding trong cấu hình tiêu chuẩn của chúng) hỗ trợ internal transactions giữa các node của cơ sở dữ liệu đó. Ví dụ, YugabyteDB, TiDB, FoundationDB, Spanner, VoltDB, và MySQL Cluster’s NDB storage engine có hỗ trợ internal transaction như vậy. Trong trường hợp này, tất cả các node tham gia giao dịch đều chạy cùng phần mềm cơ sở dữ liệu.
- Heterogeneous distributed transactions (Giao dịch phân tán không đồng nhất)
- Trong một heterogeneous transaction (giao dịch không đồng nhất), các participant là hai hoặc nhiều công nghệ khác nhau: ví dụ như hai cơ sở dữ liệu từ các nhà cung cấp khác nhau, hoặc thậm chí các hệ thống không phải cơ sở dữ liệu như message broker. Một distributed transaction trên các hệ thống này phải đảm bảo atomic commit, mặc dù các hệ thống có thể hoàn toàn khác nhau về cơ bản.
Database-internal transactions không cần phải tương thích với bất kỳ hệ thống nào khác, do đó chúng có thể sử dụng bất kỳ giao thức nào và áp dụng các tối ưu hóa dành riêng cho công nghệ cụ thể đó. Vì lý do đó, database-internal distributed transactions thường có thể hoạt động khá tốt. Mặt khác, các giao dịch trải rộng trên các công nghệ không đồng nhất thì đầy thách thức hơn nhiều.
Exactly-once message processing (Xử lý tin nhắn đúng một lần)
Heterogeneous distributed transactions cho phép các hệ thống đa dạng được tích hợp theo những cách mạnh mẽ. Ví dụ, một tin nhắn từ message queue có thể được xác nhận là đã xử lý nếu và chỉ nếu giao dịch cơ sở dữ liệu để xử lý tin nhắn đó đã được commit thành công. Điều này được thực hiện bằng cách commit nguyên tử xác nhận tin nhắn và các lần ghi cơ sở dữ liệu trong một giao dịch duy nhất. Với hỗ trợ distributed transaction, điều này là có thể, ngay cả khi message broker và cơ sở dữ liệu là hai công nghệ không liên quan chạy trên các máy khác nhau.
Nếu việc gửi tin nhắn hoặc giao dịch cơ sở dữ liệu thất bại, cả hai đều bị hủy bỏ, và do đó message broker có thể an toàn gửi lại tin nhắn sau. Do đó, bằng cách commit nguyên tử tin nhắn và tác dụng phụ của việc xử lý nó, chúng ta có thể đảm bảo rằng tin nhắn được effectively xử lý đúng một lần, ngay cả khi cần một vài lần thử lại trước khi thành công. Việc hủy bỏ loại bỏ bất kỳ tác dụng phụ nào của giao dịch hoàn thành một phần. Điều này được gọi là exactly-once semantics (ngữ nghĩa đúng một lần).
Một distributed transaction như vậy chỉ có thể thực hiện được nếu tất cả các hệ thống bị ảnh hưởng bởi giao dịch đều có thể sử dụng cùng giao thức atomic commit. Ví dụ, giả sử tác dụng phụ của việc xử lý một tin nhắn là gửi email, và email server không hỗ trợ two-phase commit: có thể xảy ra rằng email được gửi hai lần trở lên nếu quá trình xử lý tin nhắn thất bại và được thử lại. Nhưng nếu tất cả tác dụng phụ của việc xử lý một tin nhắn đều bị rollback khi giao dịch hủy bỏ, thì bước xử lý có thể an toàn được thử lại như thể không có gì xảy ra.
Chúng ta sẽ quay lại chủ đề exactly-once semantics sau trong chương này. Hãy xem xét trước giao thức atomic commit cho phép các heterogeneous distributed transactions như vậy.
XA transactions
X/Open XA (viết tắt của eXtended Architecture) là một tiêu chuẩn để triển khai two-phase commit trên các công nghệ không đồng nhất 73. Nó được giới thiệu vào năm 1991 và đã được triển khai rộng rãi: XA được hỗ trợ bởi nhiều cơ sở dữ liệu quan hệ truyền thống (bao gồm PostgreSQL, MySQL, Db2, SQL Server, và Oracle) và message broker (bao gồm ActiveMQ, HornetQ, MSMQ, và IBM MQ).
XA không phải là một giao thức mạng, nó chỉ là một C API để giao tiếp với một transaction coordinator. Các binding cho API này tồn tại trong các ngôn ngữ khác; ví dụ, trong thế giới Java EE applications, XA transactions được triển khai bằng Java Transaction API (JTA), lần lượt được hỗ trợ bởi nhiều driver cho cơ sở dữ liệu sử dụng Java Database Connectivity (JDBC) và driver cho message broker sử dụng Java Message Service (JMS) APIs.
XA giả định rằng ứng dụng của bạn sử dụng network driver hoặc client library để giao tiếp với các participant databases hoặc messaging services. Nếu driver hỗ trợ XA, điều đó có nghĩa là nó gọi XA API để tìm hiểu xem một thao tác có nên là một phần của distributed transaction hay không, và nếu có, nó gửi thông tin cần thiết đến database server. Driver cũng cung cấp các callback thông qua đó coordinator có thể yêu cầu participant chuẩn bị, commit, hoặc hủy bỏ.
Transaction coordinator (bộ điều phối giao dịch) triển khai XA API. Tiêu chuẩn không quy định cách triển khai cụ thể, nhưng trong thực tế, coordinator thường chỉ là một thư viện được nạp vào cùng tiến trình với ứng dụng phát ra giao dịch (không phải một dịch vụ riêng biệt). Nó theo dõi các participant trong một giao dịch, thu thập phản hồi của các participant sau khi yêu cầu họ chuẩn bị (thông qua callback vào driver), và sử dụng log trên đĩa cục bộ để theo dõi quyết định commit/abort cho mỗi giao dịch.
Nếu tiến trình ứng dụng bị crash, hoặc máy chạy ứng dụng bị chết, coordinator cũng biến mất theo. Các participant đang có giao dịch đã prepared nhưng chưa committed sẽ bị kẹt trong trạng thái nghi ngờ (in doubt). Vì log của coordinator nằm trên đĩa cục bộ của application server, server đó phải được khởi động lại, và thư viện coordinator phải đọc log để khôi phục kết quả commit/abort của từng giao dịch. Chỉ sau đó coordinator mới có thể dùng XA callback của database driver để yêu cầu các participant commit hoặc abort, tùy trường hợp. Database server không thể liên hệ trực tiếp với coordinator, vì mọi giao tiếp đều phải đi qua thư viện client.
Giữ khóa trong khi đang nghi ngờ
Tại sao chúng ta lại lo ngại đến vậy về một giao dịch bị kẹt trong trạng thái nghi ngờ? Phần còn lại của hệ thống không thể tiếp tục công việc của mình và bỏ qua giao dịch nghi ngờ đó, rồi dọn dẹp nó sau sao?
Vấn đề nằm ở locking (khóa). Như đã thảo luận trong “Read Committed”, các giao dịch cơ sở dữ liệu thường lấy row-level exclusive lock (khóa độc quyền cấp hàng) trên bất kỳ hàng nào chúng sửa đổi, để ngăn dirty writes. Ngoài ra, nếu bạn muốn serializable isolation, một cơ sở dữ liệu sử dụng two-phase locking cũng phải lấy shared lock trên bất kỳ hàng nào được đọc bởi giao dịch.
Cơ sở dữ liệu không thể giải phóng các khóa đó cho đến khi giao dịch commit hoặc abort (được minh họa là vùng bóng mờ trong Hình 8-13). Do đó, khi sử dụng two-phase commit, một giao dịch phải giữ các khóa trong suốt thời gian nó ở trạng thái nghi ngờ. Nếu coordinator bị crash và mất 20 phút để khởi động lại, các khóa đó sẽ bị giữ trong 20 phút. Nếu log của coordinator bị mất hoàn toàn vì lý do nào đó, các khóa đó sẽ bị giữ mãi mãi, hoặc ít nhất cho đến khi tình huống được giải quyết thủ công bởi một quản trị viên.
Khi các khóa đó đang bị giữ, không có giao dịch nào khác có thể sửa đổi các hàng đó. Tùy thuộc vào mức isolation, các giao dịch khác thậm chí có thể bị chặn không đọc được các hàng đó. Do đó, các giao dịch khác không thể đơn giản tiếp tục công việc của mình: nếu chúng muốn truy cập dữ liệu đó, chúng sẽ bị chặn. Điều này có thể khiến nhiều phần lớn của ứng dụng trở nên không khả dụng cho đến khi giao dịch nghi ngờ được giải quyết.
Khôi phục sau khi coordinator gặp sự cố
Về lý thuyết, nếu coordinator bị crash và được khởi động lại, nó nên khôi phục trạng thái sạch từ log và giải quyết mọi giao dịch đang nghi ngờ. Tuy nhiên, trong thực tế, các giao dịch nghi ngờ mồ côi (orphaned) vẫn xảy ra 83 84, tức là các giao dịch mà coordinator không thể quyết định kết quả vì lý do gì đó (ví dụ vì log giao dịch đã bị mất hoặc bị hỏng do lỗi phần mềm). Các giao dịch này không thể được giải quyết tự động, vì vậy chúng nằm mãi trong cơ sở dữ liệu, giữ các khóa và chặn các giao dịch khác.
Thậm chí khởi động lại các database server cũng không khắc phục được vấn đề này, vì một triển khai đúng của 2PC phải bảo toàn các khóa của giao dịch nghi ngờ ngay cả qua các lần khởi động lại (nếu không sẽ có nguy cơ vi phạm đảm bảo tính nguyên tử). Đây là một tình huống khó xử.
Cách duy nhất thoát ra là để quản trị viên quyết định thủ công có nên commit hay rollback các giao dịch. Quản trị viên phải kiểm tra các participant của từng giao dịch nghi ngờ, xác định xem participant nào đã committed hoặc aborted rồi, và sau đó áp dụng kết quả tương tự cho các participant còn lại. Giải quyết vấn đề có thể đòi hỏi rất nhiều công sức thủ công, và rất có khả năng cần thực hiện dưới áp lực cao và gấp rút trong một sự cố sản xuất nghiêm trọng (nếu không tại sao coordinator lại ở trong trạng thái tệ đến vậy?).
Nhiều triển khai XA có một lối thoát khẩn cấp gọi là heuristic decisions (quyết định theo kinh nghiệm): cho phép một participant tự ý quyết định abort hoặc commit một giao dịch nghi ngờ mà không có quyết định dứt khoát từ coordinator 73. Cần nói rõ, heuristic ở đây là một cách nói giảm nhẹ cho có thể phá vỡ tính nguyên tử, vì quyết định heuristic vi phạm hệ thống cam kết trong two-phase commit. Vì vậy, heuristic decisions chỉ dành để thoát ra khỏi các tình huống thảm khốc, không phải để dùng thường xuyên.
Các vấn đề với giao dịch XA
Một coordinator đơn nút là điểm lỗi duy nhất (single point of failure) cho toàn bộ hệ thống, và việc đặt nó như một phần của application server cũng có vấn đề vì log của coordinator trên đĩa cục bộ trở thành một phần quan trọng của trạng thái hệ thống lâu dài, quan trọng ngang với bản thân các cơ sở dữ liệu.
Về nguyên tắc, coordinator của một giao dịch XA có thể được làm có tính sẵn sàng cao và được nhân bản, giống như chúng ta mong đợi với bất kỳ cơ sở dữ liệu quan trọng nào. Thật không may, điều này vẫn không giải quyết được một vấn đề cơ bản với XA, đó là nó không cung cấp cách nào để coordinator và các participant của một giao dịch giao tiếp trực tiếp với nhau. Chúng chỉ có thể giao tiếp thông qua code ứng dụng đã khởi tạo giao dịch, và các database driver mà code đó dùng để gọi các participant.
Ngay cả khi coordinator được nhân bản, code ứng dụng vẫn sẽ là điểm lỗi duy nhất. Để giải quyết vấn đề này sẽ cần thiết kế lại hoàn toàn cách code ứng dụng chạy để làm cho nó có thể nhân bản hoặc khởi động lại được, điều mà có thể trông tương tự như durable execution (xem “Durable Execution and Workflows”). Tuy nhiên, dường như không có công cụ nào thực sự áp dụng cách tiếp cận này trong thực tế.
Một vấn đề khác là vì XA cần tương thích với nhiều loại hệ thống dữ liệu khác nhau, nó nhất thiết là mẫu số chung thấp nhất (lowest common denominator). Ví dụ, nó không thể phát hiện deadlock qua các hệ thống khác nhau (vì điều đó sẽ đòi hỏi một giao thức chuẩn hóa để các hệ thống trao đổi thông tin về các khóa mà mỗi giao dịch đang chờ), và nó không hoạt động với SSI (xem “Serializable Snapshot Isolation (SSI)”), vì điều đó sẽ đòi hỏi một giao thức để xác định các xung đột qua các hệ thống khác nhau.
Những vấn đề này phần nào là vốn có khi thực hiện giao dịch qua các công nghệ không đồng nhất. Tuy nhiên, việc giữ nhiều hệ thống dữ liệu không đồng nhất nhất quán với nhau vẫn là một bài toán thực sự và quan trọng, vì vậy chúng ta cần tìm một giải pháp khác cho nó. Điều này có thể thực hiện được, như chúng ta sẽ thấy trong phần tiếp theo và trong “Derived data versus distributed transactions”.
Giao dịch phân tán nội bộ cơ sở dữ liệu
Như đã giải thích trước đó, có sự khác biệt lớn giữa các giao dịch phân tán trải rộng qua nhiều công nghệ lưu trữ không đồng nhất, và các giao dịch nội bộ của một hệ thống, tức là nơi tất cả các nút tham gia đều là các shard của cùng một cơ sở dữ liệu chạy cùng phần mềm. Các giao dịch phân tán nội bộ như vậy là đặc trưng định nghĩa của các cơ sở dữ liệu “NewSQL” như CockroachDB 5, TiDB 6, Spanner 7, FoundationDB 8, và YugabyteDB, chẳng hạn. Một số message broker như Kafka cũng hỗ trợ giao dịch phân tán nội bộ [^85].
Nhiều hệ thống trong số này sử dụng 2-phase commit để đảm bảo tính nguyên tử của các giao dịch ghi vào nhiều shard, nhưng vẫn không gặp phải những vấn đề tương tự như giao dịch XA. Lý do là vì các giao dịch phân tán của chúng không cần giao tiếp với bất kỳ công nghệ nào khác, chúng tránh được cạm bẫy mẫu số chung thấp nhất: các nhà thiết kế của các hệ thống này được tự do sử dụng các giao thức tốt hơn, đáng tin cậy hơn và nhanh hơn.
Các vấn đề lớn nhất với XA có thể được khắc phục bằng cách:
- Nhân bản coordinator, với tự động failover sang nút coordinator khác nếu nút chính bị crash;
- Cho phép coordinator và các data shard giao tiếp trực tiếp mà không cần đi qua code ứng dụng;
- Nhân bản các shard tham gia, để giảm nguy cơ phải abort một giao dịch do lỗi ở một trong các shard; và
- Kết hợp giao thức atomic commitment với giao thức kiểm soát đồng thời phân tán hỗ trợ phát hiện deadlock và đọc nhất quán qua các shard.
Các thuật toán đồng thuận (consensus algorithm) thường được sử dụng để nhân bản coordinator và các database shard. Chúng ta sẽ thấy trong Chương 10 cách atomic commitment cho các giao dịch phân tán có thể được triển khai bằng thuật toán đồng thuận. Các thuật toán này chịu lỗi bằng cách tự động chuyển đổi từ nút này sang nút khác mà không cần can thiệp của con người, trong khi vẫn tiếp tục đảm bảo các thuộc tính nhất quán mạnh.
Các mức isolation được cung cấp cho giao dịch phân tán phụ thuộc vào hệ thống, nhưng cả snapshot isolation và serializable snapshot isolation đều khả thi qua các shard. Chi tiết về cách hoạt động của điều này có thể được tìm thấy trong các bài báo được tham chiếu ở cuối chương này.
Xem lại xử lý tin nhắn đúng một lần
Chúng ta đã thấy trong “Exactly-once message processing” rằng một trường hợp sử dụng quan trọng cho giao dịch phân tán là đảm bảo rằng một số thao tác có hiệu lực đúng một lần, ngay cả khi xảy ra crash trong khi xử lý và việc xử lý cần được thử lại. Nếu bạn có thể commit nguyên tử một giao dịch qua cả message broker lẫn database, bạn có thể xác nhận tin nhắn với broker khi và chỉ khi nó được xử lý thành công và các lần ghi vào cơ sở dữ liệu từ quá trình đó đã được committed.
Tuy nhiên, bạn thực ra không cần các giao dịch phân tán như vậy để đạt được ngữ nghĩa exactly-once. Một cách tiếp cận thay thế là như sau, chỉ cần các giao dịch trong cơ sở dữ liệu:
- Giả sử mỗi tin nhắn có một ID duy nhất, và trong cơ sở dữ liệu bạn có một bảng các message ID đã được xử lý. Khi bạn bắt đầu xử lý một tin nhắn từ broker, bạn bắt đầu một giao dịch mới trên cơ sở dữ liệu, và kiểm tra message ID. Nếu cùng một message ID đã có trong cơ sở dữ liệu, bạn biết rằng nó đã được xử lý rồi, vì vậy bạn có thể xác nhận tin nhắn với broker và bỏ nó đi.
- Nếu message ID chưa có trong cơ sở dữ liệu, bạn thêm nó vào bảng. Sau đó bạn xử lý tin nhắn, điều này có thể dẫn đến các lần ghi thêm vào cơ sở dữ liệu trong cùng một giao dịch. Khi bạn hoàn thành xử lý tin nhắn, bạn commit giao dịch trên cơ sở dữ liệu.
- Khi giao dịch cơ sở dữ liệu được committed thành công, bạn có thể xác nhận tin nhắn với broker.
- Khi tin nhắn đã được xác nhận thành công với broker, bạn biết rằng nó sẽ không thử xử lý lại tin nhắn đó nữa, vì vậy bạn có thể xóa message ID khỏi cơ sở dữ liệu (trong một giao dịch riêng biệt).
Nếu message processor bị crash trước khi commit giao dịch cơ sở dữ liệu, giao dịch bị abort và message broker sẽ thử lại xử lý. Nếu nó crash sau khi commit nhưng trước khi xác nhận tin nhắn với broker, nó cũng sẽ thử lại xử lý, nhưng lần thử lại sẽ thấy message ID trong cơ sở dữ liệu và bỏ nó đi. Nếu nó crash sau khi xác nhận tin nhắn nhưng trước khi xóa message ID khỏi cơ sở dữ liệu, bạn sẽ có một message ID cũ còn nằm đó, điều này không gây hại gì ngoài việc chiếm một chút không gian lưu trữ. Nếu một lần thử lại xảy ra trước khi giao dịch cơ sở dữ liệu bị abort (điều này có thể xảy ra nếu giao tiếp giữa message processor và cơ sở dữ liệu bị gián đoạn), một ràng buộc uniqueness trên bảng message ID sẽ ngăn cùng một message ID bị chèn bởi hai giao dịch đồng thời.
Do đó, việc đạt được xử lý exactly-once chỉ cần các giao dịch trong cơ sở dữ liệu: tính nguyên tử qua cơ sở dữ liệu và message broker không cần thiết cho trường hợp sử dụng này. Ghi lại message ID trong cơ sở dữ liệu làm cho việc xử lý tin nhắn trở nên idempotent (lũy đẳng), do đó việc xử lý tin nhắn có thể được thử lại an toàn mà không nhân đôi các tác dụng phụ của nó. Một cách tiếp cận tương tự được sử dụng trong các framework xử lý luồng như Kafka Streams để đạt được ngữ nghĩa exactly-once, như chúng ta sẽ thấy trong “Fault Tolerance”.
Tuy nhiên, các giao dịch phân tán nội bộ trong cơ sở dữ liệu vẫn hữu ích cho khả năng mở rộng của các mẫu như thế này: ví dụ, chúng sẽ cho phép các message ID được lưu trên một shard và dữ liệu chính được cập nhật bởi quá trình xử lý tin nhắn được lưu trên các shard khác, và đảm bảo tính nguyên tử của giao dịch commit qua các shard đó.
Tóm tắt
Giao dịch (transaction) là một lớp trừu tượng cho phép ứng dụng giả vờ rằng một số vấn đề đồng thời và một số loại lỗi phần cứng và phần mềm nhất định không tồn tại. Một lớp lỗi lớn được rút gọn xuống thành một transaction abort đơn giản, và ứng dụng chỉ cần thử lại.
Trong chương này chúng ta đã thấy nhiều ví dụ về các vấn đề mà giao dịch giúp ngăn chặn. Không phải tất cả ứng dụng đều dễ bị tổn thương bởi tất cả những vấn đề đó: một ứng dụng với các mẫu truy cập rất đơn giản, chẳng hạn như chỉ đọc và ghi một bản ghi duy nhất, có thể quản lý được mà không cần giao dịch. Tuy nhiên, đối với các mẫu truy cập phức tạp hơn, giao dịch có thể giảm đáng kể số lượng các trường hợp lỗi tiềm năng mà bạn cần suy nghĩ đến.
Nếu không có giao dịch, các tình huống lỗi khác nhau (tiến trình bị crash, gián đoạn mạng, mất điện, đĩa đầy, đồng thời bất ngờ, v.v.) có nghĩa là dữ liệu có thể trở nên không nhất quán theo nhiều cách khác nhau. Ví dụ, dữ liệu denormalized có thể dễ dàng lệch khỏi đồng bộ với dữ liệu nguồn. Nếu không có giao dịch, việc suy luận về các tác động mà các truy cập tương tác phức tạp có thể có trên cơ sở dữ liệu trở nên rất khó khăn.
Trong chương này, chúng ta đã đi sâu vào chủ đề kiểm soát đồng thời (concurrency control). Chúng ta đã thảo luận về một số mức isolation được sử dụng rộng rãi, đặc biệt là read committed, snapshot isolation (đôi khi được gọi là repeatable read), và serializable. Chúng ta đã mô tả các mức isolation đó bằng cách thảo luận về các ví dụ khác nhau về race condition, được tóm tắt trong Bảng 8-1:
Bảng 8-1. Tóm tắt các bất thường có thể xảy ra ở các mức isolation khác nhau
| Mức isolation | Dirty reads | Read skew | Phantom reads | Lost updates | Write skew |
|---|---|---|---|---|---|
| Read uncommitted | ✗ Possible | ✗ Possible | ✗ Possible | ✗ Possible | ✗ Possible |
| Read committed | ✓ Prevented | ✗ Possible | ✗ Possible | ✗ Possible | ✗ Possible |
| Snapshot isolation | ✓ Prevented | ✓ Prevented | ✓ Prevented | ? Depends | ✗ Possible |
| Serializable | ✓ Prevented | ✓ Prevented | ✓ Prevented | ✓ Prevented | ✓ Prevented |
- Dirty reads (đọc bẩn)
- Một client đọc các lần ghi của client khác trước khi chúng được committed. Mức isolation read committed và các mức cao hơn ngăn chặn dirty reads.
- Dirty writes (ghi bẩn)
- Một client ghi đè dữ liệu mà một client khác đã ghi, nhưng chưa committed. Hầu hết tất cả các triển khai giao dịch đều ngăn chặn dirty writes.
- Read skew (lệch đọc)
- Một client thấy các phần khác nhau của cơ sở dữ liệu tại các thời điểm khác nhau. Một số trường hợp của read skew còn được gọi là nonrepeatable reads. Vấn đề này thường được ngăn chặn bằng snapshot isolation, cho phép một giao dịch đọc từ một snapshot nhất quán tương ứng với một thời điểm cụ thể. Nó thường được triển khai với multi-version concurrency control (MVCC, kiểm soát đồng thời đa phiên bản).
- Lost updates (cập nhật bị mất)
- Hai client đồng thời thực hiện chu trình read-modify-write. Một client ghi đè lên lần ghi của client kia mà không kết hợp các thay đổi của nó, dẫn đến mất dữ liệu. Một số triển khai của snapshot isolation ngăn chặn bất thường này tự động, trong khi các triển khai khác yêu cầu khóa thủ công (
SELECT FOR UPDATE). - Write skew (lệch ghi)
- Một giao dịch đọc một thứ gì đó, đưa ra quyết định dựa trên giá trị nó thấy, và ghi quyết định vào cơ sở dữ liệu. Tuy nhiên, vào thời điểm ghi được thực hiện, tiền đề của quyết định không còn đúng nữa. Chỉ có serializable isolation mới ngăn chặn bất thường này.
- Phantom reads (đọc bóng ma)
- Một giao dịch đọc các đối tượng phù hợp với một điều kiện tìm kiếm nào đó. Một client khác thực hiện một lần ghi ảnh hưởng đến kết quả của tìm kiếm đó. Snapshot isolation ngăn chặn phantom reads đơn giản, nhưng các phantom trong ngữ cảnh write skew đòi hỏi xử lý đặc biệt, chẳng hạn như index-range locks.
Các mức isolation yếu bảo vệ chống lại một số bất thường đó nhưng để lại cho bạn, nhà phát triển ứng dụng, phải xử lý các bất thường khác theo cách thủ công (ví dụ sử dụng khóa tường minh). Chỉ có serializable isolation mới bảo vệ chống lại tất cả những vấn đề này. Chúng ta đã thảo luận về ba cách tiếp cận khác nhau để triển khai các giao dịch serializable:
- Thực thi giao dịch theo thứ tự nối tiếp thực sự
- Nếu bạn có thể làm cho mỗi giao dịch thực thi rất nhanh (thường bằng cách sử dụng stored procedure), và throughput của giao dịch đủ thấp để xử lý trên một lõi CPU đơn hoặc có thể được sharded, đây là một lựa chọn đơn giản và hiệu quả.
- Two-phase locking (khóa hai pha)
- Trong nhiều thập kỷ, đây là cách tiêu chuẩn để triển khai serializability, nhưng nhiều ứng dụng tránh sử dụng nó vì hiệu suất kém.
- Serializable snapshot isolation (SSI)
- Một thuật toán tương đối mới tránh được hầu hết những nhược điểm của các cách tiếp cận trước. Nó sử dụng cách tiếp cận lạc quan (optimistic), cho phép các giao dịch tiến hành mà không bị chặn. Khi một giao dịch muốn commit, nó được kiểm tra, và bị abort nếu quá trình thực thi không phải là serializable.
Cuối cùng, chúng ta đã xem xét cách đạt được tính nguyên tử khi một giao dịch được phân tán qua nhiều nút, sử dụng two-phase commit. Nếu các nút đó đều chạy cùng phần mềm cơ sở dữ liệu, các giao dịch phân tán có thể hoạt động khá tốt, nhưng qua các công nghệ lưu trữ khác nhau (sử dụng giao dịch XA), 2PC là vấn đề: nó rất nhạy cảm với các lỗi trong coordinator và code ứng dụng điều khiển giao dịch, và nó tương tác kém với các cơ chế kiểm soát đồng thời. May mắn thay, tính idempotent có thể đảm bảo ngữ nghĩa exactly-once mà không cần atomic commit qua các công nghệ lưu trữ khác nhau, và chúng ta sẽ thấy thêm về điều này trong các chương sau.
Các ví dụ trong chương này sử dụng mô hình dữ liệu quan hệ (relational data model). Tuy nhiên, như đã thảo luận trong “The need for multi-object transactions”, giao dịch là một tính năng cơ sở dữ liệu có giá trị, bất kể mô hình dữ liệu nào được sử dụng.
Tài liệu tham khảo
Steven J. Murdoch. What went wrong with Horizon: learning from the Post Office Trial. benthamsgaze.org, July 2021. Archived at perma.cc/CNM4-553F ↩︎
Donald D. Chamberlin, Morton M. Astrahan, Michael W. Blasgen, James N. Gray, W. Frank King, Bruce G. Lindsay, Raymond Lorie, James W. Mehl, Thomas G. Price, Franco Putzolu, Patricia Griffiths Selinger, Mario Schkolnick, Donald R. Slutz, Irving L. Traiger, Bradford W. Wade, and Robert A. Yost. A History and Evaluation of System R. Communications of the ACM, volume 24, issue 10, pages 632–646, October 1981. doi:10.1145/358769.358784 ↩︎
Jim N. Gray, Raymond A. Lorie, Gianfranco R. Putzolu, and Irving L. Traiger. Granularity of Locks and Degrees of Consistency in a Shared Data Base. in Modelling in Data Base Management Systems: Proceedings of the IFIP Working Conference on Modelling in Data Base Management Systems, edited by G. M. Nijssen, pages 364–394, Elsevier/North Holland Publishing, 1976. Also in Readings in Database Systems, 4th edition, edited by Joseph M. Hellerstein and Michael Stonebraker, MIT Press, 2005. ISBN: 978-0-262-69314-1 ↩︎ ↩︎ ↩︎ ↩︎
Kapali P. Eswaran, Jim N. Gray, Raymond A. Lorie, and Irving L. Traiger. The Notions of Consistency and Predicate Locks in a Database System. Communications of the ACM, volume 19, issue 11, pages 624–633, November 1976. doi:10.1145/360363.360369 ↩︎ ↩︎ ↩︎
Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaffray, Lucy Zhang, and Peter Mattis. CockroachDB: The Resilient Geo-Distributed SQL Database. At ACM SIGMOD International Conference on Management of Data (SIGMOD), pages 1493–1509, June 2020. doi:10.1145/3318464.3386134 ↩︎ ↩︎ ↩︎
Dongxu Huang, Qi Liu, Qiu Cui, Zhuhe Fang, Xiaoyu Ma, Fei Xu, Li Shen, Liu Tang, Yuxing Zhou, Menglong Huang, Wan Wei, Cong Liu, Jian Zhang, Jianjun Li, Xuelian Wu, Lingyu Song, Ruoxi Sun, Shuaipeng Yu, Lei Zhao, Nicholas Cameron, Liquan Pei, and Xin Tang. TiDB: a Raft-based HTAP database. Proceedings of the VLDB Endowment, volume 13, issue 12, pages 3072–3084. doi:10.14778/3415478.3415535 ↩︎ ↩︎
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s Globally-Distributed Database. At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012. ↩︎ ↩︎
Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Namasivayam, Alex Miller, Evan Tschannen, Steve Atherton, Andrew J. Beamon, Rusty Sears, John Leach, Dave Rosenthal, Xin Dong, Will Wilson, Ben Collins, David Scherer, Alec Grieser, Young Liu, Alvin Moore, Bhaskar Muppana, Xiaoge Su, and Vishesh Yadav. FoundationDB: A Distributed Unbundled Transactional Key Value Store. At ACM International Conference on Management of Data (SIGMOD), June 2021. doi:10.1145/3448016.3457559 ↩︎ ↩︎ ↩︎ ↩︎
Theo Härder and Andreas Reuter. Principles of Transaction-Oriented Database Recovery. ACM Computing Surveys, volume 15, issue 4, pages 287–317, December 1983. doi:10.1145/289.291 ↩︎
Peter Bailis, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. HAT, not CAP: Towards Highly Available Transactions. At 14th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2013. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Armando Fox, Steven D. Gribble, Yatin Chawathe, Eric A. Brewer, and Paul Gauthier. Cluster-Based Scalable Network Services. At 16th ACM Symposium on Operating Systems Principles (SOSP), October 1997. doi:10.1145/268998.266662 ↩︎
Tony Andrews. Enforcing Complex Constraints in Oracle. tonyandrews.blogspot.co.uk, October 2004. Archived at archive.org ↩︎ ↩︎
Philip A. Bernstein, Vassos Hadzilacos, and Nathan Goodman. Concurrency Control and Recovery in Database Systems. Addison-Wesley, 1987. ISBN: 978-0-201-10715-9, available online at microsoft.com. ↩︎ ↩︎ ↩︎
Alan Fekete, Dimitrios Liarokapis, Elizabeth O’Neil, Patrick O’Neil, and Dennis Shasha. Making Snapshot Isolation Serializable. ACM Transactions on Database Systems, volume 30, issue 2, pages 492–528, June 2005. doi:10.1145/1071610.1071615 ↩︎ ↩︎ ↩︎
Mai Zheng, Joseph Tucek, Feng Qin, and Mark Lillibridge. Understanding the Robustness of SSDs Under Power Fault. At 11th USENIX Conference on File and Storage Technologies (FAST), February 2013. ↩︎
Laurie Denness. SSDs: A Gift and a Curse. laur.ie, June 2015. Archived at perma.cc/6GLP-BX3T ↩︎
Adam Surak. When Solid State Drives Are Not That Solid. blog.algolia.com, June 2015. Archived at perma.cc/CBR9-QZEE ↩︎
Hewlett Packard Enterprise. Bulletin: (Revision) HPE SAS Solid State Drives - Critical Firmware Upgrade Required for Certain HPE SAS Solid State Drive Models to Prevent Drive Failure at 32,768 Hours of Operation. support.hpe.com, November 2019. Archived at perma.cc/CZR4-AQBS ↩︎
Craig Ringer et al. PostgreSQL’s handling of fsync() errors is unsafe and risks data loss at least on XFS. Email thread on pgsql-hackers mailing list, postgresql.org, March 2018. Archived at perma.cc/5RKU-57FL ↩︎
Anthony Rebello, Yuvraj Patel, Ramnatthan Alagappan, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. Can Applications Recover from fsync Failures? At USENIX Annual Technical Conference (ATC), July 2020. ↩︎
Thanumalayan Sankaranarayana Pillai, Vijay Chidambaram, Ramnatthan Alagappan, Samer Al-Kiswany, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. Crash Consistency: Rethinking the Fundamental Abstractions of the File System. ACM Queue, volume 13, issue 7, pages 20–28, July 2015. doi:10.1145/2800695.2801719 ↩︎
Thanumalayan Sankaranarayana Pillai, Vijay Chidambaram, Ramnatthan Alagappan, Samer Al-Kiswany, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications. At 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2014. ↩︎ ↩︎
Chris Siebenmann. Unix’s File Durability Problem. utcc.utoronto.ca, April 2016. Archived at perma.cc/VSS8-5MC4 ↩︎
Aishwarya Ganesan, Ramnatthan Alagappan, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. Redundancy Does Not Imply Fault Tolerance: Analysis of Distributed Storage Reactions to Single Errors and Corruptions. At 15th USENIX Conference on File and Storage Technologies (FAST), February 2017. ↩︎
Lakshmi N. Bairavasundaram, Garth R. Goodson, Bianca Schroeder, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. An Analysis of Data Corruption in the Storage Stack. At 6th USENIX Conference on File and Storage Technologies (FAST), February 2008. ↩︎
Bianca Schroeder, Raghav Lagisetty, and Arif Merchant. Flash Reliability in Production: The Expected and the Unexpected. At 14th USENIX Conference on File and Storage Technologies (FAST), February 2016. ↩︎
Don Allison. SSD Storage – Ignorance of Technology Is No Excuse. blog.korelogic.com, March 2015. Archived at perma.cc/9QN4-9SNJ ↩︎
Gordon Mah Ung. Debunked: Your SSD won’t lose data if left unplugged after all. pcworld.com, May 2015. Archived at perma.cc/S46H-JUDU ↩︎
Martin Kleppmann. Hermitage: Testing the ‘I’ in ACID. martin.kleppmann.com, November 2014. Archived at perma.cc/KP2Y-AQGK ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Todd Warszawski and Peter Bailis. ACIDRain: Concurrency-Related Attacks on Database-Backed Web Applications. At ACM International Conference on Management of Data (SIGMOD), May 2017. doi:10.1145/3035918.3064037 ↩︎ ↩︎
Tristan D’Agosta. BTC Stolen from Poloniex. bitcointalk.org, March 2014. Archived at perma.cc/YHA6-4C5D ↩︎
bitcointhief2. How I Stole Roughly 100 BTC from an Exchange and How I Could Have Stolen More! reddit.com, February 2014. Archived at archive.org ↩︎
Sudhir Jorwekar, Alan Fekete, Krithi Ramamritham, and S. Sudarshan. Automating the Detection of Snapshot Isolation Anomalies. At 33rd International Conference on Very Large Data Bases (VLDB), September 2007. ↩︎ ↩︎
Michael Melanson. Transactions: The Limits of Isolation. michaelmelanson.net, November 2014. Archived at perma.cc/RG5R-KMYZ ↩︎
Edward Kim. How ACH works: A developer perspective — Part 1. engineering.gusto.com, April 2014. Archived at perma.cc/7B2H-PU94 ↩︎
Hal Berenson, Philip A. Bernstein, Jim N. Gray, Jim Melton, Elizabeth O’Neil, and Patrick O’Neil. A Critique of ANSI SQL Isolation Levels. At ACM International Conference on Management of Data (SIGMOD), May 1995. doi:10.1145/568271.223785 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Atul Adya. Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions. PhD Thesis, Massachusetts Institute of Technology, March 1999. Archived at perma.cc/E97M-HW5Q ↩︎ ↩︎
Peter Bailis, Aaron Davidson, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Highly Available Transactions: Virtues and Limitations. At 40th International Conference on Very Large Data Bases (VLDB), September 2014. ↩︎ ↩︎ ↩︎
Natacha Crooks, Youer Pu, Lorenzo Alvisi, and Allen Clement. Seeing is Believing: A Client-Centric Specification of Database Isolation. At ACM Symposium on Principles of Distributed Computing (PODC), pages 73–82, July 2017. doi:10.1145/3087801.3087802 ↩︎
Bruce Momjian. MVCC Unmasked. momjian.us, July 2014. Archived at perma.cc/KQ47-9GYB ↩︎ ↩︎ ↩︎
Peter Alvaro and Kyle Kingsbury. MySQL 8.0.34. jepsen.io, December 2023. Archived at perma.cc/HGE2-Z878 ↩︎ ↩︎ ↩︎
Egor Rogov. PostgreSQL 14 Internals. postgrespro.com, April 2023. Archived at perma.cc/FRK2-D7WB ↩︎
Hironobu Suzuki. The Internals of PostgreSQL. interdb.jp, 2017. ↩︎ ↩︎
Rohan Reddy Alleti. Internals of MVCC in Postgres: Hidden costs of Updates vs Inserts. medium.com, March 2025. Archived at perma.cc/3ACX-DFXT ↩︎
Andy Pavlo and Bohan Zhang. The Part of PostgreSQL We Hate the Most. cs.cmu.edu, April 2023. Archived at perma.cc/XSP6-3JBN ↩︎ ↩︎
Yingjun Wu, Joy Arulraj, Jiexi Lin, Ran Xian, and Andrew Pavlo. An empirical evaluation of in-memory multi-version concurrency control. Proceedings of the VLDB Endowment, volume 10, issue 7, pages 781–792, March 2017. doi:10.14778/3067421.3067427 ↩︎ ↩︎
Nikita Prokopov. Unofficial Guide to Datomic Internals. tonsky.me, May 2014. ↩︎
Daniil Svetlov. A Practical Guide to Taming Postgres Isolation Anomalies. dansvetlov.me, March 2025. Archived at perma.cc/L7LE-TDLS ↩︎
Nate Wiger. An Atomic Rant. nateware.com, February 2010. Archived at perma.cc/5ZYB-PE44 ↩︎
James Coglan. Reading and writing, part 3: web applications. blog.jcoglan.com, October 2020. Archived at perma.cc/A7EK-PJVS ↩︎ ↩︎
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Feral Concurrency Control: An Empirical Investigation of Modern Application Integrity. At ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2737784 ↩︎ ↩︎
Jaana Dogan. Things I Wished More Developers Knew About Databases. rakyll.medium.com, April 2020. Archived at perma.cc/6EFK-P2TD ↩︎
Michael J. Cahill, Uwe Röhm, and Alan Fekete. Serializable Isolation for Snapshot Databases. At ACM International Conference on Management of Data (SIGMOD), June 2008. doi:10.1145/1376616.1376690 ↩︎ ↩︎
Dan R. K. Ports and Kevin Grittner. Serializable Snapshot Isolation in PostgreSQL. At 38th International Conference on Very Large Databases (VLDB), August 2012. ↩︎ ↩︎ ↩︎ ↩︎
Douglas B. Terry, Marvin M. Theimer, Karin Petersen, Alan J. Demers, Mike J. Spreitzer and Carl H. Hauser. Managing Update Conflicts in Bayou, a Weakly Connected Replicated Storage System. At 15th ACM Symposium on Operating Systems Principles (SOSP), December 1995. doi:10.1145/224056.224070 ↩︎
Hans-Jürgen Schönig. Constraints over multiple rows in PostgreSQL. cybertec-postgresql.com, June 2021. Archived at perma.cc/2TGH-XUPZ ↩︎
Michael Stonebraker, Samuel Madden, Daniel J. Abadi, Stavros Harizopoulos, Nabil Hachem, and Pat Helland. The End of an Architectural Era (It’s Time for a Complete Rewrite). At 33rd International Conference on Very Large Data Bases (VLDB), September 2007. ↩︎
John Hugg. H-Store/VoltDB Architecture vs. CEP Systems and Newer Streaming Architectures. At Data @Scale Boston, November 2014. ↩︎
Robert Kallman, Hideaki Kimura, Jonathan Natkins, Andrew Pavlo, Alexander Rasin, Stanley Zdonik, Evan P. C. Jones, Samuel Madden, Michael Stonebraker, Yang Zhang, John Hugg, and Daniel J. Abadi. H-Store: A High-Performance, Distributed Main Memory Transaction Processing System. Proceedings of the VLDB Endowment, volume 1, issue 2, pages 1496–1499, August 2008. ↩︎ ↩︎
Rich Hickey. The Architecture of Datomic. infoq.com, November 2012. Archived at perma.cc/5YWU-8XJK ↩︎
John Hugg. Debunking Myths About the VoltDB In-Memory Database. dzone.com, May 2014. Archived at perma.cc/2Z9N-HPKF ↩︎ ↩︎
Xinjing Zhou, Viktor Leis, Xiangyao Yu, and Michael Stonebraker. OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck. At 15th Annual Conference on Innovative Data Systems Research (CIDR), January 2025. ↩︎
Xinjing Zhou, Xiangyao Yu, Goetz Graefe, and Michael Stonebraker. Lotus: scalable multi-partition transactions on single-threaded partitioned databases. Proceedings of the VLDB Endowment (PVLDB), volume 15, issue 11, pages 2939–2952, July 2022. doi:10.14778/3551793.3551843 ↩︎
Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton. Architecture of a Database System. Foundations and Trends in Databases, volume 1, issue 2, pages 141–259, November 2007. doi:10.1561/1900000002 ↩︎
Michael J. Cahill. Serializable Isolation for Snapshot Databases. PhD Thesis, University of Sydney, July 2009. Archived at perma.cc/727J-NTMP ↩︎
Cristian Diaconu, Craig Freedman, Erik Ismert, Per-Åke Larson, Pravin Mittal, Ryan Stonecipher, Nitin Verma, and Mike Zwilling. Hekaton: SQL Server’s Memory-Optimized OLTP Engine. At ACM SIGMOD International Conference on Management of Data (SIGMOD), pages 1243–1254, June 2013. doi:10.1145/2463676.2463710 ↩︎
Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. At ACM SIGMOD International Conference on Management of Data (SIGMOD), pages 677–689, May 2015. doi:10.1145/2723372.2749436 ↩︎ ↩︎
D. Z. Badal. Correctness of Concurrency Control and Implications in Distributed Databases. At 3rd International IEEE Computer Software and Applications Conference (COMPSAC), November 1979. doi:10.1109/CMPSAC.1979.762563 ↩︎
Rakesh Agrawal, Michael J. Carey, and Miron Livny. Concurrency Control Performance Modeling: Alternatives and Implications. ACM Transactions on Database Systems (TODS), volume 12, issue 4, pages 609–654, December 1987. doi:10.1145/32204.32220 ↩︎
Marc Brooker. Snapshot Isolation vs Serializability. brooker.co.za, December 2024. Archived at perma.cc/5TRC-CR5G ↩︎
B. G. Lindsay, P. G. Selinger, C. Galtieri, J. N. Gray, R. A. Lorie, T. G. Price, F. Putzolu, I. L. Traiger, and B. W. Wade. Notes on Distributed Databases. IBM Research, Research Report RJ2571(33471), July 1979. Archived at perma.cc/EPZ3-MHDD ↩︎
C. Mohan, Bruce G. Lindsay, and Ron Obermarck. Transaction Management in the R* Distributed Database Management System. ACM Transactions on Database Systems, volume 11, issue 4, pages 378–396, December 1986. doi:10.1145/7239.7266 ↩︎
X/Open Company Ltd. Distributed Transaction Processing: The XA Specification. Technical Standard XO/CAE/91/300, December 1991. ISBN: 978-1-872-63024-3, archived at perma.cc/Z96H-29JB ↩︎ ↩︎ ↩︎
Ivan Silva Neto and Francisco Reverbel. Lessons Learned from Implementing WS-Coordination and WS-AtomicTransaction. At 7th IEEE/ACIS International Conference on Computer and Information Science (ICIS), May 2008. doi:10.1109/ICIS.2008.75 ↩︎
James E. Johnson, David E. Langworthy, Leslie Lamport, and Friedrich H. Vogt. Formal Specification of a Web Services Protocol. At 1st International Workshop on Web Services and Formal Methods (WS-FM), February 2004. doi:10.1016/j.entcs.2004.02.022 ↩︎
Jim Gray. The Transaction Concept: Virtues and Limitations. At 7th International Conference on Very Large Data Bases (VLDB), September 1981. ↩︎
Dale Skeen. Nonblocking Commit Protocols. At ACM International Conference on Management of Data (SIGMOD), April 1981. doi:10.1145/582318.582339 ↩︎
Gregor Hohpe. Your Coffee Shop Doesn’t Use Two-Phase Commit. IEEE Software, volume 22, issue 2, pages 64–66, March 2005. doi:10.1109/MS.2005.52 ↩︎
Pat Helland. Life Beyond Distributed Transactions: An Apostate’s Opinion. At 3rd Biennial Conference on Innovative Data Systems Research (CIDR), January 2007. ↩︎
Jonathan Oliver. My Beef with MSDTC and Two-Phase Commits. blog.jonathanoliver.com, April 2011. Archived at perma.cc/K8HF-Z4EN ↩︎
Oren Eini (Ahende Rahien). The Fallacy of Distributed Transactions. ayende.com, July 2014. Archived at perma.cc/VB87-2JEF ↩︎
Clemens Vasters. Transactions in Windows Azure (with Service Bus) – An Email Discussion. learn.microsoft.com, July 2012. Archived at perma.cc/4EZ9-5SKW ↩︎
Ajmer Dhariwal. Orphaned MSDTC Transactions (-2 spids). eraofdata.com, December 2008. Archived at perma.cc/YG6F-U34C ↩︎
Paul Randal. Real World Story of DBCC PAGE Saving the Day. sqlskills.com, June 2013. Archived at perma.cc/2MJN-A5QH ↩︎