12. Stream Processing
Một hệ thống phức tạp hoạt động được thì hầu như đều được phát triển từ một hệ thống đơn giản đã hoạt động. Mệnh đề ngược lại dường như cũng đúng: Một hệ thống phức tạp được thiết kế từ đầu thì không bao giờ hoạt động được và cũng không thể khiến nó hoạt động được.
John Gall, Systemantics (1975)
A NOTE FOR EARLY RELEASE READERS
With Early Release ebooks, you get books in their earliest form—the author’s raw and unedited content as they write—so you can take advantage of these technologies long before the official release of these titles.
This will be the 12th chapter of the final book. The GitHub repo for this book is https://github.com/ept/ddia2-feedback.
If you’d like to be actively involved in reviewing and commenting on this draft, please reach out on GitHub.
Trong Chương 11 chúng ta đã thảo luận về xử lý theo lô (batch processing), tức là các kỹ thuật đọc một tập hợp tệp đầu vào và tạo ra một tập hợp tệp đầu ra mới. Đầu ra là một dạng dữ liệu dẫn xuất (derived data): đó là tập dữ liệu có thể được tạo lại bằng cách chạy lại quá trình batch nếu cần. Chúng ta đã thấy cách ý tưởng đơn giản nhưng mạnh mẽ này có thể được dùng để tạo chỉ mục tìm kiếm, hệ thống gợi ý, phân tích dữ liệu và nhiều thứ khác.
Tuy nhiên, trong suốt Chương 11 có một giả định lớn vẫn còn tồn tại: đầu vào là hữu hạn (bounded), tức là có kích thước đã biết và cố định, nên quá trình batch biết khi nào nó đã đọc hết đầu vào. Ví dụ, phép sắp xếp vốn là trung tâm của MapReduce phải đọc toàn bộ đầu vào trước khi có thể bắt đầu tạo ra đầu ra: có thể bản ghi đầu vào cuối cùng lại chính là bản ghi có khóa nhỏ nhất, do đó phải là bản ghi đầu ra đầu tiên, vì vậy không thể xuất kết quả sớm hơn.
Trên thực tế, rất nhiều dữ liệu là vô hạn (unbounded) vì nó đến dần dần theo thời gian: người dùng của bạn tạo ra dữ liệu hôm qua và hôm nay, và họ sẽ tiếp tục tạo ra thêm dữ liệu vào ngày mai. Trừ khi doanh nghiệp của bạn đóng cửa, quá trình này không bao giờ kết thúc, và do đó tập dữ liệu không bao giờ “hoàn chỉnh” theo bất kỳ nghĩa nào có ý nghĩa 1. Vì vậy, các bộ xử lý batch phải nhân tạo chia dữ liệu thành các khối với thời lượng cố định: ví dụ, xử lý dữ liệu của một ngày vào cuối mỗi ngày, hoặc xử lý dữ liệu của một giờ vào cuối mỗi giờ.
Vấn đề với các quá trình batch chạy mỗi ngày là những thay đổi trong đầu vào chỉ được phản ánh trong đầu ra sau một ngày, điều này quá chậm đối với nhiều người dùng thiếu kiên nhẫn. Để giảm độ trễ, chúng ta có thể chạy xử lý thường xuyên hơn, chẳng hạn xử lý dữ liệu của một giây vào cuối mỗi giây, hoặc thậm chí liên tục, hoàn toàn bỏ qua các khoảng thời gian cố định và đơn giản là xử lý mọi sự kiện ngay khi nó xảy ra. Đó là ý tưởng đằng sau xử lý luồng (stream processing).
Nói chung, một “luồng” (stream) là dữ liệu được cung cấp tăng dần theo thời gian. Khái niệm này xuất hiện ở nhiều nơi: trong stdin và stdout của Unix, các ngôn ngữ lập trình (lazy lists, tức danh sách lười biếng) 2, API hệ thống tệp (chẳng hạn FileInputStream của Java), kết nối TCP, phát âm thanh và video qua internet, v.v.
Trong chương này chúng ta sẽ xem xét các luồng sự kiện (event streams) như một cơ chế quản lý dữ liệu: phiên bản vô hạn và được xử lý tăng dần tương ứng với dữ liệu batch mà chúng ta đã thấy trong chương trước. Đầu tiên chúng ta sẽ thảo luận về cách các luồng được biểu diễn, lưu trữ và truyền qua mạng. Trong “Cơ sở dữ liệu và Luồng” chúng ta sẽ tìm hiểu mối quan hệ giữa luồng và cơ sở dữ liệu. Cuối cùng, trong “Xử lý Luồng” chúng ta sẽ khám phá các phương pháp và công cụ để xử lý liên tục các luồng đó, cũng như cách chúng có thể được dùng để xây dựng ứng dụng.
Truyền Luồng Sự Kiện
Trong thế giới xử lý batch, đầu vào và đầu ra của một job là các tệp (có thể trên một hệ thống tệp phân tán). Phiên bản tương đương với streaming trông như thế nào?
Khi đầu vào là một tệp (một chuỗi byte), bước xử lý đầu tiên thường là phân tích cú pháp nó thành một chuỗi các bản ghi. Trong ngữ cảnh xử lý luồng, một bản ghi thường được gọi là một sự kiện (event), nhưng về bản chất là cùng một thứ: một đối tượng nhỏ, tự chứa, bất biến, chứa thông tin chi tiết về một điều gì đó đã xảy ra tại một thời điểm nào đó. Một sự kiện thường chứa một dấu thời gian cho biết nó đã xảy ra khi nào theo đồng hồ thực (xem “Monotonic Versus Time-of-Day Clocks”).
Ví dụ, điều đã xảy ra có thể là một hành động mà người dùng thực hiện, chẳng hạn xem một trang hoặc thực hiện một giao dịch mua. Nó cũng có thể xuất phát từ máy móc, chẳng hạn một phép đo định kỳ từ cảm biến nhiệt độ, hoặc một chỉ số sử dụng CPU. Trong ví dụ về “Batch Processing with Unix Tools”, mỗi dòng của log máy chủ web là một sự kiện.
Một sự kiện có thể được mã hóa dưới dạng chuỗi văn bản, hoặc JSON, hoặc có thể ở dạng nhị phân, như đã thảo luận trong Chương 5. Cách mã hóa này cho phép bạn lưu trữ một sự kiện, ví dụ bằng cách nối thêm nó vào một tệp, chèn vào một bảng quan hệ, hoặc ghi vào một cơ sở dữ liệu tài liệu. Nó cũng cho phép bạn gửi sự kiện qua mạng đến một nút khác để xử lý.
Trong xử lý batch, một tệp được ghi một lần và sau đó có thể được đọc bởi nhiều job. Tương tự, trong thuật ngữ streaming, một sự kiện được tạo ra một lần bởi một producer (còn gọi là publisher hoặc sender, tức nhà sản xuất), và sau đó có thể được xử lý bởi nhiều consumer (subscriber hoặc recipient, tức người tiêu dùng) 3. Trong hệ thống tệp, một tên tệp xác định một tập hợp các bản ghi liên quan; trong hệ thống streaming, các sự kiện liên quan thường được nhóm lại thành một topic (chủ đề) hoặc stream (luồng).
Về nguyên tắc, một tệp hoặc cơ sở dữ liệu là đủ để kết nối producer và consumer: một producer ghi mọi sự kiện nó tạo ra vào kho dữ liệu, và mỗi consumer định kỳ thăm dò kho dữ liệu để kiểm tra các sự kiện đã xuất hiện kể từ lần chạy trước. Đây về cơ bản là điều mà một quá trình batch làm khi nó xử lý dữ liệu của một ngày vào cuối mỗi ngày.
Tuy nhiên, khi chuyển sang xử lý liên tục với độ trễ thấp, việc thăm dò (polling) trở nên tốn kém nếu kho dữ liệu không được thiết kế cho loại sử dụng này. Bạn thăm dò càng thường xuyên, tỷ lệ phần trăm yêu cầu trả về sự kiện mới càng thấp, và do đó chi phí overhead càng cao. Thay vào đó, tốt hơn là để consumer được thông báo khi có sự kiện mới xuất hiện.
Theo truyền thống, cơ sở dữ liệu không hỗ trợ cơ chế thông báo loại này rất tốt: cơ sở dữ liệu quan hệ thường có trigger (trình kích hoạt), có thể phản ứng với một thay đổi (ví dụ, một hàng được chèn vào bảng), nhưng chúng rất hạn chế về những gì chúng có thể làm và đã phần nào là một tính năng phụ trong thiết kế cơ sở dữ liệu 4. Thay vào đó, các công cụ chuyên dụng đã được phát triển cho mục đích cung cấp thông báo sự kiện.
Hệ Thống Nhắn Tin
Một phương pháp phổ biến để thông báo cho consumer về các sự kiện mới là sử dụng hệ thống nhắn tin (messaging system): một producer gửi một tin nhắn chứa sự kiện, sau đó được đẩy đến các consumer. Chúng ta đã đề cập đến các hệ thống này trước đây trong “Event-Driven Architectures”, nhưng bây giờ chúng ta sẽ đi sâu hơn vào chi tiết.
Một kênh truyền thông trực tiếp như Unix pipe hoặc kết nối TCP giữa producer và consumer sẽ là một cách đơn giản để triển khai hệ thống nhắn tin. Tuy nhiên, hầu hết các hệ thống nhắn tin mở rộng trên mô hình cơ bản này. Đặc biệt, Unix pipe và TCP kết nối chính xác một người gửi với một người nhận, trong khi một hệ thống nhắn tin cho phép nhiều nút producer gửi tin nhắn đến cùng một topic và cho phép nhiều nút consumer nhận tin nhắn trong một topic.
Trong mô hình publish/subscribe này, các hệ thống khác nhau áp dụng nhiều cách tiếp cận khác nhau, và không có một câu trả lời đúng duy nhất cho mọi mục đích. Để phân biệt các hệ thống, đặc biệt hữu ích khi đặt ra hai câu hỏi sau:
Điều gì xảy ra nếu producer gửi tin nhắn nhanh hơn consumer có thể xử lý? Nói chung, có ba tùy chọn: hệ thống có thể loại bỏ tin nhắn, lưu đệm tin nhắn trong một hàng đợi, hoặc áp dụng backpressure (áp lực ngược, còn gọi là flow control, kiểm soát luồng; tức là chặn producer không gửi thêm tin nhắn). Ví dụ, Unix pipe và TCP sử dụng backpressure: chúng có một bộ đệm nhỏ có kích thước cố định, và nếu đầy, người gửi bị chặn cho đến khi người nhận lấy dữ liệu ra khỏi bộ đệm (xem “Network congestion and queueing”).
Nếu tin nhắn được đệm trong một hàng đợi, điều quan trọng là phải hiểu điều gì xảy ra khi hàng đợi đó phát triển. Hệ thống có bị sập nếu hàng đợi không còn vừa trong bộ nhớ, hay nó ghi tin nhắn ra đĩa? Trong trường hợp sau, việc truy cập đĩa ảnh hưởng đến hiệu năng của hệ thống nhắn tin như thế nào 5, và điều gì xảy ra khi đĩa đầy 6?
Điều gì xảy ra nếu các nút bị sập hoặc tạm thời ngoại tuyến, có tin nhắn nào bị mất không? Như với cơ sở dữ liệu, tính bền vững (durability) có thể yêu cầu một số kết hợp giữa ghi ra đĩa và/hoặc sao chép (xem thanh bên “Replication and Durability”), điều này có chi phí nhất định. Nếu bạn có thể chấp nhận đôi khi mất tin nhắn, bạn có thể đạt được thông lượng cao hơn và độ trễ thấp hơn trên cùng phần cứng.
Việc mất tin nhắn có chấp nhận được hay không phụ thuộc rất nhiều vào ứng dụng. Ví dụ, với các số đo cảm biến và chỉ số được truyền định kỳ, một điểm dữ liệu bị thiếu đôi khi có thể không quan trọng, vì một giá trị cập nhật sẽ được gửi sau một thời gian ngắn nữa. Tuy nhiên, hãy cẩn thận rằng nếu một số lượng lớn tin nhắn bị loại bỏ, có thể không rõ ràng ngay lập tức rằng các chỉ số là không chính xác 7. Nếu bạn đang đếm các sự kiện, điều quan trọng hơn là chúng được cung cấp đáng tin cậy, vì mỗi tin nhắn bị mất đồng nghĩa với bộ đếm không chính xác.
Một tính chất tốt của các hệ thống xử lý batch mà chúng ta đã khám phá trong Chương 11 là chúng cung cấp đảm bảo độ tin cậy mạnh: các tác vụ thất bại được tự động thử lại, và đầu ra một phần từ các tác vụ thất bại tự động bị loại bỏ. Điều này có nghĩa là đầu ra giống như thể không có lỗi nào xảy ra, điều này giúp đơn giản hóa mô hình lập trình. Ở phần sau của chương này chúng ta sẽ xem xét cách chúng ta có thể cung cấp các đảm bảo tương tự trong ngữ cảnh streaming.
Nhắn tin trực tiếp từ producer đến consumer
Một số hệ thống nhắn tin sử dụng giao tiếp mạng trực tiếp giữa producer và consumer mà không đi qua các nút trung gian:
UDP multicast được sử dụng rộng rãi trong ngành tài chính cho các luồng như feed thị trường chứng khoán, nơi độ trễ thấp là quan trọng 8. Mặc dù bản thân UDP là không đáng tin cậy, các giao thức ở tầng ứng dụng có thể khôi phục các gói tin bị mất (producer phải nhớ các gói tin nó đã gửi để có thể truyền lại chúng theo yêu cầu).
Các thư viện nhắn tin không có broker như ZeroMQ và nanomsg có cách tiếp cận tương tự, triển khai nhắn tin publish/subscribe qua TCP hoặc IP multicast.
Một số agent thu thập chỉ số, chẳng hạn StatsD 9 sử dụng nhắn tin UDP không đáng tin cậy để thu thập chỉ số từ tất cả các máy trên mạng và giám sát chúng. (Trong giao thức StatsD, các chỉ số bộ đếm chỉ chính xác nếu tất cả tin nhắn đều được nhận; sử dụng UDP làm cho các chỉ số tốt nhất là gần đúng 10. Xem thêm “TCP Versus UDP”.)
Nếu consumer cung cấp một dịch vụ trên mạng, producer có thể thực hiện yêu cầu HTTP hoặc RPC trực tiếp (xem “Dataflow Through Services: REST and RPC”) để đẩy tin nhắn đến consumer. Đây là ý tưởng đằng sau webhook 11, một mẫu trong đó URL callback của một dịch vụ được đăng ký với dịch vụ khác, và dịch vụ đó gửi yêu cầu đến URL đó bất cứ khi nào có sự kiện xảy ra.
Mặc dù các hệ thống nhắn tin trực tiếp này hoạt động tốt trong các tình huống mà chúng được thiết kế, chúng nói chung yêu cầu mã ứng dụng phải nhận thức về khả năng mất tin nhắn. Các lỗi mà chúng có thể chịu đựng khá hạn chế: ngay cả khi các giao thức phát hiện và truyền lại các gói tin bị mất trong mạng, chúng nói chung giả định rằng producer và consumer luôn trực tuyến.
Nếu một consumer ngoại tuyến, nó có thể bỏ lỡ các tin nhắn được gửi trong khi nó không thể truy cập. Một số giao thức cho phép producer thử lại việc giao tin nhắn thất bại, nhưng cách tiếp cận này có thể thất bại nếu producer bị sập, mất bộ đệm các tin nhắn mà nó được cho là phải thử lại.
Message broker
Một lựa chọn thay thế được sử dụng rộng rãi là gửi tin nhắn qua một message broker (còn gọi là message queue, hàng đợi tin nhắn), về cơ bản là một loại cơ sở dữ liệu được tối ưu hóa để xử lý các luồng tin nhắn 12. Nó chạy như một máy chủ, với producer và consumer kết nối đến nó như các client. Producer ghi tin nhắn vào broker, và consumer nhận chúng bằng cách đọc từ broker.
Bằng cách tập trung hóa dữ liệu trong broker, các hệ thống này có thể dễ dàng chịu đựng các client đến và đi (kết nối, ngắt kết nối và bị sập), và câu hỏi về tính bền vững được chuyển sang broker. Một số message broker chỉ giữ tin nhắn trong bộ nhớ, trong khi các broker khác (tùy thuộc vào cấu hình) ghi chúng ra đĩa để chúng không bị mất trong trường hợp broker bị sập. Khi gặp consumer chậm, chúng nói chung cho phép xếp hàng không giới hạn (trái ngược với việc loại bỏ tin nhắn hoặc backpressure), mặc dù lựa chọn này cũng có thể phụ thuộc vào cấu hình.
Một hệ quả của việc xếp hàng là consumer nói chung là bất đồng bộ (asynchronous): khi producer gửi một tin nhắn, nó thường chỉ chờ broker xác nhận rằng nó đã lưu đệm tin nhắn và không chờ tin nhắn được xử lý bởi consumer. Việc giao tin nhắn cho consumer sẽ xảy ra tại một thời điểm không xác định trong tương lai, thường trong một phần nhỏ của giây, nhưng đôi khi lâu hơn đáng kể nếu có tồn đọng trong hàng đợi.
So sánh message broker và cơ sở dữ liệu
Một số message broker thậm chí có thể tham gia vào các giao thức two-phase commit sử dụng XA hoặc JTA (xem “Distributed Transactions Across Different Systems”). Tính năng này làm cho chúng khá giống với cơ sở dữ liệu về bản chất, mặc dù vẫn có những sự khác biệt thực tế quan trọng giữa message broker và cơ sở dữ liệu:
Cơ sở dữ liệu thường giữ dữ liệu cho đến khi nó được xóa một cách rõ ràng, trong khi một số message broker tự động xóa một tin nhắn khi nó đã được giao thành công đến consumer. Các message broker như vậy không phù hợp cho lưu trữ dữ liệu lâu dài.
Vì chúng nhanh chóng xóa tin nhắn, hầu hết message broker giả định rằng tập làm việc của chúng khá nhỏ, tức là các hàng đợi ngắn. Nếu broker cần đệm nhiều tin nhắn vì consumer chậm (có thể tràn tin nhắn ra đĩa nếu chúng không còn vừa trong bộ nhớ), mỗi tin nhắn riêng lẻ mất nhiều thời gian hơn để xử lý, và thông lượng tổng thể có thể giảm sút 5.
Cơ sở dữ liệu thường hỗ trợ chỉ mục thứ cấp và nhiều cách tìm kiếm dữ liệu bằng ngôn ngữ truy vấn, trong khi message broker thường hỗ trợ một số cách đăng ký một tập hợp con các topic phù hợp với một mẫu nào đó. Cả hai đều là cách để client chọn phần dữ liệu mà nó muốn biết, nhưng cơ sở dữ liệu thường cung cấp chức năng truy vấn nâng cao hơn nhiều.
Khi truy vấn một cơ sở dữ liệu, kết quả thường dựa trên một ảnh chụp (snapshot) tại một thời điểm của dữ liệu; nếu một client khác sau đó ghi gì đó vào cơ sở dữ liệu làm thay đổi kết quả truy vấn, client đầu tiên không biết rằng kết quả trước đó của nó hiện đã lỗi thời (trừ khi nó lặp lại truy vấn, hoặc thăm dò các thay đổi). Ngược lại, message broker không hỗ trợ các truy vấn tùy ý và không cho phép cập nhật tin nhắn sau khi chúng được gửi, nhưng chúng thông báo cho client khi dữ liệu thay đổi (tức là khi có tin nhắn mới).
Đây là quan điểm truyền thống về message broker, được đóng gói trong các tiêu chuẩn như JMS 13 và AMQP 14 và được triển khai trong phần mềm như RabbitMQ, ActiveMQ, HornetQ, Qpid, TIBCO Enterprise Message Service, IBM MQ, Azure Service Bus, và Google Cloud Pub/Sub 15. Mặc dù có thể sử dụng cơ sở dữ liệu như hàng đợi, việc tinh chỉnh chúng để có hiệu năng tốt không đơn giản 16.
Nhiều consumer
Khi nhiều consumer đọc tin nhắn trong cùng một topic, hai mẫu chính của nhắn tin được sử dụng, như minh họa trong Hình 12-1:
- Cân bằng tải (Load balancing)
Mỗi tin nhắn được giao đến một trong số các consumer, vì vậy các consumer có thể chia sẻ công việc xử lý tin nhắn trong topic. Broker có thể phân công tin nhắn cho các consumer một cách tùy ý. Mẫu này hữu ích khi các tin nhắn tốn kém để xử lý, và do đó bạn muốn có thể thêm consumer để song song hóa việc xử lý. (Trong AMQP, bạn có thể triển khai cân bằng tải bằng cách có nhiều client tiêu thụ từ cùng một hàng đợi, và trong JMS nó được gọi là shared subscription, đăng ký chia sẻ.)
- Fan-out (Phát rộng)
Mỗi tin nhắn được giao đến tất cả các consumer. Fan-out cho phép nhiều consumer độc lập cùng “theo dõi” cùng một luồng phát sóng tin nhắn mà không ảnh hưởng đến nhau, tương đương với streaming của việc có nhiều job batch khác nhau đọc cùng một tệp đầu vào. (Tính năng này được cung cấp bởi topic subscription trong JMS, và exchange binding trong AMQP.)
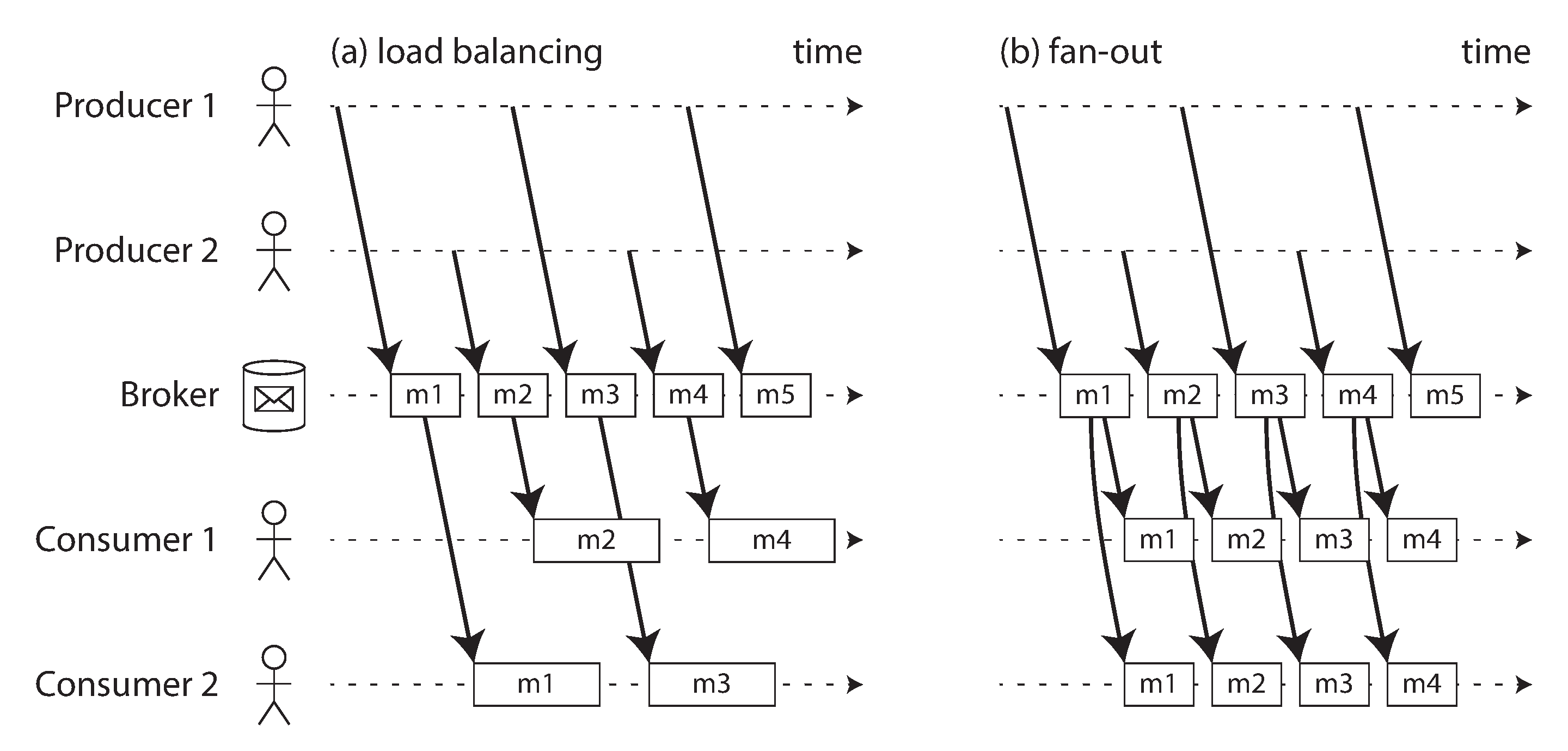
Hai mẫu có thể được kết hợp, ví dụ sử dụng tính năng consumer groups (nhóm consumer) của Kafka. Khi một consumer group đăng ký một topic, mỗi tin nhắn trong topic được gửi đến một trong các consumer trong nhóm (cân bằng tải giữa các consumer trong nhóm). Nếu hai consumer group riêng biệt đăng ký cùng một topic, mỗi tin nhắn được gửi đến một consumer trong mỗi nhóm (cung cấp fan-out giữa các consumer group).
Acknowledgment và tái giao tin nhắn
Consumer có thể bị sập bất cứ lúc nào, vì vậy có thể xảy ra trường hợp broker giao một tin nhắn đến consumer nhưng consumer không bao giờ xử lý nó, hoặc chỉ xử lý một phần trước khi bị sập. Để đảm bảo rằng tin nhắn không bị mất, message broker sử dụng acknowledgment (xác nhận): client phải thông báo rõ ràng cho broker khi nó đã hoàn thành xử lý một tin nhắn để broker có thể xóa nó khỏi hàng đợi.
Nếu kết nối đến một client bị đóng hoặc hết thời gian chờ mà không có broker nhận được acknowledgment, broker giả định rằng tin nhắn chưa được xử lý, và do đó nó giao tin nhắn một lần nữa cho một consumer khác. (Lưu ý rằng có thể xảy ra trường hợp tin nhắn thực sự đã được xử lý đầy đủ, nhưng acknowledgment bị mất trong mạng. Xử lý trường hợp này yêu cầu giao thức atomic commit, như đã thảo luận trong “Exactly-once message processing”, trừ khi thao tác là idempotent hoặc ngữ nghĩa exactly-once không được yêu cầu.)
Khi kết hợp với cân bằng tải, hành vi tái giao tin nhắn này có một hiệu ứng thú vị đối với thứ tự tin nhắn. Trong Hình 12-2, các consumer nói chung xử lý tin nhắn theo thứ tự chúng được producer gửi. Tuy nhiên, consumer 2 bị sập trong khi xử lý tin nhắn m3, cùng lúc consumer 1 đang xử lý tin nhắn m4. Tin nhắn m3 chưa được xác nhận sau đó được tái giao cho consumer 1, với kết quả là consumer 1 xử lý các tin nhắn theo thứ tự m4, m3, m5. Vì vậy, m3 và m4 không được giao theo thứ tự như khi chúng được producer 1 gửi.
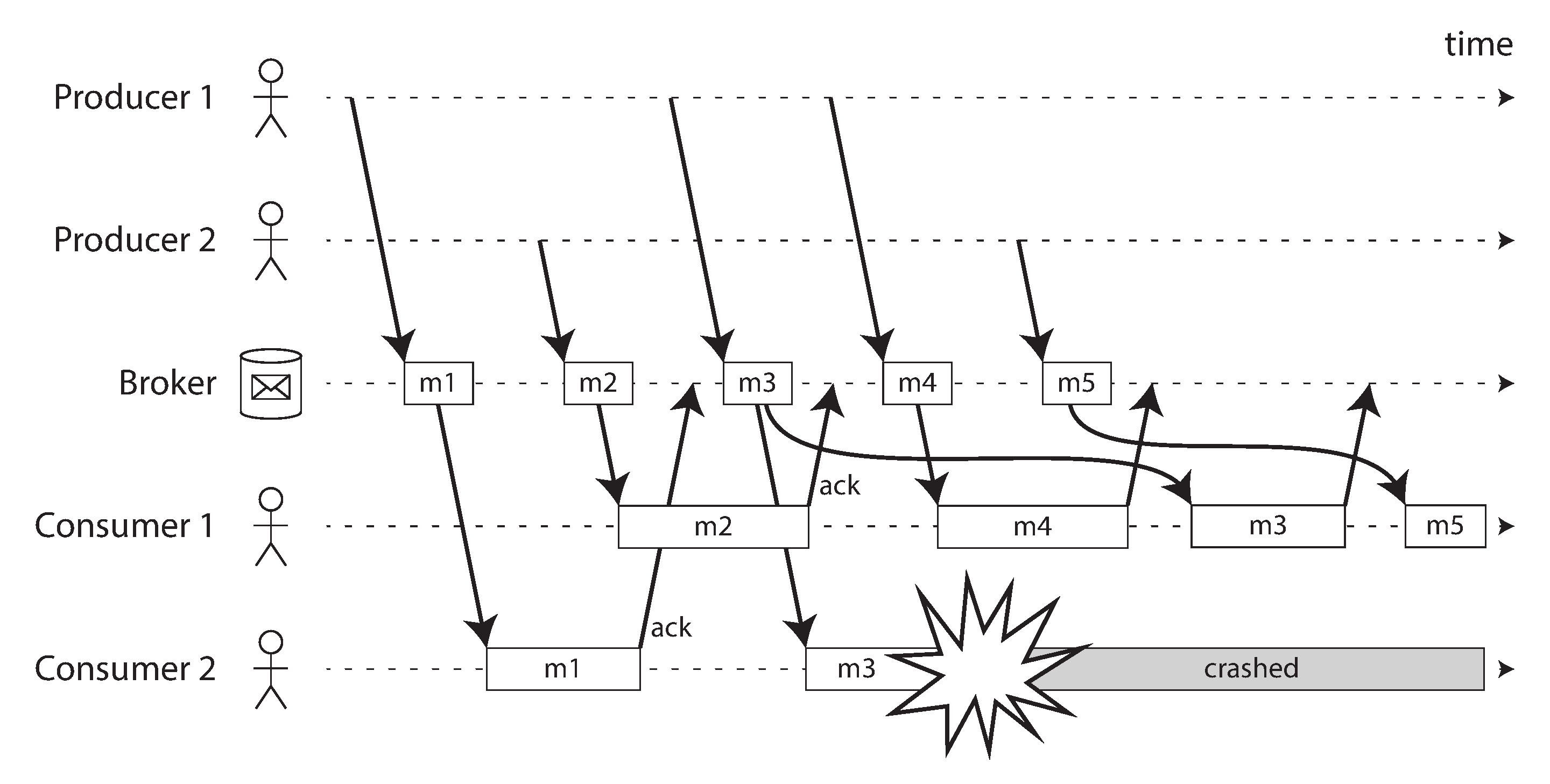
Ngay cả khi message broker cố gắng bảo toàn thứ tự tin nhắn (theo yêu cầu của cả tiêu chuẩn JMS và AMQP), sự kết hợp của cân bằng tải với tái giao tin nhắn chắc chắn dẫn đến việc tin nhắn bị sắp xếp lại. Để tránh vấn đề này, bạn có thể sử dụng một hàng đợi riêng biệt cho mỗi consumer (tức là không sử dụng tính năng cân bằng tải). Việc sắp xếp lại tin nhắn không phải là vấn đề nếu các tin nhắn hoàn toàn độc lập với nhau, nhưng có thể quan trọng nếu có các phụ thuộc nhân quả giữa các tin nhắn, như chúng ta sẽ thấy ở phần sau của chương.
Tái giao tin nhắn cũng có thể dẫn đến lãng phí tài nguyên, cạn kiệt tài nguyên, hoặc tắc nghẽn vĩnh viễn trong một luồng. Một kịch bản phổ biến là producer serialize một tin nhắn không đúng cách; ví dụ, bỏ qua một khóa bắt buộc trong đối tượng được mã hóa JSON. Bất kỳ consumer nào đọc tin nhắn sẽ kỳ vọng có khóa đó, và thất bại nếu thiếu nó. Không có acknowledgment nào được gửi, vì vậy broker sẽ gửi lại tin nhắn, điều này sẽ khiến một consumer khác thất bại. Vòng lặp này lặp lại vô thời hạn. Nếu broker đảm bảo thứ tự mạnh, không thể tiến thêm. Các broker cho phép sắp xếp lại tin nhắn có thể tiếp tục tiến triển, nhưng sẽ lãng phí tài nguyên vào các tin nhắn sẽ không bao giờ được xác nhận.
Dead letter queue (DLQ, hàng đợi thư chết) được sử dụng để xử lý vấn đề này. Thay vì giữ tin nhắn trong hàng đợi hiện tại và thử lại mãi mãi, tin nhắn được chuyển sang một hàng đợi khác để bỏ chặn consumer 17, 18. Việc giám sát thường được thiết lập trên dead letter queue, bất kỳ tin nhắn nào trong hàng đợi đều là lỗi. Khi một tin nhắn mới được phát hiện, người vận hành có thể quyết định xóa vĩnh viễn nó, chỉnh sửa thủ công và tái sản xuất tin nhắn, hoặc sửa mã consumer để xử lý tin nhắn một cách phù hợp. DLQ phổ biến trong hầu hết các hệ thống xếp hàng, nhưng các hệ thống nhắn tin dựa trên log như Apache Pulsar và các hệ thống xử lý luồng như Kafka Streams hiện cũng hỗ trợ chúng 19.
Message Broker Dựa Trên Log
Gửi một gói tin qua mạng hoặc thực hiện yêu cầu đến một dịch vụ mạng thường là một thao tác tạm thời không để lại dấu vết vĩnh cửu. Mặc dù có thể ghi lại nó vĩnh viễn (bằng cách chụp gói tin và ghi log), chúng ta thường không nghĩ theo cách đó. Các message broker theo phong cách AMQP/JMS kế thừa tư duy nhắn tin tạm thời này: mặc dù chúng có thể ghi tin nhắn ra đĩa, chúng nhanh chóng xóa tin nhắn sau khi chúng đã được giao đến consumer.
Cơ sở dữ liệu và hệ thống tệp có cách tiếp cận ngược lại: mọi thứ được ghi vào cơ sở dữ liệu hoặc tệp thường được kỳ vọng là được ghi lại vĩnh viễn, ít nhất là cho đến khi ai đó chọn rõ ràng để xóa nó.
Sự khác biệt trong tư duy này có ảnh hưởng lớn đến cách tạo ra dữ liệu dẫn xuất. Một tính năng quan trọng của các quá trình batch, như đã thảo luận trong Chương 11, là bạn có thể chạy chúng nhiều lần, thử nghiệm các bước xử lý, mà không có nguy cơ làm hỏng đầu vào (vì đầu vào là chỉ đọc). Điều này không đúng với nhắn tin theo phong cách AMQP/JMS: nhận một tin nhắn là mang tính hủy hoại nếu acknowledgment khiến nó bị xóa khỏi broker, vì vậy bạn không thể chạy lại cùng một consumer và kỳ vọng nhận được cùng kết quả.
Nếu bạn thêm một consumer mới vào hệ thống nhắn tin, nó thường chỉ bắt đầu nhận các tin nhắn được gửi sau khi nó được đăng ký; bất kỳ tin nhắn nào trước đó đều đã biến mất và không thể khôi phục. Hãy so sánh điều này với tệp và cơ sở dữ liệu, nơi bạn có thể thêm một client mới bất cứ lúc nào, và nó có thể đọc dữ liệu được ghi từ rất lâu trong quá khứ (miễn là nó chưa bị ghi đè hoặc xóa rõ ràng bởi ứng dụng).
Tại sao chúng ta không thể có một phiên bản kết hợp, kết hợp cách tiếp cận lưu trữ bền vững của cơ sở dữ liệu với cơ sở hạ tầng thông báo độ trễ thấp của nhắn tin? Đó là ý tưởng đằng sau message broker dựa trên log (log-based message broker), đã trở nên rất phổ biến trong những năm gần đây.
Sử dụng log để lưu trữ tin nhắn
Một log đơn giản là một chuỗi bản ghi chỉ nối thêm (append-only) trên đĩa. Chúng ta đã thảo luận về log trong ngữ cảnh của các engine lưu trữ có cấu trúc log và write-ahead log trong Chương 4, trong ngữ cảnh của sao chép trong Chương 6, và như một hình thức đồng thuận trong Chương 10.
Cùng một cấu trúc có thể được sử dụng để triển khai một message broker: một producer gửi một tin nhắn bằng cách nối thêm nó vào cuối log, và một consumer nhận tin nhắn bằng cách đọc log tuần tự. Nếu consumer đạt đến cuối log, nó chờ thông báo rằng một tin nhắn mới đã được nối thêm. Công cụ Unix tail -f, theo dõi một tệp để phát hiện dữ liệu được nối thêm, về cơ bản hoạt động như thế này.
Để mở rộng đến thông lượng cao hơn so với một đĩa đơn có thể cung cấp, log có thể được sharded (chia mảnh, theo nghĩa của Chương 7). Các shard khác nhau sau đó có thể được lưu trữ trên các máy khác nhau, làm cho mỗi shard trở thành một log riêng biệt có thể được đọc và ghi độc lập với các shard khác. Sau đó một topic có thể được định nghĩa là một nhóm các shard đều mang tin nhắn cùng loại. Cách tiếp cận này được minh họa trong Hình 12-3.
Trong mỗi shard, mà Kafka gọi là một partition (phân vùng), broker gán một số thứ tự tăng đơn điệu (monotonically increasing), hay còn gọi là offset (độ lệch), cho mọi tin nhắn (trong Hình 12-3, các số trong hộp là offset của tin nhắn). Số thứ tự như vậy có ý nghĩa vì một partition (shard) là chỉ nối thêm, do đó các tin nhắn trong một partition được sắp xếp hoàn toàn. Không có đảm bảo thứ tự nào giữa các partition khác nhau.
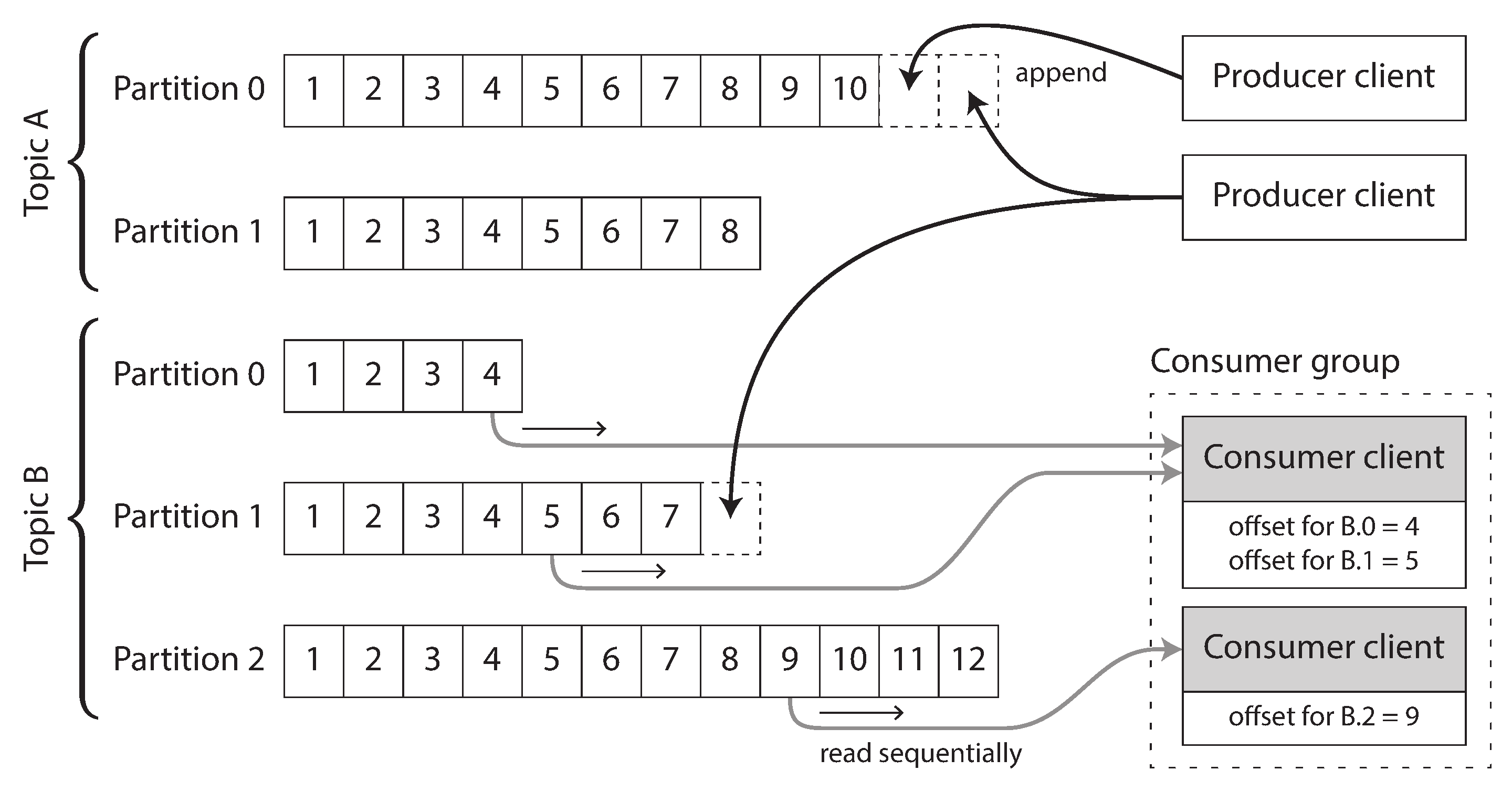
Apache Kafka 20 và Amazon Kinesis Streams là các message broker dựa trên log hoạt động như thế này. Google Cloud Pub/Sub có kiến trúc tương tự nhưng cung cấp API theo phong cách JMS thay vì trừu tượng log 15. Mặc dù các message broker này ghi tất cả tin nhắn ra đĩa, chúng có thể đạt thông lượng hàng triệu tin nhắn mỗi giây bằng cách chia mảnh trên nhiều máy, và chịu lỗi bằng cách sao chép tin nhắn 21, 22.
So sánh log với nhắn tin truyền thống
Cách tiếp cận dựa trên log hỗ trợ nhắn tin fan-out một cách dễ dàng, vì nhiều consumer có thể đọc log độc lập mà không ảnh hưởng đến nhau, đọc một tin nhắn không xóa nó khỏi log. Để đạt cân bằng tải trên một nhóm consumer, thay vì phân công các tin nhắn riêng lẻ cho các client consumer, broker có thể phân công toàn bộ shard cho các nút trong consumer group.
Mỗi client sau đó tiêu thụ tất cả tin nhắn trong các shard được giao cho nó. Thông thường, khi một consumer được giao một shard log, nó đọc các tin nhắn trong shard đó tuần tự, theo cách đơn luồng đơn giản. Cách tiếp cận cân bằng tải thô này có một số nhược điểm:
Số lượng nút chia sẻ công việc tiêu thụ một topic có thể tối đa bằng số lượng shard log trong topic đó, vì các tin nhắn trong cùng một shard được giao đến cùng một nút. (Có thể tạo một cơ chế cân bằng tải trong đó hai consumer chia sẻ công việc xử lý một shard bằng cách cả hai đều đọc toàn bộ tập tin nhắn, nhưng một trong số chúng chỉ xem xét các tin nhắn có offset chẵn trong khi cái còn lại xử lý các offset lẻ. Ngoài ra, bạn có thể phân phối xử lý tin nhắn qua một thread pool, nhưng cách đó làm phức tạp việc quản lý offset consumer. Nói chung, xử lý đơn luồng của một shard là tốt hơn, và tính song song có thể được tăng lên bằng cách sử dụng nhiều shard hơn.)
Nếu một tin nhắn đơn lẻ chậm xử lý, nó sẽ giữ lại việc xử lý các tin nhắn tiếp theo trong shard đó (một dạng head-of-line blocking, tắc nghẽn đầu hàng; xem “Describing Performance”).
Vì vậy, trong các tình huống mà tin nhắn có thể tốn kém để xử lý và bạn muốn song song hóa xử lý trên cơ sở từng tin nhắn, và khi thứ tự tin nhắn không quan trọng lắm, phong cách JMS/AMQP của message broker là tốt hơn. Mặt khác, trong các tình huống với thông lượng tin nhắn cao, nơi mỗi tin nhắn nhanh để xử lý và thứ tự tin nhắn quan trọng, cách tiếp cận dựa trên log hoạt động rất tốt 23, 24. Tuy nhiên, sự phân biệt giữa hai kiến trúc đang bị mờ đi khi các hệ thống nhắn tin dựa trên log như Kafka hiện hỗ trợ các consumer group theo phong cách JMS/AMQP, cho phép nhiều consumer nhận tin nhắn từ cùng một partition 25, 26.
Vì các log được chia mảnh thường chỉ bảo toàn thứ tự tin nhắn trong một shard đơn, tất cả các tin nhắn cần được sắp xếp nhất quán phải được định tuyến đến cùng một shard. Ví dụ, một ứng dụng có thể yêu cầu rằng các sự kiện liên quan đến một người dùng cụ thể xuất hiện theo thứ tự cố định. Điều này có thể đạt được bằng cách chọn shard cho một sự kiện dựa trên ID người dùng của sự kiện đó (nói cách khác, làm cho ID người dùng trở thành partition key, khóa phân vùng).
Consumer offset
Tiêu thụ một shard tuần tự giúp dễ dàng biết tin nhắn nào đã được xử lý: tất cả các tin nhắn có offset nhỏ hơn offset hiện tại của consumer đã được xử lý, và tất cả các tin nhắn có offset lớn hơn chưa được nhìn thấy. Vì vậy, broker không cần theo dõi acknowledgment cho từng tin nhắn riêng lẻ, nó chỉ cần định kỳ ghi lại các offset consumer. Chi phí bookkeeping (quản lý sổ sách) giảm và các cơ hội cho việc batching và pipelining trong cách tiếp cận này giúp tăng thông lượng của các hệ thống dựa trên log. Tuy nhiên, nếu một consumer thất bại, nó sẽ tiếp tục từ offset được ghi lại lần cuối thay vì offset gần đây nhất mà nó đã thấy. Điều này có thể khiến consumer thấy một số tin nhắn hai lần.
Offset này thực sự rất giống với log sequence number (số thứ tự log) thường thấy trong sao chép cơ sở dữ liệu single-leader, mà chúng ta đã thảo luận trong “Setting Up New Followers”. Trong sao chép cơ sở dữ liệu, log sequence number cho phép một follower kết nối lại với leader sau khi nó bị ngắt kết nối, và tiếp tục sao chép mà không bỏ qua bất kỳ lần ghi nào. Chính xác cùng nguyên tắc được sử dụng ở đây: message broker hoạt động như một cơ sở dữ liệu leader, và consumer như một follower.
Nếu một nút consumer thất bại, một nút khác trong consumer group được giao các shard của consumer thất bại, và nó bắt đầu tiêu thụ tin nhắn tại offset được ghi lại lần cuối. Nếu consumer đã xử lý các tin nhắn tiếp theo nhưng chưa ghi lại offset của chúng, những tin nhắn đó sẽ được xử lý lần thứ hai khi khởi động lại. Chúng ta sẽ thảo luận về cách xử lý vấn đề này ở phần sau của chương.
Sử dụng không gian đĩa
Nếu bạn chỉ nối thêm vào log, cuối cùng bạn sẽ hết dung lượng đĩa. Để thu hồi không gian đĩa, log thực sự được chia thành các segment, và theo thời gian các segment cũ được xóa hoặc chuyển sang lưu trữ lưu trữ. (Chúng ta sẽ thảo luận về một cách tinh vi hơn để giải phóng không gian đĩa trong “Log compaction”.)
Điều này có nghĩa là nếu một consumer chậm không thể theo kịp tốc độ tin nhắn, và nó tụt hậu đến mức offset consumer của nó trỏ đến một segment đã bị xóa, nó sẽ bỏ lỡ một số tin nhắn. Về mặt hiệu quả, log triển khai một bộ đệm có kích thước giới hạn loại bỏ các tin nhắn cũ khi đầy, còn gọi là circular buffer (bộ đệm vòng) hoặc ring buffer (bộ đệm vành). Tuy nhiên, vì bộ đệm đó nằm trên đĩa, nó có thể khá lớn.
Hãy thực hiện một phép tính tính nhanh. Tại thời điểm viết, một ổ đĩa cứng lớn điển hình có dung lượng 20 TB và thông lượng ghi tuần tự 250 MB/s. Nếu bạn đang ghi tin nhắn ở tốc độ nhanh nhất có thể, phải mất khoảng 22 giờ cho đến khi ổ đĩa đầy và bạn cần bắt đầu xóa các tin nhắn cũ nhất. Điều đó có nghĩa là một log dựa trên đĩa luôn có thể đệm ít nhất 22 giờ tin nhắn, ngay cả khi bạn có nhiều đĩa với nhiều máy (có nhiều đĩa hơn tăng cả dung lượng có sẵn và tổng băng thông ghi). Trong thực tế, các triển khai hiếm khi sử dụng toàn bộ băng thông ghi của đĩa, vì vậy log thường có thể giữ bộ đệm tin nhắn trong vài ngày hoặc thậm chí vài tuần.
Nhiều message broker dựa trên log hiện lưu trữ tin nhắn trong object storage để tăng dung lượng lưu trữ, tương tự như cơ sở dữ liệu như chúng ta đã thấy trong “Databases Backed by Object Storage”. Các message broker như Apache Kafka và Redpanda phục vụ các tin nhắn cũ hơn từ object storage như một phần của tiered storage (lưu trữ phân tầng). Các broker khác, như WarpStream, Confluent Freight, và Bufstream lưu tất cả dữ liệu của chúng trong object store. Ngoài hiệu quả chi phí, kiến trúc này cũng giúp tích hợp dữ liệu dễ dàng hơn: các tin nhắn trong object storage được lưu trữ dưới dạng bảng Iceberg, cho phép thực thi job batch và data warehouse trực tiếp trên dữ liệu mà không cần sao chép nó vào hệ thống khác.
Khi consumer không thể theo kịp producer
Ở đầu “Hệ Thống Nhắn Tin” chúng ta đã thảo luận về ba lựa chọn phải làm gì nếu consumer không thể theo kịp tốc độ mà producer gửi tin nhắn: loại bỏ tin nhắn, đệm, hoặc áp dụng backpressure. Trong phân loại này, cách tiếp cận dựa trên log là một dạng đệm với bộ đệm lớn nhưng kích thước cố định (bị giới hạn bởi không gian đĩa có sẵn).
Nếu consumer tụt hậu đến mức các tin nhắn nó yêu cầu cũ hơn những gì được giữ lại trên đĩa, nó sẽ không thể đọc các tin nhắn đó, vì vậy broker thực sự loại bỏ các tin nhắn cũ vượt quá kích thước bộ đệm có thể chứa. Bạn có thể theo dõi consumer tụt hậu bao xa so với đầu log, và đưa ra cảnh báo nếu nó tụt hậu đáng kể. Vì bộ đệm lớn, có đủ thời gian để người vận hành sửa consumer chậm và cho phép nó bắt kịp trước khi nó bắt đầu bỏ lỡ tin nhắn.
Ngay cả khi một consumer tụt hậu quá xa và bắt đầu bỏ lỡ tin nhắn, chỉ có consumer đó bị ảnh hưởng; nó không gây gián đoạn dịch vụ cho các consumer khác. Thực tế này là một lợi thế vận hành lớn: bạn có thể thử nghiệm tiêu thụ một log sản xuất để phát triển, kiểm thử, hoặc gỡ lỗi, mà không phải lo lắng nhiều về việc gây gián đoạn các dịch vụ sản xuất. Khi một consumer bị tắt hoặc bị sập, nó ngừng tiêu thụ tài nguyên, điều duy nhất còn lại là offset consumer của nó.
Hành vi này cũng tương phản với các message broker truyền thống, nơi bạn cần cẩn thận để xóa bất kỳ hàng đợi nào mà consumer của chúng đã bị tắt, nếu không chúng tiếp tục tích lũy tin nhắn một cách không cần thiết và chiếm bộ nhớ của các consumer vẫn còn hoạt động.
Phát lại tin nhắn cũ
Chúng ta đã lưu ý trước đây rằng với các message broker theo phong cách AMQP và JMS, xử lý và xác nhận tin nhắn là một thao tác mang tính hủy hoại, vì nó khiến các tin nhắn bị xóa trên broker. Mặt khác, trong một message broker dựa trên log, tiêu thụ tin nhắn giống như đọc từ một tệp hơn: đó là một thao tác chỉ đọc không thay đổi log.
Tác dụng phụ duy nhất của việc xử lý, ngoài bất kỳ đầu ra nào của consumer, là offset consumer tiến về phía trước. Nhưng offset nằm dưới quyền kiểm soát của consumer, vì vậy nó có thể dễ dàng được thao tác nếu cần thiết: ví dụ, bạn có thể khởi động một bản sao của consumer với offset của ngày hôm qua và ghi đầu ra ra một vị trí khác, để xử lý lại tin nhắn của ngày cuối cùng. Bạn có thể lặp lại điều này bất kỳ số lần nào, thay đổi mã xử lý.
Khía cạnh này làm cho nhắn tin dựa trên log giống với các quá trình batch của chương trước hơn, nơi dữ liệu dẫn xuất được tách biệt rõ ràng khỏi dữ liệu đầu vào thông qua một quá trình biến đổi có thể lặp lại. Nó cho phép thử nghiệm nhiều hơn và phục hồi dễ dàng hơn từ các lỗi và bug, làm cho nó trở thành một công cụ tốt để tích hợp dataflow trong một tổ chức 27.
Cơ Sở Dữ Liệu và Luồng
Chúng ta đã so sánh một số điểm giữa message broker và cơ sở dữ liệu. Mặc dù theo truyền thống chúng được coi là các danh mục công cụ riêng biệt, chúng ta đã thấy rằng các message broker dựa trên log đã thành công trong việc lấy ý tưởng từ cơ sở dữ liệu và áp dụng chúng vào nhắn tin. Chúng ta cũng có thể đi theo chiều ngược lại: lấy ý tưởng từ nhắn tin và luồng, và áp dụng chúng vào cơ sở dữ liệu.
Một cách tiếp cận là sử dụng một event stream làm system of record (hệ thống lưu trữ chính) để lưu dữ liệu (xem “Systems of Record and Derived Data”). Đây là điều xảy ra trong event sourcing (lấy nguồn từ sự kiện), mà chúng ta đã thảo luận trong “Event Sourcing and CQRS”: thay vì lưu trữ dữ liệu trong một mô hình dữ liệu bị biến đổi bằng cách cập nhật và xóa, bạn có thể mô hình hóa mọi thay đổi trạng thái như một sự kiện bất biến, và ghi nó vào log chỉ nối thêm. Bất kỳ materialized view nào được tối ưu hóa để đọc đều được dẫn xuất từ các sự kiện này. Các message broker dựa trên log (được cấu hình để không bao giờ xóa các sự kiện cũ) rất phù hợp cho event sourcing vì chúng sử dụng lưu trữ chỉ nối thêm, và chúng có thể thông báo cho consumer về các sự kiện mới với độ trễ thấp.
Nhưng bạn không nhất thiết phải đi xa đến mức áp dụng event sourcing; ngay cả với các mô hình dữ liệu có thể thay đổi, các event stream vẫn hữu ích cho cơ sở dữ liệu. Thực tế, mọi lần ghi vào cơ sở dữ liệu đều là một sự kiện có thể được nắm bắt, lưu trữ và xử lý. Mối liên hệ giữa cơ sở dữ liệu và luồng sâu sắc hơn chỉ là lưu trữ vật lý của các log trên đĩa, nó khá cơ bản.
Ví dụ, một replication log (log sao chép, xem “Implementation of Replication Logs”) là một luồng các sự kiện ghi cơ sở dữ liệu, được tạo ra bởi leader khi nó xử lý các transaction. Các follower áp dụng luồng ghi đó vào bản sao của cơ sở dữ liệu của chính họ và do đó kết thúc với một bản sao chính xác của cùng dữ liệu. Các sự kiện trong replication log mô tả các thay đổi dữ liệu đã xảy ra.
Chúng ta cũng đã gặp nguyên tắc state machine replication (sao chép máy trạng thái) trong “Using shared logs”, nguyên tắc này nói rằng: nếu mỗi sự kiện đại diện cho một lần ghi vào cơ sở dữ liệu, và mỗi bản sao xử lý các sự kiện giống nhau theo cùng thứ tự, thì các bản sao sẽ đều kết thúc ở cùng trạng thái cuối cùng. (Xử lý một sự kiện được giả định là một thao tác xác định.) Đó chỉ là một trường hợp khác của event stream!
Trong phần này chúng ta trước tiên sẽ xem xét một vấn đề phát sinh trong các hệ thống dữ liệu không đồng nhất, sau đó khám phá cách chúng ta có thể giải quyết nó bằng cách đưa ý tưởng từ event stream vào cơ sở dữ liệu.
Giữ Các Hệ Thống Đồng Bộ
Như chúng ta đã thấy trong suốt cuốn sách này, không có hệ thống đơn lẻ nào có thể đáp ứng tất cả nhu cầu lưu trữ, truy vấn và xử lý dữ liệu. Trong thực tế, hầu hết các ứng dụng không tầm thường cần kết hợp nhiều công nghệ khác nhau để đáp ứng yêu cầu của chúng: ví dụ, sử dụng cơ sở dữ liệu OLTP để phục vụ yêu cầu người dùng, cache để tăng tốc các yêu cầu phổ biến, chỉ mục full-text để xử lý các truy vấn tìm kiếm, và data warehouse để phân tích. Mỗi trong số này có bản sao dữ liệu của riêng nó, được lưu trữ trong biểu diễn riêng của nó được tối ưu hóa cho mục đích riêng.
Khi cùng dữ liệu hoặc dữ liệu liên quan xuất hiện ở nhiều nơi khác nhau, chúng cần được giữ đồng bộ với nhau: nếu một mục được cập nhật trong cơ sở dữ liệu, nó cũng cần được cập nhật trong cache, chỉ mục tìm kiếm và data warehouse. Với data warehouse, đồng bộ hóa này thường được thực hiện bởi các quá trình ETL (xem “Data Warehousing”), thường bằng cách lấy một bản sao đầy đủ của cơ sở dữ liệu, chuyển đổi nó, và tải hàng loạt vào data warehouse, nói cách khác là một quá trình batch. Tương tự, chúng ta đã thấy trong “Batch Use Cases” cách các chỉ mục tìm kiếm, hệ thống gợi ý, và các hệ thống dữ liệu dẫn xuất khác có thể được tạo bằng các quá trình batch.
Nếu các bản dump cơ sở dữ liệu đầy đủ định kỳ quá chậm, một giải pháp thay thế đôi khi được sử dụng là dual writes (ghi kép), trong đó mã ứng dụng ghi rõ ràng vào mỗi hệ thống khi dữ liệu thay đổi: ví dụ, trước tiên ghi vào cơ sở dữ liệu, sau đó cập nhật chỉ mục tìm kiếm, sau đó vô hiệu hóa các mục cache (hoặc thậm chí thực hiện các lần ghi đó đồng thời).
Tuy nhiên, dual writes có một số vấn đề nghiêm trọng, một trong đó là điều kiện race condition được minh họa trong Hình 12-4. Trong ví dụ này, hai client đồng thời muốn cập nhật một mục X: client 1 muốn đặt giá trị thành A, và client 2 muốn đặt nó thành B. Cả hai client đầu tiên ghi giá trị mới vào cơ sở dữ liệu, sau đó ghi vào chỉ mục tìm kiếm. Do thời gian không may, các yêu cầu bị xen kẽ: cơ sở dữ liệu đầu tiên thấy lần ghi từ client 1 đặt giá trị thành A, sau đó lần ghi từ client 2 đặt giá trị thành B, vì vậy giá trị cuối cùng trong cơ sở dữ liệu là B. Chỉ mục tìm kiếm đầu tiên thấy lần ghi từ client 2, sau đó client 1, vì vậy giá trị cuối cùng trong chỉ mục tìm kiếm là A. Hai hệ thống hiện không nhất quán vĩnh viễn với nhau, mặc dù không có lỗi nào xảy ra.
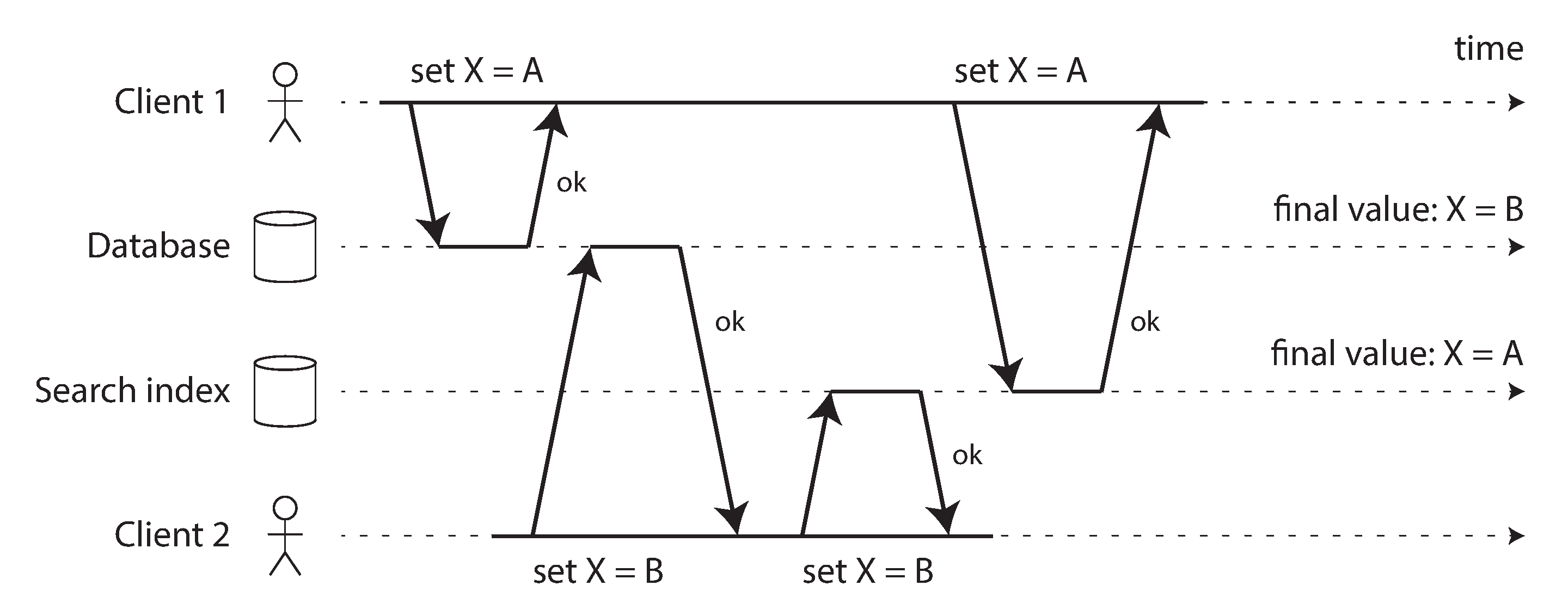
Trừ khi bạn có một số cơ chế phát hiện tính đồng thời bổ sung, chẳng hạn như các version vector mà chúng ta đã thảo luận trong “Detecting Concurrent Writes”, bạn thậm chí sẽ không nhận ra rằng các lần ghi đồng thời đã xảy ra, một giá trị sẽ đơn giản ghi đè im lặng lên giá trị khác.
Một vấn đề khác với dual writes là một trong các lần ghi có thể thất bại trong khi cái kia thành công. Đây là vấn đề chịu lỗi chứ không phải vấn đề đồng thời, nhưng nó cũng có tác dụng khiến hai hệ thống trở nên không nhất quán với nhau. Đảm bảo rằng cả hai đều thành công hoặc đều thất bại là trường hợp của vấn đề atomic commit (cam kết nguyên tử), tốn kém để giải quyết (xem “Two-Phase Commit (2PC)”).
Nếu bạn chỉ có một cơ sở dữ liệu được sao chép với một single leader, thì leader đó xác định thứ tự ghi, vì vậy cách tiếp cận state machine replication hoạt động giữa các bản sao của cơ sở dữ liệu. Tuy nhiên, trong Hình 12-4 không có một single leader: cơ sở dữ liệu có thể có một leader và chỉ mục tìm kiếm có thể có một leader, nhưng không cái nào theo cái kia, và vì vậy xung đột có thể xảy ra (xem “Multi-Leader Replication”).
Tình huống sẽ tốt hơn nếu thực sự chỉ có một leader, ví dụ cơ sở dữ liệu, và nếu chúng ta có thể làm cho chỉ mục tìm kiếm trở thành follower của cơ sở dữ liệu. Nhưng điều này có khả thi trong thực tế không?
Change Data Capture
Vấn đề với replication log của hầu hết các cơ sở dữ liệu là chúng từ lâu đã được coi là chi tiết triển khai nội bộ của cơ sở dữ liệu, không phải là một API công khai. Client được cho là truy vấn cơ sở dữ liệu thông qua mô hình dữ liệu và ngôn ngữ truy vấn của nó, không phải phân tích cú pháp replication log và cố gắng trích xuất dữ liệu từ chúng.
Trong nhiều thập kỷ, nhiều cơ sở dữ liệu đơn giản không có cách được ghi lại để lấy log các thay đổi được ghi vào chúng. Vì lý do này, rất khó để lấy tất cả các thay đổi được thực hiện trong một cơ sở dữ liệu và sao chép chúng sang một công nghệ lưu trữ khác như chỉ mục tìm kiếm, cache, hoặc data warehouse.
Gần đây hơn, đã có sự quan tâm ngày càng tăng đối với change data capture (CDC, nắm bắt dữ liệu thay đổi), đó là quá trình quan sát tất cả các thay đổi dữ liệu được ghi vào cơ sở dữ liệu và trích xuất chúng ở dạng có thể được sao chép sang các hệ thống khác 28. CDC đặc biệt thú vị nếu các thay đổi được cung cấp như một luồng, ngay lập tức khi chúng được ghi.
Ví dụ, bạn có thể nắm bắt các thay đổi trong một cơ sở dữ liệu và liên tục áp dụng các thay đổi tương tự vào một chỉ mục tìm kiếm. Nếu log thay đổi được áp dụng theo cùng thứ tự, bạn có thể kỳ vọng dữ liệu trong chỉ mục tìm kiếm khớp với dữ liệu trong cơ sở dữ liệu. Chỉ mục tìm kiếm và bất kỳ hệ thống dữ liệu dẫn xuất nào khác chỉ là consumer của luồng thay đổi.
Hình 12-5 cho thấy cách vấn đề đồng thời trong Hình 12-4 được giải quyết với CDC. Mặc dù hai yêu cầu đặt X thành A và B tương ứng đến đồng thời tại cơ sở dữ liệu, cơ sở dữ liệu quyết định một thứ tự để thực thi chúng, và ghi chúng vào replication log của nó theo thứ tự đó. Chỉ mục tìm kiếm chọn chúng và áp dụng chúng theo cùng thứ tự. Nếu bạn cần dữ liệu trong một hệ thống khác, chẳng hạn data warehouse, bạn có thể đơn giản thêm nó như một consumer khác của CDC event stream.
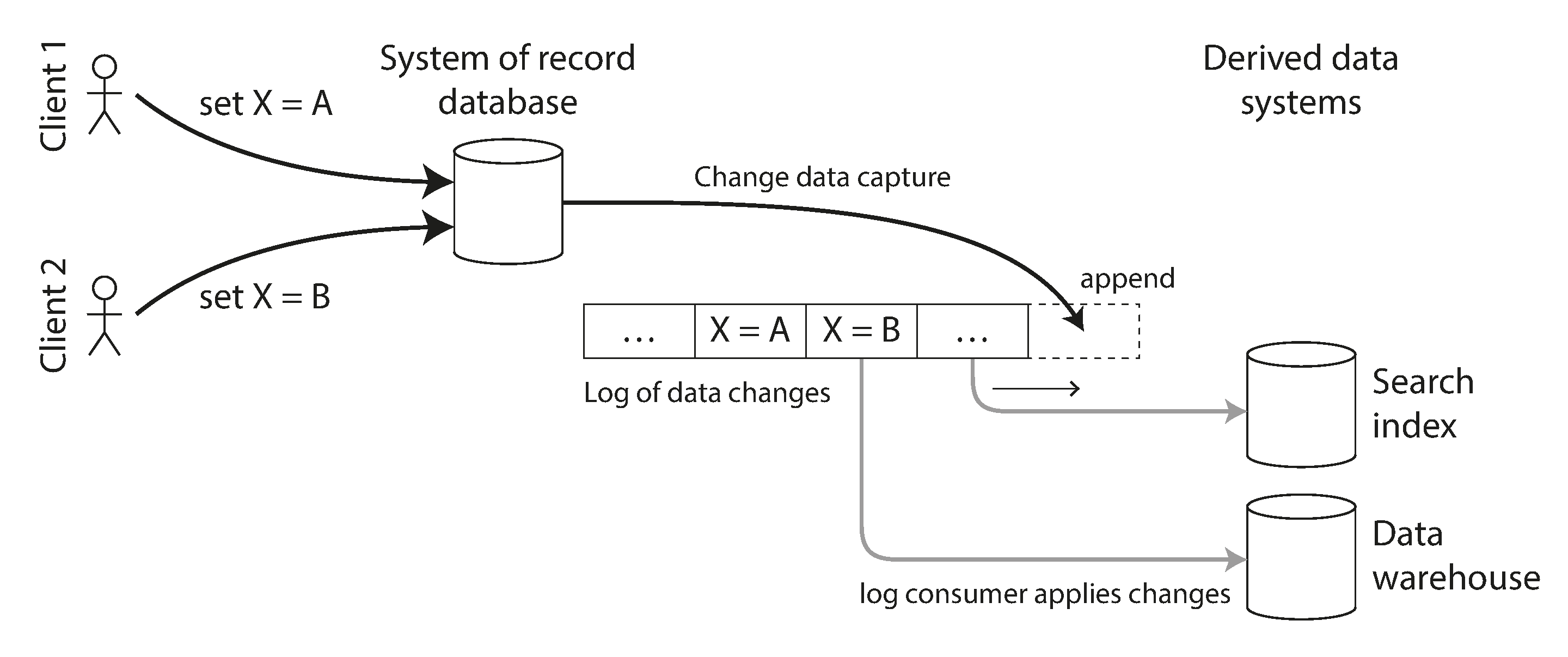
Triển khai change data capture
Chúng ta có thể gọi các log consumer là các hệ thống dữ liệu dẫn xuất (derived data systems), như đã thảo luận trong “Systems of Record and Derived Data”: dữ liệu được lưu trữ trong chỉ mục tìm kiếm và data warehouse chỉ là một cái nhìn khác về dữ liệu trong system of record. Change data capture là một cơ chế để đảm bảo rằng tất cả các thay đổi được thực hiện đối với system of record cũng được phản ánh trong các hệ thống dữ liệu dẫn xuất để các hệ thống dẫn xuất có một bản sao chính xác của dữ liệu.
Về cơ bản, change data capture làm cho một cơ sở dữ liệu trở thành leader (cơ sở dữ liệu mà các thay đổi được nắm bắt từ đó), và biến các cơ sở dữ liệu khác thành follower. Một message broker dựa trên log rất phù hợp để vận chuyển các sự kiện thay đổi từ cơ sở dữ liệu nguồn đến các hệ thống dẫn xuất, vì nó bảo toàn thứ tự của tin nhắn (tránh vấn đề sắp xếp lại của Hình 12-2).
Các logical replication log có thể được sử dụng để triển khai change data capture (xem “Logical (row-based) log replication”), mặc dù nó đi kèm với những thách thức, chẳng hạn xử lý các thay đổi schema và mô hình hóa đúng các cập nhật. Dự án mã nguồn mở Debezium giải quyết những thách thức này. Dự án chứa các source connector (kết nối nguồn) cho MySQL, PostgreSQL, Oracle, SQL Server, Db2, Cassandra, và nhiều cơ sở dữ liệu khác. Các connector này gắn vào replication log của cơ sở dữ liệu và cung cấp các thay đổi theo một schema sự kiện chuẩn. Các tin nhắn có thể được chuyển đổi và ghi vào các cơ sở dữ liệu downstream. Framework Kafka Connect cũng cung cấp thêm các CDC connector cho các cơ sở dữ liệu khác nhau. Maxwell làm điều tương tự cho MySQL bằng cách phân tích binlog 29, GoldenGate cung cấp các cơ sở hạ tầng tương tự cho Oracle, và pgcapture làm điều tương tự cho PostgreSQL.
Như với message broker, change data capture thường là bất đồng bộ: cơ sở dữ liệu system of record không chờ thay đổi được áp dụng cho consumer trước khi commit nó. Thiết kế này có lợi thế vận hành là thêm một consumer chậm không ảnh hưởng quá nhiều đến system of record, nhưng nó có nhược điểm là tất cả các vấn đề về replication lag áp dụng (xem “Problems with Replication Lag”).
Snapshot ban đầu
Nếu bạn có log của tất cả các thay đổi từng được thực hiện đối với một cơ sở dữ liệu, bạn có thể tái tạo toàn bộ trạng thái của cơ sở dữ liệu bằng cách phát lại log. Tuy nhiên, trong nhiều trường hợp, giữ tất cả các thay đổi mãi mãi sẽ đòi hỏi quá nhiều dung lượng đĩa, và phát lại nó sẽ mất quá nhiều thời gian, vì vậy log cần được cắt ngắn.
Ví dụ, xây dựng một chỉ mục full-text mới yêu cầu một bản sao đầy đủ của toàn bộ cơ sở dữ liệu, không đủ để chỉ áp dụng log của các thay đổi gần đây, vì nó sẽ thiếu các mục không được cập nhật gần đây. Vì vậy, nếu bạn không có toàn bộ lịch sử log, bạn cần bắt đầu với một snapshot nhất quán, như đã thảo luận trước đây trong “Setting Up New Followers”.
Snapshot của cơ sở dữ liệu phải tương ứng với một vị trí hoặc offset đã biết trong change log, để bạn biết tại điểm nào phải bắt đầu áp dụng các thay đổi sau khi snapshot đã được xử lý. Một số công cụ CDC tích hợp tiện ích snapshot này, trong khi các công cụ khác để nó như một thao tác thủ công. Debezium sử dụng thuật toán watermarking DBLog của Netflix để cung cấp các snapshot tăng dần 30, 31.
Log compaction
Nếu bạn chỉ có thể giữ một lượng lịch sử log giới hạn, bạn cần phải trải qua quá trình snapshot mỗi khi bạn muốn thêm một hệ thống dữ liệu dẫn xuất mới. Tuy nhiên, log compaction (nén log) cung cấp một giải pháp thay thế tốt.
Chúng ta đã thảo luận về log compaction trước đây trong “Log-Structured Storage”, trong ngữ cảnh của các engine lưu trữ có cấu trúc log (xem Hình 4-3 để có ví dụ). Nguyên tắc rất đơn giản: engine lưu trữ định kỳ tìm kiếm các bản ghi log có cùng khóa, loại bỏ bất kỳ bản sao nào, và chỉ giữ bản cập nhật gần đây nhất cho mỗi khóa. Điều này có thể làm cho các segment log nhỏ hơn nhiều, vì vậy các segment cũng có thể được hợp nhất như một phần của quá trình compaction, như được hiển thị trong Hình 12-6. Quá trình này chạy trong nền.

Trong một engine lưu trữ có cấu trúc log, một cập nhật với giá trị null đặc biệt (một tombstone, dấu bia mộ) chỉ ra rằng một khóa đã bị xóa, và làm cho nó bị xóa trong quá trình log compaction. Nhưng miễn là một khóa không bị ghi đè hoặc xóa, nó vẫn trong log mãi mãi. Dung lượng đĩa cần thiết cho một log đã được nén như vậy chỉ phụ thuộc vào nội dung hiện tại của cơ sở dữ liệu, không phải số lần ghi từng xảy ra trong cơ sở dữ liệu. Nếu cùng một khóa thường xuyên bị ghi đè, các giá trị trước đó cuối cùng sẽ bị thu gom rác, và chỉ giá trị mới nhất sẽ được giữ lại.
Ý tưởng tương tự hoạt động trong ngữ cảnh của message broker dựa trên log và change data capture. Nếu hệ thống CDC được thiết lập sao cho mỗi thay đổi có một primary key, và mỗi cập nhật cho một khóa thay thế giá trị trước đó cho khóa đó, thì đủ để chỉ giữ lần ghi gần đây nhất cho một khóa cụ thể.
Bây giờ, bất cứ khi nào bạn muốn xây dựng lại một hệ thống dữ liệu dẫn xuất như chỉ mục tìm kiếm, bạn có thể khởi động một consumer mới từ offset 0 của topic đã được nén log, và quét tuần tự qua tất cả các tin nhắn trong log. Log được đảm bảo chứa giá trị gần đây nhất cho mỗi khóa trong cơ sở dữ liệu (và có thể một số giá trị cũ hơn), nói cách khác, bạn có thể sử dụng nó để lấy một bản sao đầy đủ nội dung cơ sở dữ liệu mà không cần phải lấy một snapshot khác của cơ sở dữ liệu nguồn CDC.
Tính năng log compaction này được hỗ trợ bởi Apache Kafka. Như chúng ta sẽ thấy ở phần sau trong chương này, nó cho phép message broker được sử dụng cho lưu trữ bền vững, không chỉ cho nhắn tin tạm thời.
Hỗ trợ API cho các luồng thay đổi
Hầu hết các cơ sở dữ liệu phổ biến hiện nay cung cấp các change stream như một giao diện first-class, thay vì những nỗ lực CDC được cải tiến và đảo ngược công nghệ (reverse-engineered) trong quá khứ. Các cơ sở dữ liệu quan hệ như MySQL và PostgreSQL thường gửi các thay đổi qua cùng replication log mà chúng sử dụng cho các bản sao của riêng chúng. Hầu hết các nhà cung cấp đám mây cũng cung cấp các giải pháp CDC cho sản phẩm của họ: ví dụ, Datastream cung cấp truy cập dữ liệu streaming cho các cơ sở dữ liệu quan hệ và data warehouse của Google Cloud.
Ngay cả các cơ sở dữ liệu consistent cuối cùng, dựa trên quorum như Cassandra hiện cũng hỗ trợ change data capture. Như chúng ta đã thấy trong “Linearizability and quorums”, client phải lưu các lần ghi đến đa số nút trước khi chúng được coi là hiển thị. Hỗ trợ CDC cho quorum write là thách thức vì không có một nguồn dữ liệu sự thật duy nhất để đăng ký. Việc dữ liệu có hiển thị hay không phụ thuộc vào sở thích nhất quán của mỗi người đọc. Cassandra vượt qua vấn đề này bằng cách cung cấp các segment log thô cho mỗi nút thay vì cung cấp một luồng đột biến duy nhất. Các hệ thống muốn tiêu thụ dữ liệu phải đọc các segment log thô cho mỗi nút và quyết định cách tốt nhất để hợp nhất chúng thành một luồng duy nhất (giống như một quorum reader làm) 32.
Kafka Connect 33 tích hợp các công cụ change data capture cho nhiều hệ thống cơ sở dữ liệu với Kafka. Khi luồng sự kiện thay đổi có trong Kafka, nó có thể được sử dụng để cập nhật các hệ thống dữ liệu dẫn xuất như chỉ mục tìm kiếm, và cũng cấp dữ liệu vào các hệ thống xử lý luồng như đã thảo luận ở phần sau của chương này.
So sánh change data capture và event sourcing
Hãy so sánh change data capture với event sourcing. Tương tự như change data capture, event sourcing liên quan đến việc lưu trữ tất cả các thay đổi đối với trạng thái ứng dụng như một log các sự kiện thay đổi. Sự khác biệt lớn nhất là event sourcing áp dụng ý tưởng ở một mức trừu tượng khác:
Trong change data capture, ứng dụng sử dụng cơ sở dữ liệu theo cách có thể thay đổi, cập nhật và xóa các bản ghi tùy ý. Log thay đổi được trích xuất từ cơ sở dữ liệu ở mức thấp (ví dụ, bằng cách phân tích replication log), điều này đảm bảo rằng thứ tự ghi được trích xuất từ cơ sở dữ liệu khớp với thứ tự chúng thực sự được ghi, tránh điều kiện race condition trong Hình 12-4.
Trong event sourcing, logic ứng dụng được xây dựng rõ ràng trên cơ sở các sự kiện bất biến được ghi vào một event log. Trong trường hợp này, event store là chỉ nối thêm, và cập nhật hoặc xóa các sự kiện không được khuyến khích hoặc bị cấm. Các sự kiện được thiết kế để phản ánh những điều đã xảy ra ở mức ứng dụng, thay vì các thay đổi trạng thái mức thấp.
Cái nào tốt hơn phụ thuộc vào tình huống của bạn. Áp dụng event sourcing là một thay đổi lớn đối với một ứng dụng chưa làm điều đó; nó có một số ưu và nhược điểm, mà chúng ta đã thảo luận trong “Event Sourcing and CQRS”. Ngược lại, CDC có thể được thêm vào cơ sở dữ liệu hiện có với những thay đổi tối thiểu, ứng dụng ghi vào cơ sở dữ liệu thậm chí có thể không biết rằng CDC đang xảy ra.
CHANGE DATA CAPTURE AND DATABASE SCHEMAS
Though change data capture appears easier to adopt than event sourcing, it comes with its own set of challenges.
In a microservices architecture, a database is typically only accessed from one service. Other services interact with it through that service’s public API, but they don’t normally access the database directly. This makes the database an internal implementation detail of the service, allowing the developers to change its database schema without affecting the public API.
However, CDC systems typically use the upstream database’s schema when replicating its data, which turns these schemas into public APIs that must be managed much like the public API of the service. A developer who removes a table column in their database table will break downstream consumers that depend on this field. Such challenges have always existed with data pipelines, but they typically only impacted data warehouse ETL. Since CDC is often implemented as a data stream, other production services might be consumers. Breaking such consumers can cause a customer-facing outage 34. Data contracts are often used to prevent these breakages.
A common way to decouple internal from external schemas is to use the outbox pattern. Outboxes are tables with their own schemas, which are exposed to the CDC system rather than the internal domain model in the database 35, 36. Developers can then modify their internal schemas as they see fit while leaving their outbox tables untouched. This might look like a dual write—it is. However, outboxes avoid the challenges we discussed in “Keeping Systems in Sync” by keeping both writes in the same system (the database). This design allows both writes to appear in a single transaction.
Outboxes present a few tradeoffs, though. Developers must still maintain the transformation between their internal and outbox schemas, which can be challenging. An outbox also increases the amount of data that the database has to write to its underlying storage, which might trigger performance problems.
Cũng như với change data capture, phát lại event log cho phép bạn tái tạo trạng thái hiện tại của hệ thống. Tuy nhiên, log compaction cần được xử lý khác nhau:
Một CDC event cho việc cập nhật một bản ghi thường chứa toàn bộ phiên bản mới của bản ghi, vì vậy giá trị hiện tại cho một primary key hoàn toàn được xác định bởi sự kiện gần đây nhất cho primary key đó, và log compaction có thể loại bỏ các sự kiện trước đó cho cùng khóa.
Mặt khác, với event sourcing, các sự kiện được mô hình hóa ở mức cao hơn: một sự kiện thường thể hiện ý định của một hành động người dùng, không phải cơ chế cập nhật trạng thái xảy ra do hành động đó. Trong trường hợp này, các sự kiện sau thường không ghi đè lên các sự kiện trước, và vì vậy bạn cần toàn bộ lịch sử sự kiện để tái tạo trạng thái cuối cùng. Log compaction không thể thực hiện theo cách tương tự.
Các ứng dụng sử dụng event sourcing thường có một số cơ chế để lưu trữ snapshot của trạng thái hiện tại được dẫn xuất từ log sự kiện, để chúng không cần phải xử lý lại toàn bộ log nhiều lần. Tuy nhiên, đây chỉ là một tối ưu hóa hiệu năng để tăng tốc việc đọc và phục hồi từ sự cố; ý định là hệ thống có thể lưu trữ tất cả các sự kiện thô mãi mãi và xử lý lại toàn bộ event log bất cứ khi nào được yêu cầu. Chúng ta thảo luận giả định này trong “Limitations of immutability”.
Trạng Thái, Luồng và Tính Bất Biến
Chúng ta đã thấy trong Chương 11 rằng xử lý batch được hưởng lợi từ tính bất biến của các tệp đầu vào, vì vậy bạn có thể chạy các job xử lý thử nghiệm trên các tệp đầu vào hiện có mà không sợ làm hỏng chúng. Nguyên tắc bất biến này cũng là điều làm cho event sourcing và change data capture trở nên mạnh mẽ.
Chúng ta thường nghĩ về cơ sở dữ liệu như lưu trữ trạng thái hiện tại của ứng dụng, biểu diễn này được tối ưu hóa để đọc, và thường là thuận tiện nhất để phục vụ các truy vấn. Bản chất của trạng thái là nó thay đổi, vì vậy cơ sở dữ liệu hỗ trợ cập nhật và xóa dữ liệu cũng như chèn nó. Điều này phù hợp với tính bất biến như thế nào?
Bất cứ khi nào bạn có trạng thái thay đổi, trạng thái đó là kết quả của các sự kiện đã biến đổi nó theo thời gian. Ví dụ, danh sách chỗ ngồi hiện có của bạn là kết quả của các đặt chỗ bạn đã xử lý, số dư tài khoản hiện tại là kết quả của các khoản ghi có và ghi nợ trên tài khoản, và biểu đồ thời gian phản hồi cho máy chủ web của bạn là tổng hợp của các thời gian phản hồi riêng lẻ của tất cả các yêu cầu web đã xảy ra.
Dù trạng thái thay đổi như thế nào, luôn có một chuỗi sự kiện gây ra những thay đổi đó. Ngay cả khi mọi thứ được thực hiện và hoàn tác, thực tế vẫn đúng rằng những sự kiện đó đã xảy ra. Ý tưởng chính là trạng thái có thể thay đổi và một log chỉ nối thêm của các sự kiện bất biến không mâu thuẫn với nhau: chúng là hai mặt của cùng một đồng xu. Log của tất cả các thay đổi, changelog, đại diện cho sự tiến hóa của trạng thái theo thời gian.
Nếu bạn có khuynh hướng toán học, bạn có thể nói rằng trạng thái ứng dụng là những gì bạn nhận được khi bạn tích phân một event stream theo thời gian, và một change stream là những gì bạn nhận được khi bạn vi phân trạng thái theo thời gian, như được hiển thị trong Hình 12-7 37, 38. Phép tương tự có những hạn chế (ví dụ, đạo hàm bậc hai của trạng thái dường như không có ý nghĩa), nhưng đó là một điểm xuất phát hữu ích để suy nghĩ về dữ liệu.
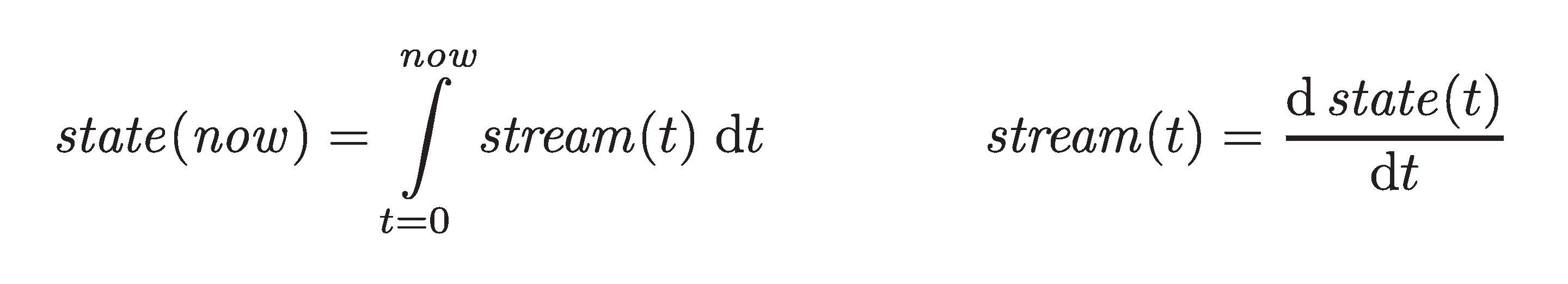
Nếu bạn lưu trữ changelog một cách bền vững, điều đó đơn giản có tác dụng làm cho trạng thái có thể tái tạo. Nếu bạn coi log sự kiện là system of record của bạn, và bất kỳ trạng thái có thể thay đổi nào đều được dẫn xuất từ nó, thì việc lý luận về luồng dữ liệu qua một hệ thống trở nên dễ dàng hơn. Như Jim Gray và Andreas Reuter đã nói vào năm 1992 39:
here is no fundamental need to keep a database at all; the log contains all the information there is. The only reason for storing the database (i.e., the current end-of-the-log) is performance of retrieval operations.
Log compaction là một cách để thu hẹp sự phân biệt giữa log và trạng thái cơ sở dữ liệu: nó chỉ giữ lại phiên bản mới nhất của mỗi bản ghi, và loại bỏ các phiên bản bị ghi đè.
Lợi thế của các sự kiện bất biến
Tính bất biến trong cơ sở dữ liệu là một ý tưởng cũ. Ví dụ, kế toán đã sử dụng tính bất biến trong nhiều thế kỷ trong việc ghi sổ tài chính. Khi một giao dịch xảy ra, nó được ghi lại trong một sổ cái (ledger) chỉ nối thêm, về cơ bản là một log các sự kiện mô tả tiền, hàng hóa hoặc dịch vụ đã đổi chủ. Các tài khoản, chẳng hạn lãi lỗ hoặc bảng cân đối kế toán, được dẫn xuất từ các giao dịch trong sổ cái bằng cách cộng chúng lại 40.
Nếu một sai lầm được thực hiện, kế toán không xóa hoặc thay đổi giao dịch không chính xác trong sổ cái, thay vào đó, họ thêm một giao dịch khác bù đắp cho sai lầm, ví dụ hoàn tiền một khoản phí không chính xác. Giao dịch không chính xác vẫn còn trong sổ cái mãi mãi, vì nó có thể quan trọng cho mục đích kiểm toán. Nếu các số liệu không chính xác, được dẫn xuất từ sổ cái không chính xác, đã được công bố, thì các số liệu cho kỳ kế toán tiếp theo bao gồm một khoản điều chỉnh. Quá trình này hoàn toàn bình thường trong kế toán 41.
Mặc dù khả năng kiểm toán như vậy đặc biệt quan trọng trong các hệ thống tài chính, nó cũng có lợi cho nhiều hệ thống khác không phải chịu các quy định nghiêm ngặt như vậy. Nếu bạn vô tình triển khai mã lỗi ghi dữ liệu xấu vào cơ sở dữ liệu, việc phục hồi sẽ khó hơn nhiều nếu mã có thể ghi đè phá hủy dữ liệu. Với log chỉ nối thêm của các sự kiện bất biến, việc chẩn đoán những gì đã xảy ra và phục hồi từ vấn đề dễ dàng hơn nhiều. Tương tự, dịch vụ khách hàng có thể sử dụng audit log (log kiểm toán) để chẩn đoán các yêu cầu và khiếu nại của khách hàng.
Các sự kiện bất biến cũng nắm bắt nhiều thông tin hơn so với chỉ trạng thái hiện tại. Ví dụ, trên một trang web mua sắm, một khách hàng có thể thêm một mục vào giỏ hàng và sau đó xóa nó. Mặc dù sự kiện thứ hai hủy bỏ sự kiện đầu tiên từ quan điểm thực hiện đơn hàng, có thể hữu ích để biết cho mục đích phân tích rằng khách hàng đã cân nhắc một mục cụ thể nhưng sau đó quyết định không mua. Có lẽ họ sẽ chọn mua nó trong tương lai, hoặc có lẽ họ đã tìm thấy một thứ thay thế. Thông tin này được ghi lại trong event log, nhưng sẽ bị mất trong cơ sở dữ liệu xóa các mục khi chúng bị xóa khỏi giỏ hàng.
Dẫn xuất nhiều view từ cùng một event log
Hơn nữa, bằng cách tách biệt trạng thái có thể thay đổi khỏi immutable event log, bạn có thể dẫn xuất nhiều biểu diễn khác nhau hướng đến đọc từ cùng một log sự kiện. Điều này hoạt động giống như có nhiều consumer của một luồng (Hình 12-5): ví dụ, cơ sở dữ liệu phân tích Druid nhập trực tiếp từ Kafka bằng cách tiếp cận này, và các Kafka Connect sink có thể xuất dữ liệu từ Kafka sang nhiều cơ sở dữ liệu và chỉ mục khác nhau 33.
Có một bước dịch rõ ràng từ event log sang cơ sở dữ liệu giúp dễ dàng phát triển ứng dụng của bạn theo thời gian: nếu bạn muốn giới thiệu một tính năng mới trình bày dữ liệu hiện có của bạn theo một cách mới, bạn có thể sử dụng event log để xây dựng một view hướng đến đọc riêng biệt được tối ưu hóa cho tính năng mới, và chạy nó cùng với các hệ thống hiện có mà không cần sửa đổi chúng. Chạy các hệ thống cũ và mới song song thường dễ hơn so với thực hiện di cư schema phức tạp trong một hệ thống hiện có. Khi người đọc đã chuyển sang hệ thống mới và hệ thống cũ không còn cần thiết nữa, bạn có thể đơn giản tắt nó và thu hồi tài nguyên của nó 42, 43.
Ý tưởng ghi dữ liệu ở một dạng được tối ưu hóa cho ghi, và sau đó dịch nó sang các biểu diễn khác nhau được tối ưu hóa cho đọc khi cần, là mẫu command query responsibility segregation (CQRS, phân tách trách nhiệm lệnh truy vấn) mà chúng ta đã gặp trong “Event Sourcing and CQRS”. Nó không nhất thiết yêu cầu event sourcing: bạn cũng có thể xây dựng nhiều materialized view từ một luồng CDC event 44.
Cách tiếp cận truyền thống đối với thiết kế cơ sở dữ liệu và schema dựa trên sự ngộ nhận rằng dữ liệu phải được ghi ở cùng dạng như nó sẽ được truy vấn. Các cuộc tranh luận về chuẩn hóa và phi chuẩn hóa (xem “Normalization, Denormalization, and Joins”) trở nên phần lớn không liên quan nếu bạn có thể dịch dữ liệu từ event log được tối ưu hóa cho ghi sang trạng thái ứng dụng được tối ưu hóa cho đọc: hoàn toàn hợp lý để phi chuẩn hóa dữ liệu trong các view được tối ưu hóa cho đọc, vì quá trình dịch cung cấp cho bạn một cơ chế để giữ nó nhất quán với event log.
Trong “Case Study: Social Network Home Timelines” chúng ta đã thảo luận về home timeline của mạng xã hội, một cache của các bài đăng gần đây của những người mà một người dùng cụ thể đang theo dõi (như một hộp thư). Đây là một ví dụ khác về trạng thái được tối ưu hóa cho đọc: home timeline được phi chuẩn hóa cao, vì các bài đăng của bạn được nhân đôi trong tất cả các timeline của những người đang theo dõi bạn. Tuy nhiên, dịch vụ fan-out giữ trạng thái nhân đôi này đồng bộ với các bài đăng mới và những người following relationships, which keeps the duplication manageable.
Kiểm soát đồng thời
Nhược điểm lớn nhất của CQRS là các consumer của event log thường hoạt động bất đồng bộ, nên có khả năng một người dùng thực hiện ghi vào log, sau đó đọc từ derived view (khung nhìn dẫn xuất) và thấy rằng lần ghi đó chưa được phản ánh vào view. Chúng ta đã thảo luận về vấn đề này và các giải pháp tiềm năng trong “Reading Your Own Writes”.
Một giải pháp là thực hiện cập nhật read view đồng bộ với việc nối thêm sự kiện vào log. Điều này đòi hỏi một distributed transaction (giao dịch phân tán) qua event log và derived view, hoặc một cách nào đó để chờ đến khi sự kiện được phản ánh vào view. Cả hai cách tiếp cận thường không khả thi, nên views thường được cập nhật bất đồng bộ.
Mặt khác, việc dẫn xuất trạng thái hiện tại từ event log cũng đơn giản hóa một số khía cạnh của kiểm soát đồng thời. Phần lớn nhu cầu dùng multi-object transaction (giao dịch đa đối tượng, xem “Single-Object and Multi-Object Operations”) xuất phát từ việc một hành động người dùng yêu cầu thay đổi dữ liệu ở nhiều nơi khác nhau. Với event sourcing, bạn có thể thiết kế một sự kiện sao cho nó là mô tả tự đầy đủ về một hành động người dùng. Hành động người dùng sau đó chỉ cần một lần ghi duy nhất tại một chỗ, cụ thể là nối thêm sự kiện vào log, điều này dễ thực hiện nguyên tử.
Nếu event log và application state được phân mảnh theo cùng một cách (ví dụ, xử lý một sự kiện của khách hàng ở shard 3 chỉ yêu cầu cập nhật shard 3 của application state), thì một log consumer đơn luồng đơn giản không cần kiểm soát đồng thời khi ghi, vì theo thiết kế, nó chỉ xử lý một sự kiện tại một thời điểm (xem thêm “Actual Serial Execution”). Log loại bỏ tính không xác định của đồng thời bằng cách xác định thứ tự tuần tự của các sự kiện trong một shard 27. Nếu một sự kiện chạm đến nhiều state shard, cần thêm một chút công sức, điều này chúng ta sẽ thảo luận trong Chương 13.
Nhiều hệ thống không dùng mô hình event-sourced vẫn dựa vào tính bất biến để kiểm soát đồng thời: nhiều cơ sở dữ liệu nội bộ sử dụng cấu trúc dữ liệu bất biến hoặc dữ liệu đa phiên bản để hỗ trợ point-in-time snapshot (ảnh chụp tại thời điểm cụ thể, xem “Indexes and snapshot isolation”). Các hệ thống quản lý phiên bản như Git, Mercurial và Fossil cũng dựa vào dữ liệu bất biến để lưu giữ lịch sử phiên bản của các tệp.
Giới hạn của tính bất biến
Đến mức độ nào thì việc lưu giữ lịch sử bất biến của tất cả các thay đổi mãi mãi là khả thi? Câu trả lời phụ thuộc vào mức độ biến động của tập dữ liệu. Một số workload chủ yếu thêm dữ liệu và hiếm khi cập nhật hoặc xóa; chúng dễ dàng được làm bất biến. Các workload khác có tỷ lệ cập nhật và xóa cao trên một tập dữ liệu tương đối nhỏ; trong những trường hợp này, lịch sử bất biến có thể phát triển quá lớn, phân mảnh có thể trở thành vấn đề, và hiệu năng của compaction (nén) và garbage collection (thu gom rác) trở nên cực kỳ quan trọng cho tính ổn định vận hành 45, 46.
Ngoài lý do hiệu năng, còn có thể có những trường hợp bạn cần xóa dữ liệu vì lý do quản trị hoặc pháp lý, bất chấp tính bất biến. Ví dụ, các quy định về quyền riêng tư như Quy định Bảo vệ Dữ liệu Chung châu Âu (GDPR) yêu cầu thông tin cá nhân của người dùng phải được xóa và thông tin sai lệch phải được loại bỏ theo yêu cầu, hoặc một rò rỉ thông tin nhạy cảm tình cờ có thể cần được kiểm soát.
Trong những trường hợp này, chỉ nối thêm một sự kiện vào log để chỉ ra rằng dữ liệu trước đó nên được coi là đã xóa là chưa đủ, bạn thực sự muốn viết lại lịch sử và giả vờ rằng dữ liệu chưa bao giờ được ghi. Ví dụ, Datomic gọi tính năng này là excision (trích xuất cưỡng bức) 47, và hệ thống quản lý phiên bản Fossil có một khái niệm tương tự gọi là shunning (tẩy chay) 48.
Việc thực sự xóa dữ liệu đáng ngạc nhiên là khó 49, vì các bản sao có thể tồn tại ở nhiều nơi: ví dụ, storage engine, filesystem và SSD thường ghi vào vị trí mới thay vì ghi đè tại chỗ 41, và backup thường được cố ý làm bất biến để ngăn việc xóa hoặc hỏng dữ liệu tình cờ.
Một cách để cho phép xóa dữ liệu bất biến là crypto-shredding (băm nhỏ bằng mã hóa) 50: dữ liệu mà bạn có thể muốn xóa trong tương lai được lưu trữ dưới dạng mã hóa, và khi bạn muốn loại bỏ nó, bạn quên đi khóa mã hóa. Dữ liệu đã mã hóa vẫn còn đó, nhưng không ai có thể sử dụng được. Theo một nghĩa nào đó, cách này chỉ chuyển vấn đề sang chỗ khác: dữ liệu thực sự bây giờ là bất biến, nhưng bộ lưu trữ khóa của bạn thì có thể thay đổi.
Hơn nữa, bạn phải quyết định trước dữ liệu nào sẽ được mã hóa bằng cùng một khóa, và khi nào bạn sẽ dùng khóa khác, đây là một quyết định quan trọng, vì sau này bạn có thể crypto-shred toàn bộ hoặc không dữ liệu nào được mã hóa bằng một khóa cụ thể, nhưng không thể chỉ một phần. Lưu trữ một khóa riêng cho mỗi mục dữ liệu sẽ trở nên quá cồng kềnh, vì bộ lưu trữ khóa sẽ có kích thước bằng với bộ lưu trữ dữ liệu chính. Các phương pháp phức tạp hơn như puncturable encryption (mã hóa có thể thu hồi chọn lọc) 51 cho phép thu hồi chọn lọc khả năng giải mã của một khóa, nhưng chúng không được sử dụng rộng rãi.
Nhìn chung, việc xóa phần lớn là vấn đề của “làm cho việc truy xuất dữ liệu khó hơn” thay vì thực sự “làm cho việc truy xuất dữ liệu là không thể.” Tuy nhiên, đôi khi bạn vẫn phải cố thử, như chúng ta sẽ thấy trong “Legislation and Self-Regulation”.
Xử lý Streams
Cho đến nay trong chương này, chúng ta đã nói về nguồn gốc của stream (sự kiện hoạt động người dùng, cảm biến và ghi vào cơ sở dữ liệu), và chúng ta đã nói về cách stream được truyền tải (qua messaging trực tiếp, qua message broker và trong event log).
Điều còn lại là thảo luận về những gì bạn có thể làm với stream khi đã có nó, cụ thể là bạn có thể xử lý nó. Nhìn chung, có ba lựa chọn:
Bạn có thể lấy dữ liệu trong các sự kiện và ghi vào cơ sở dữ liệu, cache, search index hoặc hệ thống lưu trữ tương tự, từ đó các client khác có thể truy vấn. Như được hiển thị trong Hình 12-5, đây là cách tốt để giữ cơ sở dữ liệu đồng bộ với các thay đổi xảy ra ở các phần khác của hệ thống, đặc biệt nếu stream consumer là client duy nhất ghi vào cơ sở dữ liệu. Ghi vào hệ thống lưu trữ là tương đương streaming của những gì chúng ta đã thảo luận trong “Batch Use Cases”.
Bạn có thể đẩy các sự kiện đến người dùng theo một cách nào đó, ví dụ bằng cách gửi email cảnh báo hoặc push notification, hoặc stream các sự kiện đến một real-time dashboard để chúng được trực quan hóa. Trong trường hợp này, con người là consumer cuối cùng của stream.
Bạn có thể xử lý một hoặc nhiều input stream để tạo ra một hoặc nhiều output stream. Stream có thể đi qua một pipeline bao gồm nhiều giai đoạn xử lý như vậy trước khi cuối cùng kết thúc tại một output (lựa chọn 1 hoặc 2).
Trong phần còn lại của chương này, chúng ta sẽ thảo luận về lựa chọn 3: xử lý stream để tạo ra các stream dẫn xuất khác. Một đoạn mã xử lý stream như vậy được gọi là operator (bộ xử lý) hoặc job (công việc). Nó có liên quan chặt chẽ đến các Unix process và MapReduce job chúng ta đã thảo luận trong Chương 11, và mẫu dataflow tương tự nhau: một stream processor tiêu thụ input stream theo kiểu chỉ đọc và ghi output ra một vị trí khác theo kiểu chỉ nối thêm.
Các mẫu phân mảnh và song song hóa trong stream processor cũng rất giống với những mẫu trong MapReduce và các dataflow engine chúng ta đã thấy trong Chương 11, nên chúng ta sẽ không lặp lại những chủ đề đó ở đây. Các thao tác mapping cơ bản như biến đổi và lọc bản ghi cũng hoạt động tương tự.
Sự khác biệt quan trọng duy nhất so với batch job là stream không bao giờ kết thúc. Sự khác biệt này có nhiều hệ quả: như đã thảo luận ở đầu chương này, sắp xếp không có ý nghĩa với tập dữ liệu không giới hạn, và do đó sort-merge join (xem “JOIN and GROUP BY”) không thể được sử dụng. Các cơ chế fault-tolerance cũng phải thay đổi: với một batch job đã chạy được vài phút, một task thất bại có thể đơn giản được khởi động lại từ đầu, nhưng với một stream job đã chạy nhiều năm, khởi động lại từ đầu sau khi crash có thể không phải là lựa chọn khả thi.
Các Ứng dụng của Stream Processing
Stream processing từ lâu đã được sử dụng cho mục đích giám sát, nơi một tổ chức muốn được cảnh báo nếu một số điều nhất định xảy ra. Ví dụ:
Hệ thống phát hiện gian lận cần xác định xem mẫu sử dụng thẻ tín dụng có thay đổi bất ngờ không, và khóa thẻ nếu có khả năng bị đánh cắp.
Hệ thống giao dịch cần kiểm tra sự thay đổi giá trên thị trường tài chính và thực hiện giao dịch theo các quy tắc được chỉ định.
Hệ thống sản xuất cần giám sát trạng thái máy móc trong nhà máy, và nhanh chóng xác định vấn đề nếu có sự cố.
Hệ thống quân sự và tình báo cần theo dõi các hoạt động của đối thủ tiềm năng, và phát cảnh báo nếu có dấu hiệu tấn công.
Các loại ứng dụng này đòi hỏi pattern matching (khớp mẫu) và tương quan khá phức tạp. Tuy nhiên, theo thời gian cũng đã xuất hiện các ứng dụng khác của stream processing. Trong phần này, chúng ta sẽ so sánh ngắn gọn một số ứng dụng này.
Complex event processing
Complex event processing (CEP, xử lý sự kiện phức tạp) là một phương pháp được phát triển vào những năm 1990 để phân tích event stream, đặc biệt hướng đến loại ứng dụng yêu cầu tìm kiếm các mẫu sự kiện nhất định 52. Tương tự như cách biểu thức chính quy cho phép bạn tìm kiếm các mẫu ký tự nhất định trong chuỗi, CEP cho phép bạn chỉ định các quy tắc để tìm kiếm các mẫu sự kiện nhất định trong stream.
Các hệ thống CEP thường sử dụng ngôn ngữ truy vấn khai báo cấp cao như SQL, hoặc giao diện người dùng đồ họa, để mô tả các mẫu sự kiện cần được phát hiện. Các truy vấn này được gửi đến một processing engine tiêu thụ input stream và nội bộ duy trì một state machine thực hiện việc khớp yêu cầu. Khi tìm thấy khớp, engine phát ra một complex event (sự kiện phức tạp, do đó có tên gọi) với chi tiết về mẫu sự kiện được phát hiện 53.
Trong các hệ thống này, mối quan hệ giữa truy vấn và dữ liệu được đảo ngược so với cơ sở dữ liệu thông thường. Thông thường, cơ sở dữ liệu lưu trữ dữ liệu lâu dài và xử lý truy vấn như là tạm thời: khi một truy vấn đến, cơ sở dữ liệu tìm kiếm dữ liệu phù hợp với truy vấn, rồi quên đi truy vấn khi hoàn thành. CEP engine đảo ngược các vai trò này: các truy vấn được lưu trữ lâu dài; khi mỗi sự kiện đến, engine kiểm tra xem nó có thấy một mẫu sự kiện khớp với bất kỳ truy vấn thường trực nào của nó không 54.
Các triển khai CEP bao gồm Esper, Apama và TIBCO StreamBase. Các distributed stream processor như Flink và Spark Streaming cũng có hỗ trợ SQL cho các truy vấn khai báo trên stream.
Stream analytics
Một lĩnh vực khác mà stream processing được sử dụng là analytics trên stream. Ranh giới giữa CEP và stream analytics khá mờ nhạt, nhưng theo quy tắc chung, analytics thường ít quan tâm đến việc tìm các chuỗi sự kiện cụ thể và hướng nhiều hơn đến các tổng hợp và chỉ số thống kê trên một số lượng lớn sự kiện, ví dụ:
Đo tần suất của một loại sự kiện (tần suất xảy ra trên mỗi khoảng thời gian)
Tính trung bình động của một giá trị trong một khoảng thời gian
So sánh thống kê hiện tại với các khoảng thời gian trước đó (ví dụ, để phát hiện xu hướng hoặc cảnh báo về các chỉ số cao hoặc thấp bất thường so với cùng thời điểm tuần trước)
Các thống kê như vậy thường được tính trên các khoảng thời gian cố định, ví dụ bạn có thể muốn biết số lượng truy vấn trung bình mỗi giây đến một dịch vụ trong 5 phút vừa qua, và thời gian phản hồi ở phân vị thứ 99 trong khoảng thời gian đó. Lấy trung bình trong vài phút làm mịn các biến động không liên quan từ giây này sang giây khác, trong khi vẫn cho bạn bức tranh kịp thời về bất kỳ thay đổi nào trong mẫu lưu lượng. Khoảng thời gian mà bạn tổng hợp được gọi là window (cửa sổ thời gian), và chúng ta sẽ xem xét windowing chi tiết hơn trong “Reasoning About Time”.
Các hệ thống stream analytics đôi khi sử dụng thuật toán xác suất, chẳng hạn như Bloom filter (mà chúng ta đã gặp trong “Bloom filters”) để kiểm tra thành viên tập hợp, HyperLogLog 55 để ước tính cardinality (lực lượng tập hợp), và các thuật toán ước tính phân vị khác nhau (xem “Computing Percentiles”). Các thuật toán xác suất tạo ra kết quả gần đúng, nhưng có ưu điểm là yêu cầu bộ nhớ ít hơn đáng kể trong stream processor so với các thuật toán chính xác. Việc sử dụng thuật toán gần đúng này đôi khi khiến người ta tin rằng các hệ thống stream processing luôn có mất mát và không chính xác, nhưng điều đó là sai: không có gì vốn là gần đúng về stream processing, và việc sử dụng thuật toán xác suất chỉ đơn giản là một tối ưu hóa 56.
Nhiều framework stream processing phân tán mã nguồn mở được thiết kế với analytics trong đầu: ví dụ, Apache Storm, Spark Streaming, Flink, Samza, Apache Beam và Kafka Streams 57. Các dịch vụ được lưu trữ bao gồm Google Cloud Dataflow và Azure Stream Analytics.
Duy trì materialized view
Chúng ta đã thấy rằng một stream các thay đổi đến cơ sở dữ liệu có thể được sử dụng để giữ các hệ thống dữ liệu dẫn xuất, chẳng hạn như cache, search index và data warehouse, đồng bộ với cơ sở dữ liệu nguồn. Đây là các ví dụ về duy trì materialized view (khung nhìn vật chất hóa): dẫn xuất một khung nhìn thay thế trên một số tập dữ liệu để bạn có thể truy vấn hiệu quả, và cập nhật khung nhìn đó bất cứ khi nào dữ liệu cơ bản thay đổi 37.
Tương tự, trong event sourcing, trạng thái ứng dụng được duy trì bằng cách áp dụng một log các sự kiện; ở đây trạng thái ứng dụng cũng là một loại materialized view. Không giống như các kịch bản stream analytics, thường không đủ để chỉ xem xét các sự kiện trong một khoảng thời gian nhất định: việc xây dựng materialized view có thể yêu cầu tất cả các sự kiện trong một khoảng thời gian tùy ý, ngoại trừ bất kỳ sự kiện lỗi thời nào có thể bị loại bỏ bởi log compaction. Thực tế, bạn cần một window kéo dài tất cả về phía trước đến lúc ban đầu.
Về nguyên tắc, bất kỳ stream processor nào cũng có thể được sử dụng để duy trì materialized view, mặc dù nhu cầu lưu giữ sự kiện mãi mãi đi ngược lại các giả định của một số framework hướng analytics chủ yếu hoạt động trên các window có thời gian giới hạn. Kafka Streams và ksqlDB của Confluent hỗ trợ loại sử dụng này, dựa trên hỗ trợ log compaction của Kafka 58.
INCREMENTAL VIEW MAINTENANCE
Databases might seem well suited for materialized view maintenance; they are designed to keep full copies of a dataset, after all. Many also support materialized views. We saw in “Materialized Views and Data Cubes” that analytical queries typical of a data warehouse can be materialized into OLAP cubes.
Unfortunately, databases often refresh materialized view tables using batch jobs or on-demand
requests such as PostgreSQL’s REFRESH MATERIALIZED VIEW. Views are recalculated
periodically rather than as updates to souce data occurs. This approach has two significant
drawbacks that make it inappropriate for stream processing view maintenance:
Poor efficiency: All data is reprocessed every time the view is updated, though it’s likely that most of the data remains unchanged.
Data freshness: changes in source data are not reflected in a materialized view until its query is re-run during its next scheduled update.
It is possible to write database triggers that update materialized views efficiently in scenarios where the data is easily partitioned and the computation is naturally incremental. For example, if a materialized view maintains total sales revenue per-day, the row for the appropriate day can be updated every time a new sale occurs. Bespoke solutions work in a few cases, but many SQL queries can’t be easily or efficiently converted to incremental computation.
Incremental view maintenance (IVM) is a more general solution to the problems listed above. IVM techniques convert relational grammars such as SQL into operators capable of incremental computations. Rather than processing entire datasets, IVM algorithms recompute and update only data that has changed 38, 59, 60. View computation becomes far more efficient. Updates can then be run much more frequently, which dramatically increases data freshness.
Databases such as Materialize 61, RisingWave, ClickHouse, and Feldera all use IVM techniques to provide efficient incremental materialized views. These databases ingest streams of events to expose materialized views in realtime. Recent events are buffered in-memory and periodically used to update on-disk materialized views. Reads combine the recent events and the materialized data to provide a single realtime view. Since reads are often expressed in SQL and materialized views are often stored in OLAP-style formats, these systems also support large-scale data warehouse-style queries such as those disucssed in Chapter 11.
Tìm kiếm trên stream
Ngoài CEP, cho phép tìm kiếm các mẫu bao gồm nhiều sự kiện, đôi khi còn có nhu cầu tìm kiếm các sự kiện riêng lẻ dựa trên các tiêu chí phức tạp, chẳng hạn như các truy vấn tìm kiếm toàn văn.
Ví dụ, các dịch vụ giám sát truyền thông đăng ký các nguồn cấp tin tức và chương trình phát sóng từ các cơ quan truyền thông, và tìm kiếm bất kỳ tin tức nào đề cập đến các công ty, sản phẩm hoặc chủ đề quan tâm. Điều này được thực hiện bằng cách xây dựng một truy vấn tìm kiếm trước, sau đó liên tục khớp stream tin tức với truy vấn này. Các tính năng tương tự tồn tại trên một số trang web: ví dụ, người dùng các trang web bất động sản có thể yêu cầu được thông báo khi một bất động sản mới khớp với tiêu chí tìm kiếm của họ xuất hiện trên thị trường. Tính năng percolator của Elasticsearch 62 là một lựa chọn để triển khai loại tìm kiếm stream này.
Các công cụ tìm kiếm thông thường trước tiên lập chỉ mục tài liệu rồi chạy truy vấn trên chỉ mục. Ngược lại, tìm kiếm trên stream đảo ngược quá trình xử lý: các truy vấn được lưu trữ, và các tài liệu chạy qua các truy vấn, giống như trong CEP. Trong trường hợp đơn giản nhất, bạn có thể kiểm tra mỗi tài liệu với mọi truy vấn, mặc dù điều này có thể trở nên chậm nếu bạn có số lượng truy vấn lớn. Để tối ưu hóa quá trình, có thể lập chỉ mục cả truy vấn lẫn tài liệu, và do đó thu hẹp tập hợp các truy vấn có thể khớp 63.
Kiến trúc Event-Driven và RPC
Trong “Event-Driven Architectures”, chúng ta đã thảo luận về các hệ thống message-passing (truyền thông điệp) như một sự thay thế cho RPC, tức là như một cơ chế để các dịch vụ giao tiếp, như được sử dụng ví dụ trong mô hình actor. Mặc dù các hệ thống này cũng dựa trên thông điệp và sự kiện, chúng ta thường không coi chúng là stream processor:
Các framework actor chủ yếu là cơ chế để quản lý đồng thời và thực thi phân tán các module giao tiếp, trong khi stream processing chủ yếu là kỹ thuật quản lý dữ liệu.
Giao tiếp giữa các actor thường là tạm thời và một-một, trong khi event log là bền vững và đa người đăng ký.
Các actor có thể giao tiếp theo các cách tùy ý (bao gồm các mẫu request/response vòng lặp), nhưng các stream processor thường được thiết lập trong các pipeline không chu trình nơi mỗi stream là đầu ra của một job cụ thể, và được dẫn xuất từ một tập hợp input stream được xác định rõ ràng.
Dù vậy, có một số vùng giao thoa giữa hệ thống kiểu RPC và stream processing. Ví dụ, Apache Storm có một tính năng gọi là distributed RPC (RPC phân tán), cho phép các truy vấn người dùng được phân phối đến một tập hợp các node cũng xử lý event stream; các truy vấn này sau đó được xen kẽ với các sự kiện từ input stream, và kết quả có thể được tổng hợp và gửi lại cho người dùng. (Xem thêm “Multi-shard data processing”.)
Cũng có thể xử lý stream bằng các framework actor. Tuy nhiên, nhiều framework như vậy không đảm bảo việc gửi thông điệp trong trường hợp crash, nên quá trình xử lý không có khả năng chịu lỗi trừ khi bạn triển khai thêm logic thử lại.
Lý luận về Thời gian
Các stream processor thường cần xử lý thời gian, đặc biệt khi được sử dụng cho mục đích analytics, thường xuyên sử dụng time window như “trung bình trong năm phút qua.” Có vẻ như ý nghĩa của “năm phút qua” nên rõ ràng và không mơ hồ, nhưng tiếc thay khái niệm này lại phức tạp đến bất ngờ.
Trong một batch process, các task xử lý nhanh chóng qua một tập hợp lớn các sự kiện lịch sử. Nếu cần phân tích theo thời gian, batch process cần nhìn vào timestamp được nhúng trong mỗi sự kiện. Không có ý nghĩa gì khi nhìn vào đồng hồ hệ thống của máy chạy batch process, vì thời điểm process được chạy không liên quan gì đến thời điểm các sự kiện thực sự xảy ra.
Một batch process có thể đọc một năm lịch sử sự kiện trong vài phút; trong hầu hết các trường hợp, dòng thời gian quan tâm là năm lịch sử, không phải vài phút xử lý. Hơn nữa, sử dụng timestamp trong các sự kiện cho phép xử lý là xác định: chạy cùng một process lại trên cùng đầu vào cho ra cùng kết quả.
Mặt khác, nhiều framework stream processing sử dụng đồng hồ hệ thống cục bộ trên máy xử lý (processing time, thời gian xử lý) để xác định windowing 64. Cách tiếp cận này có ưu điểm là đơn giản, và hợp lý nếu độ trễ giữa tạo sự kiện và xử lý sự kiện là ngắn đến mức không đáng kể. Tuy nhiên, nó bị hỏng nếu có độ trễ xử lý đáng kể, tức là nếu việc xử lý có thể xảy ra muộn đáng chú ý so với thời điểm sự kiện thực sự xảy ra.
Thời gian sự kiện so với thời gian xử lý
Có nhiều lý do khiến xử lý có thể bị trễ: xếp hàng chờ, lỗi mạng, vấn đề hiệu năng dẫn đến tranh chấp trong message broker hoặc processor, khởi động lại stream consumer, hoặc xử lý lại các sự kiện quá khứ trong khi phục hồi sau sự cố hoặc sau khi sửa lỗi trong mã.
Hơn nữa, độ trễ thông điệp cũng có thể dẫn đến thứ tự thông điệp không thể đoán trước. Ví dụ, giả sử một người dùng đầu tiên thực hiện một yêu cầu web (được xử lý bởi web server A), rồi một yêu cầu thứ hai (được xử lý bởi server B). A và B phát ra các sự kiện mô tả các yêu cầu mà chúng xử lý, nhưng sự kiện của B đến message broker trước sự kiện của A. Bây giờ stream processor sẽ thấy sự kiện B trước rồi mới đến sự kiện A, mặc dù chúng thực sự xảy ra theo thứ tự ngược lại.
Nếu cần một phép tương tự, hãy xem các bộ phim Star Wars: Tập IV được phát hành năm 1977, Tập V năm 1980 và Tập VI năm 1983, tiếp theo là Tập I, II và III vào năm 1999, 2002 và 2005, và Tập VII, VIII và IX vào năm 2015, 2017 và 2019 65. Nếu bạn xem các bộ phim theo thứ tự chúng ra mắt, thứ tự bạn xử lý các bộ phim không nhất quán với thứ tự câu chuyện. (Số tập giống như timestamp của sự kiện, và ngày bạn xem bộ phim là processing time.) Là con người, chúng ta có thể đối phó với những gián đoạn như vậy, nhưng các thuật toán stream processing cần được viết cụ thể để phù hợp với các vấn đề về thời gian và thứ tự như vậy.
Nhầm lẫn event time (thời gian sự kiện) và processing time dẫn đến dữ liệu xấu. Ví dụ, giả sử bạn có một stream processor đo tốc độ yêu cầu (đếm số lượng yêu cầu mỗi giây). Nếu bạn triển khai lại stream processor, nó có thể bị tắt trong một phút và xử lý hàng đợi tồn đọng khi khởi động lại. Nếu bạn đo tốc độ dựa trên processing time, sẽ trông như thể có đột biến bất thường đột ngột của các yêu cầu trong khi xử lý hàng tồn đọng, trong khi thực tế tốc độ yêu cầu thực sự là ổn định (Hình 12-8).
Xử lý sự kiện đến trễ
Một vấn đề khó khi định nghĩa window theo event time là bạn không bao giờ chắc chắn khi nào bạn đã nhận được tất cả các sự kiện cho một window cụ thể, hoặc liệu có còn một số sự kiện sắp đến hay không.
Ví dụ, giả sử bạn đang nhóm các sự kiện vào các window một phút để bạn có thể đếm số lượng yêu cầu mỗi phút. Bạn đã đếm được một số sự kiện với timestamp rơi vào phút thứ 37 của giờ, và thời gian đã tiến lên; bây giờ hầu hết các sự kiện đến rơi vào phút thứ 38 và 39 của giờ. Khi nào bạn tuyên bố rằng bạn đã kết thúc window cho phút thứ 37, và xuất giá trị bộ đếm của nó?
Bạn có thể hết thời gian chờ và tuyên bố một window sẵn sàng sau khi bạn không thấy bất kỳ sự kiện mới nào cho window đó trong một thời gian. Tuy nhiên, vẫn có thể xảy ra rằng một số sự kiện đang được đệm trên một máy khác đâu đó, bị trễ do gián đoạn mạng. Bạn cần có khả năng xử lý các sự kiện straggler (đến muộn) như vậy khi đến sau khi window đã được tuyên bố hoàn tất. Nhìn chung, bạn có hai lựa chọn 1:
Bỏ qua các sự kiện straggler, vì chúng có thể là một phần trăm nhỏ sự kiện trong điều kiện bình thường. Bạn có thể theo dõi số lượng sự kiện bị bỏ như một chỉ số, và cảnh báo nếu bạn bắt đầu bỏ một lượng dữ liệu đáng kể.
Xuất bản một correction (sửa chữa), một giá trị cập nhật cho window với các sự kiện straggler được bao gồm. Bạn cũng có thể cần thu hồi đầu ra trước đó.
Trong một số trường hợp, có thể sử dụng một thông điệp đặc biệt để chỉ ra “Từ bây giờ sẽ không có thêm thông điệp nào có timestamp trước t,” điều này có thể được consumer sử dụng để kích hoạt window 66. Tuy nhiên, nếu có nhiều producer trên các máy khác nhau đang tạo sự kiện, mỗi máy có ngưỡng timestamp tối thiểu riêng, consumer cần theo dõi từng producer riêng lẻ. Thêm và xóa producer phức tạp hơn trong trường hợp này.
Bạn đang dùng đồng hồ của ai?
Gán timestamp cho sự kiện thậm chí còn khó hơn khi sự kiện có thể được đệm ở nhiều điểm trong hệ thống. Ví dụ, hãy xem xét một ứng dụng di động báo cáo các sự kiện cho số liệu sử dụng đến một server. Ứng dụng có thể được sử dụng khi thiết bị ngoại tuyến, trong trường hợp đó nó sẽ đệm các sự kiện cục bộ trên thiết bị và gửi chúng đến server khi có kết nối internet lần sau (có thể là vài giờ hoặc thậm chí vài ngày sau đó). Đối với bất kỳ consumer nào của stream này, các sự kiện sẽ xuất hiện như là straggler cực kỳ trễ.
Trong bối cảnh này, timestamp trên các sự kiện thực sự phải là thời gian tương tác người dùng xảy ra, theo đồng hồ cục bộ của thiết bị di động. Tuy nhiên, đồng hồ trên thiết bị do người dùng kiểm soát thường không thể tin cậy, vì nó có thể bị đặt sai thời gian một cách tình cờ hoặc cố ý (xem “Clock Synchronization and Accuracy”). Thời gian mà sự kiện được server nhận (theo đồng hồ của server) có nhiều khả năng chính xác hơn, vì server nằm trong tầm kiểm soát của bạn, nhưng ít có ý nghĩa hơn về mặt mô tả tương tác người dùng.
Để điều chỉnh đồng hồ thiết bị không chính xác, một cách tiếp cận là ghi lại ba timestamp 67:
Thời gian sự kiện xảy ra, theo đồng hồ thiết bị
Thời gian sự kiện được gửi đến server, theo đồng hồ thiết bị
Thời gian sự kiện được server nhận, theo đồng hồ server
Bằng cách trừ timestamp thứ hai từ timestamp thứ ba, bạn có thể ước tính độ lệch giữa đồng hồ thiết bị và đồng hồ server (giả sử độ trễ mạng là không đáng kể so với độ chính xác timestamp yêu cầu). Sau đó bạn có thể áp dụng độ lệch đó cho event timestamp, và do đó ước tính thời gian thực sự mà sự kiện thực sự xảy ra (giả sử độ lệch đồng hồ thiết bị không thay đổi giữa thời điểm sự kiện xảy ra và thời điểm nó được gửi đến server).
Vấn đề này không chỉ xảy ra với stream processing, batch processing cũng gặp phải chính xác các vấn đề tương tự về lý luận thời gian. Nó chỉ đáng chú ý hơn trong bối cảnh streaming, nơi chúng ta nhận thức rõ hơn về sự trôi qua của thời gian.
Các loại window
Khi bạn biết timestamp của sự kiện nên được xác định như thế nào, bước tiếp theo là quyết định cách định nghĩa window theo các khoảng thời gian. Window sau đó có thể được sử dụng cho các tổng hợp, ví dụ để đếm sự kiện, hoặc để tính trung bình các giá trị trong window. Có nhiều loại window phổ biến được sử dụng 64, 68:
- Tumbling window (Cửa sổ lật)
Tumbling window có độ dài cố định, và mỗi sự kiện thuộc chính xác một window. Ví dụ, nếu bạn có tumbling window 1 phút, tất cả các sự kiện có timestamp từ 10:03:00 đến 10:03:59 được nhóm vào một window, các sự kiện từ 10:04:00 đến 10:04:59 vào window tiếp theo, v.v. Bạn có thể triển khai tumbling window 1 phút bằng cách lấy từng event timestamp và làm tròn xuống đến phút gần nhất để xác định window mà nó thuộc về.
- Hopping window (Cửa sổ nhảy)
Hopping window cũng có độ dài cố định, nhưng cho phép các window chồng lên nhau để cung cấp một số làm mịn. Ví dụ, một window 5 phút với kích thước bước nhảy 1 phút sẽ chứa các sự kiện từ 10:03:00 đến 10:07:59, sau đó window tiếp theo sẽ bao gồm các sự kiện từ 10:04:00 đến 10:08:59, v.v. Bạn có thể triển khai hopping window này bằng cách trước tiên tính toán các tumbling window 1 phút, rồi tổng hợp qua nhiều window liền kề.
- Sliding window (Cửa sổ trượt)
Sliding window chứa tất cả các sự kiện xảy ra trong một khoảng cách thời gian nhất định với nhau. Ví dụ, một sliding window 5 phút sẽ bao gồm các sự kiện lúc 10:03:39 và 10:08:12, vì chúng cách nhau ít hơn 5 phút (lưu ý rằng tumbling và hopping window 5 phút sẽ không đặt hai sự kiện này trong cùng một window, vì chúng dùng ranh giới cố định). Sliding window có thể được triển khai bằng cách duy trì một bộ đệm sự kiện được sắp xếp theo thời gian và loại bỏ các sự kiện cũ khi chúng hết hạn khỏi window.
- Session window (Cửa sổ phiên)
Không giống như các loại window khác, session window không có thời lượng cố định. Thay vào đó, nó được định nghĩa bằng cách nhóm tất cả các sự kiện của cùng một người dùng xảy ra liền kề nhau theo thời gian, và window kết thúc khi người dùng không hoạt động trong một khoảng thời gian (ví dụ, nếu không có sự kiện nào trong 30 phút). Sessionization (phân chia theo phiên) là một yêu cầu phổ biến trong phân tích website.
Các thao tác trên window thường duy trì trạng thái tạm thời. Trong một số trường hợp, trạng thái có kích thước cố định, bất kể window lớn hay nhỏ, hay có bao nhiêu sự kiện xảy ra: ví dụ, một thao tác đếm chỉ có một bộ đếm duy nhất bất kể kích thước window hoặc số lượng sự kiện. Mặt khác, sliding window hoặc stream join, được thảo luận ở phần tiếp theo, yêu cầu các sự kiện phải được đệm cho đến khi window kết thúc. Do đó, kích thước window lớn hoặc các luồng có thông lượng cao có thể khiến bộ xử lý luồng phải duy trì rất nhiều trạng thái tạm thời. Khi đó, bạn phải đảm bảo rằng các máy chạy tác vụ xử lý luồng có đủ dung lượng để duy trì trạng thái này, dù là trong bộ nhớ hay trên đĩa.
Stream Joins (Kết hợp luồng)
Trong “JOIN and GROUP BY” chúng ta đã thảo luận về cách các tác vụ batch có thể join các tập dữ liệu theo khóa, và cách các join như vậy tạo thành một phần quan trọng của các data pipeline. Vì xử lý luồng tổng quát hóa data pipeline thành xử lý tăng dần (incremental processing) trên các tập dữ liệu không có biên giới (unbounded datasets), nhu cầu join trên các luồng cũng hoàn toàn tương tự.
Tuy nhiên, thực tế là các sự kiện mới có thể xuất hiện bất kỳ lúc nào trên một luồng khiến việc join trên luồng khó hơn so với trong các tác vụ batch. Để hiểu rõ hơn tình huống này, hãy phân biệt ba loại join khác nhau: stream-stream join, stream-table join, và table-table join. Trong các phần tiếp theo, chúng ta sẽ minh họa từng loại bằng ví dụ cụ thể.
Stream-stream join (window join)
Giả sử bạn có tính năng tìm kiếm trên website và muốn phát hiện các xu hướng mới nhất trong các URL được tìm kiếm. Mỗi khi ai đó nhập một truy vấn tìm kiếm, bạn ghi lại một sự kiện chứa truy vấn và kết quả được trả về. Mỗi khi ai đó nhấp vào một trong các kết quả tìm kiếm, bạn ghi lại một sự kiện khác ghi lại lần nhấp đó. Để tính tỉ lệ nhấp (click-through rate) cho mỗi URL trong kết quả tìm kiếm, bạn cần kết hợp các sự kiện cho hành động tìm kiếm và hành động nhấp chuột, được liên kết với nhau qua cùng một session ID. Các phân tích tương tự cũng cần thiết trong các hệ thống quảng cáo 69.
Lần nhấp có thể không bao giờ xảy ra nếu người dùng bỏ dở tìm kiếm, và ngay cả khi nó xảy ra, khoảng thời gian giữa tìm kiếm và nhấp có thể biến thiên rất lớn: trong nhiều trường hợp có thể chỉ vài giây, nhưng cũng có thể kéo dài đến vài ngày hoặc vài tuần (nếu người dùng thực hiện tìm kiếm, quên mất tab trình duyệt đó, rồi quay lại tab và nhấp vào kết quả sau đó). Do độ trễ mạng biến đổi, sự kiện nhấp thậm chí có thể đến trước sự kiện tìm kiếm. Bạn có thể chọn một window phù hợp cho join, ví dụ bạn có thể chọn join một lần nhấp với một lượt tìm kiếm nếu chúng xảy ra cách nhau không quá một giờ.
Lưu ý rằng việc nhúng các chi tiết của tìm kiếm vào sự kiện nhấp không tương đương với việc join các sự kiện: làm như vậy chỉ cho bạn biết về các trường hợp người dùng nhấp vào kết quả tìm kiếm, không phải về các lần tìm kiếm mà người dùng không nhấp vào kết quả nào. Để đo lường chất lượng tìm kiếm, bạn cần tỉ lệ nhấp chính xác, mà để có được điều đó bạn cần cả sự kiện tìm kiếm lẫn sự kiện nhấp.
Để triển khai loại join này, một bộ xử lý luồng cần duy trì state (trạng thái): ví dụ, tất cả các sự kiện xảy ra trong giờ vừa qua, được lập chỉ mục theo session ID. Bất cứ khi nào có sự kiện tìm kiếm hoặc sự kiện nhấp xảy ra, nó được thêm vào chỉ mục thích hợp, và bộ xử lý luồng cũng kiểm tra chỉ mục kia để xem liệu một sự kiện khác với cùng session ID đã đến chưa. Nếu có sự kiện khớp, bạn phát ra một sự kiện cho biết kết quả tìm kiếm nào đã được nhấp. Nếu sự kiện tìm kiếm hết hạn mà không thấy sự kiện nhấp khớp, bạn phát ra một sự kiện cho biết kết quả tìm kiếm nào không được nhấp.
Stream-table join (làm giàu luồng)
Trong “JOIN and GROUP BY” (Hình 11-2) chúng ta đã thấy một ví dụ về tác vụ batch join hai tập dữ liệu: một tập hợp các sự kiện hoạt động của người dùng và một cơ sở dữ liệu về hồ sơ người dùng. Rất tự nhiên khi coi các sự kiện hoạt động của người dùng là một luồng, và thực hiện join tương tự một cách liên tục trong bộ xử lý luồng: đầu vào là một luồng các sự kiện hoạt động chứa user ID, và đầu ra là một luồng các sự kiện hoạt động trong đó user ID đã được bổ sung thêm thông tin hồ sơ về người dùng. Quá trình này đôi khi được gọi là enriching (làm giàu) các sự kiện hoạt động với thông tin từ cơ sở dữ liệu.
Để thực hiện join này, bộ xử lý luồng cần xem xét từng sự kiện hoạt động một, tra cứu user ID của sự kiện trong cơ sở dữ liệu, và thêm thông tin hồ sơ vào sự kiện hoạt động. Việc tra cứu cơ sở dữ liệu có thể được thực hiện bằng cách truy vấn cơ sở dữ liệu từ xa; tuy nhiên, như đã thảo luận trong “JOIN and GROUP BY”, các truy vấn từ xa như vậy thường chậm và có nguy cơ làm quá tải cơ sở dữ liệu 58.
Một cách tiếp cận khác là tải một bản sao của cơ sở dữ liệu vào bộ xử lý luồng để có thể truy vấn cục bộ mà không cần round-trip qua mạng. Kỹ thuật này được gọi là hash join vì bản sao cục bộ của cơ sở dữ liệu có thể là một bảng băm trong bộ nhớ nếu đủ nhỏ, hoặc một chỉ mục trên đĩa cục bộ.
Sự khác biệt so với các tác vụ batch là tác vụ batch sử dụng ảnh chụp tại một thời điểm (point-in-time snapshot) của cơ sở dữ liệu làm đầu vào, trong khi bộ xử lý luồng chạy lâu dài, và nội dung của cơ sở dữ liệu có thể thay đổi theo thời gian, vì vậy bản sao cục bộ của cơ sở dữ liệu trong bộ xử lý luồng cần được cập nhật liên tục. Vấn đề này có thể được giải quyết bằng change data capture (CDC): bộ xử lý luồng có thể đăng ký nhận changelog của cơ sở dữ liệu hồ sơ người dùng cùng với luồng các sự kiện hoạt động. Khi một hồ sơ được tạo hoặc sửa đổi, bộ xử lý luồng cập nhật bản sao cục bộ của mình. Như vậy, chúng ta có được một join giữa hai luồng: các sự kiện hoạt động và các bản cập nhật hồ sơ.
Stream-table join thực ra rất giống với stream-stream join; sự khác biệt lớn nhất là đối với luồng changelog của bảng, join sử dụng một window kéo dài về “thời điểm ban đầu” (một window về mặt khái niệm là vô hạn), với các phiên bản mới hơn của bản ghi ghi đè lên các phiên bản cũ hơn. Đối với đầu vào là luồng, join có thể không duy trì window nào cả.
Table-table join (duy trì materialized view)
Hãy xem xét ví dụ về timeline mạng xã hội mà chúng ta đã thảo luận trong “Case Study: Social Network Home Timelines”. Chúng ta đã nói rằng khi người dùng muốn xem timeline trang chủ của họ, việc duyệt qua tất cả những người họ theo dõi, tìm các bài đăng gần đây của họ và gộp lại là quá tốn kém.
Thay vào đó, chúng ta muốn có một timeline cache: một loại “hộp thư đến” riêng cho mỗi người dùng để các bài đăng được ghi vào khi chúng được gửi, để việc đọc timeline chỉ là một lần tra cứu đơn giản. Việc hiện thực hóa (materializing) và duy trì bộ cache này đòi hỏi phải xử lý các sự kiện sau:
Khi người dùng u gửi một bài đăng mới, nó được thêm vào timeline của mọi người dùng đang theo dõi u.
Khi người dùng xóa một bài đăng, hoặc xóa toàn bộ tài khoản của họ, bài đăng đó được xóa khỏi timeline của tất cả người dùng.
Khi người dùng u
1bắt đầu theo dõi người dùng u2, các bài đăng gần đây của u2được thêm vào timeline của u1.Khi người dùng u
1bỏ theo dõi người dùng u2, các bài đăng của u2bị xóa khỏi timeline của u1.
Để triển khai việc duy trì cache này trong một bộ xử lý luồng, bạn cần các luồng sự kiện cho các bài đăng (gửi và xóa) và cho các mối quan hệ theo dõi (theo dõi và bỏ theo dõi). Bộ xử lý luồng cần duy trì một cơ sở dữ liệu chứa tập hợp những người theo dõi cho mỗi người dùng để biết những timeline nào cần được cập nhật khi có bài đăng mới.
Một cách nhìn khác về bộ xử lý luồng này là nó duy trì một materialized view cho một truy vấn join hai bảng (posts và follows), đại loại như sau:
SELECT follows.follower_id AS timeline_id,
array_agg(posts.* ORDER BY posts.timestamp DESC)
FROM posts
JOIN follows ON follows.followee_id = posts.sender_id
GROUP BY follows.follower_idJoin của các luồng tương ứng trực tiếp với join của các bảng trong truy vấn đó. Các timeline thực chất là một bộ cache của kết quả truy vấn này, được cập nhật mỗi khi các bảng bên dưới thay đổi.
Note
Nếu bạn coi một luồng là đạo hàm của một bảng, như trong Hình 12-7, và coi một join là tích của hai bảng u·v, một điều thú vị xảy ra: luồng các thay đổi của materialized join tuân theo quy tắc tích (u·v)′ = u′v + uv′. Nói cách khác: bất kỳ thay đổi nào của posts được join với danh sách followers hiện tại, và bất kỳ thay đổi nào của followers được join với các posts hiện tại 37.
Sự phụ thuộc thời gian của join
Ba loại join được mô tả ở đây (stream-stream, stream-table, và table-table) có nhiều điểm chung: tất cả đều yêu cầu bộ xử lý luồng duy trì một số trạng thái (các sự kiện tìm kiếm và nhấp, hồ sơ người dùng, hoặc danh sách followers) dựa trên một đầu vào join, và truy vấn trạng thái đó trên các thông điệp từ đầu vào join kia.
Thứ tự của các sự kiện duy trì trạng thái là quan trọng (việc bạn theo dõi rồi bỏ theo dõi, hay bỏ theo dõi rồi theo dõi là khác nhau). Trong một event log được phân mảnh như Kafka, thứ tự của các sự kiện trong một mảnh (partition) đơn được bảo toàn, nhưng thường không có đảm bảo về thứ tự giữa các luồng hoặc các mảnh khác nhau.
Điều này đặt ra một câu hỏi: nếu các sự kiện trên các luồng khác nhau xảy ra vào khoảng cùng một thời điểm, chúng được xử lý theo thứ tự nào? Trong ví dụ stream-table join, nếu người dùng cập nhật hồ sơ của họ, những sự kiện hoạt động nào được join với hồ sơ cũ (được xử lý trước khi cập nhật hồ sơ), và những sự kiện nào được join với hồ sơ mới (được xử lý sau khi cập nhật hồ sơ)? Nói cách khác: nếu trạng thái thay đổi theo thời gian, và bạn join với một số trạng thái, bạn sử dụng thời điểm nào để join?
Sự phụ thuộc thời gian như vậy có thể xảy ra ở nhiều nơi. Ví dụ, nếu bạn bán hàng, bạn cần áp dụng mức thuế đúng vào hóa đơn, điều này phụ thuộc vào quốc gia hoặc tiểu bang, loại sản phẩm, và ngày bán (vì mức thuế thay đổi theo thời gian). Khi join các giao dịch bán hàng với bảng mức thuế, bạn có thể muốn join với mức thuế tại thời điểm bán, có thể khác với mức thuế hiện tại nếu bạn đang xử lý lại dữ liệu lịch sử.
Nếu thứ tự các sự kiện giữa các luồng không được xác định, join trở nên không xác định (nondeterministic) 70, nghĩa là bạn không thể chạy lại cùng một tác vụ trên cùng một đầu vào và nhất thiết nhận được cùng một kết quả: các sự kiện trên các luồng đầu vào có thể được xen kẽ theo một cách khác khi bạn chạy lại tác vụ.
Trong các data warehouse, vấn đề này được gọi là slowly changing dimension (SCD, chiều thay đổi chậm), và nó thường được giải quyết bằng cách sử dụng một định danh duy nhất cho một phiên bản cụ thể của bản ghi được join: ví dụ, mỗi khi mức thuế thay đổi, nó được gán một định danh mới, và hóa đơn bao gồm định danh của mức thuế tại thời điểm bán 71, 72. Thay đổi này làm cho join trở nên xác định, nhưng có hệ quả là không thể nén log (log compaction), vì tất cả các phiên bản của bản ghi trong bảng cần được giữ lại. Ngoài ra, bạn có thể denormalize dữ liệu và bao gồm mức thuế áp dụng trực tiếp trong mỗi sự kiện bán hàng.
Khả năng chịu lỗi
Trong phần cuối cùng của chương này, hãy xem xét cách các bộ xử lý luồng có thể chịu đựng lỗi. Chúng ta đã thấy trong Chương 11 rằng các framework xử lý batch có thể chịu đựng lỗi khá dễ dàng: nếu một tác vụ thất bại, nó chỉ cần được khởi động lại trên một máy khác, và đầu ra của tác vụ thất bại bị loại bỏ. Việc thử lại trong suốt (transparent retry) này có thể thực hiện được vì các file đầu vào là bất biến, mỗi tác vụ ghi đầu ra ra một file riêng biệt, và đầu ra chỉ được hiển thị khi một tác vụ hoàn thành thành công.
Đặc biệt, cách tiếp cận batch để chịu lỗi đảm bảo rằng đầu ra của tác vụ batch giống như thể không có gì xảy ra sai, ngay cả khi thực tế một số tác vụ đã thất bại. Có vẻ như mọi bản ghi đầu vào đều được xử lý đúng một lần, không có bản ghi nào bị bỏ qua, và không có bản ghi nào được xử lý hai lần. Mặc dù việc khởi động lại tác vụ có nghĩa là các bản ghi có thể thực sự được xử lý nhiều lần, hiệu ứng có thể nhìn thấy trong đầu ra là như thể chúng chỉ được xử lý một lần. Nguyên tắc này được gọi là exactly-once semantics (ngữ nghĩa đúng một lần), mặc dù effectively-once (hiệu quả một lần) sẽ là thuật ngữ mô tả chính xác hơn 73.
Vấn đề về khả năng chịu lỗi tương tự cũng phát sinh trong xử lý luồng, nhưng ít đơn giản hơn để xử lý: việc chờ cho đến khi một tác vụ hoàn thành trước khi hiển thị đầu ra của nó không phải là một lựa chọn, vì một luồng là vô hạn và vì vậy bạn không bao giờ có thể hoàn thành việc xử lý nó.
Microbatching và checkpointing
Một giải pháp là chia luồng thành các khối nhỏ, và xử lý mỗi khối như một tác vụ batch thu nhỏ. Cách tiếp cận này được gọi là microbatching, và được sử dụng trong Spark Streaming 74. Kích thước batch thường khoảng một giây, là kết quả của sự đánh đổi về hiệu suất: các batch nhỏ hơn gây ra chi phí lập lịch và điều phối lớn hơn, trong khi các batch lớn hơn có nghĩa là độ trễ dài hơn trước khi kết quả của bộ xử lý luồng được hiển thị.
Microbatching cũng ngầm cung cấp một tumbling window bằng với kích thước batch (theo thời gian xử lý, không phải theo timestamp của sự kiện); bất kỳ tác vụ nào yêu cầu window lớn hơn cần phải mang trạng thái rõ ràng từ microbatch này sang microbatch tiếp theo.
Một biến thể, được sử dụng trong Apache Flink, là định kỳ tạo ra các rolling checkpoint (điểm kiểm tra luân phiên) của trạng thái và ghi chúng vào bộ lưu trữ bền vững 75, 76. Nếu một stream operator gặp sự cố, nó có thể khởi động lại từ checkpoint gần nhất và loại bỏ bất kỳ đầu ra nào được tạo ra giữa checkpoint cuối cùng và sự cố. Các checkpoint được kích hoạt bởi các barrier trong luồng thông điệp, tương tự như ranh giới giữa các microbatch, nhưng không ép buộc một kích thước window cụ thể.
Trong phạm vi của framework xử lý luồng, các cách tiếp cận microbatching và checkpointing cung cấp cùng ngữ nghĩa exactly-once như xử lý batch. Tuy nhiên, ngay khi đầu ra rời khỏi bộ xử lý luồng (ví dụ, bằng cách ghi vào cơ sở dữ liệu, gửi thông điệp đến một message broker bên ngoài, hoặc gửi email), framework không còn có thể loại bỏ đầu ra của một microbatch thất bại nữa. Trong trường hợp này, việc khởi động lại một tác vụ thất bại khiến tác dụng phụ bên ngoài xảy ra hai lần, và chỉ microbatching hoặc checkpointing không đủ để ngăn chặn vấn đề này.
Atomic commit được xem xét lại
Để tạo ra ảo tưởng xử lý đúng một lần trong trường hợp có lỗi, chúng ta cần đảm bảo rằng tất cả các đầu ra và tác dụng phụ của việc xử lý một sự kiện có hiệu lực khi và chỉ khi quá trình xử lý thành công. Các hiệu ứng đó bao gồm bất kỳ thông điệp nào được gửi đến các operator downstream hoặc các hệ thống nhắn tin bên ngoài (bao gồm email hoặc thông báo đẩy), bất kỳ thao tác ghi cơ sở dữ liệu nào, bất kỳ thay đổi nào đối với trạng thái của operator, và bất kỳ sự xác nhận nào về các thông điệp đầu vào (bao gồm việc di chuyển consumer offset về phía trước trong một log-based message broker).
Tất cả những thứ đó phải xảy ra một cách nguyên tử (atomically), hoặc không cái nào được xảy ra, nhưng chúng không nên bị lệch pha nhau. Nếu cách tiếp cận này nghe có vẻ quen thuộc, đó là vì chúng ta đã thảo luận về nó trong “Exactly-once message processing” trong bối cảnh các giao dịch phân tán và two-phase commit.
Trong Chương 10 chúng ta đã thảo luận về các vấn đề trong các triển khai truyền thống của các giao dịch phân tán, chẳng hạn như XA. Tuy nhiên, trong các môi trường hạn chế hơn, có thể triển khai cơ sở atomic commit như vậy một cách hiệu quả. Cách tiếp cận này được sử dụng trong Google Cloud Dataflow 66, 75, VoltDB 77, và Apache Kafka 78, 79. Không giống như XA, các triển khai này không cố gắng cung cấp giao dịch trên các công nghệ không đồng nhất, mà thay vào đó giữ các giao dịch bên trong bằng cách quản lý cả thay đổi trạng thái và nhắn tin trong framework xử lý luồng. Chi phí của giao thức giao dịch có thể được phân bổ bằng cách xử lý nhiều thông điệp đầu vào trong một giao dịch duy nhất.
Idempotence (tính lũy đẳng)
Mục tiêu của chúng ta là loại bỏ đầu ra một phần của bất kỳ tác vụ thất bại nào để chúng có thể được thử lại an toàn mà không có hiệu lực hai lần. Các giao dịch phân tán là một cách để đạt được mục tiêu đó, nhưng một cách khác là dựa vào idempotence (tính lũy đẳng), như chúng ta đã thấy trong “Durable Execution and Workflows” 80.
Một thao tác idempotent là một thao tác mà bạn có thể thực hiện nhiều lần, và nó có cùng hiệu ứng như thể bạn chỉ thực hiện một lần. Ví dụ, xóa một khóa trong key-value store là idempotent (xóa giá trị lần nữa không có thêm hiệu ứng gì), trong khi tăng một bộ đếm thì không idempotent (thực hiện tăng lần nữa có nghĩa là giá trị được tăng hai lần).
Ngay cả khi một thao tác không tự nhiên idempotent, nó thường có thể được làm cho idempotent với một ít metadata bổ sung. Ví dụ, khi tiêu thụ các thông điệp từ Kafka, mỗi thông điệp có một offset liên tục, tăng đơn điệu (monotonically increasing). Khi ghi một giá trị vào cơ sở dữ liệu bên ngoài, bạn có thể bao gồm offset của thông điệp đã kích hoạt lần ghi cuối cùng cùng với giá trị. Như vậy, bạn có thể biết liệu một cập nhật đã được áp dụng chưa, và tránh thực hiện cùng một cập nhật lần nữa.
Việc xử lý trạng thái trong Storm’s Trident dựa trên ý tưởng tương tự. Dựa vào idempotence ngụ ý một số giả định: việc khởi động lại một tác vụ thất bại phải phát lại các thông điệp giống nhau theo cùng thứ tự (log-based message broker làm điều này), quá trình xử lý phải xác định (deterministic), và không có node nào khác được phép đồng thời cập nhật cùng giá trị 81, 82.
Khi chuyển đổi từ một node xử lý này sang node khác, có thể cần fencing (hàng rào) (xem “Distributed Locks and Leases”) để ngăn chặn sự can thiệp từ một node được cho là đã chết nhưng thực tế vẫn còn hoạt động. Mặc dù có tất cả những lưu ý đó, các thao tác idempotent có thể là một cách hiệu quả để đạt được ngữ nghĩa exactly-once với chỉ một chi phí nhỏ.
Tái tạo trạng thái sau khi gặp lỗi
Bất kỳ quá trình xử lý luồng nào yêu cầu trạng thái, ví dụ bất kỳ tổng hợp theo window nào (như bộ đếm, giá trị trung bình, và histogram) và bất kỳ bảng và chỉ mục nào được sử dụng cho join, đều phải đảm bảo rằng trạng thái này có thể được phục hồi sau khi gặp lỗi.
Một lựa chọn là giữ trạng thái trong một datastore từ xa và nhân bản nó, mặc dù việc phải truy vấn cơ sở dữ liệu từ xa cho mỗi thông điệp riêng lẻ có thể chậm. Một giải pháp thay thế là giữ trạng thái cục bộ với bộ xử lý luồng, và nhân bản nó định kỳ. Sau đó, khi bộ xử lý luồng đang phục hồi từ một lỗi, tác vụ mới có thể đọc trạng thái được nhân bản và tiếp tục xử lý mà không mất dữ liệu.
Ví dụ, Flink định kỳ chụp ảnh trạng thái của operator và ghi chúng vào bộ lưu trữ bền vững như một hệ thống file phân tán 75, 76, và Kafka Streams nhân bản các thay đổi trạng thái bằng cách gửi chúng đến một Kafka topic chuyên dụng với log compaction, tương tự như change data capture 83. VoltDB nhân bản trạng thái bằng cách xử lý dư thừa mỗi thông điệp đầu vào trên nhiều node (xem “Actual Serial Execution”).
Trong một số trường hợp, thậm chí không cần nhân bản trạng thái, vì nó có thể được tái tạo từ các luồng đầu vào. Ví dụ, nếu trạng thái bao gồm các tổng hợp trên một window khá ngắn, có thể đủ nhanh để chỉ cần phát lại các sự kiện đầu vào tương ứng với window đó. Nếu trạng thái là một bản sao cục bộ của cơ sở dữ liệu, được duy trì bởi change data capture, cơ sở dữ liệu cũng có thể được tái tạo từ luồng thay đổi được nén log.
Tuy nhiên, tất cả những sự đánh đổi này phụ thuộc vào đặc tính hiệu suất của cơ sở hạ tầng bên dưới: trong một số hệ thống, độ trễ mạng có thể thấp hơn độ trễ truy cập đĩa, và băng thông mạng có thể so sánh được với băng thông đĩa. Không có sự đánh đổi nào là lý tưởng toàn cầu cho mọi tình huống, và lợi thế của trạng thái cục bộ so với trạng thái từ xa cũng có thể thay đổi khi các công nghệ lưu trữ và mạng phát triển.
Tóm tắt
Trong chương này chúng ta đã thảo luận về các luồng sự kiện, mục đích chúng phục vụ, và cách xử lý chúng. Theo một số khía cạnh, xử lý luồng rất giống với xử lý batch mà chúng ta đã thảo luận trong Chương 11, nhưng được thực hiện liên tục trên các luồng không có biên giới (không bao giờ kết thúc) thay vì trên một đầu vào có kích thước cố định 84. Từ góc nhìn này, các message broker và event log phục vụ như là tương đương của hệ thống file trong xử lý luồng.
Chúng ta đã dành một khoảng thời gian để so sánh hai loại message broker:
- AMQP/JMS-style message broker
Broker gán các thông điệp riêng lẻ cho người tiêu thụ, và người tiêu thụ xác nhận các thông điệp riêng lẻ khi chúng đã được xử lý thành công. Các thông điệp bị xóa khỏi broker sau khi chúng được xác nhận. Cách tiếp cận này thích hợp như một hình thức không đồng bộ của RPC (xem thêm “Event-Driven Architectures”), ví dụ trong một hàng đợi tác vụ (task queue), nơi thứ tự xử lý thông điệp chính xác không quan trọng và không cần phải quay lại đọc các thông điệp cũ sau khi chúng được xử lý.
- Log-based message broker
Broker gán tất cả các thông điệp trong một mảnh (shard) cho cùng một node người tiêu thụ, và luôn phân phối các thông điệp theo cùng một thứ tự. Tính song song được đạt được thông qua sharding, và người tiêu thụ theo dõi tiến trình của mình bằng cách checkpointing offset của thông điệp cuối cùng mà họ đã xử lý. Broker giữ lại các thông điệp trên đĩa, vì vậy có thể quay lại và đọc lại các thông điệp cũ nếu cần thiết.
Cách tiếp cận log-based có điểm tương đồng với các replication log được tìm thấy trong cơ sở dữ liệu (xem Chương 6) và các log-structured storage engine (xem Chương 4). Nó cũng là một hình thức đồng thuận (consensus), như chúng ta đã thấy trong Chương 10. Chúng ta đã thấy rằng cách tiếp cận này đặc biệt thích hợp cho các hệ thống xử lý luồng tiêu thụ các luồng đầu vào và tạo ra trạng thái dẫn xuất (derived state) hoặc các luồng đầu ra dẫn xuất.
Về nguồn gốc của các luồng, chúng ta đã thảo luận về một số khả năng: các sự kiện hoạt động của người dùng, các cảm biến cung cấp số đọc định kỳ, và các nguồn cấp dữ liệu (ví dụ, dữ liệu thị trường trong tài chính) được biểu diễn tự nhiên dưới dạng luồng. Chúng ta đã thấy rằng việc coi các thao tác ghi vào cơ sở dữ liệu như là một luồng cũng có thể hữu ích: chúng ta có thể ghi lại changelog, tức là lịch sử của tất cả các thay đổi được thực hiện đối với cơ sở dữ liệu, một cách ngầm thông qua change data capture hoặc một cách rõ ràng thông qua event sourcing. Log compaction cho phép luồng giữ lại một bản sao đầy đủ nội dung của cơ sở dữ liệu.
Việc biểu diễn cơ sở dữ liệu dưới dạng luồng mở ra các cơ hội mạnh mẽ để tích hợp các hệ thống. Bạn có thể giữ cho các hệ thống dữ liệu dẫn xuất như các chỉ mục tìm kiếm, bộ nhớ đệm (cache), và các hệ thống phân tích liên tục được cập nhật bằng cách tiêu thụ log thay đổi và áp dụng chúng vào hệ thống dẫn xuất. Bạn thậm chí có thể xây dựng các view mới trên dữ liệu hiện có bằng cách bắt đầu từ đầu và tiêu thụ log thay đổi từ đầu đến hiện tại.
Các cơ sở để duy trì trạng thái dưới dạng luồng và phát lại thông điệp cũng là nền tảng cho các kỹ thuật cho phép stream join và khả năng chịu lỗi trong các framework xử lý luồng khác nhau. Chúng ta đã thảo luận về một số mục đích của xử lý luồng, bao gồm tìm kiếm các mẫu sự kiện (complex event processing, xử lý sự kiện phức tạp), tính toán các tổng hợp theo window (stream analytics, phân tích luồng), và giữ cho các hệ thống dữ liệu dẫn xuất được cập nhật (materialized views).
Sau đó chúng ta đã thảo luận về những khó khăn khi lý luận về thời gian trong một bộ xử lý luồng, bao gồm sự phân biệt giữa thời gian xử lý và timestamp sự kiện, và vấn đề xử lý các sự kiện chậm trễ (straggler events) đến sau khi bạn nghĩ window của mình đã hoàn chỉnh.
Chúng ta đã phân biệt ba loại join có thể xuất hiện trong các quá trình xử lý luồng:
- Stream-stream joins
Cả hai luồng đầu vào đều bao gồm các sự kiện hoạt động, và toán tử join tìm kiếm các sự kiện liên quan xảy ra trong một window thời gian nào đó. Ví dụ, nó có thể khớp hai hành động được thực hiện bởi cùng một người dùng trong vòng 30 phút. Hai đầu vào join thực tế có thể là cùng một luồng (self-join) nếu bạn muốn tìm các sự kiện liên quan trong cùng một luồng đó.
- Stream-table joins
Một luồng đầu vào bao gồm các sự kiện hoạt động, trong khi luồng kia là một database changelog. Changelog giữ cho một bản sao cục bộ của cơ sở dữ liệu được cập nhật. Đối với mỗi sự kiện hoạt động, toán tử join truy vấn cơ sở dữ liệu và xuất ra một sự kiện hoạt động được làm giàu thêm.
- Table-table joins
Cả hai luồng đầu vào đều là database changelog. Trong trường hợp này, mỗi thay đổi ở một phía được join với trạng thái mới nhất của phía kia. Kết quả là một luồng các thay đổi đối với materialized view của join giữa hai bảng.
Cuối cùng, chúng ta đã thảo luận về các kỹ thuật để đạt được khả năng chịu lỗi và ngữ nghĩa exactly-once trong một bộ xử lý luồng. Cũng như xử lý batch, chúng ta cần loại bỏ đầu ra một phần của bất kỳ tác vụ thất bại nào. Tuy nhiên, vì một quá trình xử lý luồng chạy lâu dài và tạo ra đầu ra liên tục, chúng ta không thể chỉ đơn giản loại bỏ tất cả đầu ra. Thay vào đó, có thể sử dụng cơ chế phục hồi chi tiết hơn, dựa trên microbatching, checkpointing, giao dịch, hoặc các thao tác ghi idempotent.
Footnotes
References
Tyler Akidau, Robert Bradshaw, Craig Chambers, Slava Chernyak, Rafael J. Fernández-Moctezuma, Reuven Lax, Sam McVeety, Daniel Mills, Frances Perry, Eric Schmidt, and Sam Whittle. The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proceedings of the VLDB Endowment, volume 8, issue 12, pages 1792–1803, August 2015. doi:10.14778/2824032.2824076 ↩︎ ↩︎
Harold Abelson, Gerald Jay Sussman, and Julie Sussman. Structure and Interpretation of Computer Programs, 2nd edition. MIT Press, 1996. ISBN: 978-0-262-51087-5, archived at archive.org/details/sicp_20211010 ↩︎
Patrick Th. Eugster, Pascal A. Felber, Rachid Guerraoui, and Anne-Marie Kermarrec. The Many Faces of Publish/Subscribe. ACM Computing Surveys, volume 35, issue 2, pages 114–131, June 2003. doi:10.1145/857076.857078 ↩︎
Don Carney, Uğur Çetintemel, Mitch Cherniack, Christian Convey, Sangdon Lee, Greg Seidman, Michael Stonebraker, Nesime Tatbul, and Stan Zdonik. Monitoring Streams – A New Class of Data Management Applications. At 28th International Conference on Very Large Data Bases (VLDB), August 2002. doi:10.1016/B978-155860869-6/50027-5 ↩︎
Matthew Sackman. Pushing Back. wellquite.org, May 2016. Archived at perma.cc/3KCZ-RUFY ↩︎ ↩︎
Thomas Figg (tef). how (not) to write a pipeline. cohost.org, June 2023. Archived at perma.cc/A3V8-NYCM ↩︎
Vicent Martí. Brubeck, a statsd-Compatible Metrics Aggregator. github.blog, June 2015. Archived at perma.cc/TP3Q-DJYM ↩︎
Seth Lowenberger. MoldUDP64 Protocol Specification V 1.00. nasdaqtrader.com, July 2009. Archived at https://perma.cc/7CRQ-QBD7 ↩︎
Ian Malpass. Measure Anything, Measure Everything. codeascraft.com, February 2011. Archived at archive.org ↩︎
Dieter Plaetinck. 25 Graphite, Grafana and statsd Gotchas. grafana.com, March 2016. Archived at perma.cc/3NP3-67U7 ↩︎
Jeff Lindsay. Web Hooks to Revolutionize the Web. progrium.com, May 2007. Archived at perma.cc/BF9U-XNX4 ↩︎
Jim N. Gray. Queues Are Databases. Microsoft Research Technical Report MSR-TR-95-56, December 1995. Archived at arxiv.org ↩︎
Mark Hapner, Rich Burridge, Rahul Sharma, Joseph Fialli, Kate Stout, and Nigel Deakin. JSR-343 Java Message Service (JMS) 2.0 Specification. jms-spec.java.net, March 2013. Archived at perma.cc/E4YG-46TA ↩︎
Sanjay Aiyagari, Matthew Arrott, Mark Atwell, Jason Brome, Alan Conway, Robert Godfrey, Robert Greig, Pieter Hintjens, John O’Hara, Matthias Radestock, Alexis Richardson, Martin Ritchie, Shahrokh Sadjadi, Rafael Schloming, Steven Shaw, Martin Sustrik, Carl Trieloff, Kim van der Riet, and Steve Vinoski. AMQP: Advanced Message Queuing Protocol Specification. Version 0-9-1, November 2008. Archived at perma.cc/6YJJ-GM9X ↩︎
Architectural overview of Pub/Sub. cloud.google.com, 2025. Archived at perma.cc/VWF5-ABP4 ↩︎ ↩︎
Aris Tzoumas. Lessons from scaling PostgreSQL queues to 100k events per second. rudderstack.com, July 2025. Archived at perma.cc/QD8C-VA4Y ↩︎
Robin Moffatt. Kafka Connect Deep Dive – Error Handling and Dead Letter Queues. confluent.io, March 2019. Archived at perma.cc/KQ5A-AB28 ↩︎
Dunith Danushka. Message reprocessing: How to implement the dead letter queue. redpanda.com. Archived at perma.cc/R7UB-WEWF ↩︎
Damien Gasparina, Loic Greffier, and Sebastien Viale. KIP-1034: Dead letter queue in Kafka Streams. cwiki.apache.org, April 2024. Archived at perma.cc/3VXV-QXAN ↩︎
Jay Kreps, Neha Narkhede, and Jun Rao. Kafka: A Distributed Messaging System for Log Processing. At 6th International Workshop on Networking Meets Databases (NetDB), June 2011. Archived at perma.cc/CSW7-TCQ5 ↩︎
Jay Kreps. Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines). engineering.linkedin.com, April 2014. Archived at archive.org ↩︎
Kartik Paramasivam. How We’re Improving and Advancing Kafka at LinkedIn. engineering.linkedin.com, September 2015. Archived at perma.cc/3S3V-JCYJ ↩︎
Philippe Dobbelaere and Kyumars Sheykh Esmaili. Kafka versus RabbitMQ: A comparative study of two industry reference publish/subscribe implementations. At 11th ACM International Conference on Distributed and Event-based Systems (DEBS), June 2017. doi:10.1145/3093742.3093908 ↩︎
Kate Holterhoff. Why Message Queues Endure: A History. redmonk.com, December 2024. Archived at perma.cc/6DX8-XK4W ↩︎
Andrew Schofield. KIP-932: Queues for Kafka. cwiki.apache.org, May 2023. Archived at perma.cc/LBE4-BEMK ↩︎
Jack Vanlightly. The advantages of queues on logs. jack-vanlightly.com, October 2023. Archived at perma.cc/WJ7V-287K ↩︎
Jay Kreps. The Log: What Every Software Engineer Should Know About Real-Time Data’s Unifying Abstraction. engineering.linkedin.com, December 2013. Archived at perma.cc/2JHR-FR64 ↩︎ ↩︎
Andy Hattemer. Change Data Capture is having a moment. Why? materialize.com, September 2021. Archived at perma.cc/AL37-P53C ↩︎
Prem Santosh Udaya Shankar. Streaming MySQL Tables in Real-Time to Kafka. engineeringblog.yelp.com, August 2016. Archived at perma.cc/5ZR3-2GVV ↩︎
Andreas Andreakis, Ioannis Papapanagiotou. DBLog: A Watermark Based Change-Data-Capture Framework. October 2020. Archived at arxiv.org ↩︎
Jiri Pechanec. Percolator. debezium.io, October 2021. Archived at perma.cc/EQ8E-W6KQ ↩︎
Debezium maintainers. Debezium Connector for Cassandra. debezium.io. Archived at perma.cc/WR6K-EKMD ↩︎
Neha Narkhede. Announcing Kafka Connect: Building Large-Scale Low-Latency Data Pipelines. confluent.io, February 2016. Archived at perma.cc/8WXJ-L6GF ↩︎ ↩︎
Chris Riccomini. Kafka change data capture breaks database encapsulation. cnr.sh, November 2018. Archived at perma.cc/P572-9MKF ↩︎
Gunnar Morling. “Change Data Capture Breaks Encapsulation”. Does it, though? decodable.co, November 2023. Archived at perma.cc/YX2P-WNWR ↩︎
Gunnar Morling. Revisiting the Outbox Pattern. decodable.co, October 2024. Archived at perma.cc/M5ZL-RPS9 ↩︎
Ashish Gupta and Inderpal Singh Mumick. Maintenance of Materialized Views: Problems, Techniques, and Applications. IEEE Data Engineering Bulletin, volume 18, issue 2, pages 3–18, June 1995. Archived at archive.org ↩︎ ↩︎ ↩︎
Mihai Budiu, Tej Chajed, Frank McSherry, Leonid Ryzhyk, Val Tannen. DBSP: Incremental Computation on Streams and Its Applications to Databases. SIGMOD Record, volume 53, issue 1, pages 87–95, March 2024. doi:10.1145/3665252.3665271 ↩︎ ↩︎
Jim Gray and Andreas Reuter. Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1992. ISBN: 9781558601901 ↩︎
Martin Kleppmann. Accounting for Computer Scientists. martin.kleppmann.com, March 2011. Archived at perma.cc/9EGX-P38N ↩︎
Pat Helland. Immutability Changes Everything. At 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015. ↩︎ ↩︎
Martin Kleppmann. Making Sense of Stream Processing. Report, O’Reilly Media, May 2016. Archived at perma.cc/RAY4-JDVX ↩︎
Kartik Paramasivam. Stream Processing Hard Problems – Part 1: Killing Lambda. engineering.linkedin.com, June 2016. Archived at archive.org ↩︎
Stéphane Derosiaux. CQRS: What? Why? How? sderosiaux.medium.com, September 2019. Archived at perma.cc/FZ3U-HVJ4 ↩︎
Baron Schwartz. Immutability, MVCC, and Garbage Collection. xaprb.com, December 2013. Archived at archive.org ↩︎
Daniel Eloff, Slava Akhmechet, Jay Kreps, et al. Re: Turning the Database Inside-out with Apache Samza. Hacker News discussion, news.ycombinator.com, March 2015. Archived at perma.cc/ML9E-JC83 ↩︎
Datomic Documentation: Excision. Cognitect, Inc., docs.datomic.com. Archived at perma.cc/J5QQ-SH32 ↩︎
Fossil Documentation: Deleting Content from Fossil. fossil-scm.org, 2025. Archived at perma.cc/DS23-GTNG ↩︎
Jay Kreps. The irony of distributed systems is that data loss is really easy but deleting data is surprisingly hard. x.com, March 2015. Archived at perma.cc/7RRZ-V7B7 ↩︎
Brent Robinson. Crypto shredding: How it can solve modern data retention challenges. medium.com, January 2019. Archived at https://perma.cc/4LFK-S6XE ↩︎
Matthew D. Green and Ian Miers. Forward Secure Asynchronous Messaging from Puncturable Encryption. At IEEE Symposium on Security and Privacy, May 2015. doi:10.1109/SP.2015.26 ↩︎
David C. Luckham. What’s the Difference Between ESP and CEP? complexevents.com, June 2019. Archived at perma.cc/E7PZ-FDEF ↩︎
Arvind Arasu, Shivnath Babu, and Jennifer Widom. The CQL Continuous Query Language: Semantic Foundations and Query Execution. The VLDB Journal, volume 15, issue 2, pages 121–142, June 2006. doi:10.1007/s00778-004-0147-z ↩︎
Julian Hyde. Data in Flight: How Streaming SQL Technology Can Help Solve the Web 2.0 Data Crunch. ACM Queue, volume 7, issue 11, December 2009. doi:10.1145/1661785.1667562 ↩︎
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. HyperLogLog: The Analysis of a Near-Optimal Cardinality Estimation Algorithm. At Conference on Analysis of Algorithms (AofA), June 2007. doi:10.46298/dmtcs.3545 ↩︎
Jay Kreps. Questioning the Lambda Architecture. oreilly.com, July 2014. Archived at perma.cc/2WY5-HC8Y ↩︎
Ian Reppel. An Overview of Apache Streaming Technologies. ianreppel.org, March 2016. Archived at perma.cc/BB3E-QJLW ↩︎
Jay Kreps. Why Local State is a Fundamental Primitive in Stream Processing. oreilly.com, July 2014. Archived at perma.cc/P8HU-R5LA ↩︎ ↩︎
RisingWave Labs. Deep Dive Into the RisingWave Stream Processing Engine - Part 2: Computational Model. risingwave.com, November 2023. Archived at perma.cc/LM74-XDEL ↩︎
Frank McSherry, Derek G. Murray, Rebecca Isaacs, and Michael Isard. Differential dataflow. At 6th Biennial Conference on Innovative Data Systems Research (CIDR), January 2013. ↩︎
Andy Hattemer. Incremental Computation in the Database. materialize.com, March 2020. Archived at perma.cc/AL94-YVRN ↩︎
Shay Banon. Percolator. elastic.co, February 2011. Archived at perma.cc/LS5R-4FQX ↩︎
Alan Woodward and Martin Kleppmann. Real-Time Full-Text Search with Luwak and Samza. martin.kleppmann.com, April 2015. Archived at perma.cc/2U92-Q7R4 ↩︎
Tyler Akidau. The World Beyond Batch: Streaming 102. oreilly.com, January 2016. Archived at perma.cc/4XF9-8M2K ↩︎ ↩︎
Stephan Ewen. Streaming Analytics with Apache Flink. At Kafka Summit, April 2016. Archived at perma.cc/QBQ4-F9MR ↩︎
Tyler Akidau, Alex Balikov, Kaya Bekiroğlu, Slava Chernyak, Josh Haberman, Reuven Lax, Sam McVeety, Daniel Mills, Paul Nordstrom, and Sam Whittle. MillWheel: Fault-Tolerant Stream Processing at Internet Scale. Proceedings of the VLDB Endowment, volume 6, issue 11, pages 1033–1044, August 2013. doi:10.14778/2536222.2536229 ↩︎ ↩︎
Alex Dean. Improving Snowplow’s Understanding of Time. snowplow.io, September 2015. Archived at perma.cc/6CT9-Z3Q2 ↩︎
Azure Stream Analytics: Windowing functions. Microsoft Azure Reference, learn.microsoft.com, July 2025. Archived at archive.org ↩︎
Rajagopal Ananthanarayanan, Venkatesh Basker, Sumit Das, Ashish Gupta, Haifeng Jiang, Tianhao Qiu, Alexey Reznichenko, Deomid Ryabkov, Manpreet Singh, and Shivakumar Venkataraman. Photon: Fault-Tolerant and Scalable Joining of Continuous Data Streams. At ACM International Conference on Management of Data (SIGMOD), June 2013. doi:10.1145/2463676.2465272 ↩︎
Ben Kirwin. Doing the Impossible: Exactly-Once Messaging Patterns in Kafka. ben.kirw.in, November 2014. Archived at perma.cc/A5QL-QRX7 ↩︎
Pat Helland. Data on the Outside Versus Data on the Inside. At 2nd Biennial Conference on Innovative Data Systems Research (CIDR), January 2005. ↩︎
Ralph Kimball and Margy Ross. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd edition. John Wiley & Sons, 2013. ISBN: 978-1-118-53080-1 ↩︎
Viktor Klang. I’m coining the phrase ’effectively-once’ for message processing with at-least-once + idempotent operations. x.com, October 2016. Archived at perma.cc/7DT9-TDG2 ↩︎
Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, and Ion Stoica. Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. At 4th USENIX Conference in Hot Topics in Cloud Computing (HotCloud), June 2012. ↩︎
Kostas Tzoumas, Stephan Ewen, and Robert Metzger. High-Throughput, Low-Latency, and Exactly-Once Stream Processing with Apache Flink. ververica.com, August 2015. Archived at archive.org ↩︎ ↩︎ ↩︎
Paris Carbone, Gyula Fóra, Stephan Ewen, Seif Haridi, and Kostas Tzoumas. Lightweight Asynchronous Snapshots for Distributed Dataflows. arXiv:1506.08603
Ryan Betts and John Hugg. Fast Data: Smart and at Scale. Report, O’Reilly Media, October 2015. Archived at perma.cc/VQ6S-XQQY ↩︎
Neha Narkhede and Guozhang Wang. Exactly-Once Semantics Are Possible: Here’s How Kafka Does It. confluent.io, June 2019. Archived at perma.cc/Q2AU-Q2ED ↩︎
Jason Gustafson, Flavio Junqueira, Apurva Mehta, Sriram Subramanian, and Guozhang Wang. KIP-98 – Exactly Once Delivery and Transactional Messaging. cwiki.apache.org, November 2016. Archived at perma.cc/95PT-RCTG ↩︎
Pat Helland. Idempotence Is Not a Medical Condition. Communications of the ACM, volume 55, issue 5, page 56, May 2012. doi:10.1145/2160718.2160734 ↩︎
Jay Kreps. Re: Trying to Achieve Deterministic Behavior on Recovery/Rewind. Email to samza-dev mailing list, September 2014. Archived at perma.cc/7DPD-GJNL ↩︎
E. N. (Mootaz) Elnozahy, Lorenzo Alvisi, Yi-Min Wang, and David B. Johnson. A Survey of Rollback-Recovery Protocols in Message-Passing Systems. ACM Computing Surveys, volume 34, issue 3, pages 375–408, September 2002. doi:10.1145/568522.568525 ↩︎
Adam Warski. Kafka Streams – How Does It Fit the Stream Processing Landscape? softwaremill.com, June 2016. Archived at perma.cc/WQ5Q-H2J2 ↩︎
Stephan Ewen, Fabian Hueske, and Xiaowei Jiang. Batch as a Special Case of Streaming and Alibaba’s contribution of Blink. flink.apache.org, February 2019. Archived at perma.cc/A529-SKA9 ↩︎