13. Triết Lý của Hệ Thống Streaming
Nếu một sự vật được sắp đặt hướng đến một mục đích khác, thì mục đích cuối cùng của nó không thể là việc bảo tồn sự tồn tại của chính nó. Do đó, một thuyền trưởng không coi việc bảo toàn con tàu được giao phó cho mình là mục đích tối hậu, bởi lẽ con tàu vốn được sắp đặt cho một mục đích khác, đó là hành hải.
(Thường được trích dẫn là: Nếu mục tiêu cao nhất của một thuyền trưởng là bảo toàn con tàu, ông ta sẽ giữ nó mãi trong cảng.)
Thánh Thomas Aquinas, Summa Theologica (1265–1274)
GHI CHÚ CHO ĐỘC GIẢ BẢN PHÁT HÀNH SỚM
Với sách ebook Phát hành Sớm, bạn nhận được sách ở dạng sơ khai nhất, tức là nội dung thô và chưa qua biên tập của tác giả khi họ đang viết, để bạn có thể tận dụng các công nghệ này từ rất lâu trước khi tác phẩm được phát hành chính thức.
Đây sẽ là chương 13 của cuốn sách hoàn chỉnh. Kho GitHub cho cuốn sách này là https://github.com/ept/ddia2-feedback.
Nếu bạn muốn tham gia tích cực vào việc đánh giá và nhận xét bản thảo này, vui lòng liên hệ trên GitHub.
Trong Chương 2 chúng ta đã thảo luận về mục tiêu tạo ra các ứng dụng và hệ thống có tính tin cậy (reliable), khả năng mở rộng (scalable), và dễ bảo trì (maintainable). Những chủ đề này đã chạy xuyên suốt tất cả các chương: chẳng hạn, chúng ta đã thảo luận về nhiều thuật toán chịu lỗi giúp cải thiện độ tin cậy, về sharding (phân mảnh) để cải thiện khả năng mở rộng, và về các cơ chế cho sự tiến hóa và trừu tượng hóa giúp cải thiện khả năng bảo trì.
Trong chương này chúng ta sẽ kết hợp tất cả những ý tưởng này lại với nhau, và xây dựng dựa trên các ý tưởng về kiến trúc streaming/hướng sự kiện từ Chương 12 để phát triển một triết lý phát triển ứng dụng đáp ứng những mục tiêu đó. Chương này mang tính quan điểm nhiều hơn các chương trước, trình bày một nghiên cứu chuyên sâu về một triết lý cụ thể thay vì so sánh nhiều cách tiếp cận.
Tích Hợp Dữ Liệu
Một chủ đề xuyên suốt cuốn sách này là đối với bất kỳ vấn đề nào, đều có nhiều giải pháp, tất cả đều có những ưu điểm, nhược điểm và đánh đổi khác nhau. Ví dụ, khi thảo luận về storage engine (bộ máy lưu trữ) trong Chương 4, chúng ta đã thấy lưu trữ log-structured, B-tree và lưu trữ hướng cột. Khi thảo luận về replication (sao chép) trong Chương 6, chúng ta đã thấy các cách tiếp cận single-leader, multi-leader và leaderless.
Nếu bạn có một vấn đề như “Tôi muốn lưu trữ một số dữ liệu và tra cứu lại sau”, không có một giải pháp đúng duy nhất, mà có nhiều cách tiếp cận khác nhau, mỗi cách phù hợp trong các hoàn cảnh khác nhau. Một triển khai phần mềm thường phải chọn một cách tiếp cận cụ thể. Việc làm cho một đường dẫn mã hoạt động mạnh mẽ và hiệu quả đã đủ khó rồi, việc cố gắng làm tất cả mọi thứ trong một phần mềm gần như chắc chắn sẽ dẫn đến một triển khai kém chất lượng.
Do đó, lựa chọn công cụ phần mềm phù hợp nhất cũng phụ thuộc vào hoàn cảnh. Mỗi phần mềm, dù được gọi là cơ sở dữ liệu “đa năng”, đều được thiết kế cho một mô hình sử dụng cụ thể.
Đối mặt với sự phong phú của các lựa chọn này, thách thức đầu tiên là tìm ra ánh xạ giữa các sản phẩm phần mềm và các hoàn cảnh mà chúng phù hợp. Các nhà cung cấp có thể hiểu được rằng họ không muốn nói với bạn về các loại workload mà phần mềm của họ không phù hợp, nhưng hy vọng rằng các chương trước đã trang bị cho bạn một số câu hỏi để đặt ra nhằm đọc giữa các dòng và hiểu rõ hơn về các đánh đổi.
Tuy nhiên, ngay cả khi bạn hiểu hoàn hảo ánh xạ giữa các công cụ và hoàn cảnh sử dụng chúng, vẫn còn một thách thức khác: trong các ứng dụng phức tạp, dữ liệu thường được sử dụng theo nhiều cách khác nhau. Khó có một phần mềm nào phù hợp với tất cả các hoàn cảnh khác nhau mà dữ liệu được sử dụng, vì vậy bạn không thể tránh khỏi việc phải ghép nhiều phần mềm khác nhau lại để cung cấp chức năng cho ứng dụng của mình.
Kết Hợp Các Công Cụ Chuyên Biệt Bằng Cách Dẫn Xuất Dữ Liệu
Ví dụ, việc tích hợp một cơ sở dữ liệu OLTP với một chỉ mục tìm kiếm toàn văn bản (full-text search index) để xử lý các truy vấn từ khóa tùy ý là điều phổ biến. Mặc dù một số cơ sở dữ liệu (chẳng hạn PostgreSQL) bao gồm tính năng lập chỉ mục toàn văn bản, điều này có thể đủ cho các ứng dụng đơn giản 1, các cơ sở tìm kiếm tinh vi hơn đòi hỏi các công cụ truy xuất thông tin chuyên biệt. Ngược lại, các chỉ mục tìm kiếm thường không phù hợp để làm system of record (hệ thống lưu trữ chính thức) lâu dài, và vì vậy nhiều ứng dụng cần kết hợp hai công cụ khác nhau để đáp ứng tất cả các yêu cầu.
Chúng ta đã đề cập đến vấn đề tích hợp các hệ thống dữ liệu trong “Keeping Systems in Sync”. Khi số lượng các biểu diễn khác nhau của dữ liệu tăng lên, bài toán tích hợp trở nên khó khăn hơn. Ngoài cơ sở dữ liệu và chỉ mục tìm kiếm, bạn có thể cần lưu trữ các bản sao của dữ liệu trong các hệ thống phân tích (data warehouse, hoặc các hệ thống xử lý batch và stream); duy trì cache hoặc các phiên bản phi chuẩn hóa của các đối tượng được dẫn xuất từ dữ liệu gốc; đưa dữ liệu qua các hệ thống machine learning, phân loại, xếp hạng hoặc gợi ý; hoặc gửi thông báo dựa trên các thay đổi trong dữ liệu.
Lý luận về luồng dữ liệu
Khi các bản sao của cùng một dữ liệu cần được duy trì trong nhiều hệ thống lưu trữ để đáp ứng các mô hình truy cập khác nhau, bạn cần rất rõ ràng về đầu vào và đầu ra: dữ liệu được ghi đầu tiên ở đâu, và những biểu diễn nào được dẫn xuất từ nguồn nào? Làm thế nào để đưa dữ liệu vào tất cả các nơi đúng, ở đúng định dạng?
Ví dụ, bạn có thể sắp xếp để dữ liệu được ghi đầu tiên vào một cơ sở dữ liệu system of record, bắt lấy các thay đổi được thực hiện đối với cơ sở dữ liệu đó (xem “Change Data Capture”) và sau đó áp dụng các thay đổi vào chỉ mục tìm kiếm theo cùng thứ tự. Nếu change data capture (CDC, bắt lấy thay đổi dữ liệu) là cách duy nhất để cập nhật chỉ mục, bạn có thể tự tin rằng chỉ mục được dẫn xuất hoàn toàn từ system of record, và do đó nhất quán với nó (trừ lỗi trong phần mềm). Ghi vào cơ sở dữ liệu là cách duy nhất để cung cấp đầu vào mới vào hệ thống này.
Cho phép ứng dụng ghi trực tiếp vào cả chỉ mục tìm kiếm lẫn cơ sở dữ liệu dẫn đến vấn đề được thể hiện trong Hình 12-4, trong đó hai client đồng thời gửi các ghi xung đột, và hai hệ thống lưu trữ xử lý chúng theo thứ tự khác nhau. Trong trường hợp này, cả cơ sở dữ liệu lẫn chỉ mục tìm kiếm đều không “chịu trách nhiệm” xác định thứ tự của các ghi, và vì vậy chúng có thể đưa ra các quyết định mâu thuẫn và trở nên mất đồng bộ vĩnh viễn với nhau.
Nếu có thể dồn tất cả đầu vào của người dùng qua một hệ thống duy nhất quyết định thứ tự cho tất cả các ghi, việc dẫn xuất các biểu diễn khác của dữ liệu bằng cách xử lý các ghi theo cùng thứ tự sẽ trở nên dễ dàng hơn nhiều. Đây là một ứng dụng của cách tiếp cận state machine replication (sao chép máy trạng thái) mà chúng ta đã thấy trong “Consensus in Practice”. Việc bạn sử dụng change data capture hay event sourcing log không quan trọng bằng nguyên tắc đơn giản là quyết định một thứ tự toàn cục.
Cập nhật một hệ thống dữ liệu dẫn xuất dựa trên một event log thường có thể được thực hiện theo cách xác định và idempotent (bất biến khi lặp lại, xem “Idempotence”), giúp dễ dàng phục hồi sau lỗi.
Dữ liệu dẫn xuất so với giao dịch phân tán
Cách tiếp cận cổ điển để giữ các hệ thống dữ liệu khác nhau nhất quán với nhau liên quan đến distributed transactions (giao dịch phân tán), như đã thảo luận trong “Two-Phase Commit (2PC)”. Vậy cách tiếp cận sử dụng các hệ thống dữ liệu dẫn xuất so sánh như thế nào với distributed transactions?
Ở cấp độ trừu tượng, chúng đạt được mục tiêu tương tự bằng các phương tiện khác nhau. Distributed transactions quyết định thứ tự của các ghi bằng cách sử dụng lock (khóa) để loại trừ lẫn nhau, trong khi CDC và event sourcing sử dụng log để sắp xếp thứ tự. Distributed transactions sử dụng atomic commit (commit nguyên tử) để đảm bảo rằng các thay đổi có hiệu lực đúng một lần, trong khi các hệ thống dựa trên log thường dựa trên việc thử lại xác định và idempotence.
Sự khác biệt lớn nhất là các hệ thống giao dịch thường đảm bảo rằng sau khi một giá trị được ghi, bạn có thể đọc ngay lập tức giá trị cập nhật (xem “Reading Your Own Writes”). Mặt khác, các hệ thống dẫn xuất thường được cập nhật bất đồng bộ, và do đó chúng không mặc định đảm bảo rằng các đọc là cập nhật nhất.
Trong các môi trường hạn chế sẵn sàng trả giá cho distributed transactions, chúng đã được sử dụng thành công. Tuy nhiên, XA có khả năng chịu lỗi và đặc tính hiệu suất kém (xem “Distributed Transactions Across Different Systems”), điều này hạn chế nghiêm trọng tính hữu dụng của nó. Có thể tạo ra một giao thức tốt hơn cho distributed transactions, nhưng việc được áp dụng rộng rãi và tích hợp với các công cụ hiện có sẽ là một thách thức, và khó có thể xảy ra sớm.
Trong trường hợp thiếu hỗ trợ rộng rãi cho một giao thức distributed transaction tốt, dữ liệu dẫn xuất dựa trên log là cách tiếp cận hứa hẹn nhất để tích hợp các hệ thống dữ liệu khác nhau. Tuy nhiên, các đảm bảo như reading your own writes là hữu ích, và không có ích gì khi nói với mọi người “eventual consistency là không thể tránh khỏi, hãy chấp nhận và học cách xử lý nó” (ít nhất là không có hướng dẫn tốt về cách xử lý nó).
Ở phần sau trong chương này chúng ta sẽ thảo luận về một số cách tiếp cận để thực hiện các đảm bảo mạnh hơn trên các hệ thống dẫn xuất bất đồng bộ, và hướng đến một điểm trung gian giữa distributed transactions và các hệ thống dựa trên log bất đồng bộ.
Giới hạn của thứ tự toàn cục
Đối với các hệ thống đủ nhỏ, việc xây dựng một event log có thứ tự toàn cục hoàn toàn khả thi (như đã được chứng minh bởi sự phổ biến của các cơ sở dữ liệu với single-leader replication, tạo ra chính xác một log như vậy). Tuy nhiên, khi các hệ thống được mở rộng đến các workload lớn hơn và phức tạp hơn, các hạn chế bắt đầu xuất hiện:
Trong hầu hết các trường hợp, xây dựng một log có thứ tự toàn cục đòi hỏi tất cả các sự kiện phải đi qua một nút leader duy nhất quyết định thứ tự. Nếu thông lượng của các sự kiện lớn hơn mức một máy có thể xử lý, bạn cần phân mảnh log trên nhiều máy. Thứ tự của các sự kiện trong hai phân mảnh khác nhau khi đó là mơ hồ.
Nếu các máy chủ trải rộng trên nhiều vùng địa lý phân tán, ví dụ để chịu đựng việc toàn bộ một trung tâm dữ liệu bị offline, bạn thường có một leader riêng biệt trong mỗi trung tâm dữ liệu, vì độ trễ mạng làm cho việc phối hợp đồng bộ giữa các trung tâm dữ liệu không hiệu quả. Điều này ngụ ý một thứ tự không xác định của các sự kiện bắt nguồn từ hai trung tâm dữ liệu khác nhau.
Khi các ứng dụng được triển khai dưới dạng microservice, một lựa chọn thiết kế phổ biến là triển khai mỗi service và trạng thái lâu dài của nó như một đơn vị độc lập, không chia sẻ trạng thái lâu dài giữa các service. Khi hai sự kiện bắt nguồn từ các service khác nhau, không có thứ tự được xác định cho các sự kiện đó.
Một số ứng dụng duy trì trạng thái phía client được cập nhật ngay lập tức khi có đầu vào của người dùng (không cần chờ xác nhận từ máy chủ), và thậm chí tiếp tục hoạt động khi offline. Với những ứng dụng như vậy, client và server rất có thể thấy các sự kiện theo thứ tự khác nhau.
Về mặt hình thức, việc quyết định thứ tự toàn cục của các sự kiện được gọi là total order broadcast (phát sóng thứ tự toàn cục), tương đương với consensus (xem “The Many Faces of Consensus”). Hầu hết các thuật toán consensus được thiết kế cho các tình huống trong đó thông lượng của một nút đơn là đủ để xử lý toàn bộ luồng sự kiện, và các thuật toán này không cung cấp cơ chế cho nhiều nút chia sẻ công việc sắp xếp thứ tự sự kiện.
Sắp xếp thứ tự sự kiện để nắm bắt quan hệ nhân quả
Trong các trường hợp không có liên kết nhân quả giữa các sự kiện, việc thiếu thứ tự toàn cục không phải là vấn đề lớn, vì các sự kiện đồng thời có thể được sắp xếp tùy ý. Một số trường hợp khác dễ xử lý hơn: ví dụ, khi có nhiều cập nhật của cùng một đối tượng, chúng có thể được sắp xếp toàn cục bằng cách định tuyến tất cả các cập nhật cho một ID đối tượng cụ thể đến cùng một phân mảnh log. Tuy nhiên, phụ thuộc nhân quả đôi khi phát sinh theo những cách tinh tế hơn.
Ví dụ, hãy xem xét một mạng xã hội, và hai người dùng đang trong một mối quan hệ nhưng vừa chia tay. Một trong hai người dùng xóa người kia khỏi danh sách bạn bè, và sau đó gửi một tin nhắn cho những người bạn còn lại để phàn nàn về người cũ. Ý định của người dùng là người cũ không nên thấy tin nhắn thô lỗ đó, vì tin nhắn được gửi sau khi quyền trạng thái bạn bè đã bị thu hồi.
Tuy nhiên, trong một hệ thống lưu trữ trạng thái bạn bè ở một nơi và tin nhắn ở một nơi khác, sự phụ thuộc thứ tự giữa sự kiện unfriend (hủy kết bạn) và sự kiện message-send (gửi tin nhắn) có thể bị mất. Nếu sự phụ thuộc nhân quả không được nắm bắt, một service gửi thông báo về tin nhắn mới có thể xử lý sự kiện message-send trước sự kiện unfriend, và do đó gửi thông báo sai cho người cũ.
Trong ví dụ này, các thông báo thực chất là một phép join giữa tin nhắn và danh sách bạn bè, liên quan đến các vấn đề về thời gian của các phép join mà chúng ta đã thảo luận trước đó (xem “Time-dependence of joins”). Tiếc thay, dường như không có câu trả lời đơn giản cho vấn đề này 2, 3. Các điểm khởi đầu bao gồm:
Logical timestamps (dấu thời gian logic) có thể cung cấp thứ tự toàn cục mà không cần phối hợp (xem “ID Generators and Logical Clocks”), vì vậy chúng có thể hữu ích trong các trường hợp mà total order broadcast không khả thi. Tuy nhiên, chúng vẫn yêu cầu người nhận xử lý các sự kiện được chuyển đến theo thứ tự không đúng, và yêu cầu siêu dữ liệu bổ sung được truyền đi.
Nếu bạn có thể ghi một sự kiện để ghi lại trạng thái của hệ thống mà người dùng đã thấy trước khi đưa ra quyết định, và cấp cho sự kiện đó một định danh duy nhất, thì bất kỳ sự kiện nào sau đó đều có thể tham chiếu đến định danh sự kiện đó để ghi lại sự phụ thuộc nhân quả 4.
Các thuật toán giải quyết xung đột (xem “Automatic conflict resolution”) giúp xử lý các sự kiện được chuyển đến theo thứ tự không mong đợi. Chúng hữu ích để duy trì trạng thái, nhưng không giúp ích gì nếu các hành động có tác dụng phụ bên ngoài (chẳng hạn như gửi thông báo cho người dùng).
Có lẽ, trong tương lai sẽ xuất hiện các mô hình phát triển ứng dụng cho phép nắm bắt các phụ thuộc nhân quả một cách hiệu quả, và duy trì trạng thái dẫn xuất một cách chính xác, mà không buộc tất cả các sự kiện phải đi qua nút thắt cổ chai của total order broadcast.
Xử Lý Batch và Stream
Mục tiêu của tích hợp dữ liệu là đảm bảo rằng dữ liệu kết thúc ở đúng dạng trong tất cả các nơi đúng. Để làm điều đó, cần tiêu thụ các đầu vào, chuyển đổi, join, lọc, tổng hợp, huấn luyện mô hình, đánh giá, và cuối cùng ghi vào các đầu ra thích hợp. Bộ xử lý batch và stream là các công cụ để đạt được mục tiêu này. Đầu ra của các quy trình batch và stream là các tập dữ liệu dẫn xuất như chỉ mục tìm kiếm, materialized view (khung nhìn được vật chất hóa), các gợi ý hiển thị cho người dùng, các số liệu tổng hợp, và nhiều thứ khác.
Như chúng ta đã thấy trong Chương 11 và Chương 12, xử lý batch và stream có rất nhiều nguyên tắc chung, và sự khác biệt cơ bản chính là bộ xử lý stream hoạt động trên các tập dữ liệu không giới hạn trong khi đầu vào xử lý batch có kích thước hữu hạn và đã biết.
Duy trì trạng thái dẫn xuất
Xử lý batch có hương vị hàm (functional) khá mạnh (ngay cả khi mã không được viết bằng ngôn ngữ lập trình hàm): nó khuyến khích các hàm thuần túy xác định mà đầu ra chỉ phụ thuộc vào đầu vào và không có tác dụng phụ nào ngoài các đầu ra tường minh, xử lý đầu vào như bất biến và đầu ra như append-only (chỉ thêm vào). Xử lý stream cũng tương tự, nhưng nó mở rộng các toán tử để cho phép trạng thái được quản lý có khả năng chịu lỗi.
Nguyên tắc về các hàm xác định với đầu vào và đầu ra được xác định rõ ràng không chỉ tốt cho khả năng chịu lỗi, mà còn đơn giản hóa việc lý luận về các luồng dữ liệu trong một tổ chức 5. Bất kể dữ liệu dẫn xuất là chỉ mục tìm kiếm, mô hình thống kê hay cache, thật hữu ích khi nghĩ về các đường ống dữ liệu dẫn xuất một thứ từ một thứ khác, đẩy các thay đổi trạng thái trong một hệ thống qua mã ứng dụng hàm và áp dụng các tác dụng lên các hệ thống dẫn xuất.
Về nguyên tắc, các hệ thống dữ liệu dẫn xuất có thể được duy trì đồng bộ, giống như cách cơ sở dữ liệu quan hệ cập nhật các chỉ mục phụ đồng bộ trong cùng một giao dịch như các ghi vào bảng đang được lập chỉ mục. Tuy nhiên, tính bất đồng bộ là điều làm cho các hệ thống dựa trên event log trở nên mạnh mẽ: nó cho phép lỗi ở một phần của hệ thống được khoanh vùng cục bộ, trong khi distributed transactions hủy bỏ nếu bất kỳ người tham gia nào thất bại, vì vậy chúng có xu hướng khuếch đại lỗi bằng cách lan truyền chúng sang phần còn lại của hệ thống.
Chúng ta đã thấy trong “Sharding and Secondary Indexes” rằng các chỉ mục phụ thường vượt qua các ranh giới phân mảnh. Một hệ thống phân mảnh với các chỉ mục phụ hoặc cần gửi các ghi đến nhiều phân mảnh (nếu chỉ mục được phân chia theo term) hoặc gửi các đọc đến tất cả các phân mảnh (nếu chỉ mục được phân chia theo tài liệu). Giao tiếp liên phân mảnh như vậy cũng đáng tin cậy và có khả năng mở rộng nhất nếu chỉ mục được duy trì bất đồng bộ 6.
Tái xử lý dữ liệu để phát triển ứng dụng
Khi duy trì dữ liệu dẫn xuất, cả xử lý batch lẫn stream đều hữu ích. Xử lý stream cho phép các thay đổi trong đầu vào được phản ánh trong các khung nhìn dẫn xuất với độ trễ thấp, trong khi xử lý batch cho phép tái xử lý lượng lớn dữ liệu lịch sử tích lũy để dẫn xuất các khung nhìn mới trên một tập dữ liệu hiện có.
Cụ thể, tái xử lý dữ liệu hiện có cung cấp một cơ chế tốt để duy trì một hệ thống, phát triển nó để hỗ trợ các tính năng mới và các yêu cầu thay đổi. Không có tái xử lý, sự tiến hóa schema bị giới hạn ở các thay đổi đơn giản như thêm một trường tùy chọn mới vào một bản ghi, hoặc thêm một loại bản ghi mới. Mặt khác, với tái xử lý, có thể tái cấu trúc một tập dữ liệu thành một mô hình hoàn toàn khác để phục vụ tốt hơn cho các yêu cầu mới.
DI CƯ SCHEMA TRÊN CÁC TUYẾN ĐƯỜNG SẮT
Các “di cư schema” quy mô lớn xảy ra trong các hệ thống phi máy tính cũng vậy. Ví dụ, trong những ngày đầu xây dựng đường sắt ở nước Anh thế kỷ 19, có nhiều tiêu chuẩn cạnh tranh khác nhau về khổ đường (khoảng cách giữa hai thanh ray). Tàu hỏa được chế tạo cho một khổ đường không thể chạy trên đường ray của khổ đường khác, điều này hạn chế các kết nối có thể có trong mạng lưới tàu hỏa 7.
Sau khi một khổ đường tiêu chuẩn duy nhất cuối cùng được quyết định vào năm 1846, các đường ray có khổ đường khác phải được chuyển đổi, nhưng làm thế nào để thực hiện điều này mà không đóng cửa tuyến tàu trong nhiều tháng hoặc nhiều năm? Giải pháp là đầu tiên chuyển đường ray thành khổ đường kép hoặc khổ đường hỗn hợp bằng cách thêm một thanh ray thứ ba. Việc chuyển đổi này có thể thực hiện dần dần, và khi hoàn thành, tàu hỏa của cả hai khổ đường có thể chạy trên tuyến đường, sử dụng hai trong số ba thanh ray. Cuối cùng, khi tất cả các đoàn tàu đã được chuyển đổi sang khổ đường tiêu chuẩn, thanh ray cung cấp khổ đường phi tiêu chuẩn có thể được tháo bỏ.
“Tái xử lý” các đường ray hiện có theo cách này, và cho phép các phiên bản cũ và mới cùng tồn tại, giúp có thể thay đổi khổ đường dần dần qua nhiều năm. Tuy nhiên, đây là một công việc tốn kém, đó là lý do tại sao các khổ đường phi tiêu chuẩn vẫn tồn tại cho đến ngày nay. Ví dụ, hệ thống BART ở vùng Vịnh San Francisco sử dụng một khổ đường khác với phần lớn nước Mỹ.
Các khung nhìn dẫn xuất cho phép di cư dần dần. Nếu bạn muốn tái cấu trúc một tập dữ liệu, bạn không cần thực hiện việc di cư như một chuyển đổi đột ngột. Thay vào đó, bạn có thể duy trì schema cũ và schema mới song song như hai khung nhìn dẫn xuất độc lập trên cùng một dữ liệu cơ bản. Sau đó bạn có thể bắt đầu chuyển một số lượng nhỏ người dùng sang khung nhìn mới để kiểm tra hiệu suất và tìm bất kỳ lỗi nào, trong khi hầu hết người dùng tiếp tục được chuyển hướng đến khung nhìn cũ. Dần dần, bạn có thể tăng tỷ lệ người dùng truy cập vào khung nhìn mới, và cuối cùng bạn có thể xóa khung nhìn cũ 8, 9.
Vẻ đẹp của quá trình di cư dần dần như vậy là mỗi giai đoạn của quá trình đều dễ dàng có thể đảo ngược nếu có sự cố: bạn luôn có một hệ thống đang hoạt động để quay lại. Bằng cách giảm nguy cơ thiệt hại không thể đảo ngược, bạn có thể tự tin hơn khi tiến hành, và do đó di chuyển nhanh hơn để cải thiện hệ thống của mình 10.
Thống nhất xử lý batch và stream
Một đề xuất ban đầu để thống nhất xử lý batch và stream là kiến trúc lambda 11, có một số vấn đề 12 và đã lỗi thời. Các hệ thống gần đây hơn cho phép các tính toán batch (tái xử lý dữ liệu lịch sử) và các tính toán stream (xử lý sự kiện khi chúng đến) được triển khai trong cùng một hệ thống 13, một cách tiếp cận đôi khi được gọi là kiến trúc kappa 12.
Việc thống nhất xử lý batch và stream trong một hệ thống đòi hỏi các tính năng sau:
Khả năng phát lại các sự kiện lịch sử qua cùng một bộ máy xử lý xử lý luồng sự kiện gần đây. Ví dụ, các message broker dựa trên log có khả năng phát lại tin nhắn, và một số bộ xử lý stream có thể đọc đầu vào từ một hệ thống tập tin phân tán hoặc object storage.
Ngữ nghĩa exactly-once cho bộ xử lý stream, tức là đảm bảo rằng đầu ra giống như khi không có lỗi nào xảy ra, ngay cả khi lỗi thực sự đã xảy ra. Giống như với xử lý batch, điều này đòi hỏi phải loại bỏ đầu ra một phần của bất kỳ tác vụ thất bại nào.
Các công cụ để windowing (phân cửa sổ) theo thời gian sự kiện, không theo thời gian xử lý, vì thời gian xử lý là vô nghĩa khi tái xử lý các sự kiện lịch sử. Ví dụ, Apache Beam cung cấp API để biểu diễn các tính toán như vậy, sau đó có thể chạy bằng Apache Flink hoặc Google Cloud Dataflow.
Unbundling Cơ Sở Dữ Liệu
Ở cấp độ trừu tượng nhất, cơ sở dữ liệu, bộ xử lý batch/stream và hệ điều hành đều thực hiện các chức năng tương tự: chúng lưu trữ một số dữ liệu, và cho phép bạn xử lý và truy vấn dữ liệu đó 14, 15. Cơ sở dữ liệu lưu trữ dữ liệu trong các bản ghi của một mô hình dữ liệu nào đó (hàng trong bảng, tài liệu, đỉnh trong đồ thị, v.v.) trong khi hệ thống tập tin của hệ điều hành lưu trữ dữ liệu trong các tập tin, nhưng về cơ bản, cả hai đều là các hệ thống “quản lý thông tin” 16. Như chúng ta đã thấy trong Chương 11, bộ xử lý batch giống như một phiên bản phân tán của Unix.
Tất nhiên, có nhiều khác biệt thực tế. Ví dụ, nhiều hệ thống tập tin không xử lý tốt lắm một thư mục chứa 10 triệu tập tin nhỏ, trong khi một cơ sở dữ liệu chứa 10 triệu bản ghi nhỏ là hoàn toàn bình thường và không đáng chú ý. Tuy nhiên, những điểm tương đồng và khác biệt giữa hệ điều hành và cơ sở dữ liệu đáng được khám phá.
Unix và cơ sở dữ liệu quan hệ đã tiếp cận bài toán quản lý thông tin với các triết lý rất khác nhau. Unix coi mục đích của nó là cung cấp cho lập trình viên một sự trừu tượng hóa phần cứng hợp lý nhưng ở mức khá thấp, trong khi cơ sở dữ liệu quan hệ muốn cung cấp cho lập trình viên ứng dụng một sự trừu tượng hóa ở mức cao ẩn giấu sự phức tạp của các cấu trúc dữ liệu trên đĩa, đồng thời, phục hồi sau sự cố, và nhiều thứ khác. Unix phát triển các pipe và file chỉ là chuỗi byte, trong khi cơ sở dữ liệu phát triển SQL và giao dịch.
Cách tiếp cận nào tốt hơn? Tất nhiên, điều đó phụ thuộc vào những gì bạn muốn. Unix “đơn giản hơn” theo nghĩa là nó là một lớp bao bọc khá mỏng quanh tài nguyên phần cứng; cơ sở dữ liệu quan hệ “đơn giản hơn” theo nghĩa là một truy vấn khai báo ngắn có thể dựa vào nhiều cơ sở hạ tầng mạnh mẽ (tối ưu hóa truy vấn, chỉ mục, phương thức join, kiểm soát đồng thời, replication, v.v.) mà không cần tác giả của truy vấn phải hiểu các chi tiết triển khai.
Sự căng thẳng giữa hai triết lý này đã kéo dài hàng thập kỷ (cả Unix lẫn mô hình quan hệ đều xuất hiện vào đầu những năm 1970) và vẫn chưa được giải quyết. Ví dụ, phong trào NoSQL có thể được hiểu là muốn áp dụng cách tiếp cận kiểu Unix với các trừu tượng ở mức thấp vào lĩnh vực lưu trữ dữ liệu OLTP phân tán.
Phần này cố gắng hòa giải hai triết lý, với hy vọng rằng chúng ta có thể kết hợp những ưu điểm tốt nhất của cả hai.
Kết Hợp Các Công Nghệ Lưu Trữ Dữ Liệu
Trong suốt cuốn sách này, chúng ta đã thảo luận về nhiều tính năng khác nhau được cung cấp bởi các cơ sở dữ liệu và cách chúng hoạt động, bao gồm:
Secondary index (chỉ mục phụ), cho phép bạn tìm kiếm hiệu quả các bản ghi dựa trên giá trị của một trường;
Materialized view (khung nhìn được vật chất hóa), là một loại cache được tính trước của các kết quả truy vấn;
Replication log (log sao chép), giữ cho các bản sao của dữ liệu trên các nút khác được cập nhật; và
Chỉ mục tìm kiếm toàn văn bản (full-text search index), cho phép tìm kiếm từ khóa trong văn bản và được tích hợp vào một số cơ sở dữ liệu quan hệ 1.
Trong các Chương 11 và 12, các chủ đề tương tự đã xuất hiện. Chúng ta đã nói về việc xây dựng các chỉ mục tìm kiếm toàn văn bản, về việc bảo trì materialized view, và về việc sao chép các thay đổi từ cơ sở dữ liệu sang các hệ thống dữ liệu dẫn xuất bằng change data capture.
Có vẻ như có sự song song giữa các tính năng được tích hợp vào cơ sở dữ liệu và các hệ thống dữ liệu dẫn xuất mà mọi người đang xây dựng với các bộ xử lý batch và stream.
Tạo một chỉ mục
Hãy nghĩ về những gì xảy ra khi bạn chạy CREATE INDEX để tạo một chỉ mục mới trong cơ sở dữ liệu quan hệ. Cơ sở dữ liệu phải quét qua một snapshot nhất quán của bảng, chọn ra tất cả các giá trị trường đang được lập chỉ mục, sắp xếp chúng, và ghi ra chỉ mục. Sau đó nó phải xử lý tồn đọng các ghi đã được thực hiện kể từ khi snapshot nhất quán được chụp (giả sử bảng không bị khóa trong khi tạo chỉ mục, do đó các ghi vẫn có thể tiếp tục). Sau khi xong, cơ sở dữ liệu phải tiếp tục giữ chỉ mục cập nhật bất cứ khi nào một giao dịch ghi vào bảng.
Quá trình này rất giống với việc thiết lập một follower replica mới (xem “Setting Up New Followers”), và cũng rất giống với việc khởi động change data capture trong một hệ thống streaming (xem “Initial snapshot”).
Bất cứ khi nào bạn chạy CREATE INDEX, cơ sở dữ liệu về cơ bản tái xử lý tập dữ liệu hiện có và dẫn xuất chỉ mục như một khung nhìn mới trên dữ liệu hiện có. Dữ liệu hiện có có thể là một snapshot của trạng thái chứ không phải là log của tất cả các thay đổi đã từng xảy ra, nhưng hai thứ có liên quan chặt chẽ với nhau.
Cơ sở dữ liệu meta của mọi thứ
Theo cách nhìn này, luồng dữ liệu trên toàn bộ một tổ chức bắt đầu trông giống như một cơ sở dữ liệu khổng lồ 5. Bất cứ khi nào một quy trình batch, stream hoặc ETL vận chuyển dữ liệu từ một nơi và hình thức này đến một nơi và hình thức khác, nó đang hoạt động như hệ thống con cơ sở dữ liệu giữ các chỉ mục hoặc materialized view cập nhật.
Nhìn theo cách này, các bộ xử lý batch và stream giống như các triển khai tinh vi của trigger (kích hoạt), stored procedure (thủ tục lưu trữ), và các thuật toán bảo trì materialized view. Các hệ thống dữ liệu dẫn xuất mà chúng duy trì giống như các loại chỉ mục khác nhau. Ví dụ, một cơ sở dữ liệu quan hệ có thể hỗ trợ chỉ mục B-tree, chỉ mục hash, chỉ mục không gian và các loại chỉ mục khác. Trong kiến trúc đang nổi lên của các hệ thống dữ liệu dẫn xuất, thay vì triển khai các tiện ích đó như là các tính năng của một sản phẩm cơ sở dữ liệu tích hợp duy nhất, chúng được cung cấp bởi các phần mềm khác nhau, chạy trên các máy khác nhau, được quản lý bởi các nhóm khác nhau.
Những phát triển này sẽ đưa chúng ta đến đâu trong tương lai? Nếu chúng ta bắt đầu từ tiền đề rằng không có mô hình dữ liệu hay định dạng lưu trữ đơn lẻ nào phù hợp cho tất cả các mô hình truy cập, có hai con đường mà qua đó các công cụ lưu trữ và xử lý khác nhau vẫn có thể được kết hợp thành một hệ thống gắn kết:
- Cơ sở dữ liệu liên kết (federated database): thống nhất đọc
Có thể cung cấp một giao diện truy vấn thống nhất cho nhiều loại bộ máy lưu trữ và phương pháp xử lý cơ bản, một cách tiếp cận được gọi là federated database hoặc polystore 17, 18. Ví dụ, tính năng foreign data wrapper của PostgreSQL phù hợp với mô hình này, cũng như các công cụ truy vấn liên kết như Trino, Hoptimator và Xorq. Các ứng dụng cần một mô hình dữ liệu hoặc giao diện truy vấn chuyên biệt vẫn có thể truy cập trực tiếp vào các bộ máy lưu trữ cơ bản, trong khi những người dùng muốn kết hợp dữ liệu từ các nơi khác nhau có thể thực hiện dễ dàng thông qua giao diện liên kết.
Một giao diện truy vấn liên kết theo truyền thống quan hệ của một hệ thống tích hợp duy nhất với ngôn ngữ truy vấn cấp cao và ngữ nghĩa thanh lịch, nhưng triển khai phức tạp.
- Cơ sở dữ liệu unbundled: thống nhất ghi
Trong khi federation giải quyết truy vấn chỉ đọc trên nhiều hệ thống khác nhau, nó không có câu trả lời tốt cho việc đồng bộ hóa các ghi trên các hệ thống đó. Chúng ta đã nói rằng trong một cơ sở dữ liệu duy nhất, tạo ra một chỉ mục nhất quán là một tính năng tích hợp sẵn. Khi chúng ta kết hợp nhiều hệ thống lưu trữ, chúng ta cũng cần đảm bảo rằng tất cả các thay đổi dữ liệu kết thúc ở tất cả các nơi đúng, ngay cả khi có lỗi. Làm cho việc kết nối các hệ thống lưu trữ một cách đáng tin cậy trở nên dễ dàng hơn (ví dụ: thông qua change data capture và event log) giống như unbundling (tách rời) các tính năng bảo trì chỉ mục của cơ sở dữ liệu theo cách có thể đồng bộ hóa các ghi trên các công nghệ khác nhau 5, 19.
Cách tiếp cận unbundled theo truyền thống Unix về các công cụ nhỏ làm một việc tốt 20, giao tiếp thông qua một API ở mức thấp thống nhất (pipe), và có thể được kết hợp bằng cách sử dụng ngôn ngữ cấp cao hơn (shell) 14.
Làm cho unbundling hoạt động
Federation và unbundling là hai mặt của cùng một đồng xu: kết hợp một hệ thống đáng tin cậy, có khả năng mở rộng và dễ bảo trì từ các thành phần đa dạng. Truy vấn chỉ đọc được liên kết đòi hỏi ánh xạ một mô hình dữ liệu sang mô hình khác, điều này đòi hỏi một chút suy nghĩ nhưng cuối cùng là một bài toán khá có thể quản lý được. Giữ cho các ghi vào nhiều hệ thống lưu trữ được đồng bộ là bài toán kỹ thuật khó hơn, và vì vậy chúng ta sẽ tập trung vào đó ở đây.
Cách tiếp cận truyền thống để đồng bộ hóa các ghi đòi hỏi distributed transactions trên các hệ thống lưu trữ không đồng nhất 17, điều này có vấn đề, như đã thảo luận trước đây. Các giao dịch trong một hệ thống lưu trữ hoặc xử lý stream duy nhất là khả thi, nhưng khi dữ liệu vượt qua ranh giới giữa các công nghệ khác nhau, một event log bất đồng bộ với các ghi idempotent là cách tiếp cận mạnh mẽ và thực tiễn hơn nhiều.
Ví dụ, distributed transactions được sử dụng trong một số bộ xử lý stream để đạt được ngữ nghĩa exactly-once, và điều này có thể hoạt động khá tốt. Tuy nhiên, khi một giao dịch cần liên quan đến các hệ thống được viết bởi các nhóm người khác nhau (ví dụ: khi dữ liệu được ghi từ một bộ xử lý stream vào một kho khóa-giá trị phân tán hoặc chỉ mục tìm kiếm), sự thiếu hụt của một giao thức giao dịch được chuẩn hóa làm cho việc tích hợp trở nên khó khăn hơn nhiều. Một log sự kiện có thứ tự với các consumer idempotent là một sự trừu tượng đơn giản hơn nhiều, và do đó khả thi hơn nhiều để triển khai trên các hệ thống không đồng nhất 5.
Ưu điểm lớn của tích hợp dựa trên log là loose coupling (liên kết lỏng lẻo) giữa các thành phần khác nhau, biểu hiện theo hai cách:
Ở cấp độ hệ thống, các luồng sự kiện bất đồng bộ làm cho hệ thống nói chung trở nên mạnh mẽ hơn đối với các sự cố hoặc sự giảm hiệu suất của các thành phần riêng lẻ. Nếu một consumer chạy chậm hoặc thất bại, event log có thể đệm tin nhắn, cho phép producer và bất kỳ consumer nào khác tiếp tục chạy không bị ảnh hưởng. Consumer bị lỗi có thể bắt kịp khi được sửa chữa, do đó không bỏ lỡ bất kỳ dữ liệu nào, và lỗi được khoanh vùng. Ngược lại, tương tác đồng bộ của distributed transactions có xu hướng leo thang các lỗi cục bộ thành các sự cố quy mô lớn.
Ở cấp độ con người, unbundling các hệ thống dữ liệu cho phép các thành phần và service phần mềm khác nhau được phát triển, cải thiện và bảo trì độc lập với nhau bởi các nhóm khác nhau. Chuyên môn hóa cho phép mỗi nhóm tập trung vào việc làm tốt một việc, với các giao diện được xác định rõ ràng cho các hệ thống của các nhóm khác. Event log cung cấp một giao diện đủ mạnh để nắm bắt các thuộc tính nhất quán khá mạnh (do độ bền và thứ tự của sự kiện), nhưng cũng đủ chung để áp dụng cho hầu hết mọi loại dữ liệu.
Unbundled so với hệ thống tích hợp
Nếu unbundling thực sự trở thành con đường của tương lai, nó sẽ không thay thế cơ sở dữ liệu ở dạng hiện tại của chúng, chúng vẫn sẽ cần thiết như trước đây. Cơ sở dữ liệu vẫn được yêu cầu để duy trì trạng thái trong các bộ xử lý stream, và để phục vụ các truy vấn cho đầu ra của các bộ xử lý batch và stream. Các công cụ truy vấn chuyên biệt sẽ tiếp tục quan trọng cho các workload cụ thể: ví dụ, các công cụ truy vấn trong data warehouse được tối ưu hóa cho các truy vấn phân tích khám phá và xử lý loại workload này rất tốt.
Sự phức tạp của việc chạy nhiều phần cơ sở hạ tầng khác nhau có thể là một vấn đề: mỗi phần mềm có một đường cong học tập, các vấn đề cấu hình và những đặc điểm vận hành riêng, vì vậy đáng để triển khai càng ít thành phần di động càng tốt. Một sản phẩm phần mềm tích hợp đơn lẻ cũng có thể đạt được hiệu suất tốt hơn và có thể dự đoán hơn trên các loại workload mà nó được thiết kế, so với một hệ thống bao gồm nhiều công cụ mà bạn đã kết hợp với mã ứng dụng 21. Xây dựng cho quy mô mà bạn không cần là nỗ lực lãng phí và có thể khóa bạn vào một thiết kế không linh hoạt. Thực tế, đó là một dạng tối ưu hóa sớm.
Mục tiêu của unbundling không phải là cạnh tranh với các cơ sở dữ liệu riêng lẻ về hiệu suất cho các workload cụ thể; mục tiêu là cho phép bạn kết hợp một số cơ sở dữ liệu khác nhau để đạt được hiệu suất tốt cho một phạm vi workload rộng hơn nhiều so với những gì có thể với một phần mềm đơn lẻ. Đó là về chiều rộng, không phải chiều sâu.
Do đó, nếu có một công nghệ đơn lẻ làm tất cả những gì bạn cần, bạn hầu như tốt nhất là chỉ sử dụng sản phẩm đó thay vì cố gắng tái triển khai nó từ các thành phần cấp thấp hơn. Những ưu điểm của unbundling và kết hợp chỉ xuất hiện khi không có một phần mềm đơn lẻ nào đáp ứng tất cả các yêu cầu của bạn.
Các công cụ để kết hợp các hệ thống dữ liệu đang ngày càng tốt hơn: Debezium có thể trích xuất các change stream từ nhiều cơ sở dữ liệu, giao thức của Kafka đang trở thành tiêu chuẩn thực tế cho các event stream, và các bộ máy bảo trì khung nhìn tăng dần (xem “Incremental View Maintenance”) giúp có thể tính trước và cập nhật các cache của các truy vấn phức tạp.
Thiết Kế Ứng Dụng Xung Quanh Luồng Dữ Liệu
Ý tưởng chung về cập nhật dữ liệu dẫn xuất khi dữ liệu cơ bản của nó thay đổi không phải là mới. Ví dụ, bảng tính có khả năng lập trình luồng dữ liệu mạnh mẽ 22: bạn có thể đặt một công thức trong một ô (ví dụ: tổng của các ô trong một cột khác), và bất cứ khi nào bất kỳ đầu vào nào của công thức thay đổi, kết quả của công thức được tính toán lại tự động. Đây chính xác là những gì chúng ta muốn ở cấp độ hệ thống dữ liệu: khi một bản ghi trong cơ sở dữ liệu thay đổi, chúng ta muốn bất kỳ chỉ mục nào cho bản ghi đó được cập nhật tự động, và bất kỳ khung nhìn hay tổng hợp được cache nào phụ thuộc vào bản ghi đó được làm mới tự động. Bạn không nên phải lo lắng về các chi tiết kỹ thuật của cách làm mới này xảy ra, mà đơn giản là tin tưởng rằng nó hoạt động chính xác.
Do đó, hầu hết các hệ thống dữ liệu vẫn còn nhiều điều để học từ các tính năng mà VisiCalc đã có vào năm 1979 23. Sự khác biệt so với bảng tính là các hệ thống dữ liệu ngày nay cần có khả năng chịu lỗi, có khả năng mở rộng và lưu trữ dữ liệu lâu dài. Chúng cũng cần có khả năng tích hợp các công nghệ khác nhau được viết bởi các nhóm người khác nhau theo thời gian, và tái sử dụng các thư viện và service hiện có: thật không thực tế khi mong đợi tất cả phần mềm được phát triển bằng một ngôn ngữ, framework hoặc công cụ cụ thể.
Trong phần này chúng ta sẽ mở rộng những ý tưởng này và khám phá một số cách xây dựng ứng dụng xung quanh các ý tưởng về unbundled database và luồng dữ liệu.
Mã ứng dụng như một hàm dẫn xuất
Khi một tập dữ liệu được dẫn xuất từ tập khác, nó trải qua một loại hàm biến đổi nào đó. Ví dụ:
Chỉ mục phụ là một loại tập dữ liệu dẫn xuất với một hàm biến đổi đơn giản: đối với mỗi hàng hoặc tài liệu trong bảng cơ sở, nó chọn ra các giá trị trong các cột hoặc trường đang được lập chỉ mục, và sắp xếp theo các giá trị đó (giả sử chỉ mục SSTable hoặc B-tree, được sắp xếp theo khóa).
Chỉ mục tìm kiếm toàn văn bản được tạo ra bằng cách áp dụng nhiều hàm xử lý ngôn ngữ tự nhiên như phát hiện ngôn ngữ, phân đoạn từ, stemming hoặc lemmatization, sửa lỗi chính tả và nhận dạng từ đồng nghĩa, tiếp theo là xây dựng cấu trúc dữ liệu để tra cứu hiệu quả (chẳng hạn như inverted index).
Trong hệ thống machine learning, chúng ta có thể coi mô hình được dẫn xuất từ dữ liệu huấn luyện bằng cách áp dụng các hàm trích xuất đặc trưng và phân tích thống kê khác nhau. Khi mô hình được áp dụng cho dữ liệu đầu vào mới, đầu ra của mô hình được dẫn xuất từ đầu vào và mô hình (và do đó, gián tiếp, từ dữ liệu huấn luyện).
Cache thường chứa một tổng hợp dữ liệu dưới dạng mà nó sẽ được hiển thị trong giao diện người dùng (UI). Do đó, việc điền vào cache đòi hỏi kiến thức về các trường nào được tham chiếu trong UI; các thay đổi trong UI có thể đòi hỏi cập nhật định nghĩa về cách cache được điền và xây dựng lại cache.
Hàm dẫn xuất cho một chỉ mục phụ thường xuyên được yêu cầu đến mức nó được tích hợp vào nhiều cơ sở dữ liệu như một tính năng cốt lõi, và bạn có thể gọi nó bằng cách chỉ nói CREATE INDEX. Đối với lập chỉ mục toàn văn bản, các tính năng ngôn ngữ cơ bản cho các ngôn ngữ phổ biến có thể được tích hợp vào cơ sở dữ liệu, nhưng các tính năng tinh vi hơn thường đòi hỏi điều chỉnh theo lĩnh vực cụ thể. Trong machine learning, kỹ thuật feature engineering nổi tiếng là đặc thù theo ứng dụng, và thường phải kết hợp kiến thức chi tiết về tương tác người dùng và triển khai của ứng dụng 24.
Khi hàm tạo ra một tập dữ liệu dẫn xuất không phải là một hàm cookie-cutter tiêu chuẩn như tạo chỉ mục phụ, mã tùy chỉnh là cần thiết để xử lý các khía cạnh đặc thù theo ứng dụng. Và mã tùy chỉnh này là nơi mà nhiều cơ sở dữ liệu gặp khó khăn. Mặc dù các cơ sở dữ liệu quan hệ thường hỗ trợ trigger, stored procedure và user-defined function (hàm do người dùng định nghĩa), có thể được sử dụng để thực thi mã ứng dụng trong cơ sở dữ liệu, chúng phần nào đã là một suy nghĩ thứ hai trong thiết kế cơ sở dữ liệu.
Tách biệt mã ứng dụng và trạng thái
Về lý thuyết, cơ sở dữ liệu có thể là môi trường triển khai cho mã ứng dụng tùy ý, giống như một hệ điều hành. Tuy nhiên, trong thực tế, chúng đã cho thấy không phù hợp tốt cho mục đích này. Chúng không phù hợp tốt với các yêu cầu của phát triển ứng dụng hiện đại, chẳng hạn như quản lý phụ thuộc và gói, kiểm soát phiên bản, cập nhật rolling, khả năng tiến hóa, giám sát, số liệu, các lệnh gọi đến service mạng và tích hợp với các hệ thống bên ngoài.
Mặt khác, các công cụ triển khai và quản lý cluster như Kubernetes, Docker, Mesos, YARN và nhiều công cụ khác được thiết kế đặc biệt cho mục đích chạy mã ứng dụng. Bằng cách tập trung vào làm tốt một việc, chúng có thể làm điều đó tốt hơn nhiều so với cơ sở dữ liệu cung cấp thực thi của user-defined function như một trong nhiều tính năng của nó.
Hầu hết các ứng dụng web ngày nay được triển khai dưới dạng stateless service (dịch vụ không trạng thái), trong đó bất kỳ yêu cầu người dùng nào cũng có thể được định tuyến đến bất kỳ máy chủ ứng dụng nào, và máy chủ quên tất cả mọi thứ về yêu cầu sau khi nó đã gửi phản hồi. Kiểu triển khai này thuận tiện, vì máy chủ có thể được thêm hoặc xóa tùy ý, nhưng trạng thái phải đi đến đâu đó: thường là cơ sở dữ liệu. Xu hướng là giữ logic ứng dụng không trạng thái tách biệt khỏi quản lý trạng thái (cơ sở dữ liệu): không đặt logic ứng dụng trong cơ sở dữ liệu và không đặt trạng thái liên tục trong ứng dụng 25. Như những người trong cộng đồng lập trình hàm thích đùa, “Chúng tôi tin vào sự tách biệt của Church và state” (Church và nhà nước) 26.
Note
Giải thích một trò đùa thường làm hỏng nó, nhưng đây là giải thích dù sao để không ai cảm thấy bị bỏ lại. Church là tham chiếu đến nhà toán học Alonzo Church, người đã tạo ra lambda calculus, một dạng tính toán ban đầu là nền tảng cho hầu hết các ngôn ngữ lập trình hàm. Lambda calculus không có trạng thái có thể thay đổi (tức là không có biến có thể bị ghi đè), vì vậy người ta có thể nói rằng trạng thái có thể thay đổi là tách biệt khỏi công trình của Church.
Trong mô hình ứng dụng web điển hình này, cơ sở dữ liệu hoạt động như một loại biến chia sẻ có thể thay đổi có thể được truy cập đồng bộ qua mạng. Ứng dụng có thể đọc và cập nhật biến, và cơ sở dữ liệu đảm nhận việc làm cho nó bền, cung cấp một số kiểm soát đồng thời và khả năng chịu lỗi.
Tuy nhiên, trong hầu hết các ngôn ngữ lập trình, bạn không thể đăng ký các thay đổi trong một biến có thể thay đổi, bạn chỉ có thể đọc nó theo định kỳ. Không giống như trong bảng tính, người đọc biến không nhận được thông báo nếu giá trị của biến thay đổi. (Bạn có thể triển khai các thông báo như vậy trong mã của mình, điều này được gọi là observer pattern (mẫu quan sát viên), nhưng hầu hết các ngôn ngữ không có mẫu này như một tính năng tích hợp sẵn.)
Cơ sở dữ liệu đã kế thừa cách tiếp cận thụ động này đối với dữ liệu có thể thay đổi: nếu bạn muốn biết liệu nội dung của cơ sở dữ liệu có thay đổi hay không, thường tùy chọn duy nhất của bạn là poll (thăm dò, tức là lặp lại truy vấn của bạn theo định kỳ). Đăng ký các thay đổi chỉ mới bắt đầu xuất hiện như một tính năng.
Luồng dữ liệu: Sự tương tác giữa các thay đổi trạng thái và mã ứng dụng
Nghĩ về các ứng dụng theo nghĩa luồng dữ liệu ngụ ý việc tái đàm phán mối quan hệ giữa mã ứng dụng và quản lý trạng thái. Thay vì coi cơ sở dữ liệu như một biến thụ động được thao túng bởi ứng dụng, chúng ta nghĩ nhiều hơn về sự tương tác và cộng tác giữa trạng thái, các thay đổi trạng thái và mã xử lý chúng. Mã ứng dụng phản ứng với các thay đổi trạng thái ở một nơi bằng cách kích hoạt các thay đổi trạng thái ở nơi khác.
Chúng ta đã thấy ý tưởng này trong change data capture, trong mô hình actor, trong trigger và bảo trì materialized view tăng dần. Unbundling cơ sở dữ liệu có nghĩa là lấy ý tưởng này và áp dụng nó cho việc tạo ra các tập dữ liệu dẫn xuất bên ngoài cơ sở dữ liệu chính: cache, chỉ mục tìm kiếm toàn văn bản, machine learning hoặc hệ thống phân tích. Chúng ta có thể sử dụng xử lý stream và các hệ thống messaging cho mục đích này.
Duy trì dữ liệu dẫn xuất đòi hỏi các thuộc tính sau, mà message broker dựa trên log có thể cung cấp:
Khi duy trì dữ liệu dẫn xuất, thứ tự của các thay đổi trạng thái thường quan trọng (nếu nhiều khung nhìn được dẫn xuất từ một event log, chúng cần xử lý các sự kiện theo cùng thứ tự để chúng duy trì nhất quán với nhau).
Khả năng chịu lỗi là điều cần thiết: việc mất chỉ một tin nhắn khiến tập dữ liệu dẫn xuất bị lệch vĩnh viễn khỏi nguồn dữ liệu của nó. Cả việc giao tin nhắn lẫn cập nhật trạng thái dẫn xuất đều phải đáng tin cậy.
Sắp xếp tin nhắn ổn định và xử lý tin nhắn có khả năng chịu lỗi là các yêu cầu khá nghiêm ngặt, nhưng chúng ít tốn kém hơn và mạnh mẽ hơn về mặt vận hành so với distributed transactions. Các bộ xử lý stream hiện đại có thể cung cấp các đảm bảo thứ tự và độ tin cậy này ở quy mô lớn, và chúng cho phép mã ứng dụng chạy như các toán tử stream.
Mã ứng dụng này có thể thực hiện xử lý tùy ý mà các hàm dẫn xuất tích hợp trong cơ sở dữ liệu thường không cung cấp. Giống như các công cụ Unix được kết nối bằng pipe, các toán tử stream có thể được kết hợp để xây dựng các hệ thống lớn xung quanh luồng dữ liệu. Mỗi toán tử nhận các luồng thay đổi trạng thái làm đầu vào và tạo ra các luồng thay đổi trạng thái khác làm đầu ra.
Bộ xử lý stream và service
Phong cách phát triển ứng dụng hiện tại chủ yếu liên quan đến việc chia nhỏ chức năng thành một tập hợp các service giao tiếp qua các yêu cầu mạng đồng bộ như REST API. Ưu điểm của kiến trúc hướng service như vậy so với một ứng dụng monolithic (nguyên khối) duy nhất chủ yếu là khả năng mở rộng tổ chức thông qua loose coupling: các nhóm khác nhau có thể làm việc trên các service khác nhau, giúp giảm nỗ lực phối hợp giữa các nhóm (miễn là các service có thể được triển khai và cập nhật độc lập).
Kết hợp các toán tử stream thành các hệ thống luồng dữ liệu có nhiều đặc điểm tương tự như cách tiếp cận microservice 27, 28. Tuy nhiên, cơ chế giao tiếp cơ bản rất khác nhau: các luồng tin nhắn bất đồng bộ một chiều thay vì các tương tác request/response đồng bộ.
Ngoài các ưu điểm được liệt kê trong “Event-Driven Architectures”, chẳng hạn như khả năng chịu lỗi tốt hơn, các hệ thống luồng dữ liệu cũng có thể đạt được hiệu suất tốt hơn so với REST API hoặc RPC truyền thống. Ví dụ, giả sử một khách hàng đang mua một mặt hàng được định giá bằng một loại tiền tệ nhưng thanh toán bằng loại tiền tệ khác. Để thực hiện chuyển đổi tiền tệ, bạn cần biết tỷ giá hối đoái hiện tại. Thao tác này có thể được triển khai theo hai cách 27, 29:
Trong cách tiếp cận microservice, mã xử lý giao dịch mua có thể sẽ truy vấn một service tỷ giá hối đoái hoặc cơ sở dữ liệu để lấy tỷ giá hiện tại cho một loại tiền tệ cụ thể.
Trong cách tiếp cận luồng dữ liệu, mã xử lý giao dịch mua sẽ đăng ký vào một luồng cập nhật tỷ giá hối đoái trước, và ghi lại tỷ giá hiện tại trong một cơ sở dữ liệu cục bộ bất cứ khi nào nó thay đổi. Khi đến lúc xử lý giao dịch mua, nó chỉ cần truy vấn cơ sở dữ liệu cục bộ.
Cách tiếp cận thứ hai đã thay thế một yêu cầu mạng đồng bộ đến một service khác bằng một truy vấn đến cơ sở dữ liệu cục bộ (có thể trên cùng một máy, thậm chí trong cùng một tiến trình). Trong cách tiếp cận microservice, bạn có thể tránh yêu cầu mạng đồng bộ bằng cách cache tỷ giá hối đoái cục bộ trong service xử lý giao dịch mua. Tuy nhiên, để giữ cho cache đó được cập nhật, bạn sẽ cần poll định kỳ để lấy tỷ giá hối đoái cập nhật, hoặc đăng ký vào một luồng thay đổi, đó chính xác là những gì xảy ra trong cách tiếp cận luồng dữ liệu.
Không chỉ cách tiếp cận luồng dữ liệu nhanh hơn, mà nó còn mạnh mẽ hơn đối với sự cố của một service khác. Yêu cầu mạng nhanh nhất và đáng tin cậy nhất là không có yêu cầu mạng nào cả! Thay vì RPC, chúng ta bây giờ có một stream join giữa các sự kiện mua hàng và các sự kiện cập nhật tỷ giá hối đoái.
Phép join phụ thuộc vào thời gian: nếu các sự kiện mua hàng được tái xử lý vào một thời điểm sau đó, tỷ giá hối đoái sẽ thay đổi. Nếu bạn muốn tái tạo lại đầu ra gốc, bạn sẽ cần lấy tỷ giá hối đoái lịch sử vào thời điểm gốc của giao dịch mua. Bất kể bạn truy vấn một service hay đăng ký vào một luồng cập nhật tỷ giá hối đoái, bạn sẽ cần xử lý sự phụ thuộc vào thời gian này (xem “Time-dependence of joins”).
Đăng ký vào một luồng thay đổi, thay vì truy vấn trạng thái hiện tại khi cần, đưa chúng ta gần hơn với mô hình tính toán giống như bảng tính: khi một phần dữ liệu thay đổi, bất kỳ dữ liệu dẫn xuất nào phụ thuộc vào nó có thể được cập nhật nhanh chóng. Vẫn còn nhiều câu hỏi mở, ví dụ xung quanh các vấn đề như phép join phụ thuộc vào thời gian, nhưng xây dựng ứng dụng xung quanh các ý tưởng luồng dữ liệu là một hướng rất hứa hẹn để khám phá.
Quan Sát Trạng Thái Dẫn Xuất
Ở cấp độ trừu tượng, các hệ thống luồng dữ liệu được thảo luận trong phần cuối cùng cung cấp cho bạn một quy trình để tạo ra các tập dữ liệu dẫn xuất (chẳng hạn như chỉ mục tìm kiếm, materialized view và các mô hình dự đoán) và giữ chúng cập nhật. Hãy gọi quy trình đó là write path (đường ghi): bất cứ khi nào một phần thông tin được ghi vào hệ thống, nó có thể đi qua nhiều giai đoạn xử lý batch và stream, và cuối cùng mọi tập dữ liệu dẫn xuất đều được cập nhật để kết hợp dữ liệu đã được ghi. Hình 13-1 cho thấy một ví dụ về cập nhật chỉ mục tìm kiếm.
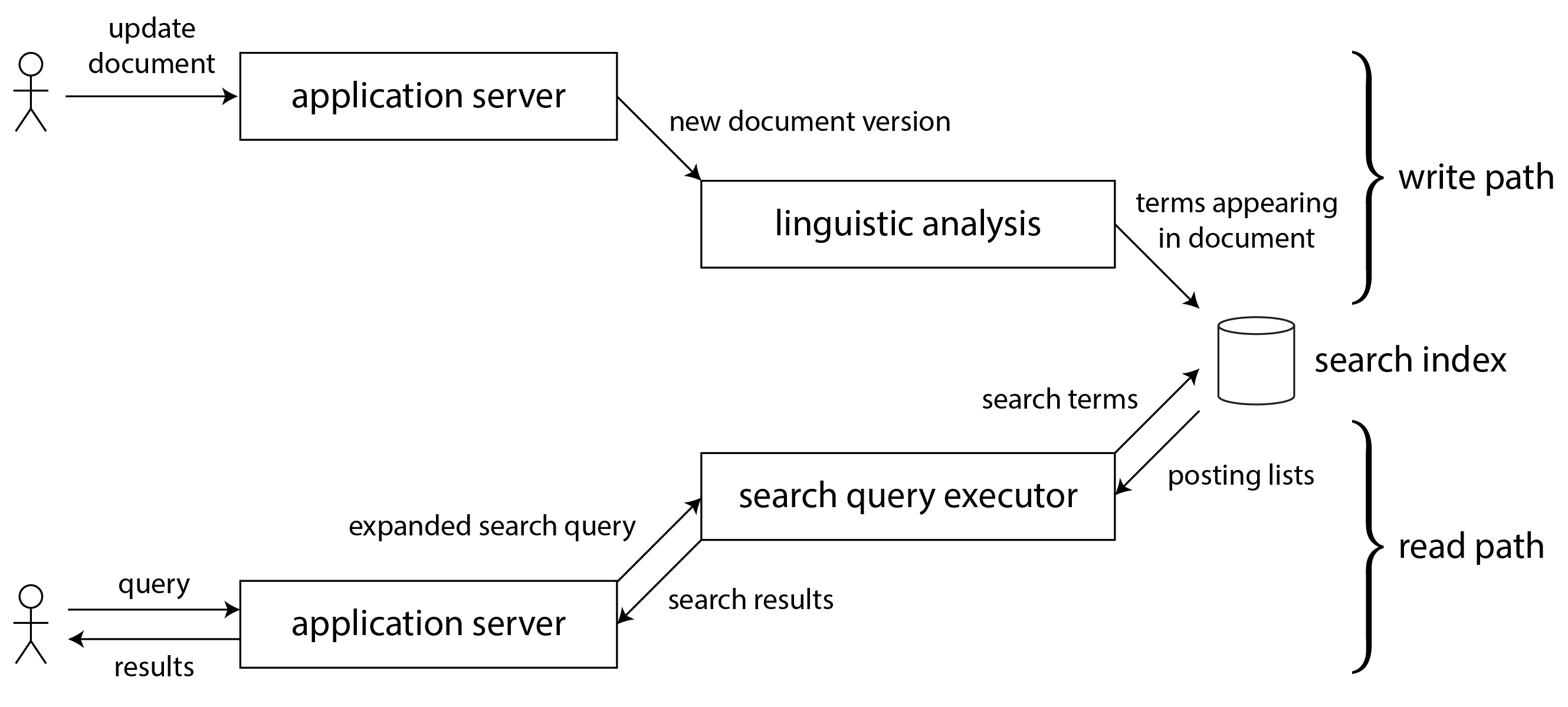
Nhưng tại sao bạn tạo ra tập dữ liệu dẫn xuất ở vị trí đầu tiên? Rất có thể vì bạn muốn truy vấn nó lại vào một thời điểm sau đó. Đây là read path (đường đọc): khi phục vụ một yêu cầu người dùng, bạn đọc từ tập dữ liệu dẫn xuất, có thể thực hiện thêm một số xử lý trên các kết quả, và xây dựng phản hồi cho người dùng.
Cùng nhau, write path và read path bao gồm toàn bộ hành trình của dữ liệu, từ điểm nơi nó được thu thập đến điểm nơi nó được tiêu thụ (có lẽ bởi một con người khác). Write path là phần hành trình được tính trước, tức là được thực hiện một cách hăng hái ngay khi dữ liệu đến, bất kể liệu có ai đã yêu cầu xem nó hay không. Read path là phần hành trình chỉ xảy ra khi ai đó yêu cầu nó. Nếu bạn quen thuộc với các ngôn ngữ lập trình hàm, bạn có thể nhận thấy rằng write path tương tự như đánh giá hăng hái (eager evaluation), và read path tương tự như đánh giá lười biếng (lazy evaluation).
Tập dữ liệu dẫn xuất là nơi write path và read path gặp nhau, như được minh họa trong Hình 13-1. Nó đại diện cho một sự đánh đổi giữa lượng công việc cần thực hiện vào thời điểm ghi và lượng cần thực hiện vào thời điểm đọc.
Materialized view và caching
Chỉ mục tìm kiếm toàn văn bản là một ví dụ tốt: write path cập nhật chỉ mục, và read path tìm kiếm chỉ mục cho các từ khóa. Cả đọc lẫn ghi đều cần thực hiện một số công việc. Ghi cần cập nhật các mục chỉ mục cho tất cả các term xuất hiện trong tài liệu. Đọc cần tìm kiếm từng từ trong truy vấn, và áp dụng logic Boolean để tìm các tài liệu chứa tất cả các từ trong truy vấn (toán tử AND), hoặc bất kỳ từ đồng nghĩa nào của mỗi từ (toán tử OR).
Nếu bạn không có chỉ mục, một truy vấn tìm kiếm sẽ phải quét qua tất cả các tài liệu (giống như grep), điều này sẽ trở nên rất tốn kém nếu bạn có nhiều tài liệu. Không có chỉ mục có nghĩa là ít công việc hơn trên write path (không có chỉ mục để cập nhật), nhưng nhiều công việc hơn trên read path.
Mặt khác, bạn có thể tưởng tượng việc tính trước kết quả tìm kiếm cho tất cả các truy vấn có thể. Trong trường hợp đó, bạn sẽ có ít công việc hơn để làm trên read path: không có logic Boolean, chỉ cần tìm kết quả cho truy vấn của bạn và trả về chúng. Tuy nhiên, write path sẽ đắt hơn nhiều: tập hợp các truy vấn tìm kiếm có thể được hỏi là vô hạn (hoặc ít nhất là lũy thừa theo số lượng term trong corpus), và do đó việc tính trước tất cả các kết quả tìm kiếm có thể sẽ không thể thực hiện được.
Một lựa chọn khác sẽ là tính trước kết quả tìm kiếm chỉ cho một tập cố định các truy vấn phổ biến nhất, để chúng có thể được phục vụ nhanh chóng mà không cần đến chỉ mục. Các truy vấn không phổ biến vẫn có thể được phục vụ từ chỉ mục. Điều này thường được gọi là cache của các truy vấn phổ biến, mặc dù chúng ta cũng có thể gọi nó là materialized view, vì nó sẽ cần được cập nhật khi các tài liệu mới xuất hiện cần được đưa vào kết quả của một trong các truy vấn phổ biến.
Từ ví dụ này, chúng ta có thể thấy rằng chỉ mục không phải là ranh giới duy nhất có thể giữa write path và read path. Caching của các kết quả tìm kiếm phổ biến là có thể, và quét kiểu grep không có chỉ mục cũng có thể trên một số lượng nhỏ tài liệu. Nhìn theo cách này, vai trò của cache, chỉ mục và materialized view rất đơn giản: chúng dịch chuyển ranh giới giữa read path và write path. Chúng cho phép chúng ta làm thêm công việc trên write path, bằng cách tính trước kết quả, để tiết kiệm nỗ lực trên read path.
Dịch chuyển ranh giới giữa công việc được thực hiện trên write path và read path thực ra là chủ đề của ví dụ mạng xã hội trong “Case Study: Social Network Home Timelines”. Trong ví dụ đó, chúng ta cũng thấy cách ranh giới giữa write path và read path có thể được vẽ khác nhau cho những người nổi tiếng so với người dùng thông thường. Sau 500 trang chúng ta đã đi một vòng tròn đầy đủ!
Client có trạng thái, có khả năng hoạt động offline
Ý tưởng về ranh giới giữa write path và read path thú vị vì chúng ta có thể thảo luận về việc dịch chuyển ranh giới đó và khám phá ý nghĩa thực tế của sự dịch chuyển đó. Hãy nhìn vào ý tưởng trong một bối cảnh khác.
Trong quá khứ, trình duyệt web là các client không trạng thái chỉ có thể làm những việc hữu ích khi bạn có kết nối internet (về cơ bản điều duy nhất bạn có thể làm khi offline là cuộn lên và xuống trong một trang mà bạn đã tải trước đó khi online). Tuy nhiên, các ứng dụng web JavaScript single-page hiện có nhiều khả năng có trạng thái, bao gồm tương tác giao diện người dùng phía client và lưu trữ cục bộ liên tục trong trình duyệt web. Các ứng dụng di động cũng có thể lưu trữ nhiều trạng thái trên thiết bị và không yêu cầu round-trip đến máy chủ cho hầu hết các tương tác người dùng.
Trong “Sync Engines and Local-First Software” chúng ta đã thấy cách trạng thái cục bộ liên tục cho phép một lớp ứng dụng trong đó người dùng có thể làm việc offline, không có kết nối internet, và đồng bộ với các máy chủ từ xa trong nền khi có kết nối mạng 30. Vì các thiết bị di động đôi khi có kết nối internet di động chậm và không đáng tin cậy, đây là một lợi thế lớn cho người dùng nếu giao diện người dùng của họ không phải chờ các yêu cầu mạng đồng bộ, và nếu các ứng dụng chủ yếu hoạt động offline.
Khi chúng ta bỏ qua giả định về client không trạng thái giao tiếp với một cơ sở dữ liệu trung tâm và hướng đến trạng thái được duy trì trên các thiết bị người dùng cuối, một thế giới cơ hội mới mở ra. Cụ thể, chúng ta có thể nghĩ về trạng thái trên thiết bị như là cache của trạng thái trên máy chủ. Các pixel trên màn hình là một materialized view trên các đối tượng mô hình trong ứng dụng client; các đối tượng mô hình là một bản sao cục bộ của trạng thái trong một trung tâm dữ liệu từ xa 31.
Đẩy các thay đổi trạng thái đến client
Trong một trang web thông thường, nếu bạn tải trang trong trình duyệt web và dữ liệu sau đó thay đổi trên máy chủ, trình duyệt không biết về thay đổi cho đến khi bạn tải lại trang. Trình duyệt chỉ đọc dữ liệu tại một thời điểm, giả định rằng nó là tĩnh, nó không đăng ký các cập nhật từ máy chủ. Do đó, trạng thái trong trình duyệt là một cache lỗi thời không được cập nhật trừ khi bạn poll rõ ràng để tìm kiếm các thay đổi. (Các giao thức đăng ký feed dựa trên HTTP như RSS thực sự chỉ là một dạng polling cơ bản.)
Các giao thức gần đây hơn đã vượt qua mẫu request/response cơ bản của HTTP: server-sent event (EventSource API) và WebSocket cung cấp các kênh giao tiếp mà qua đó một trình duyệt web có thể giữ một kết nối TCP mở đến một máy chủ, và máy chủ có thể chủ động đẩy tin nhắn đến trình duyệt miễn là nó vẫn được kết nối. Điều này cung cấp cơ hội cho máy chủ chủ động thông báo cho client người dùng cuối về bất kỳ thay đổi nào đối với trạng thái mà nó đã lưu trữ cục bộ, giảm độ trễ của trạng thái phía client.
Theo mô hình write path và read path của chúng ta, chủ động đẩy các thay đổi trạng thái tất cả con đường đến các thiết bị client có nghĩa là mở rộng write path tất cả con đường đến người dùng cuối. Khi một client được khởi tạo lần đầu tiên, nó vẫn cần sử dụng read path để lấy trạng thái ban đầu của mình, nhưng sau đó nó có thể dựa vào một luồng thay đổi trạng thái được gửi bởi máy chủ. Các ý tưởng chúng ta đã thảo luận về xử lý stream và messaging không bị giới hạn chỉ chạy trong một trung tâm dữ liệu: chúng ta có thể đưa các ý tưởng xa hơn, và mở rộng chúng tất cả con đường đến các thiết bị người dùng cuối 32.
Các thiết bị sẽ offline trong một số thời gian, và không thể nhận bất kỳ thông báo nào về các thay đổi trạng thái từ máy chủ trong thời gian đó. Nhưng chúng ta đã giải quyết vấn đề đó: trong “Consumer offsets” chúng ta đã thảo luận về cách một consumer của message broker dựa trên log có thể kết nối lại sau khi thất bại hoặc bị ngắt kết nối, và đảm bảo rằng nó không bỏ lỡ bất kỳ tin nhắn nào đến trong khi nó bị ngắt kết nối. Kỹ thuật tương tự hoạt động cho từng người dùng riêng lẻ, trong đó mỗi thiết bị là một subscriber nhỏ đến một luồng sự kiện nhỏ.
Luồng sự kiện end-to-end
Các công cụ để phát triển client và giao diện người dùng có trạng thái, chẳng hạn như React và Elm 33, đã có khả năng cập nhật giao diện người dùng được hiển thị để phản ứng với các thay đổi trong trạng thái cơ bản. Sẽ rất tự nhiên khi mở rộng mô hình lập trình này để cũng cho phép máy chủ đẩy các sự kiện thay đổi trạng thái vào đường ống sự kiện phía client này.
Do đó, các thay đổi trạng thái có thể chảy qua một write path end-to-end: từ sự tương tác trên một thiết bị kích hoạt thay đổi trạng thái, qua các event log và qua nhiều hệ thống dữ liệu dẫn xuất và bộ xử lý stream, tất cả con đường đến giao diện người dùng của một người quan sát trạng thái trên một thiết bị khác. Các thay đổi trạng thái này có thể được lan truyền với độ trễ khá thấp, ví dụ dưới một giây end-to-end.
Một số ứng dụng, chẳng hạn như nhắn tin tức thời và trò chơi online, đã có kiến trúc “real-time” như vậy (theo nghĩa là các tương tác có độ trễ thấp, không phải theo nghĩa là đảm bảo thời gian phản hồi). Nhưng tại sao chúng ta không xây dựng tất cả các ứng dụng theo cách này?
Thách thức là giả định về client không trạng thái và các tương tác request/response đã ăn sâu vào cơ sở dữ liệu, thư viện, framework và giao thức của chúng ta. Nhiều datastore hỗ trợ các thao tác đọc và ghi trong đó một yêu cầu trả về một phản hồi, nhưng ít hơn nhiều cung cấp khả năng đăng ký các thay đổi, tức là một yêu cầu trả về một luồng phản hồi theo thời gian.
Để mở rộng write path tất cả con đường đến người dùng cuối, chúng ta cần phải suy nghĩ lại một cách cơ bản về cách chúng ta xây dựng nhiều hệ thống này: di chuyển khỏi tương tác request/response và hướng đến luồng dữ liệu publish/subscribe 31. Điều này sẽ đòi hỏi nỗ lực, nhưng nó sẽ có lợi thế là làm cho giao diện người dùng phản hồi hơn và cung cấp hỗ trợ offline tốt hơn.
Đọc cũng là sự kiện
Chúng ta đã thảo luận rằng khi một bộ xử lý stream ghi dữ liệu dẫn xuất vào một kho (cơ sở dữ liệu, cache hoặc chỉ mục), và kho đó được truy vấn, kho đó hoạt động như ranh giới giữa write path và read path. Kho cho phép các truy vấn đọc truy cập ngẫu nhiên đến dữ liệu mà nếu không sẽ đòi hỏi quét toàn bộ event log.
Trong nhiều trường hợp, lưu trữ dữ liệu tách biệt với hệ thống streaming. Nhưng hãy nhớ rằng các bộ xử lý stream cũng cần duy trì trạng thái để thực hiện các tổng hợp và join. Trạng thái này thường được ẩn bên trong bộ xử lý stream, nhưng một số framework cho phép nó cũng được truy vấn bởi các client bên ngoài 34, biến bộ xử lý stream thành một loại cơ sở dữ liệu đơn giản.
Hãy đưa ý tưởng đó xa hơn. Như đã thảo luận cho đến nay, các ghi vào kho đi qua một event log, trong khi các đọc là các yêu cầu mạng thoáng qua đến trực tiếp các nút lưu trữ dữ liệu đang được truy vấn. Đây là một thiết kế hợp lý, nhưng không phải là thiết kế duy nhất có thể. Cũng có thể biểu diễn các yêu cầu đọc như là các luồng sự kiện, và gửi cả sự kiện đọc lẫn sự kiện ghi qua một bộ xử lý stream; bộ xử lý phản hồi các sự kiện đọc bằng cách phát ra kết quả của việc đọc vào một luồng đầu ra 35.
Khi cả ghi lẫn đọc được biểu diễn dưới dạng sự kiện, và được định tuyến đến cùng một toán tử stream để được xử lý, trên thực tế chúng ta đang thực hiện một stream-table join giữa luồng các truy vấn đọc và cơ sở dữ liệu. Sự kiện đọc cần được gửi đến phân mảnh cơ sở dữ liệu chứa dữ liệu, giống như các bộ xử lý batch và stream cần copartition các đầu vào trên cùng một khóa khi thực hiện join.
Sự tương ứng giữa phục vụ yêu cầu và thực hiện join là khá cơ bản 36. Một yêu cầu đọc một lần đi qua toán tử join, sau đó ngay lập tức quên yêu cầu; một yêu cầu đăng ký là một join liên tục với các sự kiện quá khứ và tương lai ở phía kia của join.
Ghi lại một log của các sự kiện đọc tiềm năng cũng có lợi ích về việc theo dõi các phụ thuộc nhân quả và nguồn gốc dữ liệu trên toàn hệ thống: nó sẽ cho phép bạn tái tạo lại những gì người dùng đã thấy trước khi họ đưa ra một quyết định cụ thể. Ví dụ, trong một cửa hàng online, rất có thể đã thấy trước khi họ đưa ra một quyết định cụ thể. Ví dụ, trong một cửa hàng trực tuyến, rất có thể ngày giao hàng dự kiến và tình trạng tồn kho được hiển thị cho khách hàng sẽ ảnh hưởng đến việc họ có chọn mua mặt hàng đó hay không 4. Để phân tích mối liên hệ này, bạn cần ghi lại kết quả truy vấn của người dùng về trạng thái vận chuyển và tồn kho.
Việc ghi các yêu cầu đọc vào bộ lưu trữ bền vững giúp theo dõi các phụ thuộc nhân quả tốt hơn, nhưng nó phát sinh thêm chi phí lưu trữ và I/O. Việc tối ưu hóa các hệ thống như vậy để giảm chi phí vẫn còn là một bài toán nghiên cứu mở 2. Tuy nhiên, nếu bạn đã ghi nhật ký các yêu cầu đọc vì mục đích vận hành, như một hiệu ứng phụ của quá trình xử lý yêu cầu, thì việc biến nhật ký thành nguồn gốc của các yêu cầu thay vì chỉ là nơi ghi chép cũng không phải là thay đổi quá lớn.
Xử lý dữ liệu trên nhiều shard
Đối với các truy vấn chỉ tác động đến một shard duy nhất, nỗ lực gửi truy vấn qua một luồng (stream) và thu thập một luồng phản hồi có lẽ là quá mức cần thiết. Tuy nhiên, ý tưởng này mở ra khả năng thực thi phân tán các truy vấn phức tạp cần kết hợp dữ liệu từ nhiều shard, tận dụng cơ sở hạ tầng định tuyến thông điệp, sharding và join đã được cung cấp sẵn bởi các bộ xử lý luồng (stream processors).
Tính năng distributed RPC (gọi thủ tục từ xa phân tán) của Storm hỗ trợ mẫu sử dụng này. Ví dụ, nó đã được dùng để tính số người đã xem một URL trên mạng xã hội, tức là phần hợp của tập hợp người theo dõi của tất cả những ai đã đăng URL đó 37. Vì tập người dùng được phân shard, phép tính này yêu cầu kết hợp kết quả từ nhiều shard.
Một ví dụ khác về mẫu này xuất hiện trong phòng chống gian lận: để đánh giá rủi ro của một sự kiện mua hàng cụ thể có phải là gian lận hay không, bạn có thể xem xét điểm danh tiếng của địa chỉ IP, địa chỉ email, địa chỉ thanh toán, địa chỉ giao hàng của người dùng, v.v. Mỗi cơ sở dữ liệu danh tiếng này được phân shard, và do đó việc thu thập điểm số cho một sự kiện mua hàng cụ thể đòi hỏi một chuỗi các phép join với các tập dữ liệu được phân shard theo các cách khác nhau 38.
Các đồ thị thực thi truy vấn nội bộ của các công cụ truy vấn kho dữ liệu có các đặc điểm tương tự. Nếu bạn cần thực hiện loại join đa shard này, thì sử dụng một cơ sở dữ liệu cung cấp tính năng này có lẽ đơn giản hơn so với tự triển khai bằng bộ xử lý luồng. Tuy nhiên, việc coi các truy vấn như các luồng cung cấp một lựa chọn để triển khai các ứng dụng quy mô lớn vượt ra ngoài giới hạn của các giải pháp thông thường có sẵn trên thị trường.
Hướng tới Tính Đúng Đắn
Với các dịch vụ phi trạng thái (stateless) chỉ đọc dữ liệu, nếu có sự cố xảy ra thì không phải là vấn đề lớn: bạn có thể sửa lỗi, khởi động lại dịch vụ, và mọi thứ trở lại bình thường. Các hệ thống có trạng thái (stateful) như cơ sở dữ liệu không đơn giản như vậy: chúng được thiết kế để ghi nhớ mọi thứ mãi mãi (nhiều hay ít), nên nếu có sự cố xảy ra, hậu quả cũng có thể kéo dài mãi mãi, điều đó có nghĩa là chúng đòi hỏi sự suy nghĩ cẩn thận hơn 39.
Chúng ta muốn xây dựng các ứng dụng đáng tin cậy và chính xác (tức là, các chương trình có ngữ nghĩa được định nghĩa và hiểu rõ ràng, ngay cả khi đối mặt với các lỗi khác nhau). Trong khoảng bốn thập kỷ qua, các thuộc tính giao dịch (transaction) về tính nguyên tử (atomicity), cô lập (isolation) và bền vững (durability) là các công cụ được lựa chọn để xây dựng các ứng dụng đúng đắn. Tuy nhiên, những nền tảng đó yếu hơn vẻ bề ngoài: hãy xem ví dụ về sự nhầm lẫn của các mức độ cô lập yếu (xem “Các Mức Độ Cô Lập Yếu”).
Trong một số lĩnh vực, các giao dịch đã bị từ bỏ hoàn toàn và được thay thế bằng các mô hình cung cấp hiệu suất và khả năng mở rộng tốt hơn, nhưng ngữ nghĩa lại lộn xộn hơn nhiều. Tính nhất quán (Consistency) thường được đề cập đến, nhưng được định nghĩa một cách mơ hồ. Một số người khẳng định rằng chúng ta nên “chấp nhận tính nhất quán yếu” vì lợi ích của tính khả dụng tốt hơn, trong khi thiếu ý tưởng rõ ràng về điều đó thực sự có nghĩa gì trong thực tế.
Đối với một chủ đề quan trọng như vậy, sự hiểu biết và các phương pháp kỹ thuật của chúng ta lại đáng ngạc nhiên là không vững chắc. Ví dụ, rất khó để xác định liệu có an toàn hay không khi chạy một ứng dụng cụ thể ở một mức độ cô lập giao dịch nhất định hoặc cấu hình nhân bản nhất định 40, 41. Thường các giải pháp đơn giản có vẻ hoạt động đúng khi mức độ đồng thời thấp và không có lỗi, nhưng hóa ra lại có nhiều lỗi tinh tế hơn trong các điều kiện khắt khe hơn.
Ví dụ, các thí nghiệm Jepsen của Kyle Kingsbury 42 đã làm nổi bật sự khác biệt rõ rệt giữa các đảm bảo an toàn được tuyên bố của một số sản phẩm và hành vi thực tế của chúng khi có sự cố mạng và sự cố hệ thống. Ngay cả khi các sản phẩm cơ sở hạ tầng như cơ sở dữ liệu không có vấn đề, mã ứng dụng vẫn cần sử dụng đúng các tính năng chúng cung cấp, điều này dễ gây ra lỗi nếu cấu hình khó hiểu (như trường hợp với các mức cô lập yếu, cấu hình quorum, v.v.).
Nếu ứng dụng của bạn có thể chịu đựng việc đôi khi làm hỏng hoặc mất dữ liệu theo những cách không thể đoán trước, cuộc sống sẽ đơn giản hơn nhiều, và bạn có thể thoát khỏi tình huống chỉ bằng cách bắt chéo ngón tay và hy vọng vào điều tốt nhất. Mặt khác, nếu bạn cần các đảm bảo về tính đúng đắn mạnh hơn, thì serializability (khả năng tuần tự hóa) và atomic commit (cam kết nguyên tử) là các cách tiếp cận đã được thiết lập, nhưng chúng đi kèm với một cái giá: chúng thường chỉ hoạt động trong một datacenter duy nhất (loại trừ các kiến trúc phân tán theo địa lý), và chúng giới hạn quy mô và các thuộc tính chịu lỗi bạn có thể đạt được.
Mặc dù cách tiếp cận giao dịch truyền thống sẽ không biến mất, nhưng đó không phải là lời nói cuối cùng trong việc làm cho các ứng dụng đúng đắn và có khả năng phục hồi trước các lỗi. Trong phần này, chúng ta sẽ khám phá một số cách suy nghĩ về tính đúng đắn trong bối cảnh kiến trúc luồng dữ liệu (dataflow architectures).
Luận điểm Đầu cuối đến Đầu cuối cho Cơ sở Dữ liệu
Chỉ vì một ứng dụng sử dụng hệ thống dữ liệu cung cấp các thuộc tính an toàn tương đối mạnh, chẳng hạn như giao dịch serializable, không có nghĩa là ứng dụng đó được đảm bảo không bị mất dữ liệu hay hỏng dữ liệu. Ví dụ, nếu một ứng dụng có lỗi khiến nó ghi dữ liệu không chính xác, hoặc xóa dữ liệu khỏi cơ sở dữ liệu, thì các giao dịch serializable sẽ không cứu được bạn. Đây là một lập luận ủng hộ dữ liệu bất biến (immutable) và chỉ thêm (append-only), vì sẽ dễ dàng hơn để phục hồi từ những sai lầm như vậy nếu bạn loại bỏ khả năng của mã bị lỗi phá hủy dữ liệu tốt.
Mặc dù tính bất biến rất hữu ích, nhưng bản thân nó không phải là phương thuốc chữa bách bệnh. Hãy xem xét một ví dụ tinh tế hơn về hỏng dữ liệu có thể xảy ra.
Thực thi đúng một lần của một thao tác
Trong “Khả năng Chịu Lỗi”, chúng ta đã gặp ngữ nghĩa exactly-once (chính xác một lần, còn gọi là effectively-once, hiệu quả một lần). Nếu có sự cố xảy ra trong khi xử lý một thông điệp, bạn có thể từ bỏ (bỏ thông điệp, tức là chịu mất dữ liệu) hoặc thử lại. Nếu bạn thử lại, có rủi ro là nó thực sự đã thành công lần đầu tiên, nhưng bạn không biết về sự thành công đó, và vì vậy thông điệp bị xử lý hai lần.
Xử lý hai lần là một dạng hỏng dữ liệu: điều không mong muốn là tính phí khách hàng hai lần cho cùng một dịch vụ (tính quá nhiều) hoặc tăng một bộ đếm hai lần (làm phóng đại một số liệu nào đó). Trong bối cảnh này, exactly-once có nghĩa là sắp xếp phép tính sao cho kết quả cuối cùng giống như thể không có lỗi nào xảy ra, ngay cả khi thao tác thực sự đã được thử lại do một số lỗi. Chúng ta đã thảo luận một số cách tiếp cận để đạt được mục tiêu này trước đó.
Một trong những cách tiếp cận hiệu quả nhất là làm cho thao tác idempotent (bất biến, tức là có cùng kết quả dù thực thi một hay nhiều lần). Tuy nhiên, việc lấy một thao tác không tự nhiên là idempotent và làm cho nó idempotent đòi hỏi một số nỗ lực và cẩn thận: bạn có thể cần duy trì một số metadata bổ sung (chẳng hạn như tập hợp các ID thao tác đã cập nhật một giá trị), và đảm bảo fencing (hàng rào bảo vệ) khi chuyển đổi từ một node này sang node khác (xem “Khóa và Hợp đồng Thuê Phân tán”).
Ngăn chặn trùng lặp
Mẫu cần ngăn chặn trùng lặp này xuất hiện ở nhiều nơi khác bên cạnh xử lý luồng. Ví dụ, TCP sử dụng số thứ tự trên các gói tin để đặt chúng vào đúng thứ tự ở đầu nhận, và để xác định liệu có gói tin nào bị mất hoặc bị trùng lặp trên mạng hay không. Các gói bị mất được truyền lại và bất kỳ gói trùng lặp nào đều được ngăn xếp TCP loại bỏ trước khi chuyển dữ liệu cho ứng dụng.
Tuy nhiên, việc ngăn chặn trùng lặp này chỉ hoạt động trong bối cảnh của một kết nối TCP duy nhất. Hãy tưởng tượng kết nối TCP là kết nối của máy khách đến cơ sở dữ liệu, và nó đang thực thi giao dịch trong Ví dụ 13-1. Trong nhiều cơ sở dữ liệu, một giao dịch được gắn với kết nối máy khách (nếu máy khách gửi nhiều truy vấn, cơ sở dữ liệu biết rằng chúng thuộc về cùng một giao dịch vì chúng được gửi trên cùng một kết nối TCP). Nếu máy khách bị gián đoạn mạng và hết thời gian kết nối sau khi gửi COMMIT, nhưng trước khi nhận được phản hồi từ máy chủ cơ sở dữ liệu, nó không biết liệu giao dịch đã được commit hay bị hủy bỏ (Hình 9-1).
Ví dụ 13-1. Một phép chuyển tiền không idempotent từ tài khoản này sang tài khoản khác
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance + 11.00 WHERE account_id = 1234;
UPDATE accounts SET balance = balance - 11.00 WHERE account_id = 4321;
COMMIT;Máy khách có thể kết nối lại với cơ sở dữ liệu và thử lại giao dịch, nhưng bây giờ nó nằm ngoài phạm vi của tính năng ngăn chặn trùng lặp của TCP. Vì giao dịch trong Ví dụ 13-1 không phải idempotent, có thể xảy ra trường hợp $22 bị chuyển thay vì $11 như mong muốn. Vì vậy, mặc dù Ví dụ 13-1 là một ví dụ chuẩn về tính nguyên tử giao dịch, nhưng thực ra nó không đúng, và các ngân hàng thực sự không hoạt động như vậy 3.
Các giao thức two-phase commit, tức là cam kết hai giai đoạn (xem “Two-Phase Commit (2PC)”) phá vỡ ánh xạ 1:1 giữa kết nối TCP và giao dịch, vì chúng phải cho phép một bộ điều phối giao dịch (transaction coordinator) kết nối lại với cơ sở dữ liệu sau một sự cố mạng, và thông báo cho nó nên commit hay hủy bỏ một giao dịch đang trong trạng thái không chắc chắn. Điều này có đủ để đảm bảo rằng giao dịch sẽ chỉ được thực thi một lần không? Thật không may là không.
Ngay cả khi chúng ta có thể ngăn chặn các giao dịch trùng lặp giữa máy khách và máy chủ cơ sở dữ liệu, chúng ta vẫn cần lo lắng về mạng giữa thiết bị đầu cuối của người dùng và máy chủ ứng dụng. Ví dụ, nếu máy khách đầu cuối của người dùng là trình duyệt web, nó có thể sử dụng yêu cầu HTTP POST để gửi lệnh đến máy chủ. Có lẽ người dùng đang dùng kết nối dữ liệu di động yếu, và họ thành công trong việc gửi POST, nhưng tín hiệu trở nên quá yếu trước khi họ có thể nhận được phản hồi từ máy chủ.
Trong trường hợp này, người dùng có thể sẽ thấy thông báo lỗi, và họ có thể thử lại thủ công. Trình duyệt web cảnh báo: “Bạn có chắc muốn gửi lại biểu mẫu này không?”, và người dùng chọn có, vì họ muốn thao tác xảy ra. (Mẫu Post/Redirect/Get 43 tránh được thông báo cảnh báo này trong hoạt động bình thường, nhưng nó không giúp ích gì nếu yêu cầu POST hết thời gian chờ.) Từ góc độ của máy chủ web, lần thử lại là một yêu cầu riêng biệt, và từ góc độ của cơ sở dữ liệu, đó là một giao dịch riêng biệt. Các cơ chế khử trùng lặp thông thường không giúp ích gì.
Nhận dạng duy nhất các yêu cầu
Để làm cho yêu cầu idempotent qua nhiều bước truyền thông mạng, không đủ khi chỉ dựa vào cơ chế giao dịch được cung cấp bởi cơ sở dữ liệu, mà bạn cần xem xét luồng đầu cuối đến đầu cuối (end-to-end) của yêu cầu.
Ví dụ, bạn có thể tạo một định danh duy nhất cho một yêu cầu (chẳng hạn như UUID) và đưa nó vào như một trường ẩn trong ứng dụng máy khách, hoặc tính toán một hash của tất cả các trường biểu mẫu liên quan để lấy ra ID yêu cầu 3. Nếu trình duyệt web gửi yêu cầu POST hai lần, hai yêu cầu sẽ có cùng ID yêu cầu. Sau đó bạn có thể chuyển ID yêu cầu đó đến tận cơ sở dữ liệu và kiểm tra rằng bạn chỉ thực thi một yêu cầu với một ID nhất định, như được hiển thị trong Ví dụ 13-2.
Ví dụ 13-2. Ngăn chặn các yêu cầu trùng lặp bằng ID duy nhất
ALTER TABLE requests ADD UNIQUE (request_id);
BEGIN TRANSACTION;
INSERT INTO requests
(request_id, from_account, to_account, amount)
VALUES('0286FDB8-D7E1-423F-B40B-792B3608036C', 4321, 1234, 11.00);
UPDATE accounts SET balance = balance + 11.00 WHERE account_id = 1234;
UPDATE accounts SET balance = balance - 11.00 WHERE account_id = 4321;
COMMIT;Ví dụ 13-2 dựa vào ràng buộc duy nhất (uniqueness constraint) trên cột request_id. Nếu một giao dịch cố gắng chèn một ID đã tồn tại, thao tác INSERT sẽ thất bại và giao dịch bị hủy bỏ, ngăn nó không có hiệu lực hai lần. Các cơ sở dữ liệu quan hệ thường có thể duy trì ràng buộc duy nhất một cách chính xác, ngay cả ở các mức cô lập yếu (trong khi việc kiểm tra rồi chèn ở mức ứng dụng có thể thất bại khi không có serializable isolation, như đã thảo luận trong “Lệch Ghi và Phantom”).
Ngoài việc ngăn chặn các yêu cầu trùng lặp, bảng requests trong Ví dụ 13-2 còn đóng vai trò như một loại nhật ký sự kiện (event log), có thể hữu ích cho event sourcing (nguồn sự kiện) hoặc change data capture (thu thập thay đổi dữ liệu). Các cập nhật vào số dư tài khoản không nhất thiết phải xảy ra trong cùng một giao dịch với việc chèn sự kiện, vì chúng là dư thừa và có thể được suy ra từ sự kiện yêu cầu trong một consumer (người tiêu thụ) hạ nguồn, miễn là sự kiện được xử lý đúng một lần, điều mà có thể được thực thi lại bằng cách sử dụng ID yêu cầu.
Luận điểm đầu cuối đến đầu cuối
Tình huống ngăn chặn các giao dịch trùng lặp chỉ là một ví dụ về một nguyên tắc tổng quát hơn được gọi là luận điểm đầu cuối đến đầu cuối (end-to-end argument), được Saltzer, Reed và Clark phát biểu vào năm 1984 44:
Chức năng được đề cập chỉ có thể được thực hiện một cách hoàn toàn và chính xác với kiến thức và sự hỗ trợ của ứng dụng đứng ở các điểm cuối của hệ thống truyền thông. Do đó, việc cung cấp chức năng được đề cập đó như một tính năng của bản thân hệ thống truyền thông là không khả thi. (Đôi khi một phiên bản chưa hoàn chỉnh của chức năng được cung cấp bởi hệ thống truyền thông có thể hữu ích như một cải tiến hiệu suất.)
Trong ví dụ của chúng ta, chức năng được đề cập là việc ngăn chặn trùng lặp. Chúng ta đã thấy rằng TCP ngăn chặn các gói tin trùng lặp ở cấp độ kết nối TCP, và một số bộ xử lý luồng cung cấp ngữ nghĩa được gọi là exactly-once ở cấp độ xử lý thông điệp, nhưng điều đó không đủ để ngăn người dùng gửi một yêu cầu trùng lặp nếu yêu cầu đầu tiên hết thời gian chờ. Bản thân TCP, các giao dịch cơ sở dữ liệu và các bộ xử lý luồng không thể loại trừ hoàn toàn các trùng lặp này. Giải quyết vấn đề đòi hỏi một giải pháp đầu cuối đến đầu cuối: một định danh giao dịch được chuyển từ đầu đến cuối, từ máy khách của người dùng cuối đến cơ sở dữ liệu.
Luận điểm đầu cuối đến đầu cuối cũng áp dụng cho việc kiểm tra tính toàn vẹn của dữ liệu: checksum (tổng kiểm tra) được tích hợp vào Ethernet, TCP và TLS có thể phát hiện sự hỏng dữ liệu của các gói tin trong mạng, nhưng chúng không thể phát hiện sự hỏng dữ liệu do lỗi phần mềm ở đầu gửi và đầu nhận của kết nối mạng, hoặc sự hỏng dữ liệu trên các đĩa nơi dữ liệu được lưu trữ. Nếu bạn muốn bắt tất cả các nguồn có thể gây hỏng dữ liệu, bạn cũng cần checksum đầu cuối đến đầu cuối.
Một lập luận tương tự áp dụng với mã hóa 44: mật khẩu trên mạng WiFi gia đình của bạn bảo vệ chống lại những người nghe lén lưu lượng WiFi của bạn, nhưng không bảo vệ chống lại những kẻ tấn công ở nơi khác trên internet; TLS/SSL giữa máy khách và máy chủ của bạn bảo vệ chống lại kẻ tấn công mạng, nhưng không chống lại việc máy chủ bị xâm phạm. Chỉ có mã hóa và xác thực đầu cuối đến đầu cuối mới có thể bảo vệ chống lại tất cả những điều này.
Mặc dù các tính năng cấp thấp (TCP ngăn chặn trùng lặp, checksum Ethernet, mã hóa WiFi) không thể tự chúng cung cấp các tính năng đầu cuối đến đầu cuối mong muốn, chúng vẫn hữu ích, vì chúng giảm xác suất gặp vấn đề ở các cấp độ cao hơn. Ví dụ, các yêu cầu HTTP thường bị hỏng nếu chúng ta không có TCP sắp xếp lại các gói tin theo đúng thứ tự. Chúng ta chỉ cần nhớ rằng các tính năng độ tin cậy cấp thấp tự chúng không đủ để đảm bảo tính đúng đắn đầu cuối đến đầu cuối.
Áp dụng tư duy đầu cuối đến đầu cuối trong các hệ thống dữ liệu
Điều này đưa chúng ta trở lại luận điểm ban đầu: chỉ vì một ứng dụng sử dụng hệ thống dữ liệu cung cấp các thuộc tính an toàn tương đối mạnh, chẳng hạn như giao dịch serializable, không có nghĩa là ứng dụng đó được đảm bảo không bị mất hoặc hỏng dữ liệu. Bản thân ứng dụng cũng cần thực hiện các biện pháp đầu cuối đến đầu cuối, chẳng hạn như ngăn chặn trùng lặp.
Đây là một điều đáng tiếc, vì các cơ chế chịu lỗi rất khó thực hiện đúng. Các cơ chế độ tin cậy cấp thấp, chẳng hạn như trong TCP, hoạt động khá tốt, và vì vậy các lỗi cấp cao còn lại xảy ra khá hiếm. Sẽ thực sự tuyệt nếu gói các máy móc chịu lỗi cấp cao còn lại vào một lớp trừu tượng để mã ứng dụng không cần lo lắng về nó, nhưng có vẻ như chúng ta vẫn chưa tìm ra đúng lớp trừu tượng đó.
Các giao dịch từ lâu đã được coi là một lớp trừu tượng hữu ích. Như đã thảo luận trong Chương 8, chúng lấy một loạt các vấn đề có thể xảy ra (ghi đồng thời, vi phạm ràng buộc, sự cố, gián đoạn mạng, lỗi đĩa) và thu hẹp chúng xuống còn hai kết quả có thể: commit hoặc hủy bỏ. Đó là một sự đơn giản hóa rất lớn của mô hình lập trình, nhưng nó vẫn chưa đủ.
Giao dịch tốn kém, đặc biệt khi chúng liên quan đến các công nghệ lưu trữ không đồng nhất (xem “Giao dịch Phân tán Trên Các Hệ thống Khác nhau”). Khi chúng ta từ chối sử dụng các giao dịch phân tán vì chúng quá tốn kém, chúng ta phải tái triển khai các cơ chế chịu lỗi trong mã ứng dụng. Như nhiều ví dụ trong cuốn sách này đã chỉ ra, việc lập luận về tính đồng thời và lỗi một phần là khó khăn và phản trực giác, và vì vậy hầu hết các cơ chế ở cấp ứng dụng không hoạt động đúng. Hậu quả là mất hoặc hỏng dữ liệu.
Vì những lý do này, việc khám phá các lớp trừu tượng chịu lỗi giúp dễ dàng cung cấp các thuộc tính tính đúng đắn đầu cuối đến đầu cuối đặc thù cho ứng dụng, trong khi vẫn duy trì hiệu suất tốt và đặc điểm vận hành tốt trong môi trường phân tán quy mô lớn, là điều đáng theo đuổi.
Thực thi Ràng buộc
Hãy suy nghĩ về tính đúng đắn trong bối cảnh các ý tưởng về unbundling databases (tách gói cơ sở dữ liệu). Chúng ta đã thấy rằng việc ngăn chặn trùng lặp đầu cuối đến đầu cuối có thể được thực hiện với một ID yêu cầu được truyền từ máy khách đến cơ sở dữ liệu ghi lại lần ghi. Còn các loại ràng buộc khác thì sao?
Cụ thể, hãy tập trung vào các ràng buộc duy nhất (uniqueness constraints), chẳng hạn như ràng buộc chúng ta đã dựa vào trong Ví dụ 13-2. Trong “Ràng buộc và đảm bảo duy nhất”, chúng ta đã thấy một số ví dụ khác về các tính năng ứng dụng cần thực thi tính duy nhất: tên đăng nhập hoặc địa chỉ email phải xác định duy nhất một người dùng, dịch vụ lưu trữ tệp không thể có nhiều hơn một tệp có cùng tên, và hai người không thể đặt cùng một chỗ ngồi trên một chuyến bay hoặc trong một rạp hát.
Các loại ràng buộc khác rất tương tự: ví dụ, đảm bảo rằng số dư tài khoản không bao giờ âm, rằng bạn không bán nhiều mặt hàng hơn số hàng trong kho, hoặc rằng một phòng họp không có các cuộc đặt chỗ chồng chéo nhau. Các kỹ thuật thực thi tính duy nhất thường có thể được sử dụng cho các loại ràng buộc này.
Ràng buộc duy nhất đòi hỏi đồng thuận
Trong Chương 10, chúng ta đã thấy rằng trong môi trường phân tán, việc thực thi ràng buộc duy nhất đòi hỏi đồng thuận (consensus): nếu có nhiều yêu cầu đồng thời với cùng một giá trị, hệ thống cần phải quyết định bằng cách nào đó xem thao tác nào trong số các thao tác xung đột được chấp nhận, và từ chối các thao tác còn lại là vi phạm ràng buộc.
Cách phổ biến nhất để đạt được đồng thuận này là chỉ định một node duy nhất làm leader (lãnh đạo), và giao cho nó trách nhiệm đưa ra tất cả các quyết định. Điều đó hoạt động tốt miễn là bạn không ngại phải dồn tất cả các yêu cầu qua một node duy nhất (ngay cả khi máy khách ở phía bên kia của thế giới), và miễn là node đó không gặp sự cố. Các thuật toán đồng thuận như Raft giải quyết vấn đề bầu chọn an toàn một leader mới nếu leader hiện tại đã gặp sự cố (hoặc được cho là đã gặp sự cố do sự cố mạng), và ngăn chặn split brain (não phân chia).
Việc kiểm tra duy nhất có thể được mở rộng quy mô bằng cách phân shard dựa trên giá trị cần duy nhất. Ví dụ, nếu bạn cần đảm bảo tính duy nhất theo ID yêu cầu, như trong Ví dụ 13-2, bạn có thể đảm bảo tất cả các yêu cầu có cùng ID yêu cầu được định tuyến đến cùng một shard. Nếu bạn cần tên đăng nhập phải duy nhất, bạn có thể phân shard theo hash của tên đăng nhập.
Tuy nhiên, nhân bản multi-leader (đa lãnh đạo) bất đồng bộ bị loại trừ, vì có thể xảy ra rằng các leader khác nhau đồng thời chấp nhận các lần ghi xung đột, và do đó các giá trị không còn duy nhất. Nếu bạn muốn có thể từ chối ngay lập tức bất kỳ lần ghi nào vi phạm ràng buộc, thì phối hợp đồng bộ là không thể tránh khỏi 45.
Tính duy nhất trong nhắn tin dựa trên log
Một log chia sẻ đảm bảo rằng tất cả các consumer (người tiêu thụ) đều thấy các thông điệp theo cùng một thứ tự, một đảm bảo được gọi chính thức là total order broadcast (phát sóng tổng thứ tự) và tương đương với đồng thuận (xem “Nhiều Dạng Của Đồng Thuận”). Trong cách tiếp cận cơ sở dữ liệu tách gói với nhắn tin dựa trên log, chúng ta có thể sử dụng một cách tiếp cận rất tương tự để thực thi các ràng buộc duy nhất.
Một bộ xử lý luồng tiêu thụ tất cả các thông điệp trong một shard log tuần tự trên một luồng đơn. Do đó, nếu log được phân shard dựa trên giá trị cần duy nhất, bộ xử lý luồng có thể quyết định một cách rõ ràng và xác định (deterministic) thao tác nào trong số các thao tác xung đột xuất hiện đầu tiên trong log. Ví dụ, trong trường hợp nhiều người dùng cố gắng đăng ký cùng một tên đăng nhập 46:
Mỗi yêu cầu về một tên đăng nhập được mã hóa thành một thông điệp, và được thêm vào một shard được xác định bởi hash của tên đăng nhập.
Bộ xử lý luồng đọc tuần tự các yêu cầu trong log, sử dụng cơ sở dữ liệu cục bộ để theo dõi những tên đăng nhập nào đã được sử dụng. Đối với mỗi yêu cầu về tên đăng nhập còn trống, nó ghi lại tên đó là đã được sử dụng và phát ra thông điệp thành công đến một luồng đầu ra. Đối với mỗi yêu cầu về tên đăng nhập đã được sử dụng, nó phát ra thông điệp từ chối đến một luồng đầu ra.
Máy khách đã yêu cầu tên đăng nhập theo dõi luồng đầu ra và chờ thông điệp thành công hoặc từ chối tương ứng với yêu cầu của nó.
Thuật toán này giống với cấu trúc để đạt được đồng thuận bằng cách sử dụng log chia sẻ, mà chúng ta đã thấy trong Chương 10. Nó dễ dàng mở rộng quy mô để đáp ứng thông lượng yêu cầu lớn bằng cách tăng số lượng shard, vì mỗi shard có thể được xử lý độc lập.
Cách tiếp cận này không chỉ hoạt động cho các ràng buộc duy nhất, mà còn cho nhiều loại ràng buộc khác. Nguyên tắc cơ bản của nó là bất kỳ lần ghi nào có thể xung đột đều được định tuyến đến cùng một shard và được xử lý tuần tự. Định nghĩa về xung đột có thể phụ thuộc vào ứng dụng, nhưng bộ xử lý luồng có thể sử dụng logic tùy ý để xác nhận một yêu cầu.
Xử lý yêu cầu đa shard
Đảm bảo rằng một thao tác được thực thi nguyên tử, trong khi thỏa mãn các ràng buộc, trở nên thú vị hơn khi có nhiều shard liên quan. Trong Ví dụ 13-2, có khả năng có ba shard: shard chứa ID yêu cầu, shard chứa tài khoản người thụ hưởng và shard chứa tài khoản người thanh toán. Không có lý do gì ba thứ đó phải ở trong cùng một shard, vì chúng hoàn toàn độc lập với nhau.
Trong cách tiếp cận truyền thống đối với cơ sở dữ liệu, việc thực thi giao dịch này sẽ yêu cầu một cam kết nguyên tử trên cả ba shard, về cơ bản ép nó vào một thứ tự tổng thể đối với tất cả các giao dịch khác trên bất kỳ shard nào trong số đó. Vì bây giờ có sự phối hợp liên shard, các shard khác nhau không còn có thể được xử lý độc lập nữa, nên thông lượng có khả năng bị ảnh hưởng.
Tuy nhiên, tính đúng đắn tương đương có thể đạt được mà không cần giao dịch liên shard bằng cách sử dụng các log được phân shard và các bộ xử lý luồng. Hình 13-2 cho thấy một ví dụ về giao dịch thanh toán cần kiểm tra xem tài khoản nguồn có đủ tiền không, và nếu có, nguyên tử chuyển một số tiền đến tài khoản đích trong khi khấu trừ phí. Nó hoạt động như sau 47:
Yêu cầu chuyển tiền từ tài khoản nguồn đến tài khoản đích được gán một ID yêu cầu duy nhất bởi máy khách của người dùng, và được thêm vào một shard log dựa trên ID tài khoản nguồn.
Bộ xử lý luồng đọc log của các yêu cầu và duy trì một cơ sở dữ liệu chứa trạng thái của tài khoản nguồn và các ID yêu cầu mà nó đã xử lý. Nội dung của cơ sở dữ liệu này hoàn toàn được suy ra từ log. Khi bộ xử lý luồng gặp một yêu cầu với ID mà nó chưa thấy trước đó, nó kiểm tra trong cơ sở dữ liệu cục bộ của mình xem tài khoản nguồn có đủ tiền để thực hiện chuyển khoản không.
Nếu có, nó cập nhật cơ sở dữ liệu cục bộ để đặt chỗ số tiền thanh toán trong tài khoản nguồn, và phát ra các sự kiện đến một số log khác: một sự kiện thanh toán đi đến shard log cho tài khoản nguồn (log đầu vào của chính nó), một sự kiện thanh toán đến đến shard log cho tài khoản đích, và một sự kiện thanh toán đến đến shard log cho tài khoản phí. ID yêu cầu gốc được bao gồm trong các sự kiện được phát ra đó.
Cuối cùng sự kiện thanh toán đi được gửi lại đến bộ xử lý tài khoản nguồn (có thể sau khi nhận được các sự kiện không liên quan trong thời gian chờ đó). Bộ xử lý luồng nhận ra dựa trên ID yêu cầu rằng đây là khoản thanh toán mà nó đã đặt chỗ trước đó, và bây giờ nó thực thi khoản thanh toán, một lần nữa cập nhật trạng thái cục bộ của tài khoản nguồn. Nó bỏ qua các bản trùng lặp dựa trên ID yêu cầu.
Các shard log cho tài khoản đích và tài khoản phí được tiêu thụ bởi các tác vụ xử lý luồng độc lập. Khi chúng nhận được sự kiện thanh toán đến, chúng cập nhật trạng thái cục bộ để phản ánh khoản thanh toán, và chúng loại trùng lặp các sự kiện dựa trên ID yêu cầu.
Hình 13-2 cho thấy ba tài khoản nằm trong ba shard riêng biệt, nhưng chúng cũng có thể nằm trong cùng các shard, điều đó không quan trọng. Tất cả những gì chúng ta cần là các sự kiện của bất kỳ tài khoản nào được xử lý nghiêm ngặt theo thứ tự log với ngữ nghĩa at-least-once (ít nhất một lần), và các bộ xử lý luồng là xác định.
Ví dụ, hãy xem xét điều gì xảy ra nếu bộ xử lý tài khoản nguồn gặp sự cố trong khi xử lý một yêu cầu thanh toán. Các thông điệp đầu ra có thể hoặc có thể không được phát ra trước khi sự cố xảy ra. Khi nó phục hồi từ sự cố, nó sẽ xử lý cùng một yêu cầu một lần nữa (do ngữ nghĩa at-least-once), và nó sẽ đưa ra cùng một quyết định về việc có cho phép thanh toán hay không (vì nó là xác định). Do đó nó sẽ phát ra các thông điệp đầu ra giống nhau với cùng ID yêu cầu đến các shard tài khoản đi, đến và phí. Nếu chúng là bản trùng lặp, các consumer hạ nguồn sẽ bỏ qua chúng dựa trên ID yêu cầu.
Tính nguyên tử trong hệ thống này không đến từ bất kỳ giao dịch nào, mà từ thực tế là việc ghi sự kiện yêu cầu ban đầu vào log tài khoản nguồn là một hành động nguyên tử. Một khi sự kiện đó nằm trong log, tất cả các sự kiện hạ nguồn sẽ cuối cùng cũng được ghi, có thể sau khi các bộ xử lý luồng phục hồi từ sự cố, và có thể có bản trùng lặp, nhưng chúng sẽ xuất hiện cuối cùng.
Với ngữ nghĩa exactly-once, ví dụ này trở nên dễ triển khai hơn, vì nó đảm bảo rằng trạng thái cục bộ của bộ xử lý luồng nhất quán với tập hợp các thông điệp mà nó đã xử lý. Do đó, nếu nó gặp sự cố và xử lý lại một số thông điệp, trạng thái cục bộ của nó cũng được đặt lại về trạng thái trước khi những thông điệp đó được xử lý.
Nếu người dùng trong Hình 13-2 muốn biết liệu giao dịch chuyển tiền của họ có được chấp thuận hay không, họ có thể đăng ký theo dõi shard log tài khoản nguồn và chờ sự kiện thanh toán đi. Để thông báo rõ ràng cho người dùng nếu số dư không đủ, bộ xử lý luồng có thể phát ra sự kiện “thanh toán bị từ chối” đến shard log đó.
Bằng cách chia nhỏ giao dịch đa shard thành nhiều giai đoạn được phân shard khác nhau và sử dụng ID yêu cầu đầu cuối đến đầu cuối, chúng ta đã đạt được cùng thuộc tính đúng đắn (mỗi yêu cầu được áp dụng đúng một lần cho cả tài khoản người thanh toán và người thụ hưởng), ngay cả khi có sự cố, và mà không cần sử dụng giao thức cam kết nguyên tử.
Tính Kịp Thời và Tính Toàn Vẹn
Một thuộc tính tiện lợi của nhiều hệ thống giao dịch là ngay sau khi một giao dịch commit, các lần ghi của nó lập tức hiển thị với các giao dịch khác. Thuộc tính này được hình thức hóa là strict serializability (tuần tự hóa nghiêm ngặt) (xem “Linearizability So với Serializability”).
Điều này không phải là trường hợp khi tách gói một thao tác trên nhiều giai đoạn của bộ xử lý luồng: các consumer của một log là bất đồng bộ theo thiết kế, vì vậy người gửi không chờ cho đến khi thông điệp của nó được xử lý bởi các consumer. Tuy nhiên, có thể cho phép một máy khách chờ một thông điệp xuất hiện trên một luồng đầu ra, như người dùng chờ sự kiện thanh toán đi hoặc thanh toán bị từ chối trong Hình 13-2, phụ thuộc vào việc có đủ tiền trong tài khoản nguồn hay không.
Trong ví dụ này, tính đúng đắn của việc kiểm tra số dư tài khoản nguồn không phụ thuộc vào việc người dùng đưa ra yêu cầu có chờ kết quả hay không. Việc chờ đợi chỉ có mục đích thông báo đồng bộ cho người dùng xem khoản thanh toán có thành công hay không, nhưng thông báo này được tách rời khỏi các hiệu ứng của việc xử lý yêu cầu.
Tổng quát hơn, thuật ngữ tính nhất quán (consistency) kết hợp hai yêu cầu khác nhau đáng được xem xét riêng biệt:
- Tính Kịp Thời
Timeliness (tính kịp thời) nghĩa là đảm bảo người dùng quan sát hệ thống ở trạng thái cập nhật nhất. Chúng ta đã thấy trước đó rằng nếu người dùng đọc từ bản sao dữ liệu cũ, họ có thể thấy dữ liệu ở trạng thái không nhất quán (xem “Problems with Replication Lag”). Tuy nhiên, sự không nhất quán đó là tạm thời và cuối cùng sẽ được giải quyết đơn giản bằng cách chờ đợi và thử lại.
Định lý CAP sử dụng consistency (tính nhất quán) theo nghĩa của linearizability, đây là một cách mạnh để đạt được timeliness. Các thuộc tính timeliness yếu hơn như read-after-write consistency cũng có thể hữu ích.
- Integrity (tính toàn vẹn)
Integrity nghĩa là không có tình trạng hỏng dữ liệu, tức là không mất dữ liệu, không có dữ liệu mâu thuẫn hay sai lệch. Cụ thể, nếu một tập dữ liệu dẫn xuất được duy trì như một view trên một số dữ liệu nền, phép dẫn xuất phải chính xác. Ví dụ, một index của cơ sở dữ liệu phải phản ánh đúng nội dung của cơ sở dữ liệu, một index thiếu một số bản ghi sẽ không có nhiều tác dụng.
Nếu integrity bị vi phạm, sự không nhất quán là vĩnh viễn: chờ đợi và thử lại sẽ không sửa được tình trạng hỏng cơ sở dữ liệu trong hầu hết các trường hợp. Thay vào đó, cần phải kiểm tra và sửa chữa một cách tường minh. Trong ngữ cảnh của ACID transactions, “consistency” thường được hiểu là một loại khái niệm integrity dành riêng cho ứng dụng. Atomicity và durability là các công cụ quan trọng để bảo vệ integrity.
Tóm gọn bằng một câu: các vi phạm timeliness là “eventual consistency,” trong khi các vi phạm integrity là “perpetual inconsistency” (mâu thuẫn vĩnh viễn).
Trong hầu hết các ứng dụng, integrity quan trọng hơn nhiều so với timeliness. Vi phạm timeliness có thể gây bực bội và nhầm lẫn, nhưng vi phạm integrity có thể gây ra hậu quả thảm khốc.
Ví dụ, trên sao kê thẻ tín dụng của bạn, không có gì ngạc nhiên nếu một giao dịch bạn thực hiện trong vòng 24 giờ qua chưa xuất hiện, điều đó là bình thường vì các hệ thống này có độ trễ nhất định. Chúng ta biết rằng các ngân hàng đối soát và thanh toán giao dịch theo cách bất đồng bộ, và timeliness không quá quan trọng ở đây 3. Tuy nhiên, sẽ rất tệ nếu số dư sao kê không bằng tổng các giao dịch cộng với số dư sao kê trước đó (lỗi tính toán), hoặc nếu một giao dịch bị tính vào tài khoản bạn nhưng không được thanh toán cho người bán (tiền biến mất). Những vấn đề như vậy sẽ là vi phạm integrity của hệ thống.
Correctness of dataflow systems
ACID transactions thường cung cấp cả hai đảm bảo: timeliness (ví dụ: linearizability) và integrity (ví dụ: atomic commit). Do đó, nếu bạn tiếp cận tính đúng đắn của ứng dụng từ góc độ ACID transactions, sự phân biệt giữa timeliness và integrity không quá quan trọng.
Mặt khác, một thuộc tính thú vị của các hệ thống dataflow dựa trên sự kiện mà chúng ta đã thảo luận trong chương này là chúng tách rời timeliness và integrity. Khi xử lý event streams bất đồng bộ, không có đảm bảo về timeliness, trừ khi bạn xây dựng tường minh các consumer chờ một tin nhắn đến trước khi trả về. Ví dụ, người dùng có thể yêu cầu thanh toán rồi đọc trạng thái tài khoản trước khi stream processor thực thi yêu cầu đó; người dùng sẽ không thấy khoản thanh toán họ vừa yêu cầu.
Tuy nhiên, integrity thực sự là trung tâm của các hệ thống streaming. Ngữ nghĩa Exactly-once (đúng một lần) hoặc effectively-once (hiệu quả một lần) là cơ chế để bảo toàn integrity. Nếu một sự kiện bị mất, hoặc nếu một sự kiện có hiệu lực hai lần, integrity của hệ thống dữ liệu có thể bị vi phạm. Do đó, việc phân phối tin nhắn đáng tin cậy và loại bỏ trùng lặp (ví dụ: các phép toán idempotent) là quan trọng để duy trì integrity của hệ thống dữ liệu khi đối mặt với lỗi.
Như chúng ta đã thấy trong phần trước, các hệ thống xử lý stream đáng tin cậy có thể bảo toàn integrity mà không cần distributed transactions và giao thức atomic commit, điều này có nghĩa là chúng có thể đạt được tính đúng đắn tương đương với hiệu suất tốt hơn nhiều và độ bền vận hành cao hơn. Chúng ta đạt được integrity này thông qua sự kết hợp của các cơ chế:
Biểu diễn nội dung của thao tác ghi dưới dạng một tin nhắn duy nhất, có thể được ghi atomically dễ dàng, đây là cách tiếp cận phù hợp rất tốt với event sourcing
Dẫn xuất tất cả các cập nhật trạng thái khác từ tin nhắn đơn đó bằng cách sử dụng các hàm dẫn xuất xác định, tương tự như stored procedures
Truyền một request ID do client tạo ra qua tất cả các cấp độ xử lý này, cho phép loại bỏ trùng lặp end-to-end và đảm bảo idempotence
Giữ nguyên tính bất biến của tin nhắn và cho phép dữ liệu dẫn xuất được xử lý lại theo thời gian, giúp dễ dàng phục hồi sau lỗi
Loosely interpreted constraints
Như đã thảo luận trước đó, việc thực thi ràng buộc duy nhất (uniqueness constraint) đòi hỏi sự đồng thuận, thường được thực hiện bằng cách dồn tất cả các sự kiện trong một shard cụ thể qua một node duy nhất. Giới hạn này là không thể tránh khỏi nếu chúng ta muốn dạng truyền thống của uniqueness constraint, và stream processing không thể giải quyết vấn đề đó.
Tuy nhiên, điều quan trọng cần nhận ra là trong nhiều ứng dụng thực tế, thực sự có yêu cầu kinh doanh để cho phép vi phạm những gì bạn có thể nghĩ là các ràng buộc cứng:
Nếu khách hàng đặt nhiều mặt hàng hơn bạn có trong kho, bạn có thể đặt thêm hàng, xin lỗi khách hàng vì sự chậm trễ, và cung cấp cho họ giảm giá. Điều này thực sự giống với những gì bạn phải làm nếu, chẳng hạn, một chiếc xe nâng chạy qua một số mặt hàng trong kho của bạn, khiến bạn có ít hàng hơn bạn nghĩ 3. Do đó, quy trình xin lỗi đã cần phải là một phần trong quy trình kinh doanh của bạn để xử lý các sự cố xe nâng, và một ràng buộc cứng về số lượng mặt hàng trong kho có thể không cần thiết.
Tương tự, nhiều hãng hàng không bán quá số ghế với kỳ vọng rằng một số hành khách sẽ lỡ chuyến bay, và nhiều khách sạn đặt phòng vượt mức, với kỳ vọng rằng một số khách sẽ hủy. Trong những trường hợp này, ràng buộc “một người một ghế” cố ý bị vi phạm vì lý do kinh doanh, và các quy trình bồi thường (hoàn tiền, nâng cấp, cung cấp phòng miễn phí ở khách sạn lân cận) được đưa vào để xử lý các tình huống trong đó nhu cầu vượt quá nguồn cung. Ngay cả khi không có tình trạng bán quá, các quy trình xin lỗi và bồi thường vẫn cần thiết để xử lý các chuyến bay bị hủy do thời tiết xấu hoặc nhân viên đình công, việc phục hồi từ những vấn đề như vậy chỉ là một phần bình thường trong kinh doanh 3.
Nếu ai đó rút nhiều tiền hơn số tiền họ có trong tài khoản, ngân hàng có thể tính phí thấu chi và yêu cầu họ trả lại số tiền nợ. Bằng cách giới hạn tổng số tiền rút mỗi ngày, rủi ro đối với ngân hàng được kiểm soát.
Trong các hệ thống tích hợp dữ liệu giữa các tổ chức khác nhau, các mâu thuẫn sẽ không thể tránh khỏi, và cần có các cơ chế sửa chữa để xử lý chúng. Như đã lưu ý trong “Batch Use Cases”, thanh toán bù trừ giữa các ngân hàng là một ví dụ về điều này.
Trong nhiều bối cảnh kinh doanh, do đó, việc tạm thời vi phạm một ràng buộc và sửa lại sau bằng cách xin lỗi là chấp nhận được. Kiểu thay đổi để sửa lỗi này được gọi là compensating transaction (giao dịch bù trừ) 48, 49. Chi phí của lời xin lỗi (về tiền bạc hoặc danh tiếng) thay đổi, nhưng thường khá thấp: bạn không thể hủy gửi một email, nhưng bạn có thể gửi email tiếp theo với phần đính chính. Nếu bạn vô tình tính phí thẻ tín dụng hai lần, bạn có thể hoàn lại một trong các khoản phí, và chi phí cho bạn chỉ là phí xử lý và có thể là một khiếu nại từ khách hàng. Khi tiền đã được rút ra khỏi ATM, bạn không thể lấy lại trực tiếp, mặc dù về nguyên tắc bạn có thể gửi đơn vị thu hồi nợ để thu hồi tiền nếu tài khoản bị thấu chi và khách hàng không chịu trả.
Liệu chi phí của lời xin lỗi có chấp nhận được hay không là một quyết định kinh doanh. Nếu nó chấp nhận được, mô hình truyền thống kiểm tra tất cả các ràng buộc trước khi ghi dữ liệu là không cần thiết và quá hạn chế. Có thể hợp lý khi tiến hành ghi một cách lạc quan, và kiểm tra ràng buộc sau đó. Bạn vẫn có thể đảm bảo rằng việc xác thực xảy ra trước khi làm những việc tốn kém để phục hồi, nhưng điều đó không có nghĩa là bạn phải thực hiện xác thực trước khi ghi dữ liệu.
Những ứng dụng này thực sự đòi hỏi integrity: bạn sẽ không muốn mất một đặt phòng, hoặc tiền biến mất do tín dụng và ghi nợ không khớp nhau. Nhưng chúng không đòi hỏi timeliness trong việc thực thi ràng buộc: nếu bạn đã bán nhiều mặt hàng hơn bạn có trong kho, bạn có thể khắc phục vấn đề sau đó bằng cách xin lỗi. Làm như vậy tương tự như các cách tiếp cận giải quyết xung đột mà chúng ta đã thảo luận trong “Dealing with Conflicting Writes”.
Coordination-avoiding data systems
Chúng ta hiện đã có hai quan sát thú vị:
Các hệ thống dataflow có thể duy trì đảm bảo integrity trên dữ liệu dẫn xuất mà không cần atomic commit, linearizability, hoặc điều phối đồng bộ giữa các shard.
Mặc dù các ràng buộc duy nhất nghiêm ngặt đòi hỏi timeliness và điều phối, nhiều ứng dụng thực sự hoạt động tốt với các ràng buộc lỏng lẻo có thể bị vi phạm tạm thời và sửa chữa sau, miễn là integrity được bảo toàn trong suốt quá trình.
Kết hợp lại, các quan sát này có nghĩa là các hệ thống dataflow có thể cung cấp các dịch vụ quản lý dữ liệu cho nhiều ứng dụng mà không cần điều phối, đồng thời vẫn cung cấp các đảm bảo integrity mạnh mẽ. Các hệ thống dữ liệu coordination-avoiding (tránh điều phối) như vậy có nhiều điểm hấp dẫn: chúng có thể đạt được hiệu suất tốt hơn và khả năng chịu lỗi tốt hơn so với các hệ thống cần thực hiện điều phối đồng bộ 45.
Ví dụ, một hệ thống như vậy có thể hoạt động phân tán trên nhiều datacenter trong cấu hình multi-leader, sao chép bất đồng bộ giữa các vùng. Bất kỳ datacenter nào cũng có thể tiếp tục hoạt động độc lập với các datacenter khác, vì không cần điều phối đồng bộ giữa các vùng. Hệ thống như vậy sẽ có đảm bảo timeliness yếu, nó không thể linearizable mà không có điều phối, nhưng vẫn có thể có các đảm bảo integrity mạnh mẽ.
Trong bối cảnh này, serializable transactions vẫn hữu ích như một phần trong việc duy trì trạng thái dẫn xuất, nhưng chúng có thể được chạy ở phạm vi nhỏ nơi chúng hoạt động tốt 6. Không cần các distributed transactions không đồng nhất như XA transactions. Điều phối đồng bộ vẫn có thể được áp dụng ở những nơi cần thiết (ví dụ: để thực thi các ràng buộc nghiêm ngặt trước một thao tác không thể phục hồi), nhưng không cần mọi thứ phải trả chi phí của điều phối nếu chỉ có một phần nhỏ của ứng dụng cần nó 32.
Một cách khác để xem xét điều phối và các ràng buộc: chúng giảm số lượng lời xin lỗi bạn phải đưa ra do các mâu thuẫn, nhưng cũng có thể làm giảm hiệu suất và tính sẵn sàng của hệ thống, và do đó có thể tăng số lượng lời xin lỗi bạn phải đưa ra do sự cố. Bạn không thể giảm số lời xin lỗi về không, nhưng bạn có thể nhắm đến việc tìm kiếm sự đánh đổi tốt nhất cho nhu cầu của mình, điểm lý tưởng nơi không có quá nhiều mâu thuẫn cũng không có quá nhiều vấn đề về tính sẵn sàng.
Trust, but Verify
Toàn bộ thảo luận của chúng ta về tính đúng đắn, integrity và khả năng chịu lỗi đều dựa trên giả định rằng một số điều có thể xảy ra sai, nhưng những điều khác sẽ không. Chúng ta gọi những giả định này là system model (mô hình hệ thống) của mình (xem “System Model and Reality”): ví dụ, chúng ta nên giả định rằng các process có thể bị crash, các máy có thể đột ngột mất điện, và mạng có thể trì hoãn hoặc mất gói tin tùy ý. Nhưng chúng ta cũng có thể giả định rằng dữ liệu được ghi vào đĩa không bị mất sau fsync, dữ liệu trong bộ nhớ không bị hỏng, và lệnh nhân của CPU của chúng ta luôn trả về kết quả đúng.
Những giả định này khá hợp lý, vì chúng đúng hầu hết thời gian, và sẽ khó hoàn thành bất cứ điều gì nếu chúng ta phải liên tục lo lắng về việc máy tính mắc lỗi. Theo truyền thống, các mô hình hệ thống tiếp cận lỗi theo cách nhị phân: chúng ta giả định rằng một số điều có thể xảy ra, và các điều khác không bao giờ xảy ra. Trong thực tế, đó là vấn đề xác suất hơn: một số điều có khả năng xảy ra cao hơn, các điều khác ít khả năng hơn. Câu hỏi là liệu các vi phạm giả định của chúng ta có xảy ra đủ thường xuyên để chúng ta có thể gặp phải chúng trong thực tế hay không.
Chúng ta đã thấy rằng dữ liệu có thể bị hỏng trong bộ nhớ (xem “Hardware and Software Faults”), trên đĩa (xem “Replication and Durability”), và trên mạng (xem “Weak forms of lying”). Có lẽ đây là điều chúng ta nên chú ý hơn? Nếu bạn đang vận hành ở quy mô đủ lớn, ngay cả những điều rất ít xảy ra cũng sẽ xảy ra.
Maintaining integrity in the face of software bugs
Ngoài các vấn đề phần cứng như vậy, luôn có rủi ro từ các lỗi phần mềm, mà sẽ không được phát hiện bởi các checksum cấp thấp hơn của mạng, bộ nhớ, hoặc filesystem. Ngay cả phần mềm cơ sở dữ liệu được sử dụng rộng rãi cũng có lỗi: ví dụ, các phiên bản cũ của MySQL đã không duy trì đúng các ràng buộc duy nhất (uniqueness constraints) 50 và mức độ isolation serializable của PostgreSQL đã từng có các bất thường write skew 51, mặc dù MySQL và PostgreSQL là các cơ sở dữ liệu mạnh mẽ và được đánh giá cao, đã được kiểm tra thực tế bởi nhiều người trong nhiều năm. Trong phần mềm kém trưởng thành hơn, tình hình có thể tồi tệ hơn nhiều.
Mặc dù có nỗ lực đáng kể trong thiết kế cẩn thận, kiểm tra và đánh giá, các lỗi vẫn lẻn vào. Mặc dù chúng hiếm gặp và cuối cùng được tìm thấy và sửa chữa, vẫn có một giai đoạn mà các lỗi như vậy có thể làm hỏng dữ liệu.
Khi nói đến code ứng dụng, chúng ta phải giả định nhiều lỗi hơn nữa, vì hầu hết các ứng dụng không nhận được lượng đánh giá và kiểm tra gần bằng mức mà code cơ sở dữ liệu nhận được. Nhiều ứng dụng thậm chí không sử dụng đúng các tính năng mà cơ sở dữ liệu cung cấp để bảo toàn integrity, chẳng hạn như foreign key hay ràng buộc duy nhất 25.
Consistency theo nghĩa của ACID dựa trên ý tưởng rằng cơ sở dữ liệu bắt đầu ở trạng thái nhất quán, và một transaction chuyển đổi nó từ trạng thái nhất quán này sang trạng thái nhất quán khác. Do đó, chúng ta mong đợi cơ sở dữ liệu luôn ở trạng thái nhất quán. Tuy nhiên, khái niệm này chỉ có ý nghĩa nếu bạn giả định rằng transaction không có lỗi. Nếu ứng dụng sử dụng cơ sở dữ liệu không đúng cách, ví dụ sử dụng mức độ isolation yếu không an toàn, integrity của cơ sở dữ liệu không thể được đảm bảo.
Don’t just blindly trust what they promise
Với cả phần cứng và phần mềm không luôn đáp ứng được lý tưởng mà chúng ta muốn, có vẻ như hỏng dữ liệu là không thể tránh khỏi sớm hay muộn. Do đó, chúng ta ít nhất nên có cách tìm hiểu xem dữ liệu có bị hỏng hay không để chúng ta có thể sửa chữa và cố gắng tìm ra nguồn gốc của lỗi. Kiểm tra tính toàn vẹn của dữ liệu được gọi là auditing (kiểm toán).
Như đã thảo luận trong “Advantages of immutable events”, auditing không chỉ dành cho các ứng dụng tài chính. Tuy nhiên, khả năng kiểm toán rất quan trọng trong tài chính chính xác vì mọi người đều biết rằng sai lầm xảy ra, và tất cả chúng ta đều nhận ra sự cần thiết phải phát hiện và khắc phục các vấn đề.
Các hệ thống trưởng thành tương tự cũng có xu hướng xem xét khả năng những điều không mong muốn xảy ra, và quản lý rủi ro đó. Ví dụ, các hệ thống lưu trữ quy mô lớn như HDFS và Amazon S3 không hoàn toàn tin tưởng vào đĩa: chúng chạy các tiến trình nền liên tục đọc lại các tệp, so sánh chúng với các replica khác, và di chuyển tệp từ đĩa này sang đĩa khác, nhằm giảm thiểu rủi ro từ tình trạng hỏng âm thầm 52, 53.
Nếu bạn muốn chắc chắn rằng dữ liệu của mình vẫn còn đó, bạn phải thực sự đọc nó và kiểm tra. Hầu hết thời gian nó vẫn sẽ còn đó, nhưng nếu không, bạn thực sự muốn tìm ra sớm hơn là muộn hơn. Theo cùng lập luận đó, điều quan trọng là thỉnh thoảng thử khôi phục từ các bản sao lưu của bạn, nếu không bạn có thể chỉ phát hiện ra rằng bản sao lưu của bạn bị hỏng khi đã quá muộn và bạn đã mất dữ liệu. Đừng chỉ tin tưởng mù quáng rằng mọi thứ đều hoạt động.
Các hệ thống như HDFS và S3 vẫn phải giả định rằng đĩa hoạt động đúng hầu hết thời gian, đây là một giả định hợp lý, nhưng không giống như giả định rằng chúng luôn hoạt động đúng. Tuy nhiên, không nhiều hệ thống hiện nay có cách tiếp cận “tin tưởng, nhưng kiểm tra” này về việc liên tục tự kiểm toán. Nhiều hệ thống giả định rằng các đảm bảo về tính đúng đắn là tuyệt đối và không dự phòng cho khả năng hỏng dữ liệu hiếm gặp. Trong tương lai, chúng ta có thể thấy nhiều hơn các hệ thống self-validating (tự xác thực) hoặc self-auditing (tự kiểm toán) liên tục kiểm tra tính toàn vẹn của chính mình, thay vì dựa vào sự tin tưởng mù quáng 54.
Designing for auditability
Nếu một transaction thay đổi một số đối tượng trong cơ sở dữ liệu, rất khó để biết sau đó transaction đó có ý nghĩa gì. Ngay cả khi bạn nắm bắt được transaction logs, các lệnh chèn, cập nhật, và xóa trong các bảng khác nhau không nhất thiết cho thấy rõ lý do những thay đổi đó được thực hiện. Việc gọi logic ứng dụng đã quyết định những thay đổi đó là tạm thời và không thể tái tạo.
Ngược lại, các hệ thống dựa trên sự kiện có thể cung cấp khả năng kiểm toán tốt hơn. Trong cách tiếp cận event sourcing, đầu vào của người dùng vào hệ thống được biểu diễn như một sự kiện bất biến duy nhất, và bất kỳ cập nhật trạng thái kết quả nào đều được dẫn xuất từ sự kiện đó. Phép dẫn xuất có thể được làm xác định và có thể lặp lại, sao cho việc chạy cùng một log sự kiện qua cùng một phiên bản code dẫn xuất sẽ dẫn đến các cập nhật trạng thái giống nhau.
Việc tường minh hóa các dataflow giúp provenance (nguồn gốc) của dữ liệu rõ ràng hơn nhiều, điều này làm cho việc kiểm tra tính toàn vẹn trở nên khả thi hơn nhiều. Đối với event log, chúng ta có thể sử dụng các hash để kiểm tra rằng kho lưu trữ sự kiện không bị hỏng. Đối với bất kỳ trạng thái dẫn xuất nào, chúng ta có thể chạy lại các bộ xử lý batch và stream đã dẫn xuất nó từ event log để kiểm tra xem chúng ta có nhận được cùng kết quả hay không, hoặc thậm chí chạy một phép dẫn xuất dự phòng song song.
Một dataflow xác định và được định nghĩa rõ ràng cũng giúp dễ dàng debug và theo dõi quá trình thực thi của hệ thống để xác định lý do tại sao nó làm điều gì đó 4, 55. Nếu có điều gì đó bất ngờ xảy ra, rất có giá trị khi có khả năng chẩn đoán để tái tạo chính xác các hoàn cảnh dẫn đến sự kiện bất ngờ đó, một loại khả năng debug du hành thời gian.
The end-to-end argument again
Nếu chúng ta không thể hoàn toàn tin tưởng rằng mọi thành phần riêng lẻ của hệ thống sẽ không có hỏng hóc, rằng mọi phần cứng đều không có lỗi và mọi phần mềm đều không có bug, thì ít nhất chúng ta phải định kỳ kiểm tra tính toàn vẹn của dữ liệu. Nếu chúng ta không kiểm tra, chúng ta sẽ không biết về tình trạng hỏng cho đến khi quá muộn và nó đã gây ra một số thiệt hại phía hạ nguồn, tại thời điểm đó sẽ khó và tốn kém hơn nhiều để tìm ra vấn đề.
Kiểm tra tính toàn vẹn của các hệ thống dữ liệu tốt nhất là thực hiện theo cách end-to-end: càng nhiều hệ thống chúng ta có thể bao gồm trong một lần kiểm tra tính toàn vẹn, thì càng ít cơ hội để tình trạng hỏng đi không được chú ý ở một số giai đoạn của quá trình. Nếu chúng ta có thể kiểm tra rằng toàn bộ pipeline dữ liệu dẫn xuất là chính xác end-to-end, thì bất kỳ đĩa, mạng, dịch vụ và thuật toán nào dọc theo đường dẫn đều được bao gồm ngầm trong lần kiểm tra đó.
Việc có các kiểm tra tính toàn vẹn end-to-end liên tục giúp bạn tự tin hơn về tính đúng đắn của các hệ thống, điều này lại cho phép bạn di chuyển nhanh hơn 56. Giống như kiểm thử tự động, auditing tăng khả năng các lỗi sẽ được tìm thấy nhanh chóng, và do đó giảm rủi ro rằng một thay đổi đối với hệ thống hoặc một công nghệ lưu trữ mới sẽ gây ra thiệt hại. Nếu bạn không sợ thực hiện các thay đổi, bạn có thể phát triển ứng dụng tốt hơn nhiều để đáp ứng các yêu cầu thay đổi.
Tools for auditable data systems
Hiện tại, không nhiều hệ thống dữ liệu coi khả năng kiểm toán là mối quan tâm hàng đầu. Một số ứng dụng triển khai các cơ chế kiểm toán riêng, ví dụ bằng cách ghi lại tất cả các thay đổi vào một bảng kiểm toán riêng biệt, nhưng đảm bảo tính toàn vẹn của audit log và trạng thái cơ sở dữ liệu vẫn còn khó khăn. Transaction log có thể được làm chống giả mạo bằng cách định kỳ ký với một module bảo mật phần cứng, nhưng điều đó không đảm bảo rằng các transaction đúng đã vào log ngay từ đầu.
Các Blockchain như Bitcoin hoặc Ethereum là các append-only log được chia sẻ với các kiểm tra tính nhất quán bằng mật mã; các giao dịch chúng lưu trữ là các sự kiện, và các smart contract về cơ bản là các bộ xử lý stream. Các giao thức đồng thuận mà chúng sử dụng đảm bảo rằng tất cả các node đồng ý về cùng một chuỗi sự kiện. Sự khác biệt so với các giao thức đồng thuận của Chương 10 là blockchain có khả năng chịu lỗi Byzantine, tức là chúng vẫn hoạt động nếu một số node tham gia có dữ liệu bị hỏng vì các replica liên tục kiểm tra tính toàn vẹn của nhau.
Đối với hầu hết các ứng dụng, blockchain có chi phí quá cao để có thể hữu ích. Tuy nhiên, một số công cụ mật mã của chúng cũng có thể được sử dụng trong bối cảnh nhẹ hơn. Ví dụ, Merkle trees 57 là các cây hash có thể được sử dụng để chứng minh hiệu quả rằng một bản ghi xuất hiện trong một số tập dữ liệu (và một số điều khác). Certificate transparency sử dụng các append-only log được xác minh bằng mật mã và Merkle trees để kiểm tra tính hợp lệ của các chứng chỉ TLS/SSL 58, 59; nó tránh cần giao thức đồng thuận bằng cách có một leader duy nhất cho mỗi log.
Các thuật toán kiểm tra tính toàn vẹn và kiểm toán, giống như các thuật toán của certificate transparency và distributed ledgers, có thể sẽ được sử dụng rộng rãi hơn trong các hệ thống dữ liệu nói chung trong tương lai. Một số công việc sẽ cần thiết để làm cho chúng có khả năng mở rộng ngang bằng với các hệ thống không có kiểm toán bằng mật mã, và để giữ mức phạt hiệu suất càng thấp càng tốt, nhưng chúng vẫn thú vị.
Summary
Trong chương này chúng ta đã thảo luận về các cách tiếp cận mới để thiết kế hệ thống dữ liệu dựa trên các ý tưởng từ xử lý stream. Chúng ta bắt đầu với quan sát rằng không có một công cụ nào duy nhất có thể phục vụ hiệu quả tất cả các trường hợp sử dụng có thể, và do đó các ứng dụng nhất thiết cần kết hợp một số phần mềm khác nhau để hoàn thành mục tiêu của mình. Chúng ta đã thảo luận về cách giải quyết bài toán data integration (tích hợp dữ liệu) này bằng cách sử dụng batch processing và event streams để cho phép các thay đổi dữ liệu di chuyển giữa các hệ thống khác nhau.
Trong cách tiếp cận này, một số hệ thống được chỉ định là systems of record (hệ thống gốc), và các dữ liệu khác được dẫn xuất từ chúng thông qua các phép biến đổi. Theo cách này, chúng ta có thể duy trì các index, materialized views, các mô hình machine learning, các bản tóm tắt thống kê, và nhiều hơn nữa. Bằng cách làm cho các phép dẫn xuất và biến đổi này bất đồng bộ và được kết hợp lỏng lẻo, một vấn đề trong một khu vực được ngăn không lan sang các phần không liên quan của hệ thống, tăng độ bền và khả năng chịu lỗi của toàn bộ hệ thống.
Biểu diễn các dataflow như các phép biến đổi từ tập dữ liệu này sang tập dữ liệu khác cũng giúp phát triển ứng dụng: nếu bạn muốn thay đổi một trong các bước xử lý, ví dụ để thay đổi cấu trúc của một index hay cache, bạn chỉ cần chạy lại code biến đổi mới trên toàn bộ tập dữ liệu đầu vào để dẫn xuất lại đầu ra. Tương tự, nếu có gì đó xảy ra sai, bạn có thể sửa code và xử lý lại dữ liệu để phục hồi.
Các quá trình này khá giống với những gì cơ sở dữ liệu đã làm nội bộ, vì vậy chúng ta đã định hình lại ý tưởng về các ứng dụng dataflow như việc unbundling (tháo gỡ) các thành phần của một cơ sở dữ liệu, và xây dựng ứng dụng bằng cách kết hợp các thành phần được kết hợp lỏng lẻo này.
Trạng thái dẫn xuất có thể được cập nhật bằng cách quan sát các thay đổi trong dữ liệu nền. Hơn nữa, bản thân trạng thái dẫn xuất có thể tiếp tục được quan sát bởi các consumer hạ nguồn. Chúng ta thậm chí có thể đưa dataflow này tất cả các bước đến thiết bị đầu cuối của người dùng đang hiển thị dữ liệu, và do đó xây dựng các giao diện người dùng tự động cập nhật để phản ánh các thay đổi dữ liệu và tiếp tục hoạt động ngoại tuyến.
Tiếp theo, chúng ta đã thảo luận về cách đảm bảo rằng tất cả quá trình xử lý này vẫn đúng đắn khi có lỗi. Chúng ta đã thấy rằng các đảm bảo integrity mạnh mẽ có thể được triển khai có khả năng mở rộng với xử lý sự kiện bất đồng bộ, bằng cách sử dụng các định danh yêu cầu end-to-end để làm cho các thao tác idempotent và bằng cách kiểm tra các ràng buộc bất đồng bộ. Các client có thể chờ cho đến khi kiểm tra đã qua, hoặc tiến hành mà không chờ nhưng chấp nhận rủi ro phải xin lỗi về vi phạm ràng buộc. Cách tiếp cận này có khả năng mở rộng và bền vững hơn nhiều so với cách tiếp cận truyền thống sử dụng distributed transactions, và phù hợp với cách nhiều quy trình kinh doanh hoạt động trong thực tế.
Bằng cách cấu trúc các ứng dụng xung quanh dataflow và kiểm tra các ràng buộc bất đồng bộ, chúng ta có thể tránh hầu hết các điều phối và tạo ra các hệ thống duy trì integrity nhưng vẫn hoạt động tốt, ngay cả trong các kịch bản phân tán địa lý và khi có lỗi. Sau đó chúng ta đã nói một chút về việc sử dụng auditing để xác minh tính toàn vẹn của dữ liệu và phát hiện tình trạng hỏng, và nhận thấy rằng các kỹ thuật được sử dụng bởi blockchain cũng có sự tương đồng với các hệ thống dựa trên sự kiện.
Footnotes
References
Rachid Belaid. Postgres Full-Text Search is Good Enough! rachbelaid.com, July 2015. Archived at perma.cc/ZVP9-YDCB ↩︎ ↩︎
Philippe Ajoux, Nathan Bronson, Sanjeev Kumar, Wyatt Lloyd, and Kaushik Veeraraghavan. Challenges to Adopting Stronger Consistency at Scale. At 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015. ↩︎ ↩︎
Pat Helland and Dave Campbell. Building on Quicksand. At 4th Biennial Conference on Innovative Data Systems Research (CIDR), January 2009. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Jessica Kerr. Provenance and Causality in Distributed Systems. jessitron.com, September 2016. Archived at perma.cc/DTD2-F8ZM ↩︎ ↩︎ ↩︎
Jay Kreps. The Log: What Every Software Engineer Should Know About Real-Time Data’s Unifying Abstraction. engineering.linkedin.com, December 2013. Archived at perma.cc/2JHR-FR64 ↩︎ ↩︎ ↩︎ ↩︎
Pat Helland. Life Beyond Distributed Transactions: An Apostate’s Opinion. At 3rd Biennial Conference on Innovative Data Systems Research (CIDR), January 2007. ↩︎ ↩︎
Lionel A. Smith. The Broad Gauge Story. Journal of the Monmouthshire Railway Society, Summer 1985. Archived at perma.cc/DDK9-JA6X ↩︎
Jacqueline Xu. Online Migrations at Scale. stripe.com, February 2017. Archived at perma.cc/ZQY2-EAU2 ↩︎
Flavio Santos and Robert Stephenson. Changing the Wheels on a Moving Bus — Spotify’s Event Delivery Migration. engineering.atspotify.com, October 2021. Archived at perma.cc/5C4V-G8EV ↩︎
Molly Bartlett Dishman and Martin Fowler. Agile Architecture. At O’Reilly Software Architecture Conference, March 2015. ↩︎
Nathan Marz and James Warren. Big Data: Principles and Best Practices of Scalable Real-Time Data Systems. Manning, 2015. ISBN: 978-1-617-29034-3 ↩︎
Jay Kreps. Questioning the Lambda Architecture. oreilly.com, July 2014. Archived at perma.cc/PGH6-XUCH ↩︎ ↩︎
Raul Castro Fernandez, Peter Pietzuch, Jay Kreps, Neha Narkhede, Jun Rao, Joel Koshy, Dong Lin, Chris Riccomini, and Guozhang Wang. Liquid: Unifying Nearline and Offline Big Data Integration. At 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015. ↩︎
Dennis M. Ritchie and Ken Thompson. The UNIX Time-Sharing System. Communications of the ACM, volume 17, issue 7, pages 365–375, July 1974. doi:10.1145/361011.361061 ↩︎ ↩︎
Wes McKinney. The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future. wesmckinney.com, September 2023. Archived at perma.cc/J9SJ-886N ↩︎
Eric A. Brewer and Joseph M. Hellerstein. CS262a: Advanced Topics in Computer Systems. Lecture notes, University of California, Berkeley, cs.berkeley.edu, August 2011. Archived at perma.cc/TE79-LGWU ↩︎
Michael Stonebraker. The Case for Polystores. wp.sigmod.org, July 2015. Archived at perma.cc/G7J2-KR45 ↩︎ ↩︎
Jennie Duggan, Aaron J. Elmore, Michael Stonebraker, Magda Balazinska, Bill Howe, Jeremy Kepner, Sam Madden, David Maier, Tim Mattson, and Stan Zdonik. The BigDAWG Polystore System. ACM SIGMOD Record, volume 44, issue 2, pages 11–16, June 2015. doi:10.1145/2814710.2814713 ↩︎
David B. Lomet, Alan Fekete, Gerhard Weikum, and Mike Zwilling. Unbundling Transaction Services in the Cloud. At 4th Biennial Conference on Innovative Data Systems Research (CIDR), January 2009. ↩︎
Martin Kleppmann and Jay Kreps. Kafka, Samza and the Unix Philosophy of Distributed Data. IEEE Data Engineering Bulletin, volume 38, issue 4, pages 4–14, December 2015. ↩︎
John Hugg. Winning Now and in the Future: Where Volt Active Data Shines. voltactivedata.com, March 2016. Archived at perma.cc/44MP-3MWM ↩︎
Felienne Hermans. Spreadsheets Are Code. At Code Mesh, November 2015. ↩︎
Dan Bricklin and Bob Frankston. VisiCalc: Information from Its Creators. danbricklin.com. Archived at archive.org ↩︎
D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, and Michael Young. Machine Learning: The High-Interest Credit Card of Technical Debt. At NIPS Workshop on Software Engineering for Machine Learning (SE4ML), December 2014. Archived at https://perma.cc/M3MD-U7WL ↩︎
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Feral Concurrency Control: An Empirical Investigation of Modern Application Integrity. At ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2737784 ↩︎ ↩︎
Guy Steele. Re: Need for Macros (Was Re: Icon). email to ll1-discuss mailing list, people.csail.mit.edu, December 2001. Archived at perma.cc/K9X8-CJ65 ↩︎
Ben Stopford. Microservices in a Streaming World. At QCon London, March 2016. ↩︎ ↩︎
Adam Bellemare. Building Event-Driven Microservices, 2nd Edition. O’Reilly Media, 2025. ↩︎
Christian Posta. Why Microservices Should Be Event Driven: Autonomy vs Authority. blog.christianposta.com, May 2016. Archived at perma.cc/E6N9-3X92 ↩︎
Alex Feyerke. Designing Offline-First Web Apps. alistapart.com, December 2013. Archived at perma.cc/WH7R-S2DS ↩︎
Martin Kleppmann. Turning the Database Inside-out with Apache Samza. at Strange Loop, September 2014. Archived at perma.cc/U6E8-A9MT ↩︎ ↩︎
Sebastian Burckhardt, Daan Leijen, Jonathan Protzenko, and Manuel Fähndrich. Global Sequence Protocol: A Robust Abstraction for Replicated Shared State. At 29th European Conference on Object-Oriented Programming (ECOOP), July 2015. doi:10.4230/LIPIcs.ECOOP.2015.568 ↩︎ ↩︎
Evan Czaplicki and Stephen Chong. Asynchronous Functional Reactive Programming for GUIs. At 34th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), June 2013. doi:10.1145/2491956.2462161 ↩︎
Eno Thereska, Damian Guy, Michael Noll, and Neha Narkhede. Unifying Stream Processing and Interactive Queries in Apache Kafka. confluent.io, October 2016. Archived at perma.cc/W8JG-EAZF ↩︎
Frank McSherry. Dataflow as Database. github.com, July 2016. Archived at perma.cc/384D-DUFH ↩︎
Peter Alvaro. I See What You Mean. At Strange Loop, September 2015. ↩︎
Nathan Marz. Trident: A High-Level Abstraction for Realtime Computation. blog.x.com, August 2012. Archived at archive.org ↩︎
Edi Bice. Low Latency Web Scale Fraud Prevention with Apache Samza, Kafka and Friends. At Merchant Risk Council MRC Vegas Conference, March 2016. Archived at perma.cc/T3H5-QN3R ↩︎
Charity Majors. The Accidental DBA. charity.wtf, October 2016. Archived at perma.cc/6ANP-ARB6 ↩︎
Arthur J. Bernstein, Philip M. Lewis, and Shiyong Lu. Semantic Conditions for Correctness at Different Isolation Levels. At 16th International Conference on Data Engineering (ICDE), February 2000. doi:10.1109/ICDE.2000.839387 ↩︎
Sudhir Jorwekar, Alan Fekete, Krithi Ramamritham, and S. Sudarshan. Automating the Detection of Snapshot Isolation Anomalies. At 33rd International Conference on Very Large Data Bases (VLDB), September 2007. ↩︎
Kyle Kingsbury. Jespen: Distributed Systems Safety Research. jepsen.io. ↩︎
Michael Jouravlev. Redirect After Post. theserverside.com, August 2004. Archived at archive.org ↩︎
Jerome H. Saltzer, David P. Reed, and David D. Clark. End-to-End Arguments in System Design. ACM Transactions on Computer Systems, volume 2, issue 4, pages 277–288, November 1984. doi:10.1145/357401.357402 ↩︎ ↩︎
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Coordination Avoidance in Database Systems. Proceedings of the VLDB Endowment, volume 8, issue 3, pages 185–196, November 2014. doi:10.14778/2735508.2735509 ↩︎ ↩︎
Alex Yarmula. Strong Consistency in Manhattan. blog.x.com, March 2016. Archived at archive.org ↩︎
Martin Kleppmann, Alastair R. Beresford, and Boerge Svingen. Online Event Processing: Achieving consistency where distributed transactions have failed. Communications of the ACM, volume 62, issue 5, pages 43-49, May 2019. doi:10.1145/3312527 ↩︎
Jim Gray. The Transaction Concept: Virtues and Limitations. At 7th International Conference on Very Large Data Bases (VLDB), September 1981. Archived at perma.cc/8VPT-N5H6 ↩︎
Hector Garcia-Molina and Kenneth Salem. Sagas. At ACM International Conference on Management of Data (SIGMOD), May 1987. doi:10.1145/38713.38742 ↩︎
Annamalai Gurusami and Daniel Price. Bug #73170: Duplicates in Unique Secondary Index Because of Fix of Bug#68021. bugs.mysql.com, July 2014. Archived at perma.cc/P6BV-W7JJ ↩︎
Gary Fredericks. Postgres Serializability Bug. github.com, September 2015. Archived at perma.cc/N8UP-2822 ↩︎
Xiao Chen. HDFS DataNode Scanners and Disk Checker Explained. blog.cloudera.com, December 2016. Archived at perma.cc/6S36-X98L ↩︎
Daniel Persson. How does Ceph scrubbing work? youtube.com, March 2022. ↩︎
Jay Kreps. Getting Real About Distributed System Reliability. blog.empathybox.com, March 2012. Archived at perma.cc/9B5Q-AEBW ↩︎
Martin Fowler. The LMAX Architecture. martinfowler.com, July 2011. Archived at perma.cc/5AV4-N6RJ ↩︎
Sam Stokes. Move Fast with Confidence. five-eights.com, July 2016. Archived at perma.cc/J8C6-DHXB ↩︎
Ralph C. Merkle. A Digital Signature Based on a Conventional Encryption Function. At CRYPTO ‘87, August 1987. doi:10.1007/3-540-48184-2_32 ↩︎
Ben Laurie. Certificate Transparency. ACM Queue, volume 12, issue 8, pages 10-19, August 2014. doi:10.1145/2668152.2668154 ↩︎
Mark D. Ryan. Enhanced Certificate Transparency and End-to-End Encrypted Mail. At Network and Distributed System Security Symposium (NDSS), February 2014. doi:10.14722/ndss.2014.23379 ↩︎