7. Sharding
Rõ ràng, chúng ta phải thoát khỏi lối tư duy tuần tự và không để máy tính bị giới hạn. Chúng ta phải phát biểu các định nghĩa và cung cấp các ưu tiên cũng như mô tả về dữ liệu. Chúng ta phải diễn đạt các mối quan hệ, chứ không phải các thủ tục.
Grace Murray Hopper, Management and the Computer of the Future (1962)
Một cơ sở dữ liệu phân tán thường phân phối dữ liệu qua các nút theo hai cách:
- Lưu một bản sao của cùng một dữ liệu trên nhiều nút: đây là replication (nhân bản), đã được thảo luận trong Chương 6.
- Nếu chúng ta không muốn mỗi nút lưu trữ toàn bộ dữ liệu, chúng ta có thể chia một lượng lớn dữ liệu thành các shard (mảnh) hoặc partition (phân vùng) nhỏ hơn, và lưu các shard khác nhau trên các nút khác nhau. Chúng ta sẽ thảo luận về sharding trong chương này.
Thông thường, các shard được định nghĩa sao cho mỗi đơn vị dữ liệu (mỗi bản ghi, hàng, hoặc tài liệu) thuộc về đúng một shard. Có nhiều cách để thực hiện điều này, và chúng ta sẽ thảo luận chi tiết trong chương này. Về bản chất, mỗi shard là một cơ sở dữ liệu nhỏ độc lập, mặc dù một số hệ thống cơ sở dữ liệu hỗ trợ các thao tác tác động đồng thời lên nhiều shard.
Sharding thường được kết hợp với replication để các bản sao của mỗi shard được lưu trên nhiều nút. Điều này có nghĩa là, mặc dù mỗi bản ghi thuộc về đúng một shard, nó vẫn có thể được lưu trên một số nút khác nhau để đảm bảo khả năng chịu lỗi.
Một nút có thể lưu trữ nhiều hơn một shard. Nếu mô hình replication single-leader được sử dụng, sự kết hợp giữa sharding và replication có thể trông như Hình 7-1, chẳng hạn. Leader của mỗi shard được gán cho một nút, và các follower được gán cho các nút khác. Mỗi nút có thể là leader cho một số shard và là follower cho các shard khác, nhưng mỗi shard vẫn chỉ có một leader.
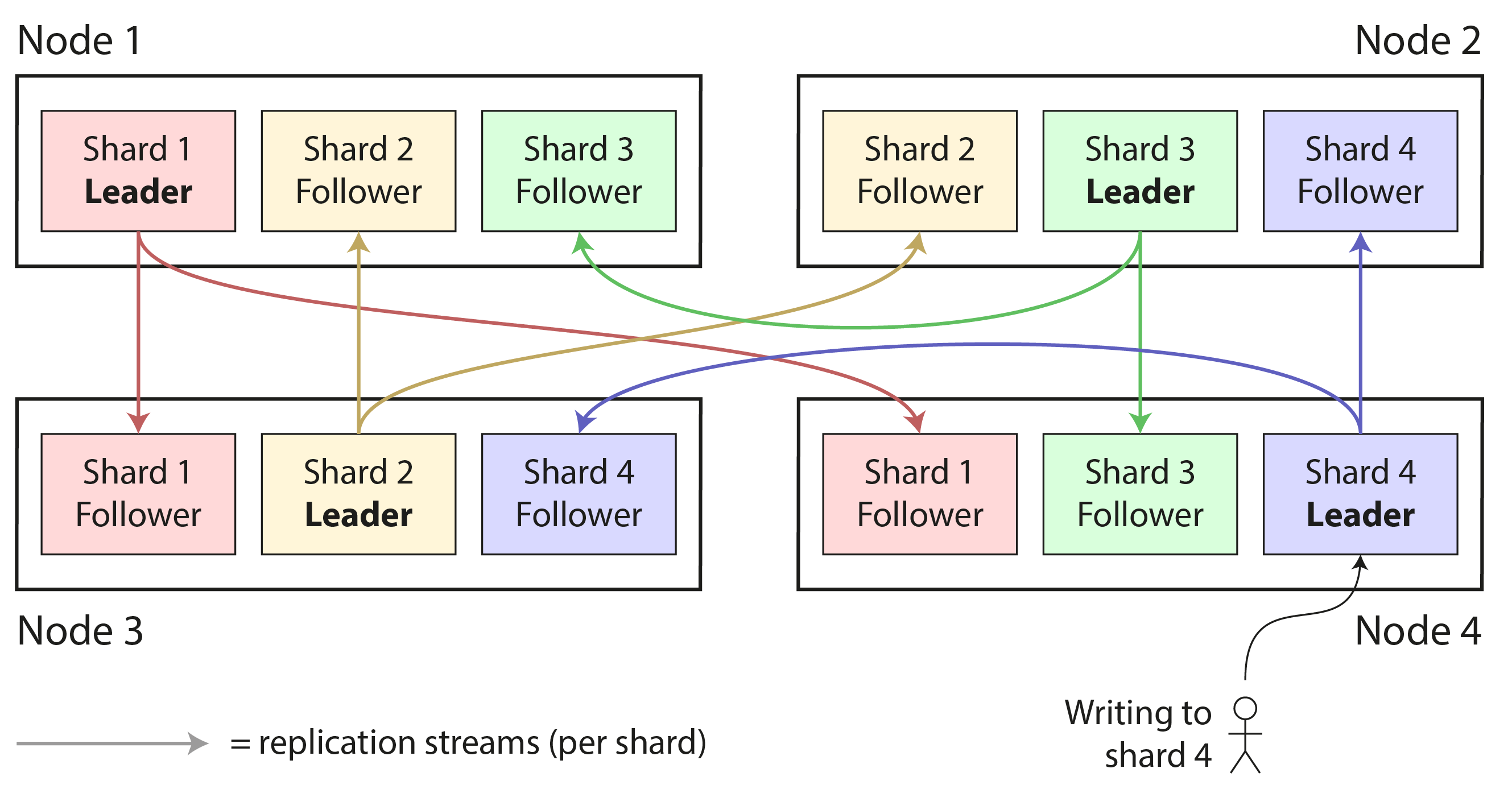
Tất cả những gì chúng ta đã thảo luận trong Chương 6 về replication của cơ sở dữ liệu đều áp dụng tương tự cho replication của các shard. Vì việc chọn sơ đồ sharding phần lớn độc lập với việc chọn sơ đồ replication, chúng ta sẽ bỏ qua replication trong chương này để đơn giản hóa.
SHARDING VÀ PARTITIONING
Những gì chúng ta gọi là shard trong chương này có nhiều tên gọi khác nhau tùy thuộc vào phần mềm bạn đang sử dụng: được gọi là partition trong Kafka, range trong CockroachDB, region trong HBase và TiDB, tablet trong Bigtable và YugabyteDB, vnode trong Cassandra, ScyllaDB, và Riak, và vBucket trong Couchbase, chỉ kể một vài tên.
Một số cơ sở dữ liệu coi partition và shard là hai khái niệm riêng biệt. Ví dụ, trong PostgreSQL, partitioning là cách chia một bảng lớn thành nhiều tệp được lưu trên cùng một máy (điều này có một số ưu điểm, chẳng hạn như giúp xóa toàn bộ một partition rất nhanh), trong khi sharding chia một tập dữ liệu qua nhiều máy 1 2. Trong nhiều hệ thống khác, partitioning chỉ là một cách gọi khác của sharding.
Trong khi partitioning khá mang tính mô tả, thì thuật ngữ sharding có lẽ gây ngạc nhiên. Theo một lý thuyết, thuật ngữ này xuất hiện từ trò chơi nhập vai trực tuyến Ultima Online, trong đó một viên pha lê ma thuật bị vỡ thành nhiều mảnh, và mỗi mảnh đó phản chiếu một bản sao của thế giới trò chơi 3. Thuật ngữ shard do đó mang nghĩa là một trong số các máy chủ trò chơi song song, và sau đó được chuyển sang lĩnh vực cơ sở dữ liệu. Một lý thuyết khác cho rằng shard ban đầu là từ viết tắt của System for Highly Available Replicated Data - được cho là một cơ sở dữ liệu từ những năm 1980, chi tiết đã bị thất truyền.
Nhân tiện, partitioning không liên quan gì đến network partitions (netsplits), một loại lỗi trong mạng giữa các nút. Chúng ta sẽ thảo luận về các lỗi như vậy trong Chương 9.
Ưu và Nhược điểm của Sharding
Lý do chính để sharding một cơ sở dữ liệu là khả năng mở rộng (scalability): đây là giải pháp khi khối lượng dữ liệu hoặc thông lượng ghi đã trở nên quá lớn để một nút đơn lẻ có thể xử lý, vì nó cho phép bạn phân tán dữ liệu và các thao tác ghi đó qua nhiều nút. (Nếu thông lượng đọc là vấn đề, bạn không nhất thiết phải dùng sharding - bạn có thể sử dụng read scaling như đã thảo luận trong Chương 6.)
Trên thực tế, sharding là một trong những công cụ chính để đạt được horizontal scaling (kiến trúc scale-out), như đã thảo luận trong “Shared-Memory, Shared-Disk, and Shared-Nothing Architecture”: tức là, cho phép một hệ thống tăng năng lực không phải bằng cách chuyển sang máy lớn hơn, mà bằng cách thêm nhiều máy (nhỏ hơn) hơn. Nếu bạn có thể phân chia khối lượng công việc sao cho mỗi shard xử lý khoảng một phần bằng nhau, bạn có thể gán các shard đó cho các máy khác nhau để xử lý dữ liệu và truy vấn của chúng song song.
Trong khi replication hữu ích ở cả quy mô nhỏ và lớn, vì nó cho phép khả năng chịu lỗi và hoạt động ngoại tuyến, thì sharding là một giải pháp nặng nề chủ yếu phù hợp ở quy mô lớn. Nếu khối lượng dữ liệu và thông lượng ghi của bạn đủ để xử lý trên một máy đơn lẻ (và một máy đơn có thể làm được rất nhiều ngày nay!), thường tốt hơn là tránh sharding và tiếp tục với cơ sở dữ liệu một shard.
Lý do cho khuyến nghị này là sharding thường thêm độ phức tạp: bạn thường phải quyết định bản ghi nào đặt trong shard nào bằng cách chọn một partition key (khóa phân vùng); tất cả các bản ghi có cùng partition key được đặt trong cùng một shard 4. Sự lựa chọn này rất quan trọng vì việc truy cập một bản ghi sẽ nhanh nếu bạn biết nó ở shard nào, nhưng nếu bạn không biết shard thì bạn phải thực hiện tìm kiếm kém hiệu quả qua tất cả các shard, và sơ đồ sharding khó thay đổi.
Do đó, sharding thường hoạt động tốt với dữ liệu dạng key-value, nơi bạn có thể dễ dàng shard theo key, nhưng khó hơn với dữ liệu quan hệ nơi bạn có thể muốn tìm kiếm theo secondary index, hoặc join các bản ghi có thể được phân tán qua các shard khác nhau. Chúng ta sẽ thảo luận thêm về điều này trong “Sharding và Secondary Indexes”.
Một vấn đề khác với sharding là một thao tác ghi có thể cần cập nhật các bản ghi liên quan trong nhiều shard khác nhau. Trong khi các transaction trên một nút đơn lẻ khá phổ biến (xem Chương 8), việc đảm bảo tính nhất quán qua nhiều shard đòi hỏi một distributed transaction (transaction phân tán). Như chúng ta sẽ thấy trong Chương 8, distributed transaction có trong một số cơ sở dữ liệu, nhưng chúng thường chậm hơn nhiều so với transaction trên một nút, có thể trở thành điểm nghẽn cho toàn bộ hệ thống, và một số hệ thống không hỗ trợ chúng.
Một số hệ thống sử dụng sharding ngay cả trên một máy đơn, thường chạy một tiến trình đơn luồng cho mỗi lõi CPU để tận dụng sự song song trong CPU, hoặc để tận dụng kiến trúc nonuniform memory access (NUMA) trong đó một số vùng bộ nhớ gần hơn với một CPU so với các CPU khác 5. Ví dụ, Redis, VoltDB, và FoundationDB sử dụng một tiến trình cho mỗi lõi, và dựa vào sharding để phân tán tải qua các lõi CPU trong cùng một máy 6.
Sharding cho Multitenancy
Các sản phẩm Software as a Service (SaaS) và dịch vụ đám mây thường là multitenant (đa người thuê), trong đó mỗi tenant là một khách hàng. Nhiều người dùng có thể đăng nhập vào cùng một tenant, nhưng mỗi tenant có một tập dữ liệu riêng biệt tách khỏi các tenant khác. Ví dụ, trong một dịch vụ email marketing, mỗi doanh nghiệp đăng ký thường là một tenant riêng biệt, vì dữ liệu đăng ký bản tin, dữ liệu gửi thư, v.v. của một doanh nghiệp tách biệt với các doanh nghiệp khác.
Đôi khi sharding được sử dụng để triển khai các hệ thống multitenant: hoặc mỗi tenant được cấp một shard riêng, hoặc nhiều tenant nhỏ có thể được nhóm lại thành một shard lớn hơn. Các shard này có thể là các cơ sở dữ liệu vật lý riêng biệt (mà chúng ta đã đề cập trước đây trong “Embedded storage engines”), hoặc các phần có thể quản lý riêng của một cơ sở dữ liệu logic lớn hơn 7. Sử dụng sharding cho multitenancy có một số ưu điểm:
- Cô lập tài nguyên (Resource isolation)
- Nếu một tenant thực hiện một thao tác tốn nhiều tài nguyên tính toán, ít có khả năng ảnh hưởng đến hiệu suất của các tenant khác nếu họ đang chạy trên các shard khác nhau.
- Cô lập quyền truy cập (Permission isolation)
- Nếu có lỗi trong logic kiểm soát truy cập của bạn, ít có khả năng bạn vô tình cấp cho một tenant quyền truy cập vào dữ liệu của tenant khác nếu các tập dữ liệu của những tenant đó được lưu trữ vật lý tách biệt nhau.
- Kiến trúc dựa trên cell (Cell-based architecture)
- Bạn có thể áp dụng sharding không chỉ ở tầng lưu trữ dữ liệu, mà còn cho các dịch vụ chạy code ứng dụng của bạn. Trong một cell-based architecture (kiến trúc dựa trên cell), các dịch vụ và bộ lưu trữ cho một tập tenant cụ thể được nhóm lại thành một cell tự chứa, và các cell khác nhau được thiết lập sao cho chúng có thể chạy phần lớn độc lập với nhau. Cách tiếp cận này cung cấp fault isolation (cô lập lỗi): tức là, một lỗi trong một cell vẫn giới hạn trong cell đó, và các tenant trong các cell khác không bị ảnh hưởng 8.
- Sao lưu và khôi phục theo tenant (Per-tenant backup and restore)
- Sao lưu shard của mỗi tenant riêng biệt giúp có thể khôi phục trạng thái của tenant từ bản sao lưu mà không ảnh hưởng đến các tenant khác, điều này có thể hữu ích trong trường hợp tenant vô tình xóa hoặc ghi đè dữ liệu quan trọng 9.
- Tuân thủ quy định (Regulatory compliance)
- Quy định bảo vệ quyền riêng tư dữ liệu như GDPR trao cho các cá nhân quyền truy cập và xóa tất cả dữ liệu được lưu về họ. Nếu dữ liệu của mỗi người được lưu trong một shard riêng biệt, điều này chuyển thành các thao tác xuất và xóa dữ liệu đơn giản trên shard của họ 10.
- Lưu trữ dữ liệu theo vùng (Data residence)
- Nếu dữ liệu của một tenant cụ thể cần được lưu trong một phạm vi địa lý nhất định để tuân thủ các luật về lưu trú dữ liệu, một cơ sở dữ liệu nhận biết vùng có thể cho phép bạn gán shard của tenant đó cho một vùng cụ thể.
- Triển khai schema từng bước (Gradual schema rollout)
- Các migration schema (đã thảo luận trước đây trong “Schema flexibility in the document model”) có thể được triển khai dần dần, một tenant mỗi lúc. Điều này giảm rủi ro, vì bạn có thể phát hiện vấn đề trước khi chúng ảnh hưởng đến tất cả các tenant, nhưng có thể khó thực hiện theo cách transactional 11.
Những thách thức chính khi sử dụng sharding cho multitenancy là:
- Nó giả định rằng mỗi tenant riêng lẻ đủ nhỏ để vừa trên một nút đơn. Nếu điều đó không đúng, và bạn có một tenant quá lớn cho một máy, bạn sẽ cần thực hiện thêm sharding trong một tenant đơn lẻ, điều này đưa chúng ta trở lại chủ đề sharding để mở rộng khả năng 12.
- Nếu bạn có nhiều tenant nhỏ, thì việc tạo một shard riêng cho mỗi tenant có thể tốn quá nhiều tài nguyên. Bạn có thể nhóm nhiều tenant nhỏ lại thành một shard lớn hơn, nhưng khi đó bạn gặp vấn đề về cách chuyển tenant từ shard này sang shard khác khi họ phát triển.
- Nếu bạn cần hỗ trợ các tính năng kết nối dữ liệu qua nhiều tenant, chúng sẽ khó triển khai hơn nếu bạn cần join dữ liệu qua nhiều shard.
Sharding Dữ Liệu Key-Value
Giả sử bạn có một lượng lớn dữ liệu và bạn muốn shard nó. Bạn quyết định lưu bản ghi nào trên nút nào bằng cách nào?
Mục tiêu của sharding là phân tán dữ liệu và tải truy vấn đồng đều qua các nút. Nếu mỗi nút đảm nhận một phần công bằng, thì về lý thuyết, 10 nút có thể xử lý gấp 10 lần dữ liệu và gấp 10 lần thông lượng đọc và ghi của một nút đơn lẻ (bỏ qua replication). Hơn nữa, nếu chúng ta thêm hoặc xóa một nút, chúng ta muốn có khả năng rebalance (cân bằng lại) tải sao cho nó được phân tán đồng đều qua 11 nút (khi thêm) hoặc 9 nút còn lại (khi xóa).
Nếu việc sharding không công bằng, sao cho một số shard có nhiều dữ liệu hoặc truy vấn hơn các shard khác, chúng ta gọi đó là skewed (lệch). Sự hiện diện của skew làm cho sharding kém hiệu quả hơn nhiều. Trong trường hợp cực đoan, tất cả tải có thể dồn vào một shard, do đó 9 trong số 10 nút đang nhàn rỗi và điểm nghẽn của bạn là nút bận duy nhất đó. Một shard có tải không cân đối cao được gọi là hot shard hoặc hot spot. Nếu có một key có tải đặc biệt cao (ví dụ, một người nổi tiếng trong mạng xã hội), chúng ta gọi nó là hot key.
Do đó chúng ta cần một thuật toán nhận vào partition key của một bản ghi và cho chúng ta biết bản ghi đó ở shard nào. Trong một key-value store, partition key thường là key, hoặc phần đầu của key. Trong mô hình quan hệ, partition key có thể là một số cột của bảng (không nhất thiết là khóa chính). Thuật toán đó cần phù hợp với việc rebalancing để giải quyết các hot spot.
Sharding theo Key Range
Một cách sharding là gán một phạm vi liên tiếp của các partition key (từ một giá trị tối thiểu đến tối đa nào đó) cho mỗi shard, giống như các tập của một bộ bách khoa toàn thư in ấn, như minh họa trong Hình 7-2. Trong ví dụ này, partition key của một mục là tiêu đề của nó. Nếu bạn muốn tra cứu mục cho một tiêu đề cụ thể, bạn có thể dễ dàng xác định shard nào chứa mục đó bằng cách tìm tập mà phạm vi key chứa tiêu đề bạn đang tìm, từ đó chọn đúng cuốn sách trên giá.

Các phạm vi key không nhất thiết phải cách đều nhau, vì dữ liệu của bạn có thể không được phân tán đều. Ví dụ, trong Hình 7-2, tập 1 chứa các từ bắt đầu bằng A và B, nhưng tập 12 chứa các từ bắt đầu bằng T, U, V, W, X, Y, và Z. Chỉ đơn giản là có một tập cho mỗi hai chữ cái trong bảng chữ cái sẽ dẫn đến một số tập lớn hơn nhiều so với các tập khác. Để phân tán dữ liệu đồng đều, các ranh giới shard cần thích ứng với dữ liệu.
Các ranh giới shard có thể được chọn thủ công bởi một quản trị viên, hoặc cơ sở dữ liệu có thể tự động chọn chúng. Key-range sharding thủ công được sử dụng bởi Vitess (một lớp sharding cho MySQL), chẳng hạn; biến thể tự động được sử dụng bởi Bigtable, tương đương mã nguồn mở của nó là HBase, tùy chọn sharding theo range trong MongoDB, CockroachDB, RethinkDB, và FoundationDB 6. YugabyteDB cung cấp cả việc tách tablet thủ công và tự động.
Trong mỗi shard, các key được lưu theo thứ tự sắp xếp (ví dụ, trong B-tree hoặc SSTable, như đã thảo luận trong Chương 4). Điều này có ưu điểm là các range scan dễ dàng, và bạn có thể coi key là một chỉ mục kết hợp để lấy nhiều bản ghi liên quan trong một truy vấn (xem “Multidimensional and Full-Text Indexes”). Ví dụ, xem xét một ứng dụng lưu trữ dữ liệu từ một mạng lưới cảm biến, trong đó key là timestamp của phép đo. Các range scan rất hữu ích trong trường hợp này, vì chúng cho phép bạn dễ dàng lấy, chẳng hạn, tất cả các số đọc từ một tháng cụ thể.
Một nhược điểm của key range sharding là bạn có thể dễ dàng gặp hot shard nếu có nhiều thao tác ghi vào các key gần nhau. Ví dụ, nếu key là timestamp, thì các shard tương ứng với các khoảng thời gian - ví dụ, một shard cho mỗi tháng. Thật không may, nếu bạn ghi dữ liệu từ các cảm biến vào cơ sở dữ liệu khi các phép đo xảy ra, tất cả các thao tác ghi đều đến shard đó (shard của tháng hiện tại), do đó shard đó có thể bị quá tải với các thao tác ghi trong khi các shard khác ngồi nhàn rỗi 13.
Để tránh vấn đề này trong cơ sở dữ liệu cảm biến, bạn cần sử dụng thứ gì đó khác ngoài timestamp làm phần tử đầu tiên của key. Ví dụ, bạn có thể đặt tiền tố mỗi timestamp bằng ID cảm biến sao cho thứ tự key là theo ID cảm biến trước rồi mới đến timestamp. Giả sử bạn có nhiều cảm biến hoạt động cùng lúc, tải ghi sẽ được phân tán đồng đều hơn qua các shard. Nhược điểm là khi bạn muốn lấy giá trị của nhiều cảm biến trong một khoảng thời gian, bạn cần thực hiện một range query riêng biệt cho mỗi cảm biến.
Rebalancing dữ liệu được shard theo key range
Khi bạn lần đầu thiết lập cơ sở dữ liệu, không có key range nào để chia thành các shard. Một số cơ sở dữ liệu, chẳng hạn như HBase và MongoDB, cho phép bạn cấu hình một tập shard ban đầu trên một cơ sở dữ liệu trống, được gọi là pre-splitting (phân chia trước). Điều này đòi hỏi bạn phải có một ý tưởng nào đó về phân phối key sẽ trông như thế nào, để bạn có thể chọn các ranh giới key range phù hợp 14.
Sau đó, khi khối lượng dữ liệu và thông lượng ghi của bạn tăng lên, một hệ thống với key-range sharding phát triển bằng cách chia một shard hiện có thành hai hoặc nhiều shard nhỏ hơn, mỗi shard giữ một phần dải key liên tiếp của shard gốc. Các shard nhỏ hơn kết quả sau đó có thể được phân tán qua nhiều nút. Nếu một lượng lớn dữ liệu bị xóa, bạn cũng có thể cần hợp nhất một số shard kề nhau đã trở nên nhỏ lại thành một shard lớn hơn. Quá trình này tương tự với những gì xảy ra ở cấp độ cao nhất của B-tree (xem “B-Trees”).
Với các cơ sở dữ liệu quản lý ranh giới shard tự động, việc chia shard thường được kích hoạt bởi:
- shard đạt đến một kích thước được cấu hình (ví dụ, trên HBase, mặc định là 10 GB), hoặc
- trong một số hệ thống, thông lượng ghi liên tục vượt quá một ngưỡng nào đó. Do đó, một shard hot có thể bị chia ngay cả khi nó không lưu trữ nhiều dữ liệu, để tải ghi của nó có thể được phân tán đồng đều hơn.
Một ưu điểm của key-range sharding là số lượng shard thích ứng với khối lượng dữ liệu. Nếu chỉ có một lượng nhỏ dữ liệu, một số lượng shard nhỏ là đủ, do đó tài nguyên overhead ít; nếu có một lượng lớn dữ liệu, kích thước của mỗi shard riêng lẻ bị giới hạn ở một mức tối đa có thể cấu hình 15.
Một nhược điểm của cách tiếp cận này là việc chia shard là một thao tác tốn kém, vì nó đòi hỏi tất cả dữ liệu của nó phải được viết lại vào các tệp mới, tương tự như một compaction trong storage engine có cấu trúc log. Một shard cần chia thường cũng là shard đang chịu tải cao, và chi phí của việc chia có thể làm trầm trọng thêm tải đó, tạo ra rủi ro bị quá tải.
Sharding theo Hash của Key
Key-range sharding hữu ích nếu bạn muốn các bản ghi với partition key gần nhau (nhưng khác nhau) được nhóm vào cùng một shard; ví dụ, đây có thể là trường hợp với timestamp. Nếu bạn không quan tâm liệu các partition key có gần nhau hay không (ví dụ, nếu chúng là tenant ID trong một ứng dụng multitenant), một cách tiếp cận phổ biến là hash partition key trước khi ánh xạ nó vào một shard.
Một hàm hash tốt nhận dữ liệu lệch và phân tán nó đồng đều. Giả sử bạn có một hàm hash 32-bit nhận một chuỗi. Bất cứ khi nào bạn cung cấp cho nó một chuỗi mới, nó trả về một số ngẫu nhiên có vẻ ngẫu nhiên giữa 0 và 2^32 - 1. Ngay cả khi các chuỗi đầu vào rất giống nhau, các hash của chúng được phân tán đều qua phạm vi số đó (nhưng cùng một đầu vào luôn tạo ra cùng một đầu ra).
Đối với mục đích sharding, hàm hash không cần phải đủ mạnh về mặt mật mã: ví dụ, MongoDB sử dụng MD5, trong khi Cassandra và ScyllaDB sử dụng Murmur3. Nhiều ngôn ngữ lập trình có các hàm hash đơn giản tích hợp sẵn (vì chúng được sử dụng cho hash table), nhưng chúng có thể không phù hợp cho sharding: ví dụ, trong Object.hashCode() của Java và Object#hash của Ruby, cùng một key có thể có giá trị hash khác nhau trong các tiến trình khác nhau, làm cho chúng không phù hợp cho sharding 16.
Hash modulo số lượng nút
Sau khi bạn đã hash key, làm thế nào để chọn shard để lưu nó? Có thể suy nghĩ đầu tiên của bạn là lấy giá trị hash modulo số nút trong hệ thống (sử dụng toán tử % trong nhiều ngôn ngữ lập trình). Ví dụ, hash(key) % 10 sẽ trả về một số từ 0 đến 9 (nếu chúng ta viết hash dưới dạng số thập phân, hash % 10 sẽ là chữ số cuối cùng).
Nếu chúng ta có 10 nút, đánh số từ 0 đến 9, đó có vẻ là một cách dễ dàng để gán mỗi key cho một nút.
Vấn đề với cách tiếp cận mod N là nếu số nút N thay đổi, hầu hết các key phải được di chuyển từ nút này sang nút khác. Hình 7-3 cho thấy điều gì xảy ra khi bạn có ba nút và thêm một nút thứ tư. Trước khi rebalancing, nút 0 lưu các key có hash là 0, 3, 6, 9, v.v. Sau khi thêm nút thứ tư, key có hash 3 đã được di chuyển đến nút 3, key có hash 6 đã được di chuyển đến nút 2, key có hash 9 đã được di chuyển đến nút 1, v.v.
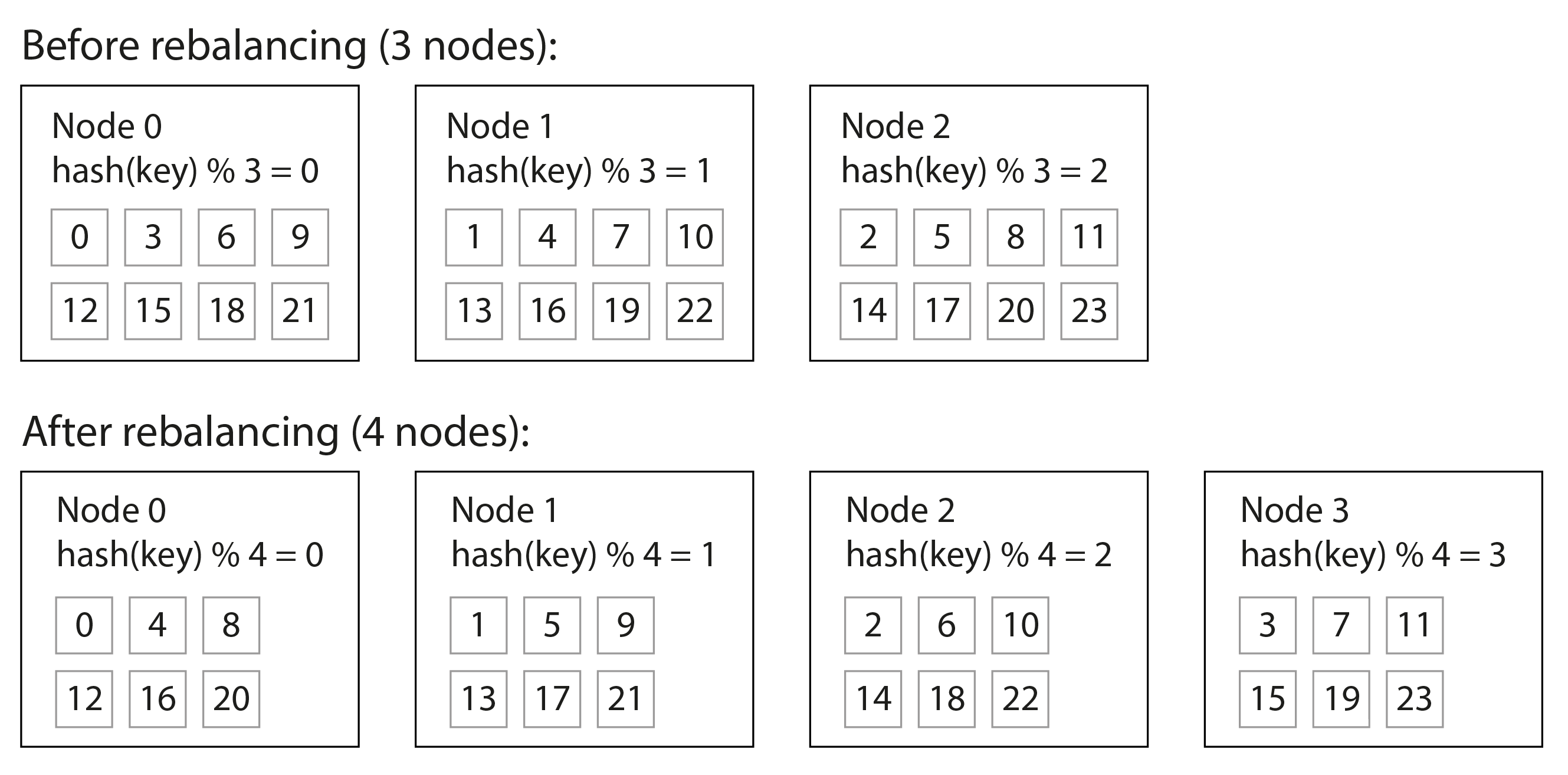
Hàm mod N dễ tính toán, nhưng nó dẫn đến rebalancing rất kém hiệu quả vì có rất nhiều di chuyển không cần thiết của bản ghi từ nút này sang nút khác. Chúng ta cần một cách tiếp cận không di chuyển dữ liệu nhiều hơn mức cần thiết.
Số lượng shard cố định
Một giải pháp đơn giản nhưng được sử dụng rộng rãi là tạo nhiều shard hơn số nút, và gán nhiều shard cho mỗi nút. Ví dụ, một cơ sở dữ liệu chạy trên một cluster gồm 10 nút có thể được chia thành 1.000 shard ngay từ đầu để 100 shard được gán cho mỗi nút. Một key sau đó được lưu trong shard số hash(key) % 1.000, và hệ thống riêng biệt theo dõi shard nào được lưu trên nút nào.
Bây giờ, nếu một nút được thêm vào cluster, hệ thống có thể gán lại một số shard từ các nút hiện có cho nút mới cho đến khi chúng được phân tán công bằng trở lại. Quá trình này được minh họa trong Hình 7-4. Nếu một nút bị xóa khỏi cluster, điều tương tự xảy ra theo chiều ngược lại.
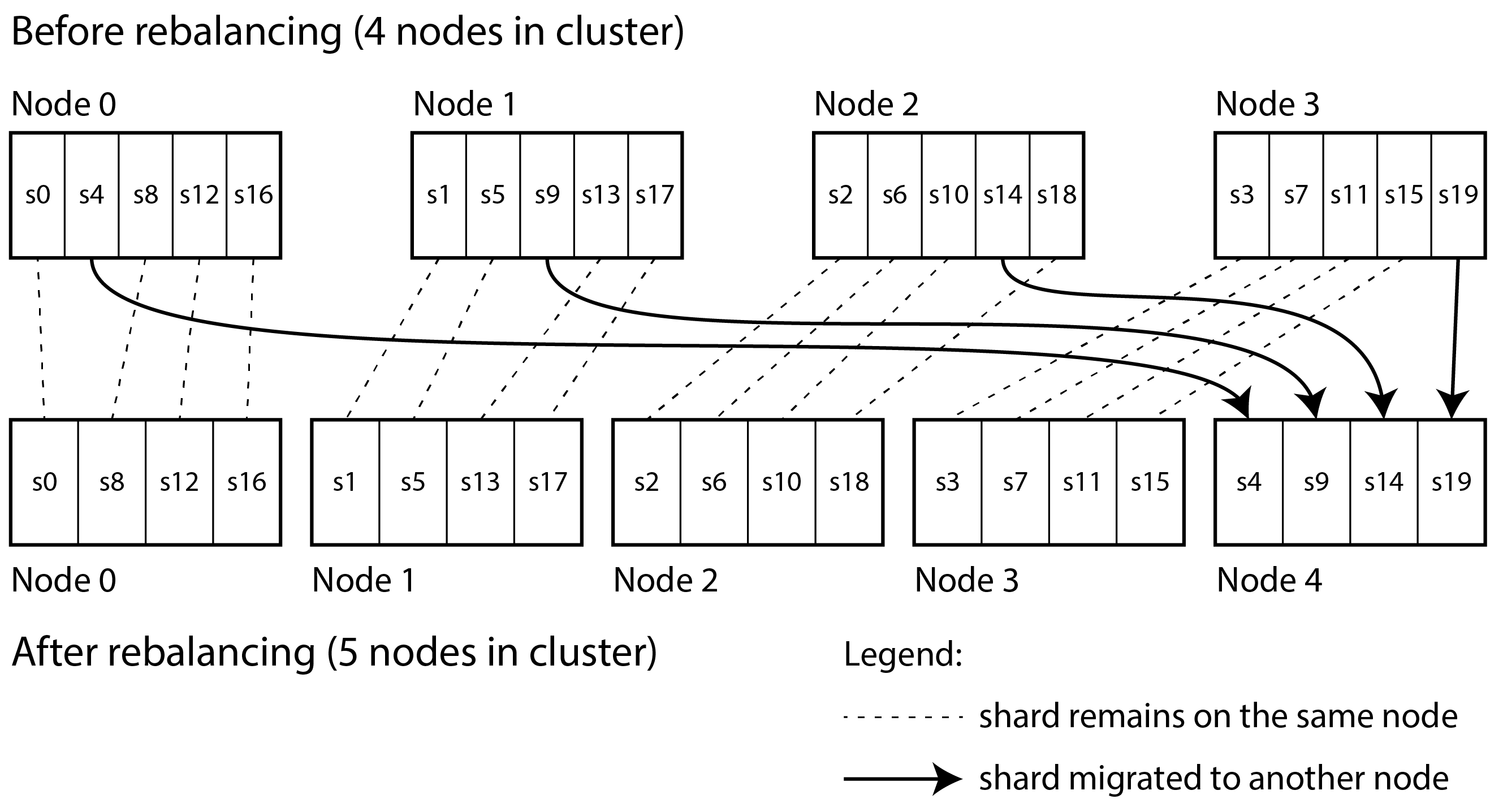
Trong mô hình này, chỉ các shard nguyên vẹn được di chuyển giữa các nút, điều này rẻ hơn so với việc chia shard. Số lượng shard không thay đổi, cũng như việc gán key cho shard. Thứ duy nhất thay đổi là việc gán shard cho nút. Sự thay đổi gán này không diễn ra ngay lập tức - mất một thời gian để truyền một lượng lớn dữ liệu qua mạng - vì vậy việc gán shard cũ được sử dụng cho bất kỳ thao tác đọc và ghi nào xảy ra trong khi quá trình truyền đang diễn ra.
Người ta thường chọn số lượng shard là một số chia hết cho nhiều thừa số, để tập dữ liệu có thể được chia đồng đều qua các số lượng nút khác nhau - không yêu cầu số lượng nút phải là lũy thừa của 2, chẳng hạn 4. Bạn thậm chí có thể tính đến phần cứng không đồng nhất trong cluster của mình: bằng cách gán nhiều shard hơn cho các nút mạnh hơn, bạn có thể làm cho các nút đó đảm nhận phần tải lớn hơn.
Cách tiếp cận sharding này được sử dụng trong Citus (một lớp sharding cho PostgreSQL), Riak, Elasticsearch, và Couchbase, trong số các hệ thống khác. Nó hoạt động tốt miễn là bạn có ước tính tốt về số lượng shard bạn sẽ cần khi lần đầu tạo cơ sở dữ liệu. Sau đó bạn có thể dễ dàng thêm hoặc xóa nút, với hạn chế là bạn không thể có nhiều nút hơn số shard bạn có.
Nếu bạn thấy số lượng shard được cấu hình ban đầu là không đúng - ví dụ, nếu bạn đã đạt đến quy mô cần nhiều nút hơn số shard bạn có - thì một thao tác resharding tốn kém là cần thiết. Nó cần chia mỗi shard và ghi ra các tệp mới, sử dụng nhiều dung lượng đĩa bổ sung trong quá trình này. Một số hệ thống không cho phép resharding trong khi đồng thời ghi vào cơ sở dữ liệu, điều này khiến việc thay đổi số lượng shard mà không có downtime trở nên khó khăn.
Việc chọn đúng số lượng shard sẽ khó khăn nếu tổng kích thước của tập dữ liệu thay đổi nhiều (ví dụ, nếu nó bắt đầu nhỏ nhưng có thể phát triển lớn hơn nhiều theo thời gian). Vì mỗi shard chứa một phần cố định của tổng dữ liệu, kích thước của mỗi shard tăng tỷ lệ thuận với tổng lượng dữ liệu trong cluster. Nếu các shard rất lớn, việc rebalancing và phục hồi từ lỗi nút trở nên tốn kém. Nhưng nếu các shard quá nhỏ, chúng phát sinh quá nhiều overhead. Hiệu suất tốt nhất đạt được khi kích thước shard “vừa phải”, không quá lớn cũng không quá nhỏ, điều này có thể khó đạt được nếu số lượng shard cố định nhưng kích thước tập dữ liệu thay đổi.
Sharding theo hash range
Nếu số lượng shard cần thiết không thể dự đoán trước, tốt hơn là sử dụng một sơ đồ trong đó số lượng shard có thể dễ dàng thích ứng với khối lượng công việc. Sơ đồ key-range sharding đã đề cập có tính chất này, nhưng nó có rủi ro hot spot khi có nhiều thao tác ghi vào các key gần nhau. Một giải pháp là kết hợp key-range sharding với một hàm hash để mỗi shard chứa một phạm vi giá trị hash thay vì một phạm vi key.
Hình 7-5 cho thấy một ví dụ sử dụng hàm hash 16-bit trả về một số từ 0 đến 65.535 = 2^16 - 1 (trong thực tế, hash thường là 32 bit hoặc nhiều hơn). Ngay cả khi các key đầu vào rất giống nhau (ví dụ, các timestamp liên tiếp), các hash của chúng được phân tán đồng đều qua phạm vi đó. Chúng ta có thể gán một phạm vi giá trị hash cho mỗi shard: ví dụ, các giá trị từ 0 đến 16.383 cho shard 0, các giá trị từ 16.384 đến 32.767 cho shard 1, v.v.
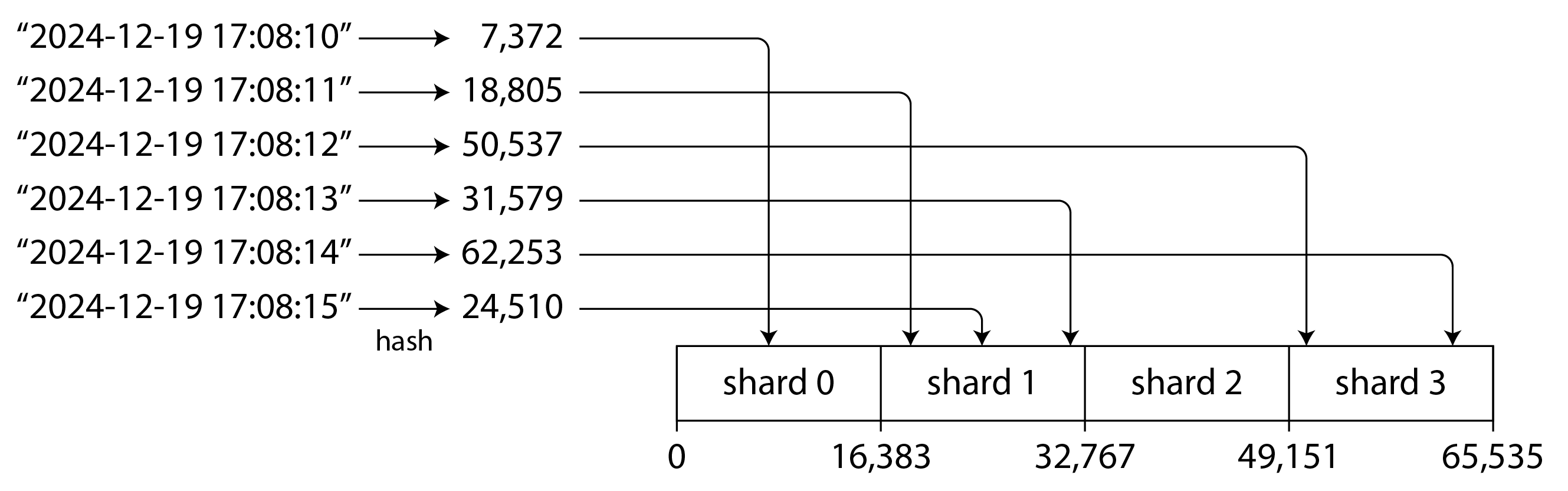
Giống như với key-range sharding, một shard trong hash-range sharding có thể được chia khi nó trở nên quá lớn hoặc chịu tải quá cao. Đây vẫn là một thao tác tốn kém, nhưng nó có thể xảy ra khi cần thiết, vì vậy số lượng shard thích ứng với khối lượng dữ liệu thay vì được cố định trước.
Nhược điểm so với key-range sharding là các range query trên partition key không hiệu quả, vì các key trong phạm vi đó giờ đây bị phân tán qua tất cả các shard. Tuy nhiên, nếu các key bao gồm hai hoặc nhiều cột, và partition key chỉ là cột đầu tiên trong số đó, bạn vẫn có thể thực hiện các range query hiệu quả trên cột thứ hai và các cột sau: miễn là tất cả các bản ghi trong range query có cùng partition key, chúng sẽ ở trong cùng một shard.
PARTITIONING VÀ RANGE QUERY TRONG DATA WAREHOUSE
Các data warehouse như BigQuery, Snowflake, và Delta Lake hỗ trợ một cách tiếp cận lập chỉ mục tương tự, mặc dù thuật ngữ khác nhau. Trong BigQuery, ví dụ, partition key xác định bản ghi nằm trong partition nào trong khi “cluster columns” xác định cách các bản ghi được sắp xếp trong partition. Snowflake tự động gán các bản ghi vào “micro-partition”, nhưng cho phép người dùng định nghĩa cluster key cho một bảng. Delta Lake hỗ trợ cả phân chia partition thủ công và tự động, và hỗ trợ cluster key. Việc phân cụm dữ liệu không chỉ cải thiện hiệu suất range scan, mà còn có thể cải thiện hiệu suất nén và lọc.
Hash-range sharding được sử dụng trong YugabyteDB và DynamoDB 17, và là một tùy chọn trong MongoDB. Cassandra và ScyllaDB sử dụng một biến thể của cách tiếp cận này được minh họa trong Hình 7-6: không gian giá trị hash được chia thành một số phạm vi tỷ lệ với số nút (3 phạm vi mỗi nút trong Hình 7-6, nhưng số thực tế là 8 mỗi nút trong Cassandra theo mặc định, và 256 mỗi nút trong ScyllaDB), với các ranh giới ngẫu nhiên giữa các phạm vi đó. Điều này có nghĩa là một số phạm vi lớn hơn các phạm vi khác, nhưng bằng cách có nhiều phạm vi trên mỗi nút, những mất cân bằng đó có xu hướng cân bằng nhau 15 18.
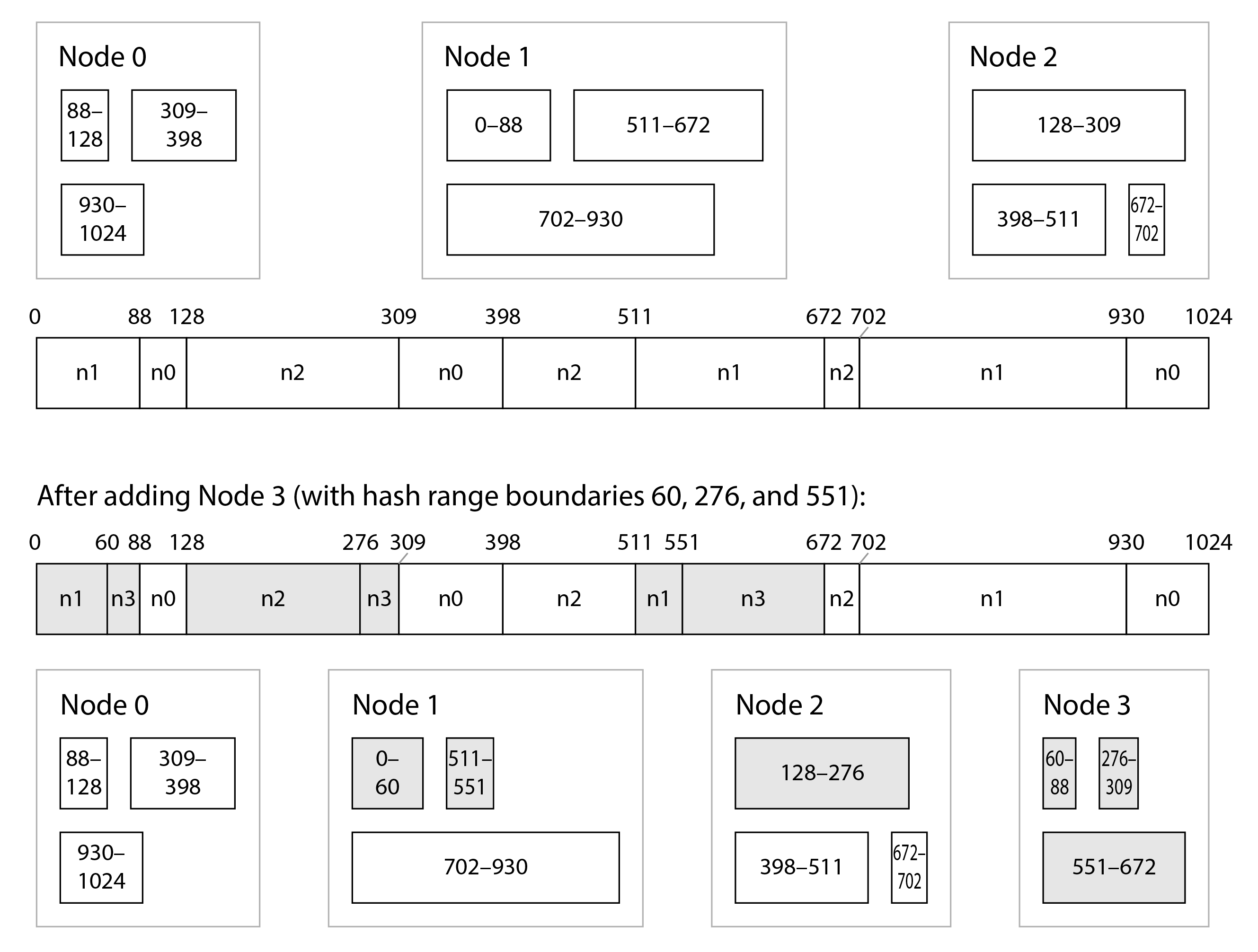
Khi các nút được thêm vào hoặc xóa đi, các ranh giới phạm vi được thêm vào và xóa đi, và các shard được chia hoặc hợp nhất tương ứng 19. Trong ví dụ của Hình 7-6, khi nút 3 được thêm vào, nút 1 chuyển một phần của hai phạm vi của nó sang nút 3, và nút 2 chuyển một phần của một phạm vi của nó sang nút 3. Điều này có tác dụng cấp cho nút mới một phần xấp xỉ công bằng của tập dữ liệu, mà không truyền nhiều dữ liệu hơn mức cần thiết từ nút này sang nút khác.
Consistent hashing
Một thuật toán consistent hashing là một hàm hash ánh xạ các key đến một số lượng shard được chỉ định theo cách thỏa mãn hai tính chất:
- số lượng key được ánh xạ đến mỗi shard là xấp xỉ bằng nhau, và
- khi số lượng shard thay đổi, càng ít key càng tốt được di chuyển từ shard này sang shard khác.
Lưu ý rằng consistent ở đây không liên quan gì đến replica consistency (xem Chương 6) hay ACID consistency (xem Chương 8), mà mô tả xu hướng của một key ở lại trong cùng một shard càng nhiều càng tốt.
Thuật toán sharding được sử dụng bởi Cassandra và ScyllaDB tương tự như định nghĩa gốc của consistent hashing 20, nhưng một số thuật toán consistent hashing khác cũng đã được đề xuất 21, chẳng hạn như highest random weight, còn được gọi là rendezvous hashing 22, và jump consistent hash 23. Với thuật toán của Cassandra, nếu một nút được thêm vào, một số shard hiện có ít được chia thành các phạm vi con; mặt khác, với rendezvous và jump consistent hash, nút mới được gán các key riêng lẻ mà trước đây được phân tán qua tất cả các nút khác. Loại nào được ưu tiên phụ thuộc vào ứng dụng.
Khối Lượng Công Việc Lệch và Giải Quyết Hot Spot
Consistent hashing đảm bảo các key được phân tán đồng đều qua các nút, nhưng điều đó không có nghĩa là tải thực tế được phân tán đồng đều. Nếu khối lượng công việc bị lệch nhiều - tức là lượng dữ liệu dưới một số partition key lớn hơn nhiều so với các key khác, hoặc nếu tốc độ yêu cầu đến một số key cao hơn nhiều so với các key khác - bạn vẫn có thể gặp tình trạng một số máy chủ bị quá tải trong khi các máy chủ khác gần như nhàn rỗi.
Ví dụ, trên một trang mạng xã hội, một người dùng nổi tiếng với hàng triệu người theo dõi có thể gây ra một cơn bão hoạt động khi họ làm gì đó 24. Sự kiện này có thể dẫn đến một khối lượng lớn đọc và ghi vào cùng một key (trong đó partition key có thể là user ID của người nổi tiếng, hoặc ID của hành động mà mọi người đang bình luận).
Trong những tình huống như vậy, cần có một chính sách sharding linh hoạt hơn 25 26. Một hệ thống định nghĩa shard dựa trên phạm vi key (hoặc phạm vi hash) giúp có thể đặt một hot key riêng lẻ trong một shard của riêng nó, và thậm chí có thể gán nó một máy chuyên dụng 27.
Cũng có thể bù đắp cho sự lệch ở cấp độ ứng dụng. Ví dụ, nếu một key được biết là rất hot, một kỹ thuật đơn giản là thêm một số ngẫu nhiên vào đầu hoặc cuối key. Chỉ cần một số ngẫu nhiên hai chữ số thập phân sẽ chia đều các thao tác ghi vào key qua 100 key khác nhau, cho phép các key đó được phân tán đến các shard khác nhau.
Tuy nhiên, sau khi chia các thao tác ghi qua các key khác nhau, bất kỳ thao tác đọc nào giờ đây phải thực hiện công việc bổ sung, vì chúng phải đọc dữ liệu từ tất cả 100 key và kết hợp chúng. Khối lượng đọc đến mỗi shard của hot key không giảm; chỉ có tải ghi được chia. Kỹ thuật này cũng đòi hỏi thêm bookkeeping: nó chỉ có ý nghĩa khi thêm số ngẫu nhiên cho số lượng nhỏ các hot key; đối với phần lớn các key có thông lượng ghi thấp, đây sẽ là overhead không cần thiết. Do đó, bạn cũng cần một cách nào đó để theo dõi những key nào đang được chia, và một quy trình để chuyển đổi một key thông thường thành hot key được quản lý đặc biệt.
Vấn đề càng phức tạp hơn bởi sự thay đổi tải theo thời gian: ví dụ, một bài đăng mạng xã hội cụ thể đã viral có thể trải qua tải cao trong vài ngày, nhưng sau đó có thể sẽ lắng xuống. Hơn nữa, một số key có thể hot cho việc ghi trong khi các key khác hot cho việc đọc, đòi hỏi các chiến lược khác nhau để xử lý chúng.
Một số hệ thống (đặc biệt là các dịch vụ đám mây được thiết kế cho quy mô lớn) có các cách tiếp cận tự động để xử lý hot shard; ví dụ, Amazon gọi nó là heat management 28 hoặc adaptive capacity 17. Chi tiết về cách hoạt động của các hệ thống này nằm ngoài phạm vi của cuốn sách này.
Thao Tác: Rebalancing Tự Động hay Thủ Công
Có một câu hỏi quan trọng liên quan đến rebalancing mà chúng ta đã bỏ qua: việc chia shard và rebalancing có xảy ra tự động hay thủ công?
Một số hệ thống tự động quyết định khi nào cần chia shard và khi nào cần di chuyển chúng từ nút này sang nút khác, mà không cần bất kỳ tương tác nào của con người, trong khi các hệ thống khác để sharding được cấu hình rõ ràng bởi quản trị viên. Cũng có một điểm trung gian: ví dụ, Couchbase và Riak tự động tạo ra gợi ý phân công shard, nhưng yêu cầu quản trị viên xác nhận trước khi nó có hiệu lực.
Rebalancing hoàn toàn tự động có thể thuận tiện, vì có ít công việc vận hành hơn cho việc bảo trì thông thường, và các hệ thống như vậy thậm chí có thể tự động mở rộng để thích ứng với các thay đổi trong khối lượng công việc. Các cơ sở dữ liệu đám mây như DynamoDB được quảng bá là có khả năng tự động thêm và xóa shard để thích ứng với sự tăng hoặc giảm lớn của tải trong vài phút 17 29.
Tuy nhiên, quản lý shard tự động cũng có thể khó đoán. Rebalancing là một thao tác tốn kém, vì nó đòi hỏi định tuyến lại các yêu cầu và di chuyển một lượng lớn dữ liệu từ nút này sang nút khác. Nếu không được thực hiện cẩn thận, quá trình này có thể làm quá tải mạng hoặc các nút, và có thể gây hại cho hiệu suất của các yêu cầu khác. Hệ thống phải tiếp tục xử lý các thao tác ghi trong khi rebalancing đang diễn ra; nếu một hệ thống gần đến thông lượng ghi tối đa của nó, quá trình chia shard thậm chí có thể không theo kịp tốc độ của các thao tác ghi đến 29.
Tự động hóa như vậy có thể nguy hiểm khi kết hợp với phát hiện lỗi tự động. Ví dụ, giả sử một nút bị quá tải và tạm thời chậm phản hồi các yêu cầu. Các nút khác kết luận rằng nút bị quá tải đã chết, và tự động rebalance cluster để di chuyển tải ra khỏi nó. Điều này đặt thêm tải lên các nút khác và mạng, làm cho tình hình tồi tệ hơn. Có rủi ro gây ra lỗi theo dây chuyền nơi các nút khác bị quá tải và cũng bị nghi ngờ giả mạo là đã chết.
Vì lý do đó, việc có một con người trong vòng lặp để rebalancing có thể là điều tốt. Nó chậm hơn so với một quy trình hoàn toàn tự động, nhưng nó có thể giúp ngăn ngừa các bất ngờ trong vận hành.
Định Tuyến Yêu Cầu
Chúng ta đã thảo luận về cách shard một tập dữ liệu qua nhiều nút, và cách rebalance các shard đó khi các nút được thêm vào hoặc xóa đi. Bây giờ hãy chuyển sang câu hỏi: nếu bạn muốn đọc hoặc ghi một key cụ thể, làm thế nào bạn biết nút nào - tức là địa chỉ IP và số cổng nào - bạn cần kết nối đến?
Chúng ta gọi vấn đề này là request routing (định tuyến yêu cầu), và nó rất giống với service discovery (khám phá dịch vụ), mà chúng ta đã thảo luận trước đây trong “Load balancers, service discovery, and service meshes”. Sự khác biệt lớn nhất giữa hai vấn đề này là với các dịch vụ chạy code ứng dụng, mỗi instance thường không có trạng thái, và một load balancer có thể gửi yêu cầu đến bất kỳ instance nào. Với các cơ sở dữ liệu được shard, một yêu cầu cho một key chỉ có thể được xử lý bởi một nút là replica cho shard chứa key đó.
Điều này có nghĩa là request routing phải biết về việc gán từ key đến shard, và từ shard đến nút. Ở cấp độ cao, có một số cách tiếp cận khác nhau cho vấn đề này (được minh họa trong Hình 7-7):
- Cho phép client liên hệ với bất kỳ nút nào (ví dụ, qua một round-robin load balancer). Nếu nút đó tình cờ sở hữu shard mà yêu cầu áp dụng, nó có thể xử lý yêu cầu trực tiếp; nếu không, nó chuyển tiếp yêu cầu đến nút thích hợp, nhận phản hồi, và chuyển phản hồi đó cho client.
- Gửi tất cả yêu cầu từ client đến một routing tier trước, routing tier này xác định nút nào cần xử lý mỗi yêu cầu và chuyển tiếp yêu cầu đó. Routing tier này không tự xử lý bất kỳ yêu cầu nào; nó chỉ hoạt động như một shard-aware load balancer.
- Yêu cầu client phải biết về sharding và việc gán shard cho nút. Trong trường hợp này, client có thể kết nối trực tiếp đến nút thích hợp, mà không cần bất kỳ trung gian nào.
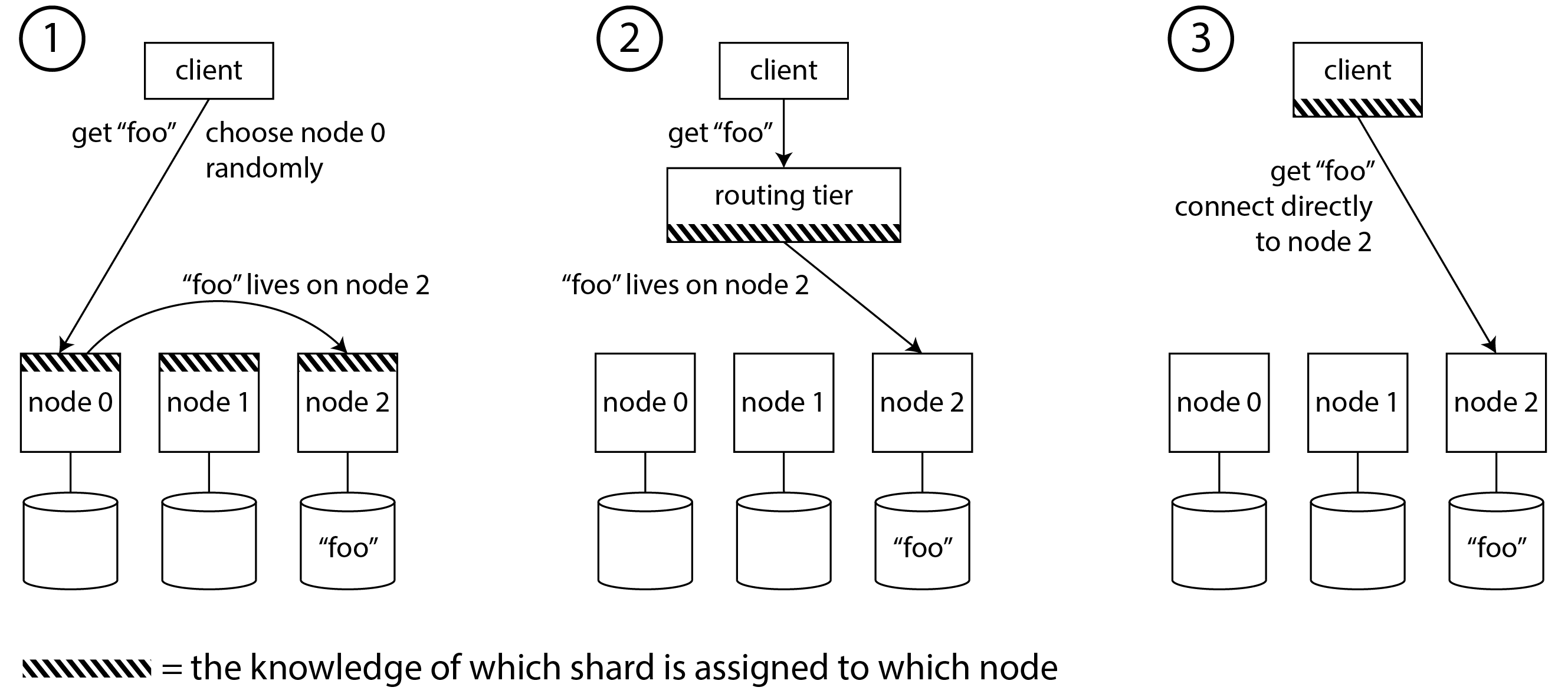
Trong tất cả các trường hợp, có một số vấn đề chính:
- Ai quyết định shard nào nên sống trên nút nào? Đơn giản nhất là có một coordinator đơn lẻ đưa ra quyết định đó, nhưng trong trường hợp đó làm thế nào để bạn làm cho nó chịu lỗi trong trường hợp nút chạy coordinator bị hỏng? Và nếu vai trò coordinator có thể failover sang nút khác, làm thế nào để bạn ngăn chặn tình huống split-brain (xem “Handling Node Outages”) trong đó hai coordinator khác nhau đưa ra các phân công shard mâu thuẫn nhau?
- Làm thế nào để thành phần thực hiện định tuyến (có thể là một trong các nút, hoặc routing tier, hoặc client) biết về các thay đổi trong việc gán shard cho nút?
- Trong khi một shard đang được di chuyển từ nút này sang nút khác, có một khoảng thời gian chuyển đổi trong đó nút mới đã tiếp quản, nhưng các yêu cầu đến nút cũ vẫn đang trên đường. Bạn xử lý chúng như thế nào?
Nhiều hệ thống dữ liệu phân tán dựa vào một dịch vụ điều phối riêng biệt như ZooKeeper hoặc etcd để theo dõi các phân công shard, như minh họa trong Hình 7-8. Chúng sử dụng các thuật toán consensus (xem Chương 10) để cung cấp khả năng chịu lỗi và bảo vệ khỏi split-brain. Mỗi nút đăng ký chính nó trong ZooKeeper, và ZooKeeper duy trì ánh xạ có thẩm quyền của shard đến nút. Các tác nhân khác, chẳng hạn như routing tier hoặc client nhận biết sharding, có thể đăng ký nhận thông tin này trong ZooKeeper. Bất cứ khi nào một shard thay đổi chủ sở hữu, hoặc một nút được thêm vào hoặc xóa đi, ZooKeeper thông báo cho routing tier để nó có thể cập nhật thông tin định tuyến của mình.
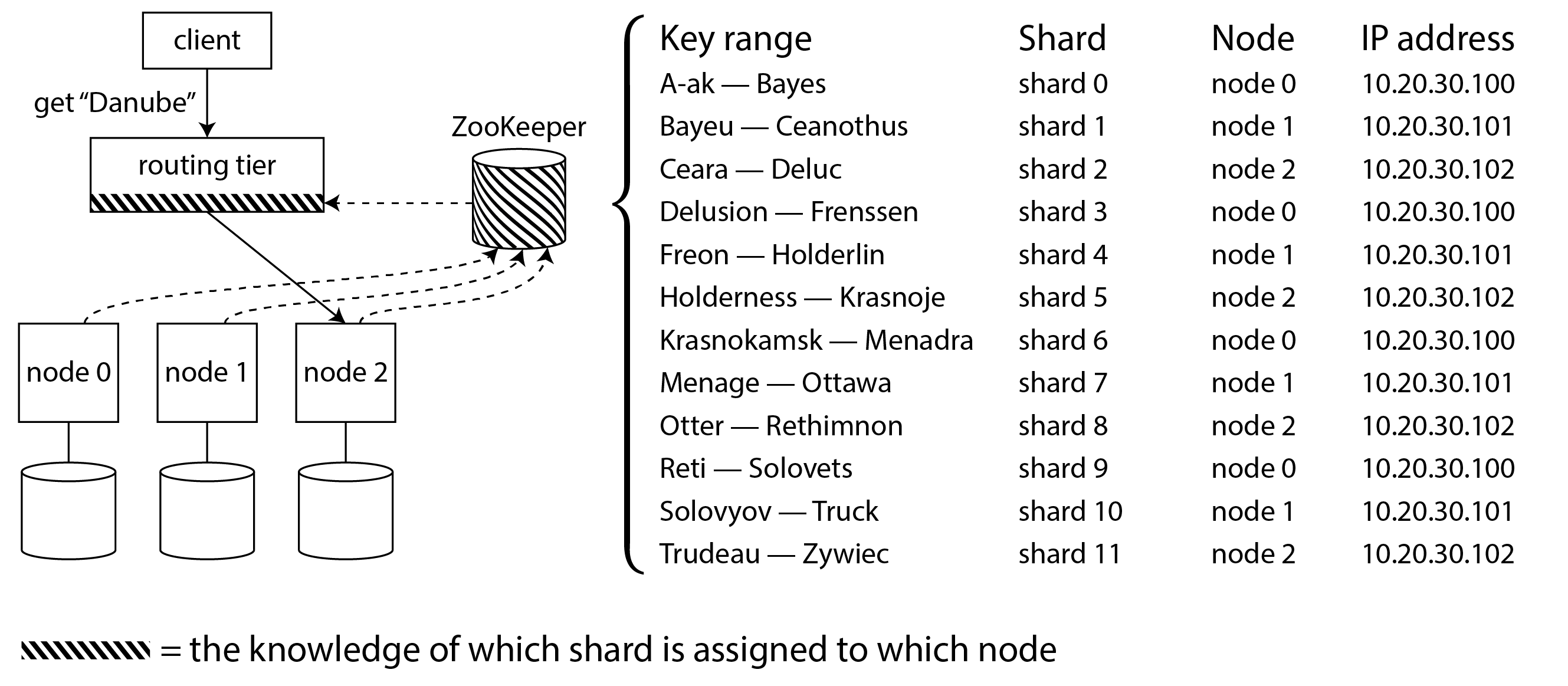
Ví dụ, HBase và SolrCloud sử dụng ZooKeeper để quản lý phân công shard, và Kubernetes sử dụng etcd để theo dõi instance dịch vụ nào đang chạy ở đâu. MongoDB có kiến trúc tương tự, nhưng nó dựa vào triển khai config server riêng và các daemon mongos làm routing tier. Kafka, YugabyteDB, và TiDB sử dụng triển khai tích hợp của giao thức đồng thuận Raft để thực hiện chức năng điều phối này.
Cassandra, ScyllaDB, và Riak có cách tiếp cận khác: họ sử dụng gossip protocol giữa các nút để phổ biến bất kỳ thay đổi nào trong trạng thái cluster. Điều này cung cấp tính nhất quán yếu hơn nhiều so với giao thức consensus; có thể có split brain, trong đó các phần khác nhau của cluster có các phân công nút khác nhau cho cùng một shard. Các cơ sở dữ liệu không có leader có thể chịu đựng điều này vì chúng thường đưa ra các bảo đảm nhất quán yếu (xem “Limitations of Quorum Consistency”).
Khi sử dụng routing tier hoặc khi gửi yêu cầu đến một nút ngẫu nhiên, client vẫn cần tìm địa chỉ IP để kết nối. Các địa chỉ này không thay đổi nhanh như việc gán shard cho nút, do đó thường đủ để sử dụng DNS cho mục đích này.
Cuộc thảo luận về request routing này đã tập trung vào việc tìm shard cho một key riêng lẻ, điều này phù hợp nhất với các cơ sở dữ liệu OLTP được shard. Các cơ sở dữ liệu phân tích thường cũng sử dụng sharding, nhưng chúng thường có loại thực thi truy vấn rất khác nhau: thay vì thực thi trong một shard duy nhất, một truy vấn thường cần tổng hợp và join dữ liệu từ nhiều shard khác nhau song song. Chúng ta sẽ thảo luận các kỹ thuật để thực thi truy vấn song song như vậy trong “JOIN and GROUP BY”.
Sharding và Secondary Indexes
Các sơ đồ sharding mà chúng ta đã thảo luận cho đến nay dựa vào việc client biết partition key cho bất kỳ bản ghi nào nó muốn truy cập. Điều này dễ thực hiện nhất trong mô hình dữ liệu key-value, trong đó partition key là phần đầu tiên của primary key (hoặc toàn bộ primary key), và do đó chúng ta có thể sử dụng partition key để xác định shard, và từ đó định tuyến đọc và ghi đến nút chịu trách nhiệm cho key đó.
Tình huống trở nên phức tạp hơn nếu có secondary index (xem thêm “Multi-Column and Secondary Indexes”). Một secondary index thường không xác định duy nhất một bản ghi mà là một cách tìm kiếm các lần xuất hiện của một giá trị cụ thể: tìm tất cả hành động của người dùng 123, tìm tất cả bài viết chứa từ hogwash, tìm tất cả xe có màu red, v.v.
Các key-value store thường không có secondary index, nhưng chúng là thứ cơ bản của các cơ sở dữ liệu quan hệ, chúng cũng phổ biến trong các cơ sở dữ liệu tài liệu, và chúng là raison d’être của các search engine toàn văn như Solr và Elasticsearch. Vấn đề với secondary index là chúng không ánh xạ gọn gàng đến các shard. Có hai cách tiếp cận chính để shard một cơ sở dữ liệu với secondary index: local index và global index.
Local Secondary Indexes
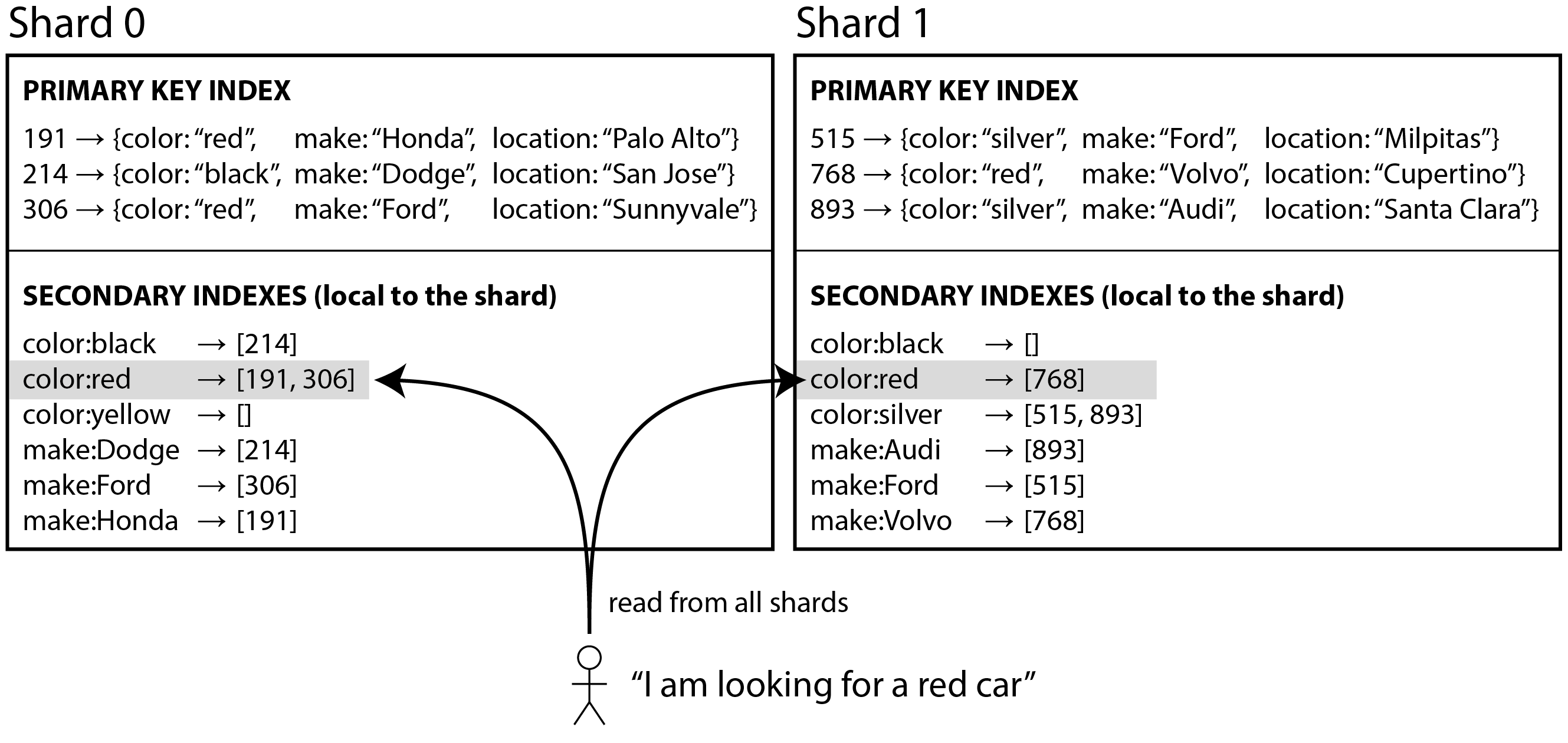
Ví dụ, tưởng tượng bạn đang vận hành một trang web bán xe đã qua sử dụng (được minh họa trong Hình 7-9). Mỗi danh sách có một ID duy nhất, và bạn sử dụng ID đó làm partition key cho sharding (ví dụ, ID từ 0 đến 499 trong shard 0, ID từ 500 đến 999 trong shard 1, v.v.).
Nếu bạn muốn cho phép người dùng tìm kiếm xe, cho phép họ lọc theo màu và theo hãng, bạn cần một secondary index trên color và make (trong cơ sở dữ liệu tài liệu đây sẽ là các trường; trong cơ sở dữ liệu quan hệ chúng sẽ là các cột). Nếu bạn đã khai báo index, cơ sở dữ liệu có thể thực hiện việc lập chỉ mục tự động. Ví dụ, bất cứ khi nào một chiếc xe màu đỏ được thêm vào cơ sở dữ liệu, shard cơ sở dữ liệu tự động thêm ID của nó vào danh sách ID cho mục nhập index color:red. Như đã thảo luận trong Chương 4, danh sách ID đó còn được gọi là postings list.
CẢNH BÁO
Nếu cơ sở dữ liệu của bạn chỉ hỗ trợ mô hình key-value, bạn có thể bị cám dỗ tự triển khai secondary index bằng cách tạo ánh xạ từ giá trị đến ID trong code ứng dụng. Nếu bạn đi theo hướng này, bạn cần hết sức cẩn thận để đảm bảo các index của bạn vẫn nhất quán với dữ liệu cơ bản. Các race condition và lỗi ghi gián đoạn (nơi một số thay đổi được lưu nhưng các thay đổi khác thì không) có thể rất dễ dàng khiến dữ liệu bị mất đồng bộ - xem “The need for multi-object transactions”.
Trong cách tiếp cận lập chỉ mục này, mỗi shard hoàn toàn tách biệt: mỗi shard duy trì secondary index riêng của nó, chỉ bao gồm các bản ghi trong shard đó. Nó không quan tâm đến dữ liệu được lưu trong các shard khác. Bất cứ khi nào bạn ghi vào cơ sở dữ liệu - để thêm, xóa, hoặc cập nhật bản ghi - bạn chỉ cần xử lý shard chứa bản ghi mà bạn đang ghi. Vì lý do đó, loại secondary index này được gọi là local index. Trong ngữ cảnh information retrieval nó còn được gọi là document-partitioned index 30.
Khi đọc từ local secondary index, nếu bạn đã biết partition key của bản ghi bạn đang tìm, bạn chỉ cần thực hiện tìm kiếm trên shard thích hợp. Hơn nữa, nếu bạn chỉ muốn một số kết quả, và không cần tất cả, bạn có thể gửi yêu cầu đến bất kỳ shard nào.
Tuy nhiên, nếu bạn muốn tất cả kết quả và không biết partition key của chúng trước, bạn cần gửi truy vấn đến tất cả các shard, và kết hợp các kết quả bạn nhận được, vì các bản ghi khớp có thể bị phân tán qua tất cả các shard. Trong Hình 7-9, xe màu đỏ xuất hiện ở cả shard 0 và shard 1.
Cách tiếp cận này để truy vấn một cơ sở dữ liệu được shard có thể làm cho các truy vấn đọc trên secondary index khá tốn kém. Ngay cả khi bạn truy vấn các shard song song, nó dễ bị khuếch đại tail latency (xem “Use of Response Time Metrics”). Nó cũng giới hạn khả năng mở rộng của ứng dụng: thêm nhiều shard hơn cho phép bạn lưu trữ nhiều dữ liệu hơn, nhưng nó không tăng thông lượng truy vấn của bạn nếu mọi shard phải xử lý mọi truy vấn.
Tuy nhiên, local secondary index được sử dụng rộng rãi 31: ví dụ, MongoDB, Riak, Cassandra 32, Elasticsearch 33, SolrCloud, và VoltDB 34 đều sử dụng local secondary index.
Global Secondary Indexes
Thay vì mỗi shard có local secondary index riêng, chúng ta có thể xây dựng một global index bao gồm dữ liệu trong tất cả các shard. Tuy nhiên, chúng ta không thể chỉ lưu index đó trên một nút, vì nó có thể sẽ trở thành điểm nghẽn và làm hỏng mục đích của sharding. Một global index cũng phải được shard, nhưng nó có thể được shard theo cách khác với primary key index.
Hình 7-10 minh họa điều này có thể trông như thế nào: ID của các xe màu đỏ từ tất cả các shard xuất hiện dưới color:red trong index, nhưng index được shard sao cho màu bắt đầu với chữ cái a đến r xuất hiện trong shard 0 và màu bắt đầu với s đến z xuất hiện trong shard 1.
Index về hãng xe được phân vùng tương tự (với ranh giới shard giữa f và h).
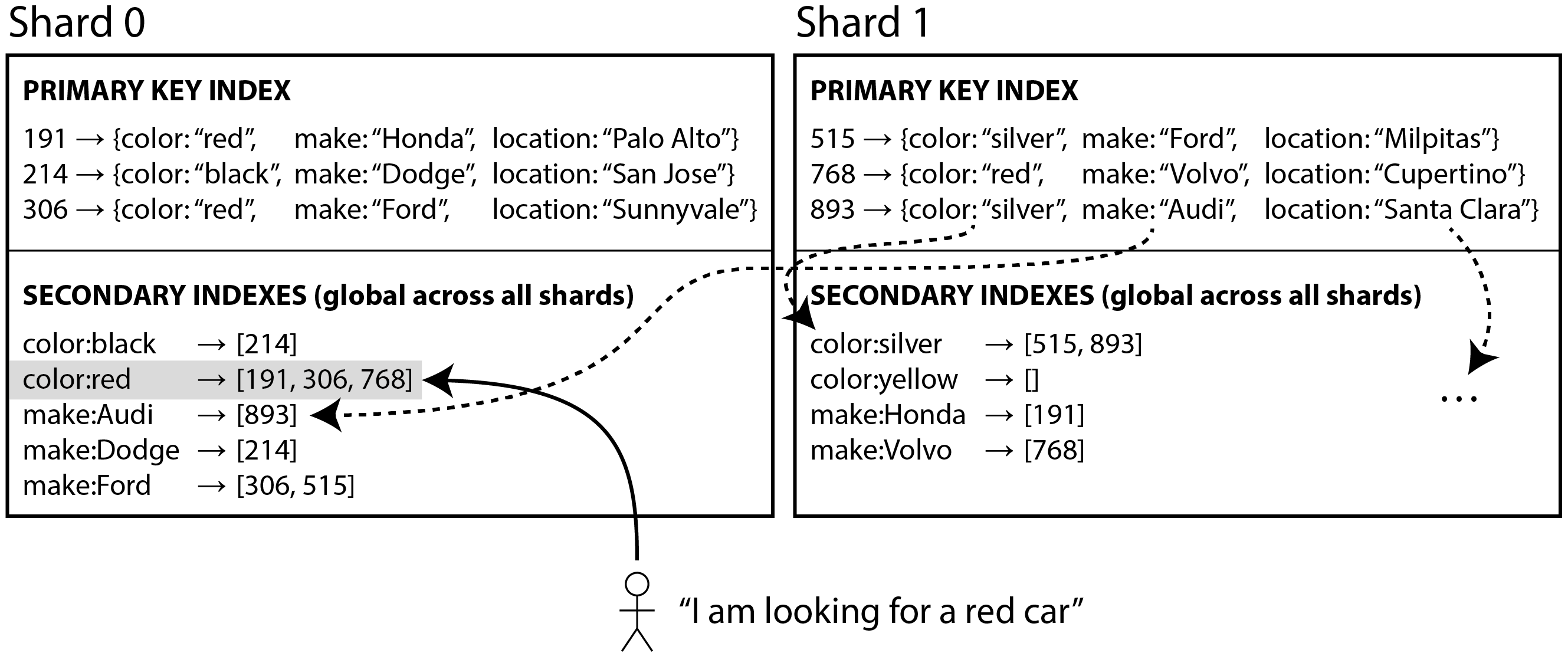
Loại index này còn được gọi là term-partitioned 30: nhớ lại từ “Full-Text Search” rằng trong full-text search, một term là một từ khóa trong văn bản mà bạn có thể tìm kiếm. Ở đây chúng ta tổng quát hóa nó để có nghĩa là bất kỳ giá trị nào mà bạn có thể tìm kiếm trong secondary index.
Global index sử dụng term làm partition key, để khi bạn tìm kiếm một term hoặc giá trị cụ thể, bạn có thể xác định shard nào bạn cần truy vấn. Như trước, một shard có thể chứa một phạm vi liên tiếp của các term (như trong Hình 7-10), hoặc bạn có thể gán các term cho shard dựa trên hash của term.
Global index có ưu điểm là một truy vấn với một điều kiện duy nhất (chẳng hạn như color = red) chỉ cần đọc từ một shard duy nhất để lấy postings list. Tuy nhiên, nếu bạn muốn lấy các bản ghi chứ không chỉ ID, bạn vẫn phải đọc từ tất cả các shard chịu trách nhiệm cho các ID đó.
Nếu bạn có nhiều điều kiện tìm kiếm hoặc term (ví dụ, tìm kiếm xe có màu nhất định và hãng nhất định, hoặc tìm kiếm nhiều từ xuất hiện trong cùng một văn bản), có thể các term đó sẽ được gán cho các shard khác nhau. Để tính AND logic của hai điều kiện, hệ thống cần tìm tất cả các ID xuất hiện trong cả hai postings list. Điều đó không phải là vấn đề nếu các postings list ngắn, nhưng nếu chúng dài, có thể chậm khi gửi chúng qua mạng để tính giao điểm 30.
Một thách thức khác với global secondary index là các thao tác ghi phức tạp hơn so với local index, vì việc ghi một bản ghi có thể ảnh hưởng đến nhiều shard của index (mỗi term trong tài liệu có thể ở một shard khác nhau). Điều này làm cho việc giữ secondary index đồng bộ với dữ liệu cơ bản khó khăn hơn. Một tùy chọn là sử dụng distributed transaction để cập nhật nguyên tử các shard lưu bản ghi chính và secondary index của nó (xem Chương 8).
Global secondary index được sử dụng bởi CockroachDB, TiDB, và YugabyteDB; DynamoDB hỗ trợ cả local và global secondary index. Trong trường hợp của DynamoDB, các thao tác ghi được phản ánh bất đồng bộ trong global index, do đó các đọc từ global index có thể bị cũ (tương tự như replication lag, như trong “Problems with Replication Lag”). Tuy nhiên, global index hữu ích nếu thông lượng đọc cao hơn thông lượng ghi, và nếu các postings list không quá dài.
Tóm Tắt
Trong chương này, chúng ta đã khám phá các cách khác nhau để shard một tập dữ liệu lớn thành các tập con nhỏ hơn. Sharding là cần thiết khi bạn có quá nhiều dữ liệu đến mức việc lưu trữ và xử lý trên một máy đơn lẻ không còn khả thi nữa.
Mục tiêu của sharding là phân tán dữ liệu và tải truy vấn đồng đều qua nhiều máy, tránh hot spot (các nút có tải không cân đối cao). Điều này đòi hỏi chọn một sơ đồ sharding phù hợp với dữ liệu của bạn, và rebalance các shard khi các nút được thêm vào hoặc xóa khỏi cluster.
Chúng ta đã thảo luận hai cách tiếp cận chính cho sharding:
- Key range sharding, trong đó các key được sắp xếp, và một shard sở hữu tất cả các key từ một giá trị tối thiểu nào đó đến một giá trị tối đa nào đó. Sắp xếp có ưu điểm là các range query hiệu quả là có thể, nhưng có rủi ro hot spot nếu ứng dụng thường xuyên truy cập các key gần nhau trong thứ tự sắp xếp.
Trong cách tiếp cận này, các shard thường được rebalance bằng cách chia phạm vi thành hai phần con khi một shard trở nên quá lớn.
- Hash sharding, trong đó một hàm hash được áp dụng cho mỗi key, và một shard sở hữu một phạm vi giá trị hash (hoặc một thuật toán consistent hashing khác có thể được sử dụng để ánh xạ hash đến shard). Phương pháp này phá hủy thứ tự của các key, làm cho range query kém hiệu quả, nhưng nó có thể phân tán tải đồng đều hơn.
Khi shard theo hash, người ta thường tạo một số lượng shard cố định trước, gán nhiều shard cho mỗi nút, và di chuyển toàn bộ shard từ nút này sang nút khác khi các nút được thêm vào hoặc xóa đi. Chia shard, như với key range, cũng có thể thực hiện.
Người ta thường sử dụng phần đầu tiên của key làm partition key (tức là để xác định shard), và sắp xếp các bản ghi trong shard đó theo phần còn lại của key. Bằng cách đó bạn vẫn có thể có các range query hiệu quả trong số các bản ghi có cùng partition key.
Chúng ta cũng đã thảo luận về sự tương tác giữa sharding và secondary index. Một secondary index cũng cần được shard, và có hai phương pháp:
- Local secondary index, trong đó secondary index được lưu trong cùng shard với primary key và giá trị. Điều này có nghĩa là chỉ một shard cần được cập nhật khi ghi, nhưng tra cứu secondary index đòi hỏi đọc từ tất cả các shard.
- Global secondary index, được shard riêng biệt dựa trên các giá trị được lập chỉ mục. Một mục trong secondary index có thể tham chiếu đến các bản ghi từ tất cả các shard của primary key. Khi một bản ghi được ghi, một số shard của secondary index có thể cần được cập nhật; tuy nhiên, một lần đọc postings list có thể được phục vụ từ một shard duy nhất (việc lấy các bản ghi thực tế vẫn đòi hỏi đọc từ nhiều shard).
Cuối cùng, chúng ta đã thảo luận các kỹ thuật để định tuyến truy vấn đến shard thích hợp, và cách một dịch vụ điều phối thường được sử dụng để theo dõi việc gán shard cho nút.
Theo thiết kế, mỗi shard hoạt động phần lớn độc lập - đó là điều cho phép một cơ sở dữ liệu được shard có thể mở rộng lên nhiều máy. Tuy nhiên, các thao tác cần ghi vào nhiều shard có thể gây ra vấn đề: ví dụ, điều gì xảy ra nếu việc ghi vào một shard thành công, nhưng shard khác thất bại? Chúng ta sẽ giải quyết câu hỏi đó trong các chương tiếp theo.
Tài liệu tham khảo
Claire Giordano. Understanding partitioning and sharding in Postgres and Citus. citusdata.com, August 2023. Archived at perma.cc/8BTK-8959 ↩︎
Brandur Leach. Partitioning in Postgres, 2022 edition. brandur.org, October 2022. Archived at perma.cc/Z5LE-6AKX ↩︎
Raph Koster. Database “sharding” came from UO? raphkoster.com, January 2009. Archived at perma.cc/4N9U-5KYF ↩︎
Garrett Fidalgo. Herding elephants: Lessons learned from sharding Postgres at Notion. notion.com, October 2021. Archived at perma.cc/5J5V-W2VX ↩︎ ↩︎
Ulrich Drepper. What Every Programmer Should Know About Memory. akkadia.org, November 2007. Archived at perma.cc/NU6Q-DRXZ ↩︎
Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Namasivayam, Alex Miller, Evan Tschannen, Steve Atherton, Andrew J. Beamon, Rusty Sears, John Leach, Dave Rosenthal, Xin Dong, Will Wilson, Ben Collins, David Scherer, Alec Grieser, Young Liu, Alvin Moore, Bhaskar Muppana, Xiaoge Su, and Vishesh Yadav. FoundationDB: A Distributed Unbundled Transactional Key Value Store. At ACM International Conference on Management of Data (SIGMOD), June 2021. doi:10.1145/3448016.3457559 ↩︎ ↩︎
Marco Slot. Citus 12: Schema-based sharding for PostgreSQL. citusdata.com, July 2023. Archived at perma.cc/R874-EC9W ↩︎
Robisson Oliveira. Reducing the Scope of Impact with Cell-Based Architecture. AWS Well-Architected white paper, Amazon Web Services, September 2023. Archived at perma.cc/4KWW-47NR ↩︎
Gwen Shapira. Things DBs Don’t Do - But Should. thenile.dev, February 2023. Archived at perma.cc/C3J4-JSFW ↩︎
Malte Schwarzkopf, Eddie Kohler, M. Frans Kaashoek, and Robert Morris. Position: GDPR Compliance by Construction. At Towards Polystores that manage multiple Databases, Privacy, Security and/or Policy Issues for Heterogenous Data (Poly), August 2019. doi:10.1007/978-3-030-33752-0_3 ↩︎
Gwen Shapira. Introducing pg_karnak: Transactional schema migration across tenant databases. thenile.dev, November 2024. Archived at perma.cc/R5RD-8HR9 ↩︎
Arka Ganguli, Guido Iaquinti, Maggie Zhou, and Rafael Chacón. Scaling Datastores at Slack with Vitess. slack.engineering, December 2020. Archived at perma.cc/UW8F-ALJK ↩︎
Ikai Lan. App Engine Datastore Tip: Monotonically Increasing Values Are Bad. ikaisays.com, January 2011. Archived at perma.cc/BPX8-RPJB ↩︎
Enis Soztutar. Apache HBase Region Splitting and Merging. cloudera.com, February 2013. Archived at perma.cc/S9HS-2X2C ↩︎
Eric Evans. Rethinking Topology in Cassandra. At Cassandra Summit, June 2013. Archived at perma.cc/2DKM-F438 ↩︎ ↩︎
Martin Kleppmann. Java’s hashCode Is Not Safe for Distributed Systems. martin.kleppmann.com, June 2012. Archived at perma.cc/LK5U-VZSN ↩︎
Mostafa Elhemali, Niall Gallagher, Nicholas Gordon, Joseph Idziorek, Richard Krog, Colin Lazier, Erben Mo, Akhilesh Mritunjai, Somu Perianayagam, Tim Rath, Swami Sivasubramanian, James Christopher Sorenson III, Sroaj Sosothikul, Doug Terry, and Akshat Vig. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. At USENIX Annual Technical Conference (ATC), July 2022. ↩︎ ↩︎ ↩︎
Brandon Williams. Virtual Nodes in Cassandra 1.2. datastax.com, December 2012. Archived at perma.cc/N385-EQXV ↩︎
Branimir Lambov. New Token Allocation Algorithm in Cassandra 3.0. datastax.com, January 2016. Archived at perma.cc/2BG7-LDWY ↩︎
David Karger, Eric Lehman, Tom Leighton, Rina Panigrahy, Matthew Levine, and Daniel Lewin. Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. At 29th Annual ACM Symposium on Theory of Computing (STOC), May 1997. doi:10.1145/258533.258660 ↩︎
Damian Gryski. Consistent Hashing: Algorithmic Tradeoffs. dgryski.medium.com, April 2018. Archived at perma.cc/B2WF-TYQ8 ↩︎
David G. Thaler and Chinya V. Ravishankar. Using name-based mappings to increase hit rates. IEEE/ACM Transactions on Networking, volume 6, issue 1, pages 1–14, February 1998. doi:10.1109/90.663936 ↩︎
John Lamping and Eric Veach. A Fast, Minimal Memory, Consistent Hash Algorithm. arxiv.org, June 2014. ↩︎
Samuel Axon. 3% of Twitter’s Servers Dedicated to Justin Bieber. mashable.com, September 2010. Archived at perma.cc/F35N-CGVX ↩︎
Gerald Guo and Thawan Kooburat. Scaling services with Shard Manager. engineering.fb.com, August 2020. Archived at perma.cc/EFS3-XQYT ↩︎
Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Thawan Kooburat, Suryadeep Biswal, Jun Chen, Kun Huang, Yatpang Cheung, Yiding Zhou, Kaushik Veeraraghavan, Biren Damani, Pol Mauri Ruiz, Vikas Mehta, and Chunqiang Tang. Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications. 28th ACM SIGOPS Symposium on Operating Systems Principles (SOSP), pages 553–569, October 2021. doi:10.1145/3477132.3483546 ↩︎
Scott Lystig Fritchie. A Critique of Resizable Hash Tables: Riak Core & Random Slicing. infoq.com, August 2018. Archived at perma.cc/RPX7-7BLN ↩︎
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/6S7P-GLM4 ↩︎
Rich Houlihan. DynamoDB adaptive capacity: smooth performance for chaotic workloads (DAT327). At AWS re:Invent, November 2017. ↩︎ ↩︎
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008. ISBN: 978-0-521-86571-5, available online at nlp.stanford.edu/IR-book ↩︎ ↩︎ ↩︎
Michael Busch, Krishna Gade, Brian Larson, Patrick Lok, Samuel Luckenbill, and Jimmy Lin. Earlybird: Real-Time Search at Twitter. At 28th IEEE International Conference on Data Engineering (ICDE), April 2012. doi:10.1109/ICDE.2012.149 ↩︎
Nadav Har’El. Indexing in Cassandra 3. github.com, April 2017. Archived at perma.cc/3ENV-8T9P ↩︎
Zachary Tong. Customizing Your Document Routing. elastic.co, June 2013. Archived at perma.cc/97VM-MREN ↩︎
Andrew Pavlo. H-Store Frequently Asked Questions. hstore.cs.brown.edu, October 2013. Archived at perma.cc/X3ZA-DW6Z ↩︎