10. Tính nhất quán và Đồng thuận
Một câu ngạn ngữ cổ cảnh báo rằng, “Đừng bao giờ ra khơi với hai đồng hồ bấm giờ; hãy mang một hoặc ba cái.”
Frederick P. Brooks Jr., The Mythical Man-Month: Essays on Software Engineering (1995)
Có rất nhiều thứ có thể xảy ra sai trong các hệ thống phân tán, như đã thảo luận trong Chương 9. Nếu chúng ta muốn một dịch vụ tiếp tục hoạt động chính xác dù những sự cố đó xảy ra, chúng ta cần tìm cách chịu lỗi (fault tolerance).
Một trong những công cụ tốt nhất chúng ta có để chịu lỗi là replication (sao chép dữ liệu). Tuy nhiên, như chúng ta đã thấy trong Chương 6, việc có nhiều bản sao dữ liệu trên nhiều replica khác nhau mở ra nguy cơ xảy ra các mâu thuẫn. Các lần đọc có thể được xử lý bởi một replica chưa cập nhật, trả về kết quả cũ. Nếu nhiều replica có thể chấp nhận ghi, chúng ta phải giải quyết xung đột giữa các giá trị được ghi đồng thời trên các replica khác nhau. Ở mức độ tổng quát, có hai triết lý cạnh tranh để giải quyết những vấn đề này:
- Eventual consistency (Tính nhất quán cuối cùng)
- Theo triết lý này, thực tế rằng một hệ thống được sao chép sẽ được công khai với ứng dụng, và bạn với tư cách là nhà phát triển ứng dụng được kỳ vọng phải tự xử lý các mâu thuẫn và xung đột có thể phát sinh. Cách tiếp cận này thường được sử dụng trong các hệ thống có multi-leader (xem “Multi-Leader Replication”) và leaderless replication (xem “Leaderless Replication”).
- Strong consistency (Tính nhất quán mạnh)
- Triết lý này cho rằng các ứng dụng không cần phải lo lắng về các chi tiết nội bộ của replication, và hệ thống nên hoạt động như thể nó là một node đơn. Ưu điểm của cách tiếp cận này là đơn giản hơn cho bạn, nhà phát triển ứng dụng. Nhược điểm là tính nhất quán mạnh hơn có chi phí về hiệu suất, và một số loại lỗi mà hệ thống nhất quán cuối cùng có thể chịu đựng được lại gây ra sự cố ngừng hoạt động trong các hệ thống nhất quán mạnh.
Như thường lệ, cách tiếp cận nào tốt hơn phụ thuộc vào ứng dụng của bạn. Nếu bạn có một ứng dụng mà người dùng có thể thay đổi dữ liệu khi ngoại tuyến, thì eventual consistency là không thể tránh khỏi, như đã thảo luận trong “Sync Engines and Local-First Software”. Tuy nhiên, eventual consistency cũng có thể khó xử lý đối với các ứng dụng. Nếu các replica của bạn được đặt trong các trung tâm dữ liệu có kết nối nhanh và đáng tin cậy, thì strong consistency thường phù hợp hơn vì chi phí của nó chấp nhận được.
Trong chương này chúng ta sẽ đi sâu hơn vào cách tiếp cận nhất quán mạnh, xem xét ba lĩnh vực:
- Một thách thức là “strong consistency” khá mơ hồ, vì vậy chúng ta sẽ phát triển một định nghĩa chính xác hơn về những gì chúng ta muốn đạt được: linearizability (khả năng tuyến tính hóa).
- Chúng ta sẽ xem xét vấn đề tạo ID và dấu thời gian. Điều này có vẻ không liên quan đến tính nhất quán nhưng thực ra có mối liên hệ chặt chẽ.
- Chúng ta sẽ khám phá cách các hệ thống phân tán có thể đạt được linearizability trong khi vẫn chịu lỗi được; câu trả lời là các thuật toán consensus (đồng thuận).
Trong quá trình đó, chúng ta sẽ thấy rằng có một số giới hạn cơ bản về những gì có thể và không thể trong một hệ thống phân tán.
Các chủ đề của chương này nổi tiếng là khó triển khai đúng; rất dễ xây dựng các hệ thống hoạt động tốt khi không có lỗi, nhưng lại sụp đổ hoàn toàn khi đối mặt với một tổ hợp không may của các lỗi mà nhà thiết kế hệ thống chưa xem xét. Rất nhiều lý thuyết đã được phát triển để giúp chúng ta suy nghĩ qua những trường hợp biên đó, cho phép chúng ta xây dựng các hệ thống có thể chịu lỗi một cách mạnh mẽ.
Chương này chỉ chạm đến bề mặt: chúng ta sẽ giữ nguyên các trực giác không chính thức, và tránh các chi tiết thuật toán phức tạp, các mô hình hình thức và bằng chứng. Nếu bạn muốn thực hiện công việc nghiêm túc trên các hệ thống consensus và cơ sở hạ tầng tương tự, bạn sẽ cần đào sâu hơn vào lý thuyết nếu muốn có bất kỳ cơ hội nào để hệ thống của bạn đủ bền vững. Như thường lệ, các tham chiếu tài liệu trong chương này cung cấp một số điểm khởi đầu ban đầu.
Linearizability
Nếu bạn muốn một cơ sở dữ liệu được sao chép đơn giản nhất có thể để sử dụng, bạn nên làm cho nó hoạt động như thể nó không được sao chép chút nào. Khi đó người dùng không cần phải lo lắng về replication lag (độ trễ sao chép), xung đột và các mâu thuẫn khác. Điều đó sẽ cho chúng ta lợi thế về khả năng chịu lỗi, nhưng không có sự phức tạp phát sinh từ việc phải suy nghĩ về nhiều replica.
Đây là ý tưởng đằng sau linearizability 1 (còn được gọi là atomic consistency (tính nhất quán nguyên tử) 2, strong consistency, immediate consistency, hoặc external consistency 3). Định nghĩa chính xác của linearizability khá tinh tế, và chúng ta sẽ khám phá nó trong phần còn lại của phần này. Nhưng ý tưởng cơ bản là làm cho một hệ thống có vẻ như chỉ có một bản sao dữ liệu, và tất cả các thao tác trên đó là nguyên tử. Với sự đảm bảo này, mặc dù trong thực tế có thể có nhiều replica, ứng dụng không cần phải lo lắng về chúng.
Trong một hệ thống linearizable, ngay khi một client hoàn thành thành công một lần ghi, tất cả các client đọc từ cơ sở dữ liệu phải có thể thấy giá trị vừa được ghi. Duy trì ảo giác về một bản sao dữ liệu duy nhất có nghĩa là đảm bảo rằng giá trị được đọc là giá trị mới nhất, cập nhật nhất, và không đến từ bộ nhớ đệm hay replica cũ. Nói cách khác, linearizability là một recency guarantee (đảm bảo tính mới nhất). Để làm rõ ý tưởng này, hãy xem xét một ví dụ về hệ thống không phải là linearizable.
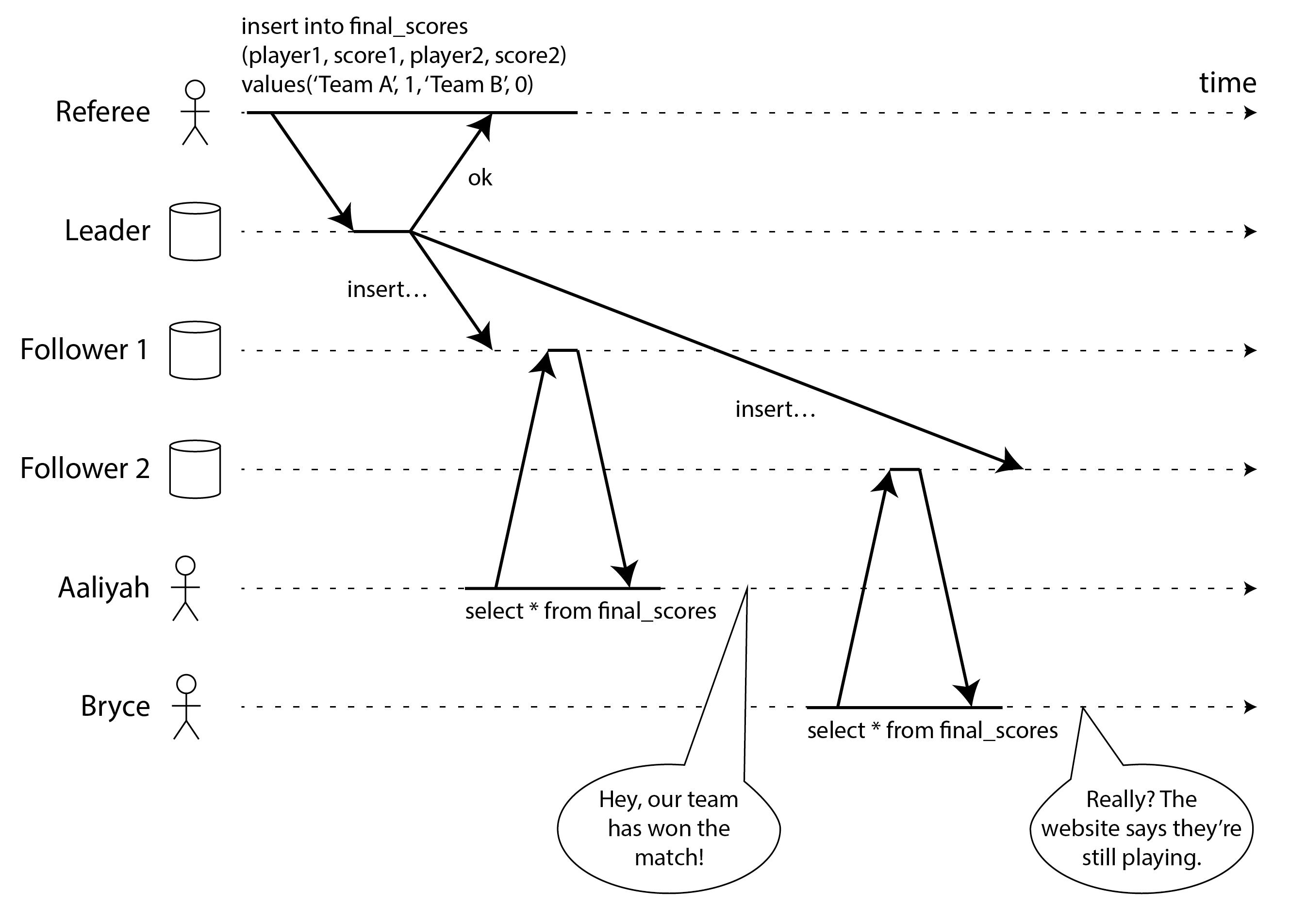
Hình 10-1 cho thấy một ví dụ về một trang web thể thao không phải linearizable 4. Aaliyah và Bryce đang ngồi trong cùng một căn phòng, cả hai đang kiểm tra điện thoại của họ để xem kết quả của một trận đấu mà đội bóng yêu thích của họ đang thi đấu. Ngay sau khi tỷ số cuối cùng được công bố, Aaliyah làm mới trang, thấy người thắng được thông báo, và hào hứng kể cho Bryce nghe về điều đó. Bryce không tin vào tai mình và nhấn reload trên điện thoại của mình, nhưng yêu cầu của anh ấy đến một replica cơ sở dữ liệu bị lag, do đó điện thoại của anh ấy hiển thị rằng trận đấu vẫn đang diễn ra.
Nếu Aaliyah và Bryce đã nhấn reload cùng một lúc, sẽ ít ngạc nhiên hơn nếu họ nhận được hai kết quả truy vấn khác nhau, vì họ sẽ không biết chính xác thời điểm các yêu cầu tương ứng của họ được máy chủ xử lý. Tuy nhiên, Bryce biết rằng anh ấy đã nhấn nút reload (khởi tạo truy vấn của mình) sau khi anh ấy nghe Aaliyah thốt lên tỷ số cuối cùng, và do đó anh ấy kỳ vọng kết quả truy vấn của mình ít nhất là mới bằng của Aaliyah. Thực tế là truy vấn của anh ấy trả về kết quả cũ là vi phạm linearizability.
What Makes a System Linearizable?
Để hiểu linearizability tốt hơn, hãy xem xét thêm một số ví dụ. Hình 10-2 cho thấy ba client đồng thời đọc và ghi cùng một đối tượng x trong một cơ sở dữ liệu linearizable. Trong lý thuyết hệ thống phân tán, x được gọi là register (thanh ghi), trong thực tế, nó có thể là một key trong một key-value store, một hàng trong một cơ sở dữ liệu quan hệ, hoặc một tài liệu trong một cơ sở dữ liệu tài liệu, chẳng hạn.
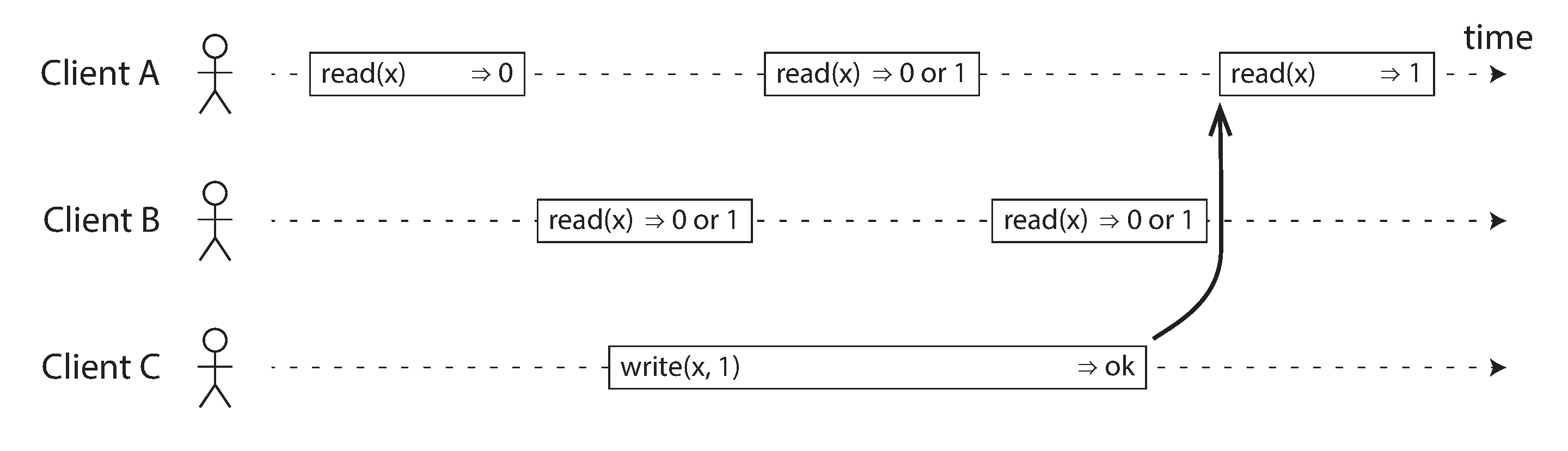
Để đơn giản, Hình 10-2 chỉ hiển thị các yêu cầu từ góc nhìn của các client, không phải nội bộ của cơ sở dữ liệu. Mỗi thanh là một yêu cầu được thực hiện bởi một client, trong đó phần đầu của thanh là thời điểm yêu cầu được gửi, và phần cuối của thanh là khi phản hồi được client nhận. Do độ trễ mạng biến đổi, một client không biết chính xác khi nào cơ sở dữ liệu xử lý yêu cầu của nó, nó chỉ biết rằng điều đó phải đã xảy ra vào một thời điểm nào đó giữa lúc client gửi yêu cầu và nhận phản hồi.
Trong ví dụ này, thanh ghi có hai loại thao tác:
- read(x) ⇒ v có nghĩa là client yêu cầu đọc giá trị của thanh ghi x, và cơ sở dữ liệu trả về giá trị v.
- write(x, v) ⇒ r có nghĩa là client yêu cầu đặt thanh ghi x thành giá trị v, và cơ sở dữ liệu trả về phản hồi r (có thể là ok hoặc error).
Trong Hình 10-2, giá trị của x ban đầu là 0, và client C thực hiện yêu cầu ghi để đặt nó thành 1. Trong khi điều này đang xảy ra, các client A và B liên tục poll cơ sở dữ liệu để đọc giá trị mới nhất. Những phản hồi có thể nào mà A và B có thể nhận được cho các yêu cầu đọc của họ?
- Thao tác đọc đầu tiên của client A hoàn thành trước khi lần ghi bắt đầu, vì vậy nó chắc chắn phải trả về giá trị cũ là 0.
- Lần đọc cuối cùng của client A bắt đầu sau khi lần ghi đã hoàn thành, vì vậy nó chắc chắn phải trả về giá trị mới là 1 nếu cơ sở dữ liệu là linearizable, bởi vì lần đọc phải đã được xử lý sau lần ghi.
- Bất kỳ thao tác đọc nào chồng lấp về mặt thời gian với thao tác ghi đều có thể trả về 0 hoặc 1, bởi vì chúng ta không biết liệu lần ghi có đã có hiệu lực hay không tại thời điểm thao tác đọc được xử lý. Những thao tác này đồng thời với lần ghi.
Tuy nhiên, đó vẫn chưa đủ để mô tả đầy đủ linearizability: nếu các lần đọc đồng thời với một lần ghi có thể trả về giá trị cũ hoặc mới, thì các reader có thể thấy giá trị thay đổi qua lại giữa giá trị cũ và mới nhiều lần trong khi một lần ghi đang diễn ra. Đó không phải là điều chúng ta kỳ vọng ở một hệ thống mô phỏng “một bản sao dữ liệu duy nhất”.
Để làm cho hệ thống linearizable, chúng ta cần thêm một ràng buộc nữa, được minh họa trong Hình 10-3.
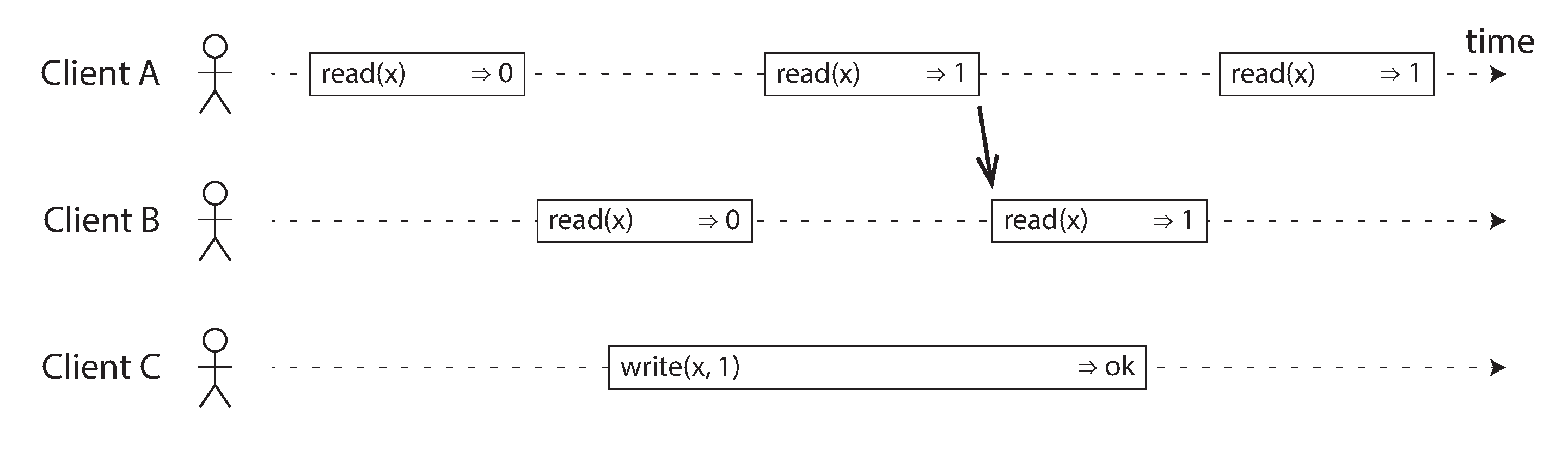
Trong một hệ thống linearizable, chúng ta tưởng tượng rằng phải có một thời điểm nào đó (giữa đầu và cuối của thao tác ghi) mà tại đó giá trị của x nguyên tử chuyển từ 0 sang 1. Vì vậy, nếu lần đọc của một client trả về giá trị mới là 1, tất cả các lần đọc tiếp theo cũng phải trả về giá trị mới, ngay cả khi thao tác ghi chưa hoàn thành.
Phụ thuộc về thời gian này được minh họa bằng một mũi tên trong Hình 10-3. Client A là người đầu tiên đọc giá trị mới, 1. Ngay sau khi lần đọc của A trả về, B bắt đầu một lần đọc mới. Vì lần đọc của B xảy ra hoàn toàn sau lần đọc của A, nó cũng phải trả về 1, ngay cả khi lần ghi của C vẫn đang diễn ra. (Đó là tình huống tương tự như với Aaliyah và Bryce trong Hình 10-1: sau khi Aaliyah đã đọc giá trị mới, Bryce cũng kỳ vọng đọc được giá trị mới.)
Chúng ta có thể tinh chỉnh thêm biểu đồ thời gian này để hình dung mỗi thao tác có hiệu lực nguyên tử tại một thời điểm nào đó 5, như trong ví dụ phức tạp hơn được hiển thị trong Hình 10-4. Trong ví dụ này, chúng ta thêm một loại thao tác thứ ba ngoài read và write:
- cas(x, vold, vnew) ⇒ r có nghĩa là client yêu cầu một thao tác compare-and-set (so sánh và đặt) nguyên tử (xem “Conditional writes (compare-and-set)”). Nếu giá trị hiện tại của thanh ghi x bằng vold, nó nên được đặt nguyên tử thành vnew. Nếu giá trị của x khác với vold, thì thao tác sẽ để thanh ghi không thay đổi và trả về lỗi. r là phản hồi của cơ sở dữ liệu (ok hoặc error).
Mỗi thao tác trong Hình 10-4 được đánh dấu bằng một đường thẳng đứng (bên trong thanh cho mỗi thao tác) tại thời điểm chúng ta nghĩ thao tác đó được thực thi. Những dấu đó được nối theo thứ tự tuần tự, và kết quả phải là một chuỗi hợp lệ của các lần đọc và ghi cho một thanh ghi (mỗi lần đọc phải trả về giá trị được đặt bởi lần ghi gần đây nhất).
Yêu cầu của linearizability là các đường nối các dấu thao tác luôn di chuyển tiến theo thời gian (từ trái sang phải), không bao giờ đi ngược lại. Yêu cầu này đảm bảo sự đảm bảo tính mới nhất mà chúng ta đã thảo luận trước đó: một khi một giá trị mới đã được ghi hoặc đọc, tất cả các lần đọc tiếp theo sẽ thấy giá trị đó cho đến khi nó bị ghi đè lại.
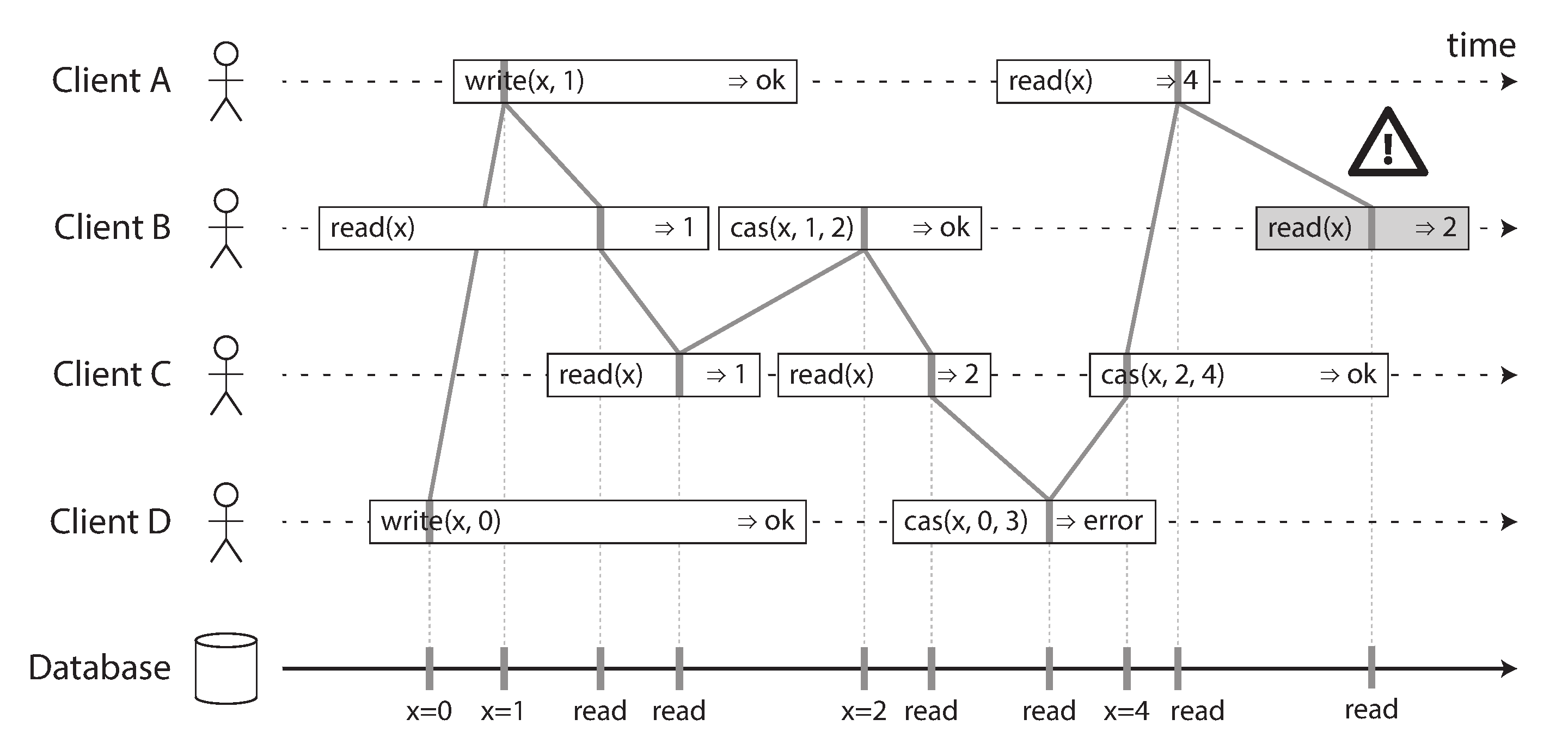
Có một số chi tiết thú vị cần chỉ ra trong Hình 10-4:
- Đầu tiên client B gửi yêu cầu đọc x, sau đó client D gửi yêu cầu đặt x thành 0, và sau đó client A gửi yêu cầu đặt x thành 1. Tuy nhiên, giá trị được trả về cho lần đọc của B là 1 (giá trị được ghi bởi A). Điều này ổn: có nghĩa là cơ sở dữ liệu đã xử lý lần ghi của D trước, sau đó lần ghi của A, và cuối cùng là lần đọc của B. Mặc dù đây không phải là thứ tự mà các yêu cầu được gửi, nhưng đó là thứ tự chấp nhận được, vì ba yêu cầu là đồng thời. Có lẽ yêu cầu đọc của B bị chậm một chút trong mạng, vì vậy nó chỉ đến cơ sở dữ liệu sau hai lần ghi.
- Lần đọc của client B trả về 1 trước khi client A nhận phản hồi từ cơ sở dữ liệu, cho biết rằng lần ghi giá trị 1 đã thành công. Điều này cũng ổn: nó chỉ có nghĩa là phản hồi ok từ cơ sở dữ liệu cho client A bị chậm một chút trong mạng.
- Mô hình này không giả định bất kỳ isolation giao dịch nào: một client khác có thể thay đổi một giá trị bất kỳ lúc nào. Ví dụ, C đầu tiên đọc 1 và sau đó đọc 2, vì giá trị đã bị thay đổi bởi B giữa hai lần đọc. Một thao tác compare-and-set (cas) nguyên tử có thể được sử dụng để kiểm tra xem giá trị có bị thay đổi đồng thời bởi một client khác hay không: các yêu cầu cas của B và C thành công, nhưng yêu cầu cas của D thất bại (khi cơ sở dữ liệu xử lý nó, giá trị của x không còn là 0 nữa).
- Lần đọc cuối cùng của client B (trong thanh được tô bóng) không phải là linearizable. Thao tác này đồng thời với lần ghi cas của C, cập nhật x từ 2 thành 4. Trong trường hợp không có các yêu cầu khác, thì ổn nếu lần đọc của B trả về 2. Tuy nhiên, client A đã đọc giá trị mới là 4 trước khi lần đọc của B bắt đầu, vì vậy B không được phép đọc một giá trị cũ hơn A. Một lần nữa, đó là tình huống tương tự như với Aaliyah và Bryce trong Hình 10-1.
Đó là trực giác đằng sau linearizability; định nghĩa hình thức 1 mô tả nó chính xác hơn. Có thể (mặc dù tốn kém về mặt tính toán) để kiểm tra xem hành vi của hệ thống có phải là linearizable hay không bằng cách ghi lại thời gian của tất cả các yêu cầu và phản hồi, và kiểm tra xem chúng có thể được sắp xếp thành một thứ tự tuần tự hợp lệ hay không 6 7.
Cũng như có nhiều mức isolation yếu cho các giao dịch ngoài serializability (xem “Weak Isolation Levels”), cũng có nhiều mô hình nhất quán yếu hơn cho các hệ thống được sao chép ngoài linearizability 8. Thực tế, các thuộc tính read-after-write, monotonic reads và consistent prefix reads mà chúng ta đã thấy trong “Problems with Replication Lag” là các ví dụ về các mô hình nhất quán yếu hơn đó. Linearizability đảm bảo tất cả các thuộc tính yếu hơn đó và nhiều hơn nữa. Trong chương này, chúng ta sẽ tập trung vào linearizability, đây là mô hình nhất quán mạnh nhất được sử dụng phổ biến.
LINEARIZABILITY VERSUS SERIALIZABILITY
Linearizability dễ bị nhầm lẫn với serializability (xem “Serializability”), vì cả hai từ đều có vẻ có nghĩa là “có thể được sắp xếp theo thứ tự tuần tự”. Tuy nhiên, chúng là những đảm bảo khá khác nhau, và điều quan trọng là phân biệt giữa chúng:
- Serializability (Khả năng tuần tự hóa)
- Serializability là một thuộc tính isolation của các giao dịch, trong đó mỗi giao dịch có thể đọc và ghi nhiều đối tượng (hàng, tài liệu, bản ghi). Nó đảm bảo rằng các giao dịch hoạt động giống như thể chúng đã thực thi theo một thứ tự tuần tự nào đó: tức là, như thể bạn đã thực hiện tất cả các thao tác của một giao dịch trước, sau đó tất cả các thao tác của một giao dịch khác, v.v., không xen kẽ chúng. Thứ tự tuần tự đó có thể khác với thứ tự mà các giao dịch thực sự chạy là điều chấp nhận được 9.
- Linearizability (Khả năng tuyến tính hóa)
- Linearizability là một đảm bảo về các lần đọc và ghi của một thanh ghi (một đối tượng riêng lẻ). Nó không gom các thao tác lại thành các giao dịch, vì vậy nó không ngăn ngừa các vấn đề như write skew liên quan đến nhiều đối tượng (xem “Write Skew and Phantoms”). Tuy nhiên, linearizability là một đảm bảo tính mới nhất: nó yêu cầu rằng nếu một thao tác kết thúc trước khi một thao tác khác bắt đầu, thì thao tác sau phải quan sát thấy một trạng thái ít nhất là mới như thao tác trước. Serializability không có yêu cầu đó: ví dụ, các lần đọc cũ được cho phép bởi serializability 10.
(Sequential consistency là một điều khác nữa 8, nhưng chúng ta sẽ không thảo luận ở đây.)
Một cơ sở dữ liệu có thể cung cấp cả serializability và linearizability, và sự kết hợp này được gọi là strict serializability (tuần tự hóa nghiêm ngặt) hoặc strong one-copy serializability (strong-1SR) 11 12. Các cơ sở dữ liệu đơn node thường là linearizable. Với các cơ sở dữ liệu phân tán sử dụng các phương pháp lạc quan như serializable snapshot isolation (xem “Serializable Snapshot Isolation (SSI)”), tình hình phức tạp hơn: ví dụ, CockroachDB cung cấp serializability và một số đảm bảo tính mới nhất về đọc, nhưng không phải strict serializability 13 vì điều này sẽ đòi hỏi sự phối hợp tốn kém giữa các giao dịch 14.
Cũng có thể kết hợp một mức isolation yếu hơn với linearizability, hoặc một mô hình nhất quán yếu hơn với serializability; thực tế, mô hình nhất quán và mức isolation có thể được chọn phần lớn độc lập với nhau 15 16.
Relying on Linearizability
Trong hoàn cảnh nào thì linearizability hữu ích? Xem tỷ số cuối cùng của một trận đấu thể thao có lẽ là một ví dụ phù phiếm: một kết quả bị lỗi thời vài giây khó có thể gây ra bất kỳ tổn hại thực sự nào trong tình huống này. Tuy nhiên, có một vài lĩnh vực mà linearizability là yêu cầu quan trọng để một hệ thống hoạt động đúng.
Locking and leader election
Một hệ thống sử dụng single-leader replication cần đảm bảo rằng thực sự chỉ có một leader, không phải nhiều (split brain, tức trạng thái não phân đôi). Một cách bầu chọn leader là sử dụng lease (thuê): mỗi node khởi động đều cố gắng giành lease, và node thành công sẽ trở thành leader 17. Dù cơ chế này được triển khai như thế nào, nó phải là linearizable: không thể có hai node khác nhau giành cùng một lease cùng một lúc.
Các dịch vụ phối hợp như Apache ZooKeeper 18 và etcd thường được sử dụng để triển khai các distributed lease (thuê phân tán) và leader election. Họ sử dụng các thuật toán consensus để triển khai các thao tác linearizable theo cách chịu lỗi (chúng ta sẽ thảo luận các thuật toán như vậy sau trong chương này). Vẫn còn nhiều chi tiết tinh tế trong việc triển khai các lease và leader election đúng cách (xem ví dụ vấn đề fencing trong “Distributed Locks and Leases”), và các thư viện như Apache Curator hỗ trợ bằng cách cung cấp các recipe cấp cao hơn trên ZooKeeper. Tuy nhiên, một dịch vụ lưu trữ linearizable là nền tảng cơ bản cho các tác vụ phối hợp này.
Note
Nói một cách chính xác, ZooKeeper cung cấp các lần ghi linearizable, nhưng các lần đọc có thể bị cũ, vì không có đảm bảo rằng chúng được phục vụ từ leader hiện tại 18. etcd từ phiên bản 3 cung cấp các lần đọc linearizable theo mặc định.
Distributed locking (khóa phân tán) cũng được sử dụng ở cấp độ chi tiết hơn nhiều trong một số cơ sở dữ liệu phân tán, chẳng hạn như Oracle Real Application Clusters (RAC) 19. RAC sử dụng một khóa trên mỗi trang đĩa, với nhiều node chia sẻ quyền truy cập vào cùng một hệ thống lưu trữ đĩa. Vì các khóa linearizable này nằm trên đường dẫn quan trọng của quá trình thực thi giao dịch, các triển khai RAC thường có một mạng cluster interconnect riêng dành cho giao tiếp giữa các node cơ sở dữ liệu.
Constraints and uniqueness guarantees
Các ràng buộc duy nhất (uniqueness constraints) rất phổ biến trong cơ sở dữ liệu: ví dụ, tên người dùng hoặc địa chỉ email phải xác định duy nhất một người dùng, và trong một dịch vụ lưu trữ tệp không thể có hai tệp có cùng đường dẫn và tên tệp. Nếu bạn muốn thực thi ràng buộc này khi dữ liệu được ghi (sao cho nếu hai người cố gắng tạo đồng thời một người dùng hoặc một tệp với cùng tên, một trong số họ sẽ nhận được lỗi), bạn cần linearizability.
Tình huống này thực sự tương tự như một khóa: khi người dùng đăng ký dịch vụ của bạn, bạn có thể nghĩ về việc họ giành một “khóa” trên tên người dùng đã chọn. Thao tác này cũng rất giống với một compare-and-set nguyên tử, đặt tên người dùng thành ID của người dùng đã đặt nó, với điều kiện là tên người dùng chưa được sử dụng.
Các vấn đề tương tự phát sinh nếu bạn muốn đảm bảo rằng số dư tài khoản ngân hàng không bao giờ âm, hoặc rằng bạn không bán nhiều hơn số mặt hàng bạn có trong kho, hoặc rằng hai người không đồng thời đặt cùng một ghế trên một chuyến bay hoặc trong rạp hát. Tất cả các ràng buộc này yêu cầu phải có một giá trị duy nhất cập nhật nhất (số dư tài khoản, mức tồn kho, trạng thái ghế ngồi) mà tất cả các node đều đồng ý.
Trong các ứng dụng thực tế, đôi khi chấp nhận được khi xử lý các ràng buộc như vậy một cách linh hoạt (ví dụ, nếu một chuyến bay bị đặt quá số ghế, bạn có thể chuyển khách hàng sang chuyến bay khác và đề nghị bồi thường cho sự bất tiện). Trong những trường hợp như vậy, linearizability có thể không cần thiết, và chúng ta sẽ thảo luận về các ràng buộc được diễn giải linh hoạt như vậy trong “Timeliness and Integrity”.
Tuy nhiên, một ràng buộc duy nhất cứng, chẳng hạn như ràng buộc bạn thường tìm thấy trong cơ sở dữ liệu quan hệ, yêu cầu linearizability. Các loại ràng buộc khác, chẳng hạn như ràng buộc foreign key hoặc thuộc tính, có thể được triển khai mà không cần linearizability 20.
Cross-channel timing dependencies
Chú ý một chi tiết trong Hình 10-1: nếu Aaliyah không thốt lên điểm số, Bryce sẽ không biết rằng kết quả truy vấn của mình bị cũ. Anh ấy chỉ làm mới trang một lần nữa sau vài giây, và cuối cùng sẽ thấy tỷ số cuối cùng. Vi phạm linearizability chỉ được nhận thấy vì có một kênh giao tiếp bổ sung trong hệ thống (giọng nói của Aaliyah đến tai của Bryce).
Các tình huống tương tự có thể phát sinh trong các hệ thống máy tính. Ví dụ, giả sử bạn có một trang web mà người dùng có thể tải lên video, và một tiến trình nền chuyển mã video thành chất lượng thấp hơn có thể được phát trực tuyến trên kết nối internet chậm. Kiến trúc và luồng dữ liệu của hệ thống này được minh họa trong Hình 10-5.
Bộ chuyển mã video cần được hướng dẫn rõ ràng để thực hiện công việc chuyển mã, và hướng dẫn này được gửi từ máy chủ web đến bộ chuyển mã qua một message queue (hàng đợi tin nhắn) (xem “Messaging Systems”). Máy chủ web không đặt toàn bộ video vào hàng đợi, vì hầu hết các message broker được thiết kế cho các tin nhắn nhỏ, và một video có thể có kích thước nhiều megabyte. Thay vào đó, video đầu tiên được ghi vào một dịch vụ lưu trữ tệp, và một khi lần ghi hoàn thành, hướng dẫn cho bộ chuyển mã được đặt vào hàng đợi.
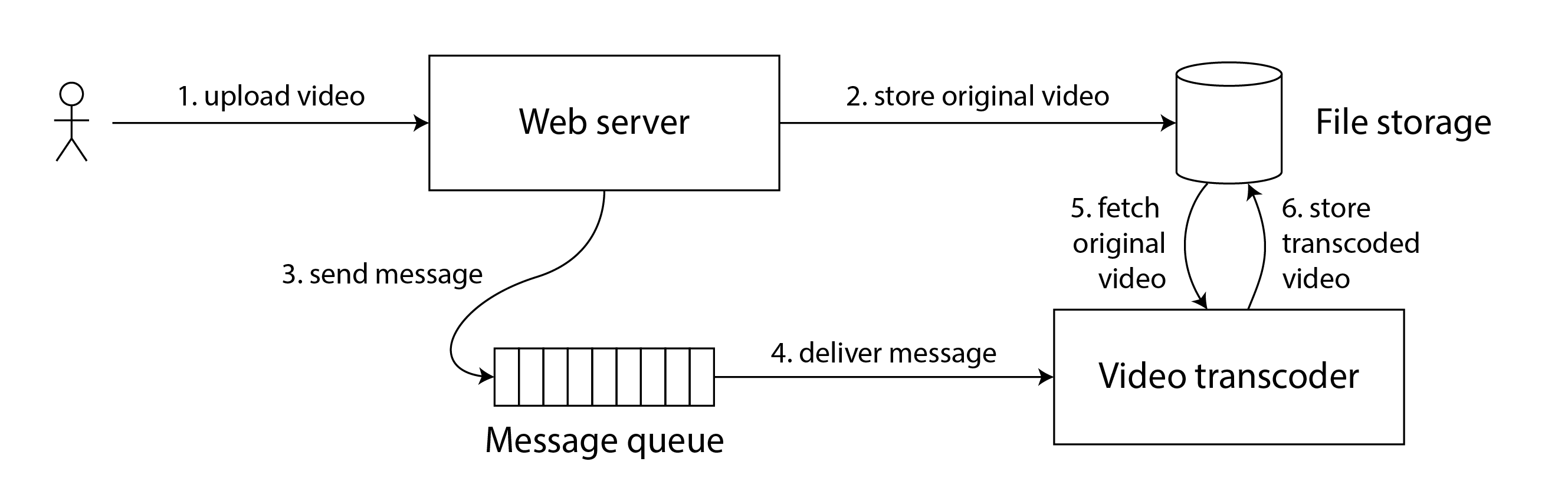
Nếu dịch vụ lưu trữ tệp là linearizable, thì hệ thống này hoạt động tốt. Nếu nó không phải là linearizable, có nguy cơ xảy ra race condition (điều kiện chạy đua): message queue (các bước 3 và 4 trong Hình 10-5) có thể nhanh hơn quá trình sao chép nội bộ bên trong dịch vụ lưu trữ. Trong trường hợp này, khi bộ chuyển mã tải về video gốc (bước 5), nó có thể thấy một phiên bản cũ của tệp, hoặc không có gì cả. Nếu nó xử lý một phiên bản cũ của video, các video gốc và đã chuyển mã trong lưu trữ tệp sẽ trở nên không nhất quán vĩnh viễn với nhau.
Vấn đề này phát sinh vì có hai kênh giao tiếp khác nhau giữa máy chủ web và bộ chuyển mã: lưu trữ tệp và message queue. Không có sự đảm bảo tính mới nhất của linearizability, race condition giữa hai kênh này là có thể. Tình huống này tương tự với Hình 10-1, trong đó cũng có một race condition giữa hai kênh giao tiếp: sao chép cơ sở dữ liệu và kênh âm thanh thực tế giữa miệng của Aaliyah và tai của Bryce.
Một race condition tương tự xảy ra nếu bạn có một ứng dụng di động có thể nhận push notification (thông báo đẩy), và ứng dụng tải một số dữ liệu từ máy chủ khi nhận được push notification. Nếu việc tải dữ liệu có thể đến một replica bị lag, có thể xảy ra là push notification đến nhanh chóng, nhưng lần tải tiếp theo không thấy dữ liệu mà push notification đề cập đến.
Linearizability không phải là cách duy nhất để tránh race condition này, nhưng nó là cách đơn giản nhất để hiểu. Nếu bạn kiểm soát kênh giao tiếp bổ sung (như trong trường hợp của message queue, nhưng không phải trong trường hợp của Aaliyah và Bryce), bạn có thể sử dụng các phương pháp thay thế tương tự như những gì chúng ta đã thảo luận trong “Reading Your Own Writes”, với chi phí là sự phức tạp bổ sung.
Implementing Linearizable Systems
Bây giờ chúng ta đã xem xét một vài ví dụ trong đó linearizability hữu ích, hãy suy nghĩ về cách chúng ta có thể triển khai một hệ thống cung cấp ngữ nghĩa linearizable.
Vì linearizability về cơ bản có nghĩa là “hành xử như thể chỉ có một bản sao dữ liệu, và tất cả các thao tác trên đó là nguyên tử”, câu trả lời đơn giản nhất sẽ là thực sự chỉ sử dụng một bản sao dữ liệu. Tuy nhiên, cách tiếp cận đó sẽ không thể chịu lỗi: nếu node giữ bản sao đó bị lỗi, dữ liệu sẽ bị mất, hoặc ít nhất là không thể truy cập được cho đến khi node được khởi động lại.
Hãy xem lại các phương pháp sao chép từ Chương 6, và so sánh xem chúng có thể được làm linearizable hay không:
- Single-leader replication (có thể linearizable)
- Trong một hệ thống với single-leader replication, leader có bản sao chính của dữ liệu được sử dụng để ghi, và các follower duy trì các bản sao dự phòng của dữ liệu trên các node khác. Miễn là bạn thực hiện tất cả các lần đọc và ghi trên leader, chúng có thể là linearizable. Tuy nhiên, điều này giả định rằng bạn biết chắc chắn ai là leader. Như đã thảo luận trong “Distributed Locks and Leases”, một node có thể nghĩ rằng nó là leader trong khi thực tế không phải, và nếu leader ảo tưởng tiếp tục phục vụ các yêu cầu, nó có thể vi phạm linearizability 21. Với asynchronous replication (sao chép bất đồng bộ), failover thậm chí có thể mất các lần ghi đã commit, vi phạm cả durability (độ bền) và linearizability.
Sharding một cơ sở dữ liệu single-leader, với một leader riêng biệt cho mỗi shard, không ảnh hưởng đến linearizability, vì nó chỉ là một đảm bảo về đối tượng đơn. Các giao dịch cross-shard lại là chuyện khác (xem “Distributed Transactions”).
- Consensus algorithms (có thể linearizable)
- Một số thuật toán consensus về cơ bản là single-leader replication với bầu chọn leader và failover tự động. Chúng được thiết kế cẩn thận để ngăn ngừa split brain, cho phép chúng triển khai lưu trữ linearizable một cách an toàn. ZooKeeper sử dụng thuật toán đồng thuận Zab 22 và etcd sử dụng Raft 23, ví dụ. Tuy nhiên, chỉ vì một hệ thống sử dụng consensus không đảm bảo rằng tất cả các thao tác trên đó là linearizable: nếu nó cho phép đọc trên một node mà không kiểm tra xem nó có còn là leader hay không, kết quả đọc có thể bị cũ nếu một leader mới vừa được bầu.
- Multi-leader replication (không phải linearizable)
- Các hệ thống với multi-leader replication thường không phải là linearizable, vì chúng xử lý đồng thời các lần ghi trên nhiều node và sao chép chúng đến các node khác một cách bất đồng bộ. Vì lý do này, chúng có thể tạo ra các lần ghi xung đột cần giải quyết (xem “Dealing with Conflicting Writes”).
- Leaderless replication (có thể không phải linearizable)
- Đối với các hệ thống với leaderless replication (kiểu Dynamo; xem “Leaderless Replication”), người ta đôi khi tuyên bố rằng bạn có thể đạt được “strong consistency” bằng cách yêu cầu quorum reads và writes (w + r > n). Tùy thuộc vào thuật toán cụ thể, và tùy thuộc vào cách bạn định nghĩa strong consistency, điều này không hoàn toàn đúng.
Các phương pháp giải quyết xung đột “last write wins” (lần ghi cuối cùng thắng) dựa trên đồng hồ thời gian thực (ví dụ trong Cassandra và ScyllaDB) gần như chắc chắn là nonlinearizable, bởi vì các dấu thời gian đồng hồ không thể được đảm bảo là nhất quán với thứ tự sự kiện thực tế do clock skew (độ lệch đồng hồ) (xem “Relying on Synchronized Clocks”). Ngay cả với quorum, hành vi nonlinearizable vẫn có thể xảy ra, như được minh chứng trong phần tiếp theo.
Linearizability and quorums
Theo trực giác, có vẻ như quorum reads và writes nên là linearizable trong mô hình kiểu Dynamo. Tuy nhiên, khi chúng ta có độ trễ mạng biến đổi, có thể xảy ra race condition, như được minh chứng trong Hình 10-6.
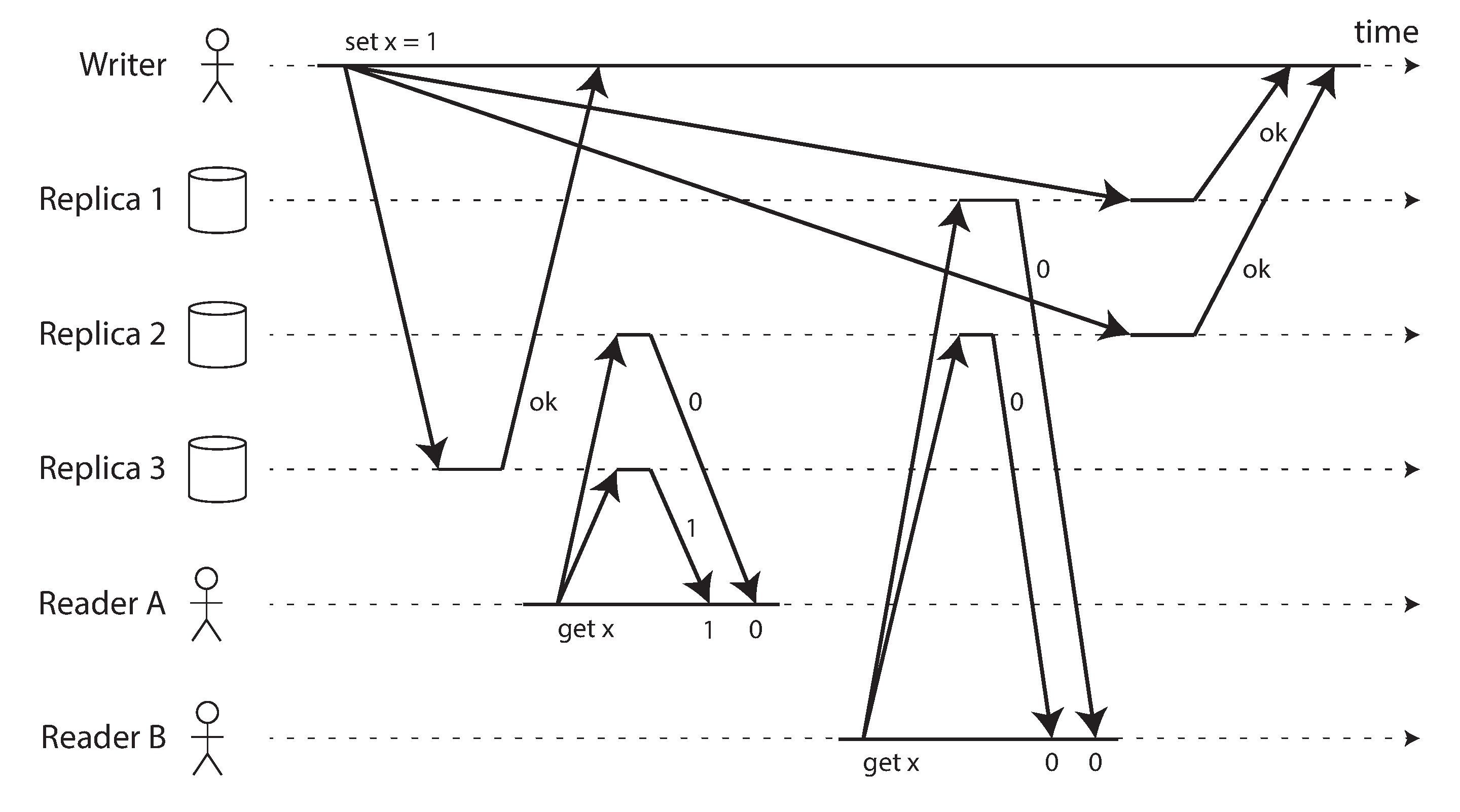
Trong Hình 10-6, giá trị ban đầu của x là 0, và một client ghi đang cập nhật x thành 1 bằng cách gửi lần ghi đến tất cả ba replica (n = 3, w = 3). Đồng thời, client A đọc từ một quorum gồm hai node (r = 2) và thấy giá trị mới là 1 trên một trong các node. Cũng đồng thời với lần ghi, client B đọc từ một quorum khác gồm hai node, và nhận lại giá trị cũ là 0 từ cả hai node.
Điều kiện quorum được đáp ứng (w + r > n), nhưng lần thực thi này vẫn không phải là linearizable: yêu cầu của B bắt đầu sau khi yêu cầu của A hoàn thành, nhưng B trả về giá trị cũ trong khi A trả về giá trị mới. (Đây một lần nữa là tình huống Aaliyah và Bryce từ Hình 10-1.)
Có thể làm cho các quorum kiểu Dynamo linearizable với chi phí hiệu suất giảm: một reader phải thực hiện read repair (sửa chữa đọc) (xem “Catching up on missed writes”) một cách đồng bộ, trước khi trả kết quả cho ứng dụng 24. Hơn nữa, trước khi ghi, một writer phải đọc trạng thái mới nhất của một quorum node để lấy dấu thời gian mới nhất của bất kỳ lần ghi nào trước đó, và đảm bảo rằng lần ghi mới có dấu thời gian lớn hơn 25 26. Tuy nhiên, Riak không thực hiện read repair đồng bộ do hình phạt về hiệu suất. Cassandra chờ read repair hoàn thành trên quorum reads 27, nhưng nó mất linearizability do sử dụng đồng hồ thời gian thực cho các dấu thời gian.
Hơn nữa, chỉ có các thao tác đọc và ghi linearizable mới có thể được triển khai theo cách này; một thao tác compare-and-set linearizable không thể, vì nó yêu cầu một thuật toán consensus 28.
Tóm lại, an toàn nhất là giả định rằng một hệ thống leaderless với sao chép kiểu Dynamo không cung cấp linearizability, ngay cả với quorum reads và writes.
The Cost of Linearizability
Vì một số phương pháp sao chép có thể cung cấp linearizability và các phương pháp khác thì không, thật thú vị khi khám phá ưu và nhược điểm của linearizability sâu hơn.
Chúng ta đã thảo luận về một số trường hợp sử dụng cho các phương pháp sao chép khác nhau trong Chương 6; ví dụ, chúng ta thấy rằng multi-leader replication thường là lựa chọn tốt cho sao chép đa vùng (xem “Geographically Distributed Operation”). Một ví dụ về triển khai như vậy được minh họa trong Hình 10-7.
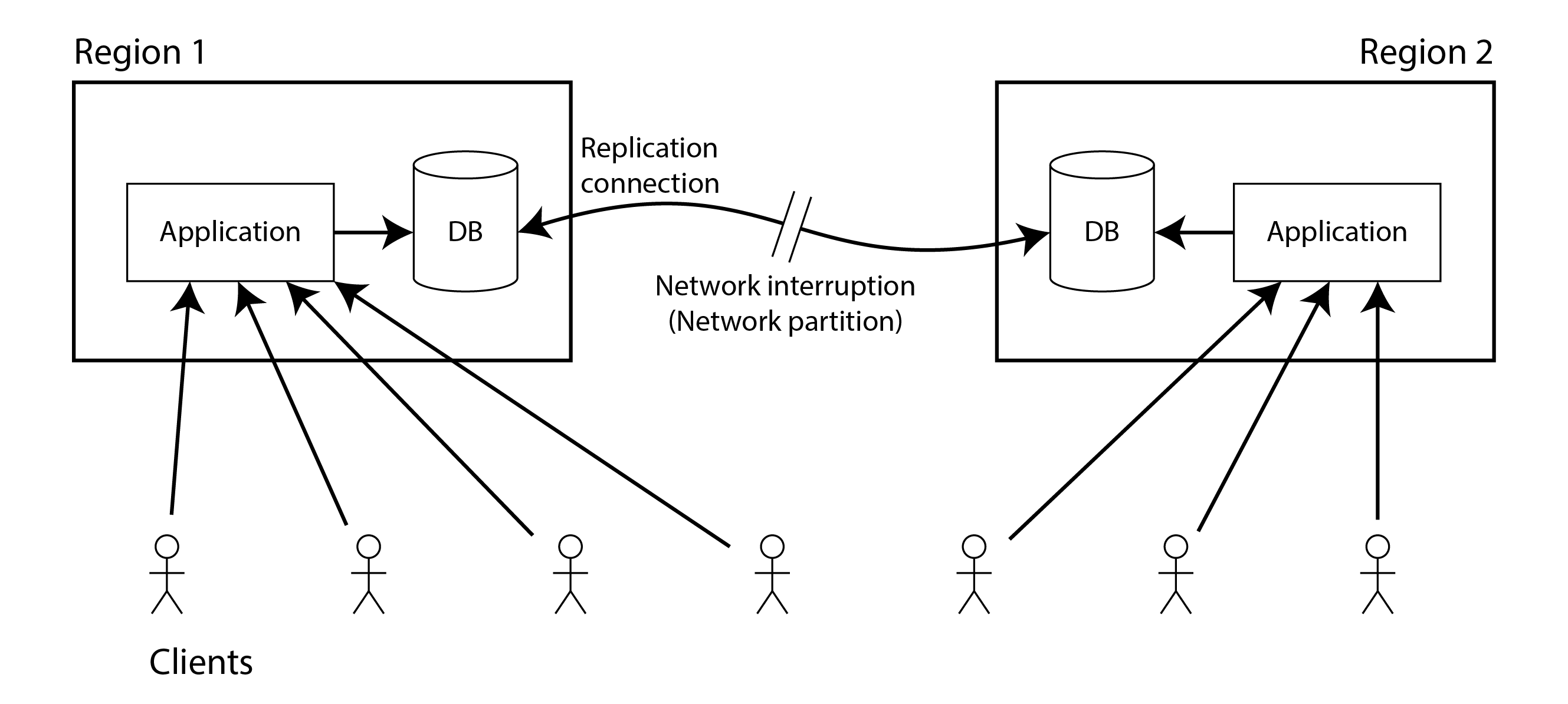
Hãy xem xét điều gì xảy ra nếu có sự gián đoạn mạng giữa hai vùng. Giả sử mạng trong mỗi vùng đang hoạt động, và các client có thể đến vùng cục bộ của họ, nhưng các vùng không thể kết nối với nhau. Điều này được gọi là network partition (phân vùng mạng).
Với một cơ sở dữ liệu multi-leader, mỗi vùng có thể tiếp tục hoạt động bình thường: vì các lần ghi từ một vùng được sao chép không đồng bộ sang vùng khác, các lần ghi chỉ đơn giản được xếp hàng và trao đổi khi kết nối mạng được khôi phục.
Mặt khác, nếu single-leader replication được sử dụng, thì leader phải ở trong một trong các vùng. Bất kỳ lần ghi nào và bất kỳ lần đọc linearizable nào đều phải được gửi đến leader, do đó, đối với bất kỳ client nào được kết nối với vùng follower, các yêu cầu đọc và ghi đó phải được gửi đồng bộ qua mạng đến vùng leader.
Nếu mạng giữa các vùng bị gián đoạn trong một cấu hình single-leader, các client được kết nối với vùng follower không thể liên hệ với leader, vì vậy họ không thể thực hiện bất kỳ lần ghi nào vào cơ sở dữ liệu, cũng như không thể đọc linearizable. Họ vẫn có thể đọc từ follower, nhưng chúng có thể bị cũ (nonlinearizable). Nếu ứng dụng yêu cầu linearizable reads và writes, sự gián đoạn mạng khiến ứng dụng trở nên không khả dụng trong các vùng không thể liên hệ với leader.
Nếu các client có thể kết nối trực tiếp với vùng leader, đây không phải là vấn đề, vì ứng dụng tiếp tục hoạt động bình thường ở đó. Nhưng các client chỉ có thể đến vùng follower sẽ bị ngừng hoạt động cho đến khi liên kết mạng được sửa chữa.
The CAP theorem
Vấn đề này không chỉ là hậu quả của single-leader và multi-leader replication: bất kỳ cơ sở dữ liệu linearizable nào cũng có vấn đề này, bất kể nó được triển khai như thế nào. Vấn đề cũng không đặc thù cho các triển khai đa vùng, mà có thể xảy ra trên bất kỳ mạng không đáng tin cậy nào, ngay cả trong một vùng. Sự đánh đổi như sau:
- Nếu ứng dụng của bạn yêu cầu linearizability, và một số replica bị ngắt kết nối khỏi các replica khác do sự cố mạng, thì một số replica không thể xử lý các yêu cầu trong khi bị ngắt kết nối: chúng phải chờ cho đến khi sự cố mạng được khắc phục, hoặc trả về lỗi (dù thế nào, chúng trở thành không khả dụng). Lựa chọn này đôi khi được gọi là CP (nhất quán khi có phân vùng mạng).
- Nếu ứng dụng của bạn không yêu cầu linearizability, thì nó có thể được viết theo cách mà mỗi replica có thể xử lý các yêu cầu một cách độc lập, ngay cả khi nó bị ngắt kết nối khỏi các replica khác (ví dụ: multi-leader). Trong trường hợp này, ứng dụng có thể vẫn khả dụng khi đối mặt với sự cố mạng, nhưng hành vi của nó không phải là linearizable. Lựa chọn này được gọi là AP (khả dụng khi có phân vùng mạng).
Do đó, các ứng dụng không yêu cầu linearizability có thể chịu đựng các sự cố mạng tốt hơn. Cái nhìn này được biết đến rộng rãi với tên CAP theorem (định lý CAP) 29 30 31 32, được đặt tên bởi Eric Brewer vào năm 2000, mặc dù sự đánh đổi đã được biết đến với các nhà thiết kế cơ sở dữ liệu phân tán từ những năm 1970 33 34 35.
CAP ban đầu được đề xuất như một quy tắc ngón tay cái, không có định nghĩa chính xác, với mục tiêu bắt đầu một cuộc thảo luận về các đánh đổi trong cơ sở dữ liệu. Vào thời điểm đó, nhiều cơ sở dữ liệu phân tán tập trung vào việc cung cấp ngữ nghĩa linearizable trên một cụm máy với lưu trữ dùng chung 19, và CAP khuyến khích các kỹ sư cơ sở dữ liệu khám phá không gian thiết kế rộng hơn của các hệ thống phân tán không dùng chung, phù hợp hơn để triển khai các dịch vụ web quy mô lớn 36. CAP xứng đáng được ghi nhận cho sự thay đổi văn hóa này, nó đã giúp kích hoạt phong trào NoSQL, một làn sóng công nghệ cơ sở dữ liệu mới vào giữa những năm 2000.
THE UNHELPFUL CAP THEOREM
CAP đôi khi được trình bày là Consistency, Availability, Partition tolerance: chọn 2 trong 3. Thật không may, đặt vấn đề theo cách này là gây hiểu lầm 32 vì phân vùng mạng là một loại lỗi, vì vậy chúng không phải là điều bạn có thể chọn: chúng sẽ xảy ra dù bạn muốn hay không.
Vào những lúc mạng hoạt động đúng, một hệ thống có thể cung cấp cả nhất quán (linearizability) và toàn bộ khả năng sẵn sàng. Khi xảy ra lỗi mạng, bạn phải chọn giữa linearizability hoặc toàn bộ khả năng sẵn sàng. Vì vậy, cách diễn đạt tốt hơn cho CAP sẽ là Consistent hoặc Available khi bị Partitioned 37. Một mạng đáng tin cậy hơn cần phải thực hiện sự lựa chọn này ít thường xuyên hơn, nhưng đến một lúc nào đó sự lựa chọn là không thể tránh khỏi.
Sơ đồ phân loại CP/AP có một số hạn chế khác 4. Consistency (tính nhất quán) được hình thức hóa là linearizability (định lý không nói gì về các mô hình nhất quán yếu hơn), và sự hình thức hóa của availability (tính khả dụng) 30 không khớp với ý nghĩa thông thường của thuật ngữ 38. Nhiều hệ thống có tính khả dụng cao (chịu lỗi) thực sự không đáp ứng định nghĩa khác thường của CAP về tính khả dụng. Hơn nữa, một số nhà thiết kế hệ thống chọn (với lý do chính đáng) không cung cấp cả linearizability lẫn hình thức khả dụng mà định lý CAP giả định, vì vậy những hệ thống đó không phải CP cũng không phải AP 39 40.
Tóm lại, có rất nhiều hiểu lầm và nhầm lẫn xung quanh CAP, và nó không giúp chúng ta hiểu hệ thống tốt hơn, vì vậy tốt nhất nên tránh CAP.
Định lý CAP như được định nghĩa hình thức 30 có phạm vi rất hẹp: nó chỉ xem xét một mô hình nhất quán (cụ thể là linearizability) và một loại lỗi (phân vùng mạng, theo dữ liệu từ Google là nguyên nhân của dưới 8% sự cố 41). Nó không nói gì về độ trễ mạng, các node chết, hoặc các đánh đổi khác. Vì vậy, mặc dù CAP có tầm ảnh hưởng lịch sử, nó có ít giá trị thực tiễn cho việc thiết kế hệ thống 4 38.
Đã có những nỗ lực để tổng quát hóa CAP. Ví dụ, nguyên tắc PACELC quan sát rằng các nhà thiết kế hệ thống cũng có thể chọn làm yếu tính nhất quán vào những lúc mạng hoạt động tốt để giảm độ trễ 39 40 42. Vì vậy, trong khi có phân vùng mạng (P), chúng ta cần chọn giữa tính khả dụng (A) và tính nhất quán (C); nếu không (E), khi không có phân vùng, chúng ta có thể chọn giữa độ trễ thấp (L) và tính nhất quán (C). Tuy nhiên, định nghĩa này thừa hưởng một số vấn đề với CAP, chẳng hạn như các định nghĩa phản trực giác về tính nhất quán và tính khả dụng.
Có nhiều kết quả không thể hơn thú vị trong các hệ thống phân tán 43, và CAP hiện đã được thay thế bởi các kết quả chính xác hơn 44 45, vì vậy nó chủ yếu có giá trị lịch sử ngày nay.
Linearizability and network delays
Mặc dù linearizability là một đảm bảo hữu ích, nhưng đáng ngạc nhiên là rất ít hệ thống thực sự là linearizable trong thực tế. Ví dụ, ngay cả RAM trên CPU đa lõi hiện đại cũng không phải linearizable 46: nếu một luồng chạy trên một lõi CPU ghi vào một địa chỉ bộ nhớ, và một luồng trên một lõi CPU khác đọc cùng địa chỉ ngay sau đó, không được đảm bảo là sẽ đọc được giá trị do luồng đầu tiên ghi (trừ khi một memory barrier (rào cản bộ nhớ) hoặc fence 47 được sử dụng).
Lý do cho hành vi này là mỗi lõi CPU có bộ nhớ đệm và bộ đệm ghi riêng của nó. Quyền truy cập bộ nhớ đầu tiên đi vào bộ nhớ đệm theo mặc định, và bất kỳ thay đổi nào được ghi ra bộ nhớ chính một cách bất đồng bộ. Vì việc truy cập dữ liệu trong bộ nhớ đệm nhanh hơn nhiều so với đi vào bộ nhớ chính 48, tính năng này rất quan trọng để có hiệu suất tốt trên các CPU hiện đại. Tuy nhiên, hiện có nhiều bản sao của dữ liệu (một trong bộ nhớ chính, và có thể nhiều hơn trong các bộ nhớ đệm khác nhau), và các bản sao này được cập nhật không đồng bộ, vì vậy linearizability bị mất.
Tại sao phải thực hiện sự đánh đổi này? Sẽ không hợp lý nếu sử dụng định lý CAP để biện minh cho mô hình nhất quán bộ nhớ đa lõi: trong một máy tính, chúng ta thường giả định giao tiếp đáng tin cậy, và chúng ta không kỳ vọng một lõi CPU có thể tiếp tục hoạt động bình thường nếu nó bị ngắt kết nối khỏi phần còn lại của máy tính. Lý do để từ bỏ linearizability là hiệu suất, không phải khả năng chịu lỗi 39.
Điều tương tự cũng đúng với nhiều cơ sở dữ liệu phân tán chọn không cung cấp các đảm bảo linearizable: họ làm như vậy chủ yếu để tăng hiệu suất, không phải vì khả năng chịu lỗi 42. Linearizability là chậm, và điều này đúng mọi lúc, không chỉ trong sự cố mạng.
Chúng ta có thể tìm một triển khai hiệu quả hơn của lưu trữ linearizable không? Câu trả lời có vẻ là không: Attiya và Welch 49 chứng minh rằng nếu bạn muốn linearizability, thời gian phản hồi của các yêu cầu đọc và ghi ít nhất tỷ lệ thuận với sự không chắc chắn của độ trễ trong mạng. Trong một mạng với độ trễ biến đổi cao, như hầu hết các mạng máy tính (xem “Timeouts and Unbounded Delays”), thời gian phản hồi của các lần đọc và ghi linearizable chắc chắn sẽ cao. Một thuật toán nhanh hơn cho linearizability không tồn tại, nhưng các mô hình nhất quán yếu hơn có thể nhanh hơn nhiều, vì vậy sự đánh đổi này quan trọng đối với các hệ thống nhạy cảm với độ trễ. Trong “Timeliness and Integrity” chúng ta sẽ thảo luận về một số phương pháp để tránh linearizability mà không hy sinh tính đúng đắn.
ID Generators and Logical Clocks
Trong nhiều ứng dụng, bạn cần gán một ID duy nhất nào đó cho các bản ghi cơ sở dữ liệu khi chúng được tạo, điều này cung cấp cho bạn một khóa chính (primary key) để bạn có thể tham chiếu đến những bản ghi đó. Trong các cơ sở dữ liệu đơn node, thường sử dụng một số nguyên tự tăng, có lợi thế là có thể được lưu trữ chỉ trong 64 bit (hoặc thậm chí 32 bit nếu bạn chắc chắn rằng bạn sẽ không bao giờ có hơn 4 tỷ bản ghi, nhưng điều đó có rủi ro).
Một ưu điểm khác của các ID tự tăng như vậy là thứ tự của các ID cho bạn biết thứ tự mà các bản ghi được tạo. Ví dụ, Hình 10-8 cho thấy một ứng dụng trò chuyện gán ID tự tăng cho các tin nhắn chat khi chúng được đăng. Sau đó bạn có thể hiển thị các tin nhắn theo thứ tự ID tăng dần, và các chủ đề trò chuyện kết quả sẽ có nghĩa: Aaliyah đăng một câu hỏi được gán ID 1, và câu trả lời của Bryce cho câu hỏi đó được gán một ID lớn hơn, cụ thể là 3.
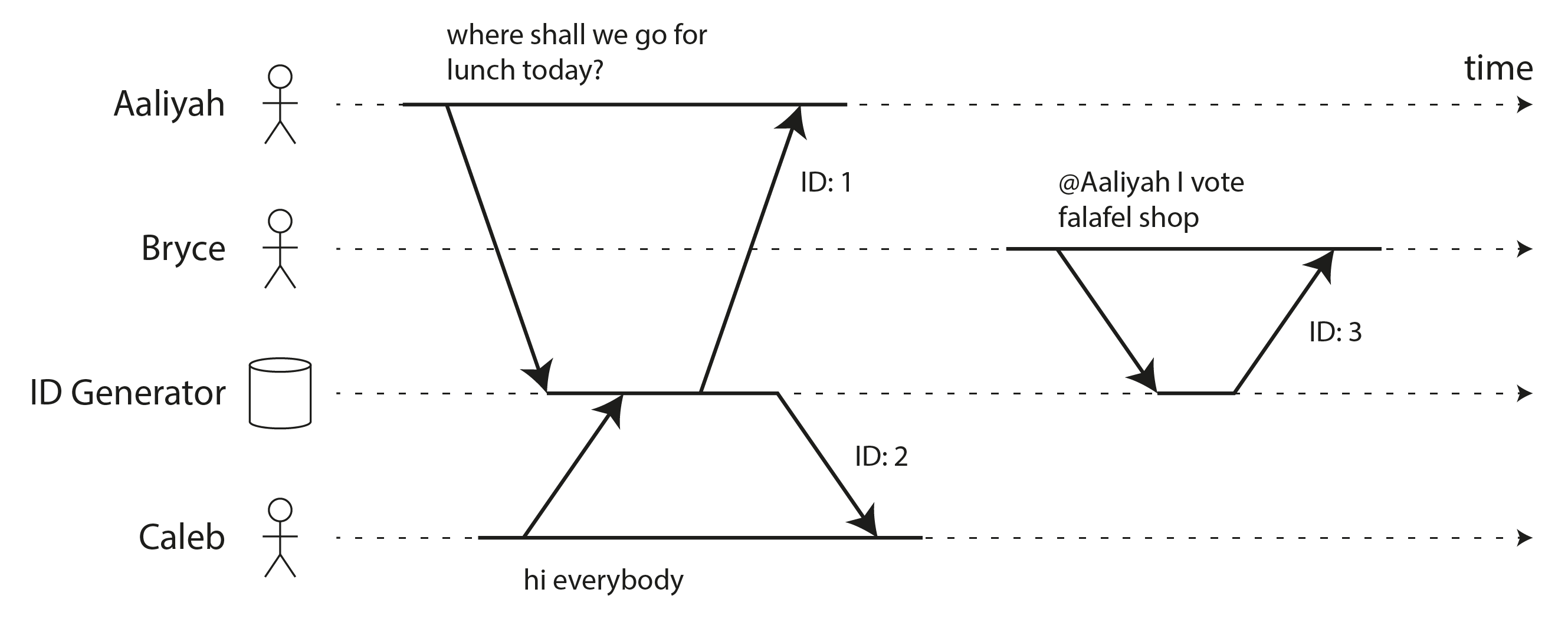
Bộ tạo ID đơn node này là một ví dụ khác về hệ thống linearizable. Mỗi yêu cầu để lấy ID là một thao tác tăng nguyên tử một bộ đếm và trả về giá trị bộ đếm cũ (một thao tác fetch-and-add); linearizability đảm bảo rằng nếu việc đăng tin nhắn của Aaliyah hoàn thành trước khi việc đăng của Bryce bắt đầu, thì ID của Bryce phải lớn hơn của Aaliyah. Các tin nhắn của Aaliyah và Caleb trong Hình 10-8 là đồng thời, vì vậy linearizability không chỉ định cách sắp xếp ID của họ, miễn là chúng là duy nhất.
Một bộ tạo ID đơn node trong bộ nhớ dễ triển khai: bạn có thể sử dụng lệnh tăng nguyên tử được cung cấp bởi CPU của bạn, cho phép nhiều luồng an toàn tăng cùng một bộ đếm. Hơi tốn công hơn để làm cho bộ đếm bền vững, sao cho node có thể gặp sự cố và khởi động lại mà không đặt lại giá trị bộ đếm, điều này sẽ dẫn đến các ID trùng lặp. Nhưng các vấn đề thực sự là:
- Một bộ tạo ID đơn node không chịu lỗi vì node đó là điểm thất bại duy nhất.
- Nó chậm nếu bạn muốn tạo một bản ghi ở một vùng khác, vì bạn có thể phải thực hiện một round-trip đến phía kia của hành tinh chỉ để lấy một ID.
- Node duy nhất đó có thể trở thành nút thắt cổ chai nếu bạn có throughput ghi cao.
Có nhiều tùy chọn thay thế cho bộ tạo ID mà bạn có thể xem xét:
- Sharded ID assignment (Phân bổ ID theo shard)
- Bạn có thể có nhiều node phân bổ ID, ví dụ, một node tạo chỉ số chẵn và một node tạo chỉ số lẻ. Nói chung, bạn có thể dành một số bit trong ID để chứa số shard. Những ID đó vẫn gọn, nhưng bạn mất thuộc tính thứ tự: ví dụ, nếu bạn có các tin nhắn chat với ID 16 và 17, bạn không biết liệu tin nhắn 16 có thực sự được gửi trước hay không, vì các ID được phân bổ bởi các node khác nhau, và một node có thể đã vượt trước node kia.
- Preallocated blocks of IDs (Khối ID được phân bổ trước)
- Thay vì yêu cầu từng ID riêng lẻ từ bộ tạo ID đơn node, nó có thể phân phát các khối ID. Ví dụ, node A có thể nhận khối ID từ 1 đến 1.000, và node B có thể nhận khối từ 1.001 đến 2.000. Sau đó mỗi node có thể độc lập phân phát các ID từ khối của mình, và yêu cầu một khối mới từ bộ tạo ID đơn node khi nguồn cung số thứ tự của nó bắt đầu cạn. Tuy nhiên, sơ đồ này cũng không đảm bảo thứ tự đúng: có thể xảy ra là một tin nhắn được gán ID trong phạm vi từ 1.001 đến 2.000, và một tin nhắn sau được gán ID trong phạm vi từ 1 đến 1.000 nếu ID được phân bổ bởi một node khác.
- Random UUIDs (UUID ngẫu nhiên)
- Bạn có thể sử dụng universally unique identifiers (UUID, định danh duy nhất toàn cầu), còn được gọi là globally unique identifiers (GUID). Chúng có lợi thế lớn là có thể được tạo cục bộ trên bất kỳ node nào mà không cần giao tiếp, nhưng chúng yêu cầu nhiều không gian hơn (128 bit). Có nhiều phiên bản khác nhau của UUID; đơn giản nhất là phiên bản 4, về cơ bản là một số ngẫu nhiên dài đến mức rất khó có khả năng hai node sẽ chọn cùng một số. Thật không may, thứ tự của các ID như vậy cũng ngẫu nhiên, vì vậy việc so sánh hai ID không cho bạn biết ID nào mới hơn.
- Wall-clock timestamp made unique (Dấu thời gian đồng hồ thực được làm duy nhất)
- Nếu đồng hồ thời gian thực của các node của bạn được giữ xấp xỉ đúng bằng NTP, bạn có thể tạo ID bằng cách đặt dấu thời gian từ đồng hồ đó vào các bit quan trọng nhất, và điền các bit còn lại với thông tin bổ sung đảm bảo ID là duy nhất ngay cả khi dấu thời gian không phải, ví dụ, một số shard và một số thứ tự tăng dần theo shard, hoặc một giá trị ngẫu nhiên dài. Cách tiếp cận này được sử dụng trong Version 7 UUID 50, Twitter’s Snowflake 51, ULID 52, Hazelcast’s Flake ID generator, MongoDB ObjectID, và nhiều sơ đồ tương tự 50. Bạn có thể triển khai các bộ tạo ID này trong mã ứng dụng hoặc trong cơ sở dữ liệu 53.
Tất cả các sơ đồ này tạo ra các ID là duy nhất (ít nhất với xác suất đủ cao để va chạm là cực kỳ hiếm), nhưng chúng có đảm bảo thứ tự yếu hơn nhiều cho các ID so với sơ đồ tự tăng đơn node.
Như đã thảo luận trong “Timestamps for ordering events”, các dấu thời gian đồng hồ thực chỉ có thể cung cấp thứ tự xấp xỉ: nếu một lần ghi sớm hơn nhận được dấu thời gian từ một đồng hồ hơi nhanh, và dấu thời gian của lần ghi sau đến từ một đồng hồ hơi chậm, thứ tự dấu thời gian có thể không nhất quán với thứ tự mà các sự kiện thực sự xảy ra. Với các bước nhảy đồng hồ do sử dụng đồng hồ không đơn điệu, ngay cả các dấu thời gian được tạo bởi một node duy nhất cũng có thể được sắp xếp không chính xác. Do đó, các bộ tạo ID dựa trên thời gian đồng hồ thực khó có thể là linearizable.
Bạn có thể giảm các mâu thuẫn thứ tự như vậy bằng cách dựa vào đồng bộ hóa đồng hồ độ chính xác cao, sử dụng đồng hồ nguyên tử hoặc máy thu GPS. Nhưng sẽ thật tốt nếu có thể tạo các ID duy nhất và có thứ tự đúng mà không phụ thuộc vào phần cứng đặc biệt. Đó là những gì logical clocks (đồng hồ logic) hướng đến.
Logical Clocks
Trong “Unreliable Clocks” chúng ta đã thảo luận về đồng hồ thời gian thực và đồng hồ đơn điệu. Cả hai đều là physical clocks (đồng hồ vật lý): chúng đo sự trôi qua của các giây (hoặc mili giây, micro giây, v.v.).
Trong các hệ thống phân tán, người ta thường cũng sử dụng một loại đồng hồ khác, được gọi là logical clock (đồng hồ logic). Trong khi đồng hồ vật lý là thiết bị phần cứng đếm các giây đã trôi qua, đồng hồ logic là một thuật toán đếm các sự kiện đã xảy ra. Do đó, một dấu thời gian từ đồng hồ logic không cho bạn biết bây giờ là mấy giờ, nhưng bạn có thể so sánh hai dấu thời gian từ đồng hồ logic để biết cái nào sớm hơn và cái nào muộn hơn.
Các yêu cầu đối với đồng hồ logic thường là:
- rằng các dấu thời gian của nó gọn nhẹ (vài byte về kích thước) và duy nhất;
- rằng bạn có thể so sánh bất kỳ hai dấu thời gian nào (tức là chúng được sắp xếp hoàn toàn); và
- rằng thứ tự của các dấu thời gian nhất quán với tính nhân quả: nếu thao tác A xảy ra trước B, thì dấu thời gian của A nhỏ hơn dấu thời gian của B. (Chúng ta đã thảo luận về tính nhân quả trước đó trong “The “happens-before” relation and concurrency”.)
Một bộ tạo ID đơn node đáp ứng các yêu cầu này, nhưng các bộ tạo ID phân tán mà chúng ta vừa thảo luận không đáp ứng yêu cầu thứ tự nhân quả.
Lamport timestamps
May mắn thay, có một phương pháp đơn giản để tạo các dấu thời gian logic nhất quán với tính nhân quả, và bạn có thể sử dụng làm bộ tạo ID phân tán. Nó được gọi là Lamport clock (đồng hồ Lamport), được đề xuất vào năm 1978 bởi Leslie Lamport 54, trong một trong những bài báo được trích dẫn nhiều nhất trong lĩnh vực các hệ thống phân tán.
Hình 10-9 cho thấy cách đồng hồ Lamport hoạt động trong ví dụ trò chuyện của Hình 10-8. Mỗi node có một định danh duy nhất, trong Hình 10-9 là tên “Aaliyah”, “Bryce”, hoặc “Caleb”, nhưng trong thực tế có thể là một UUID ngẫu nhiên hay tương tự. Hơn nữa, mỗi node giữ một bộ đếm số lượng thao tác nó đã xử lý. Dấu thời gian Lamport sau đó chỉ đơn giản là một cặp (bộ đếm, ID node). Hai node đôi khi có thể có cùng giá trị bộ đếm, nhưng bằng cách bao gồm ID node trong dấu thời gian, mỗi dấu thời gian được làm duy nhất.
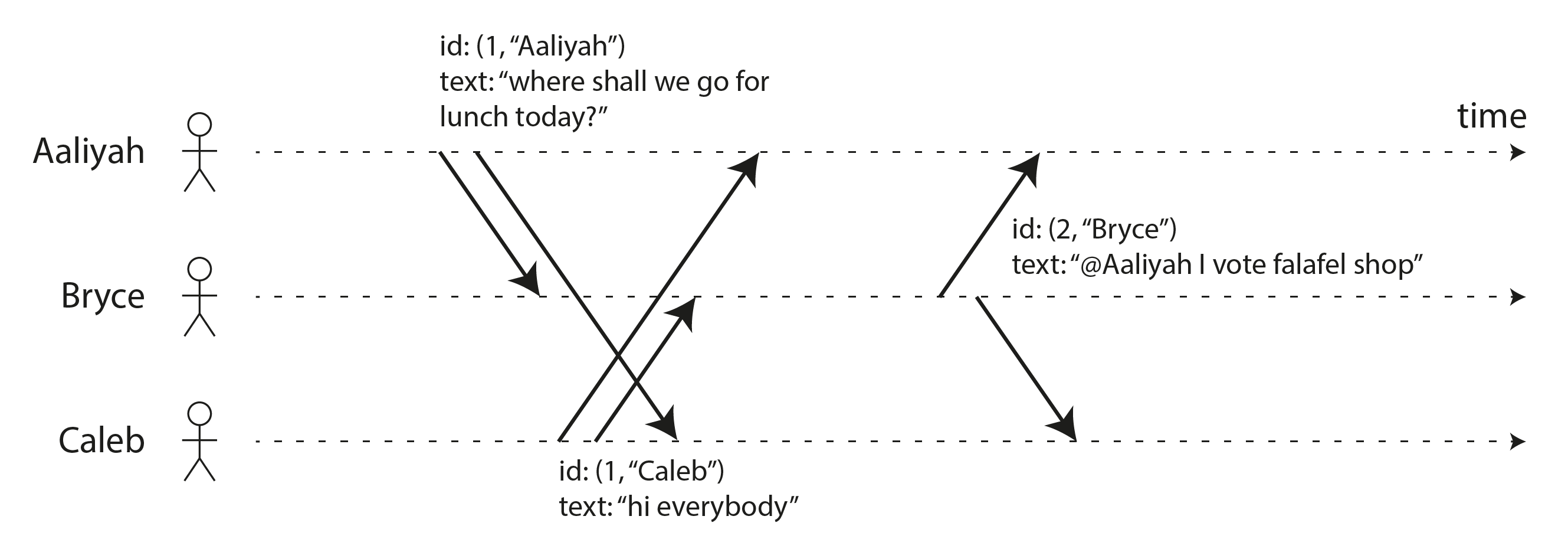
Mỗi khi một node tạo ra một dấu thời gian, nó tăng giá trị bộ đếm của mình và sử dụng giá trị mới. Hơn nữa, mỗi khi một node thấy một dấu thời gian từ một node khác, nếu giá trị bộ đếm trong dấu thời gian đó lớn hơn giá trị bộ đếm cục bộ của nó, nó tăng bộ đếm cục bộ của mình lên để khớp với giá trị trong dấu thời gian.
Trong Hình 10-9, Aaliyah chưa thấy tin nhắn của Caleb khi đăng tin nhắn của mình, và ngược lại. Giả sử cả hai người dùng bắt đầu với giá trị bộ đếm ban đầu là 0, cả hai do đó tăng bộ đếm cục bộ của mình và đính kèm giá trị bộ đếm mới là 1 vào tin nhắn của họ. Khi Bryce nhận được những tin nhắn đó, anh ấy tăng giá trị bộ đếm cục bộ của mình lên 1. Cuối cùng, Bryce gửi một phản hồi cho tin nhắn của Aaliyah, mà anh ấy tăng bộ đếm cục bộ và đính kèm giá trị mới là 2 vào tin nhắn.
Để so sánh hai dấu thời gian Lamport, chúng ta đầu tiên so sánh giá trị bộ đếm của chúng: ví dụ, (2, “Bryce”) lớn hơn (1, “Aaliyah”) và cũng lớn hơn (1, “Caleb”). Nếu hai dấu thời gian có cùng bộ đếm, chúng ta so sánh ID node của chúng thay thế, sử dụng so sánh chuỗi lexicographic thông thường. Do đó, thứ tự dấu thời gian trong ví dụ này là (1, “Aaliyah”) < (1, “Caleb”) < (2, “Bryce”).
Hybrid logical clocks
Dấu thời gian Lamport rất tốt trong việc nắm bắt thứ tự mà mọi thứ xảy ra, nhưng chúng có một số hạn chế:
- Vì chúng không có mối quan hệ trực tiếp với thời gian vật lý, bạn không thể sử dụng chúng để tìm, chẳng hạn, tất cả các tin nhắn được đăng vào một ngày cụ thể, bạn sẽ cần lưu trữ thời gian vật lý riêng biệt.
- Nếu hai node không bao giờ giao tiếp, việc tăng bộ đếm của một node sẽ không bao giờ được phản ánh trong bộ đếm của node kia. Kết quả là, có thể xảy ra là các sự kiện được tạo vào khoảng cùng một thời điểm trên các node khác nhau có giá trị bộ đếm hoàn toàn khác nhau.
Một hybrid logical clock (đồng hồ logic lai) kết hợp các ưu điểm của đồng hồ thời gian thực vật lý với các đảm bảo thứ tự của đồng hồ Lamport 55. Giống như đồng hồ vật lý, nó đếm các giây hoặc micro giây. Giống như đồng hồ Lamport, khi một node thấy một dấu thời gian từ một node khác lớn hơn giá trị đồng hồ cục bộ của nó, nó di chuyển giá trị cục bộ của mình về phía trước để khớp với dấu thời gian của node khác. Kết quả là, nếu đồng hồ của một node chạy nhanh, các node khác sẽ tương tự di chuyển đồng hồ của họ về phía trước khi họ giao tiếp.
Mỗi khi một dấu thời gian từ hybrid logical clock được tạo ra, nó cũng được tăng, điều này đảm bảo rằng đồng hồ di chuyển về phía trước một cách đơn điệu, ngay cả khi đồng hồ vật lý cơ bản nhảy về phía sau, ví dụ do điều chỉnh NTP. Do đó, hybrid logical clock có thể hơi vượt trước đồng hồ vật lý cơ bản. Các chi tiết của thuật toán đảm bảo rằng sự chênh lệch này vẫn ở mức nhỏ nhất có thể.
Do đó, bạn có thể coi một dấu thời gian từ hybrid logical clock gần như là một dấu thời gian từ đồng hồ thời gian thực thông thường, với thuộc tính bổ sung là thứ tự của nó nhất quán với quan hệ happens-before (xảy ra trước). Nó không phụ thuộc vào bất kỳ phần cứng đặc biệt nào, và chỉ yêu cầu các đồng hồ được đồng bộ hóa xấp xỉ. Hybrid logical clock được sử dụng bởi CockroachDB, ví dụ.
Lamport/hybrid logical clocks vs. vector clocks
Trong “Multi-version concurrency control (MVCC)” chúng ta đã thảo luận về cách snapshot isolation thường được triển khai: về cơ bản, bằng cách cung cấp cho mỗi giao dịch một ID giao dịch, và cho phép mỗi giao dịch xem các lần ghi được thực hiện bởi các giao dịch có ID thấp hơn, nhưng làm cho các lần ghi bởi các giao dịch có ID cao hơn không hiển thị. Đồng hồ Lamport và hybrid logical clock là cách tốt để tạo các ID giao dịch này, vì chúng đảm bảo rằng snapshot nhất quán với tính nhân quả 56.
Khi nhiều dấu thời gian được tạo ra đồng thời, các thuật toán này sắp xếp chúng một cách tùy ý. Điều này có nghĩa là khi bạn xem xét hai dấu thời gian, bạn thường không thể biết liệu chúng có được tạo ra đồng thời hay liệu cái này có xảy ra trước cái kia hay không. (Trong ví dụ về Hình 10-9, bạn thực sự có thể biết rằng các tin nhắn của Aaliyah và Caleb phải đã đồng thời, vì chúng có cùng giá trị bộ đếm, nhưng khi các giá trị bộ đếm khác nhau, bạn không thể biết liệu chúng có đồng thời hay không.)
Nếu bạn muốn có thể xác định khi nào các bản ghi được tạo ra đồng thời, bạn cần một thuật toán khác, chẳng hạn như vector clock (đồng hồ vectơ). Nhược điểm là các dấu thời gian từ vector clock lớn hơn nhiều, có thể là một số nguyên cho mỗi node trong hệ thống. Xem “Detecting Concurrent Writes” để biết thêm chi tiết về phát hiện tính đồng thời.
Linearizable ID Generators
Mặc dù đồng hồ Lamport và hybrid logical clock cung cấp các đảm bảo thứ tự hữu ích, thứ tự đó vẫn yếu hơn so với bộ tạo ID đơn node linearizable mà chúng ta đã nói trước đó. Nhớ lại rằng linearizability yêu cầu rằng nếu yêu cầu A hoàn thành trước khi yêu cầu B bắt đầu, thì B phải có ID cao hơn, ngay cả khi A và B không bao giờ giao tiếp với nhau. Mặt khác, đồng hồ Lamport chỉ có thể đảm bảo rằng một node tạo ra các dấu thời gian lớn hơn bất kỳ dấu thời gian nào khác mà node đó đã thấy, nhưng nó không thể nói bất cứ điều gì về các dấu thời gian mà nó chưa thấy.
Hình 10-10 cho thấy cách một bộ tạo ID không phải linearizable có thể gây ra vấn đề. Hãy tưởng tượng một trang web mạng xã hội nơi người dùng A muốn chia sẻ một bức ảnh đáng xấu hổ một cách riêng tư với bạn bè của họ. Tài khoản của A ban đầu là công khai, nhưng sử dụng laptop của mình, A đầu tiên thay đổi cài đặt tài khoản sang chế độ riêng tư. Sau đó A sử dụng điện thoại để tải lên bức ảnh. Vì A đã thực hiện các cập nhật này theo thứ tự, họ có thể hợp lý kỳ vọng rằng lần tải lên ảnh phải tuân theo các quyền tài khoản mới, bị hạn chế.
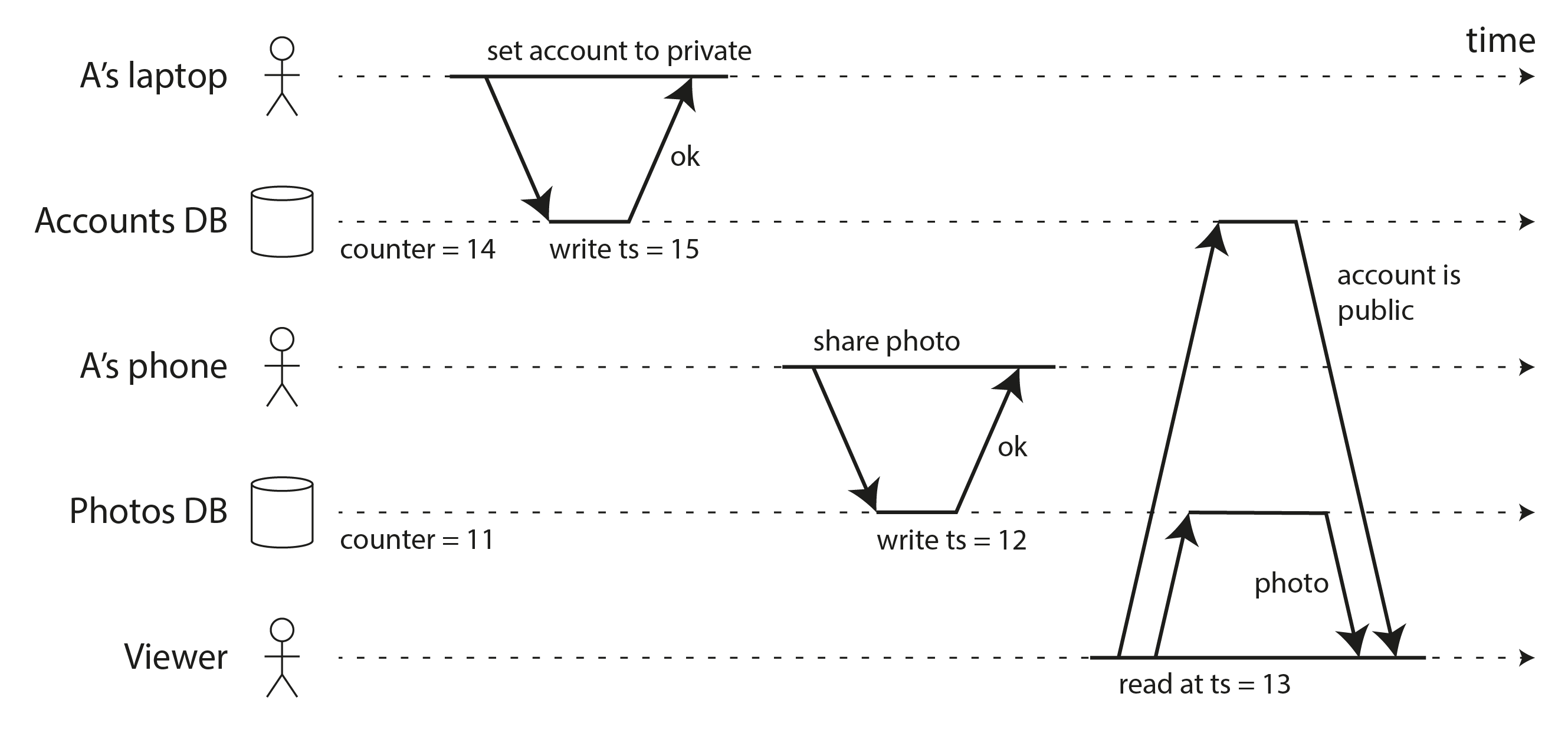
Quyền tài khoản và bức ảnh được lưu trữ trong hai cơ sở dữ liệu riêng biệt (hoặc các shard riêng biệt của cùng một cơ sở dữ liệu), và giả sử chúng sử dụng đồng hồ Lamport hoặc hybrid logical clock để gán dấu thời gian cho mỗi lần ghi. Vì cơ sở dữ liệu ảnh không đọc từ cơ sở dữ liệu tài khoản, có thể bộ đếm cục bộ trong cơ sở dữ liệu ảnh hơi tụt hậu, và do đó lần tải lên ảnh được gán dấu thời gian thấp hơn so với cập nhật cài đặt tài khoản.
Tiếp theo, giả sử một người xem (không phải bạn bè của A) đang xem hồ sơ của A, và lần đọc của họ sử dụng triển khai MVCC của snapshot isolation. Có thể xảy ra là dấu thời gian của lần đọc người xem lớn hơn dấu thời gian của lần tải lên ảnh, nhưng nhỏ hơn dấu thời gian của bản cập nhật cài đặt tài khoản. Kết quả là, hệ thống sẽ xác định rằng tài khoản vẫn còn công khai tại thời điểm đọc, và do đó hiển thị cho người xem bức ảnh đáng xấu hổ mà họ không được phép xem.
Bạn có thể tưởng tượng một số cách có thể khắc phục vấn đề này. Có lẽ cơ sở dữ liệu ảnh nên đọc trạng thái tài khoản của người dùng trước khi thực hiện lần ghi, nhưng dễ dàng quên kiểm tra như vậy. Nếu các hành động của A được thực hiện trên cùng một thiết bị, có lẽ ứng dụng trên thiết bị của họ có thể theo dõi dấu thời gian mới nhất của các lần ghi của người dùng đó, nhưng nếu người dùng sử dụng laptop và điện thoại như trong ví dụ, điều đó không dễ dàng.
Giải pháp đơn giản nhất trong trường hợp này sẽ là sử dụng bộ tạo ID linearizable, điều này sẽ đảm bảo rằng lần tải lên ảnh được gán một ID lớn hơn so với thay đổi quyền tài khoản.
Implementing a linearizable ID generator
Cách đơn giản nhất để đảm bảo rằng việc phân bổ ID là linearizable là thực sự sử dụng một node duy nhất cho mục đích này. Node đó chỉ cần nguyên tử tăng một bộ đếm và trả về giá trị của nó khi được yêu cầu, lưu trữ bền vững giá trị bộ đếm (để nó không tạo ra các ID trùng lặp nếu node gặp sự cố và khởi động lại), và sao chép nó để chịu lỗi (sử dụng single-leader replication). Cách tiếp cận này được sử dụng trong thực tế: ví dụ, TiDB/TiKV gọi nó là timestamp oracle (nhà tiên tri dấu thời gian), lấy cảm hứng từ Percolator của Google 57.
Như một tối ưu hóa, bạn có thể tránh thực hiện một lần ghi đĩa và sao chép trên mỗi yêu cầu đơn lẻ. Thay vào đó, bộ tạo ID có thể ghi một bản ghi mô tả một lô ID; sau khi bản ghi đó được lưu trữ bền vững và sao chép, node có thể bắt đầu phân phát các ID đó cho các client theo thứ tự. Trước khi cạn hết ID trong lô đó, nó có thể lưu trữ bền vững và sao chép bản ghi cho lô tiếp theo. Theo cách đó, một số ID sẽ bị bỏ qua nếu node gặp sự cố và khởi động lại hoặc nếu bạn chuyển đổi dự phòng sang một follower, nhưng bạn sẽ không phát hành bất kỳ ID trùng lặp hoặc không theo thứ tự nào.
Bạn không thể dễ dàng phân mảnh (shard) bộ sinh ID, vì nếu có nhiều shard độc lập cấp phát ID, bạn không còn có thể đảm bảo rằng thứ tự của chúng là tuyến tính hóa (linearizable) nữa. Bạn cũng không thể dễ dàng phân tán bộ sinh ID qua nhiều vùng địa lý; do đó, trong một cơ sở dữ liệu phân tán theo địa lý, tất cả các yêu cầu lấy ID đều phải đi đến một node ở một vùng duy nhất. Mặt tích cực là công việc của bộ sinh ID rất đơn giản, nên một node duy nhất có thể xử lý lượng yêu cầu thông lượng lớn.
Nếu bạn không muốn dùng bộ sinh ID trên một node duy nhất, có một giải pháp thay thế: bạn có thể làm theo cách Google Spanner thực hiện, như đã thảo luận trong “Synchronized clocks for global snapshots”. Cách này dựa vào đồng hồ vật lý trả về không chỉ một dấu thời gian đơn lẻ, mà là một khoảng dấu thời gian cho biết độ không chắc chắn trong số đọc đồng hồ. Sau đó nó chờ cho khoảng thời gian không chắc chắn đó trôi qua trước khi trả kết quả.
Giả sử khoảng không chắc chắn là chính xác (tức là thời gian vật lý thực tế luôn nằm trong khoảng đó), quá trình này cũng đảm bảo rằng nếu một yêu cầu hoàn tất trước khi yêu cầu khác bắt đầu, yêu cầu sau sẽ có dấu thời gian lớn hơn. Phương pháp này đảm bảo việc gán ID tuyến tính hóa mà không cần bất kỳ giao tiếp nào: ngay cả các yêu cầu ở các vùng khác nhau cũng sẽ được sắp xếp đúng thứ tự, mà không cần chờ các yêu cầu liên vùng. Nhược điểm là bạn cần hỗ trợ phần cứng và phần mềm để đồng hồ được đồng bộ chặt chẽ và tính toán khoảng không chắc chắn cần thiết.
Thực thi các ràng buộc bằng đồng hồ logic
Trong “Constraints and uniqueness guarantees” chúng ta đã thấy rằng một thao tác so sánh và đặt (compare-and-set) tuyến tính hóa có thể được dùng để triển khai khóa (lock), ràng buộc duy nhất (uniqueness constraint), và các cấu trúc tương tự trong hệ thống phân tán. Điều này đặt ra câu hỏi: liệu đồng hồ logic hay bộ sinh ID tuyến tính hóa có đủ để triển khai những thứ này không?
Câu trả lời là: chưa đủ. Khi có nhiều node cùng cố gắng giành cùng một khóa hay đăng ký cùng một tên người dùng, bạn có thể dùng đồng hồ logic để gán dấu thời gian cho các yêu cầu đó, và chọn yêu cầu có dấu thời gian nhỏ nhất là người thắng. Nếu đồng hồ là tuyến tính hóa, bạn biết rằng bất kỳ yêu cầu tương lai nào cũng sẽ luôn tạo dấu thời gian lớn hơn, và do đó có thể chắc chắn rằng không có yêu cầu tương lai nào nhận được dấu thời gian nhỏ hơn người thắng.
Thật không may, một phần vấn đề vẫn chưa được giải quyết: làm thế nào để một node biết dấu thời gian của mình là nhỏ nhất? Để chắc chắn, nó cần nhận thông tin từ tất cả các node khác có thể đã tạo dấu thời gian 54. Nếu một trong số các node khác đã hỏng trong thời gian đó, hoặc không thể tiếp cận được do sự cố mạng, hệ thống sẽ đình trệ, vì không thể chắc chắn liệu node đó có thể có dấu thời gian nhỏ nhất hay không. Đây không phải loại hệ thống chịu lỗi (fault-tolerant) mà chúng ta cần.
Để triển khai khóa, cho thuê (lease), và các cấu trúc tương tự theo cách chịu lỗi, chúng ta cần thứ gì đó mạnh hơn đồng hồ logic hay bộ sinh ID: chúng ta cần đồng thuận (consensus).
Đồng thuận
Trong chương này chúng ta đã thấy một số ví dụ về những thứ dễ dàng khi chỉ có một node duy nhất, nhưng trở nên khó hơn rất nhiều nếu bạn muốn chịu lỗi:
- Cơ sở dữ liệu có thể tuyến tính hóa nếu bạn chỉ có một leader duy nhất, và thực hiện tất cả đọc và ghi trên leader đó. Nhưng làm thế nào để chuyển giao (failover) nếu leader đó hỏng, trong khi tránh tình trạng split brain? Làm thế nào để đảm bảo rằng một node tin mình là leader thực sự chưa bị bãi bỏ trong thời gian đó?
- Bộ sinh ID tuyến tính hóa trên một node duy nhất chỉ là bộ đếm với lệnh fetch-and-add nguyên tử (atomic), nhưng nếu nó bị sập thì sao?
- Thao tác so sánh và đặt nguyên tử (atomic compare-and-set, CAS) hữu ích cho nhiều mục đích, chẳng hạn như quyết định ai giành được khóa hoặc cho thuê khi nhiều tiến trình đang chạy đua để giành nó, hoặc đảm bảo tính duy nhất của file hay người dùng với tên cho trước. Trên một node duy nhất, CAS có thể đơn giản như một lệnh CPU, nhưng làm thế nào để nó chịu lỗi?
Hóa ra tất cả những điều này đều là các thể hiện của cùng một vấn đề cơ bản trong hệ thống phân tán: đồng thuận (consensus). Đồng thuận là một trong những vấn đề quan trọng và cơ bản nhất trong điện toán phân tán; nó cũng nổi tiếng khó thực hiện đúng 58 59, và nhiều hệ thống đã làm sai trong quá khứ. Bây giờ chúng ta đã thảo luận về nhân bản (replication) (Chương 6), giao dịch (transaction) (Chương 8), mô hình hệ thống (Chương 9), và tuyến tính hóa (chương này), chúng ta cuối cùng đã sẵn sàng để giải quyết vấn đề đồng thuận.
Các thuật toán đồng thuận được biết đến nhiều nhất là Viewstamped Replication 60 61, Paxos 58 62 63 64, Raft 23 65 66, và Zab 18 22 67. Có khá nhiều điểm tương đồng giữa các thuật toán này, nhưng chúng không giống nhau 68 69. Các thuật toán này hoạt động trong mô hình hệ thống phi Byzantine (non-Byzantine): nghĩa là giao tiếp mạng có thể bị trì hoãn hay mất tùy ý, và các node có thể sập, khởi động lại và bị ngắt kết nối, nhưng các thuật toán giả định rằng các node ngoài ra vẫn tuân theo giao thức đúng đắn và không hành xử ác ý.
Cũng có các thuật toán đồng thuận có thể chịu đựng một số node Byzantine, tức là các node không tuân theo giao thức đúng đắn (ví dụ: gửi các thông điệp mâu thuẫn đến các node khác). Giả định thông thường là ít hơn một phần ba số node bị lỗi Byzantine 26 70. Các thuật toán đồng thuận chịu lỗi Byzantine (Byzantine fault tolerant, BFT) được dùng trong blockchain 71. Tuy nhiên, như đã giải thích trong “Byzantine Faults”, các thuật toán BFT nằm ngoài phạm vi của cuốn sách này.
SỰ BẤT KHẢ THI CỦA ĐỒNG THUẬN
Bạn có thể đã nghe về kết quả FLP 72, được đặt tên theo các tác giả Fischer, Lynch và Paterson, chứng minh rằng không có thuật toán nào luôn có thể đạt được đồng thuận nếu có nguy cơ một node có thể sập. Trong hệ thống phân tán, chúng ta phải giả định rằng các node có thể sập, vì vậy đồng thuận đáng tin cậy là không thể. Vậy mà ở đây, chúng ta đang thảo luận về các thuật toán để đạt được đồng thuận. Điều gì đang xảy ra?
Thứ nhất, FLP không nói rằng chúng ta không bao giờ có thể đạt đồng thuận, nó chỉ nói rằng chúng ta không thể đảm bảo rằng một thuật toán đồng thuận sẽ luôn luôn kết thúc. Hơn nữa, kết quả FLP được chứng minh với giả định là thuật toán tất định (deterministic algorithm) trong mô hình hệ thống bất đồng bộ (asynchronous system model) (xem “System Model and Reality”), có nghĩa là thuật toán không thể sử dụng đồng hồ hay thời gian chờ (timeout). Nếu nó có thể dùng timeout để nghi ngờ rằng một node khác có thể đã sập (dù đôi khi sự nghi ngờ là sai), thì đồng thuận trở nên có thể giải quyết được 73. Ngay cả chỉ cho phép thuật toán sử dụng số ngẫu nhiên cũng đủ để vượt qua kết quả bất khả thi đó 74.
Do đó, mặc dù kết quả FLP về sự bất khả thi của đồng thuận có tầm quan trọng lý thuyết lớn, các hệ thống phân tán thường có thể đạt được đồng thuận trong thực tế.
Các Hình Thức Của Đồng Thuận
Đồng thuận có thể được biểu diễn theo nhiều cách khác nhau:
- Đồng thuận một giá trị (single-value consensus) rất giống với thao tác compare-and-set nguyên tử, và có thể được dùng để triển khai khóa, cho thuê, và ràng buộc duy nhất.
- Xây dựng một log chỉ thêm vào (append-only log) cũng đòi hỏi đồng thuận; nó thường được hình thức hóa là phát sóng tổng thứ tự (total order broadcast). Với một log bạn có thể xây dựng nhân bản máy trạng thái (state machine replication), nhân bản dựa trên leader, event sourcing, và nhiều thứ hữu ích khác.
- Cam kết nguyên tử (atomic commitment) của một giao dịch đa cơ sở dữ liệu hoặc đa phân mảnh đòi hỏi tất cả các bên tham gia đồng ý về việc commit hay hủy bỏ giao dịch.
Chúng ta sẽ khám phá tất cả những điều này ngay sau đây. Thực ra, các vấn đề này đều tương đương với nhau: nếu bạn có một thuật toán giải quyết một trong số chúng, bạn có thể chuyển đổi nó thành giải pháp cho bất kỳ vấn đề nào trong số còn lại. Đây là một cái nhìn sâu sắc khá sâu xa và có lẽ bất ngờ! Đó là lý do tại sao chúng ta có thể gộp tất cả những thứ này vào “đồng thuận”, dù chúng trông khá khác nhau trên bề mặt.
Đồng thuận một giá trị
Công thức tiêu chuẩn của đồng thuận liên quan đến việc khiến nhiều node đồng ý về một giá trị duy nhất. Ví dụ:
- Khi một cơ sở dữ liệu với nhân bản leader đơn lần đầu khởi động, hoặc khi leader hiện tại hỏng, nhiều node có thể đồng thời cố gắng trở thành leader. Tương tự, nhiều node có thể tranh giành để giành khóa hoặc cho thuê. Đồng thuận cho phép chúng quyết định node nào thắng.
- Nếu nhiều người đồng thời cố đặt chỗ cuối cùng trên máy bay, hoặc cùng một ghế trong rạp hát, hoặc cố đăng ký tài khoản với cùng tên người dùng, thì một thuật toán đồng thuận có thể xác định ai nên thành công.
Tổng quát hơn, một hay nhiều node có thể đề xuất giá trị, và thuật toán đồng thuận quyết định một trong số các giá trị đó. Trong các ví dụ trên, mỗi node có thể đề xuất ID của chính mình, và thuật toán quyết định node ID nào sẽ trở thành leader mới, người giữ cho thuê, hoặc người mua vé máy bay/ghế rạp. Trong hình thức luận này, một thuật toán đồng thuận phải thỏa mãn các tính chất sau 26:
- Đồng thuận đồng nhất (Uniform agreement)
- Không có hai node nào quyết định khác nhau.
- Tính toàn vẹn (Integrity)
- Một khi một node đã quyết định một giá trị, nó không thể thay đổi ý kiến bằng cách quyết định giá trị khác.
- Tính hợp lệ (Validity)
- Nếu một node quyết định giá trị v, thì v đã được đề xuất bởi một node nào đó.
- Tính kết thúc (Termination)
- Mọi node không bị sập cuối cùng sẽ quyết định một giá trị nào đó.
Nếu bạn muốn quyết định nhiều giá trị, bạn có thể chạy một phiên bản riêng của thuật toán đồng thuận cho mỗi giá trị. Ví dụ, bạn có thể có một lần chạy đồng thuận riêng biệt cho mỗi ghế có thể đặt trong rạp hát, để bạn nhận được một quyết định (một người mua) cho mỗi ghế.
Các tính chất đồng thuận đồng nhất và toàn vẹn định nghĩa ý tưởng cốt lõi của đồng thuận: mọi người quyết định cùng một kết quả, và khi đã quyết định, bạn không thể thay đổi ý kiến. Tính hợp lệ loại bỏ các giải pháp tầm thường: ví dụ, bạn có thể có một thuật toán luôn quyết định null, bất kể điều gì được đề xuất; thuật toán này sẽ thỏa mãn các tính chất đồng thuận và toàn vẹn, nhưng không thỏa mãn tính hợp lệ.
Nếu bạn không quan tâm đến khả năng chịu lỗi, thì việc thỏa mãn ba tính chất đầu tiên khá dễ: bạn có thể hardcode một node là “độc tài”, và để node đó đưa ra tất cả quyết định. Tuy nhiên, nếu node đó hỏng, hệ thống không thể đưa ra bất kỳ quyết định nào nữa, giống như nhân bản leader đơn không có failover. Tất cả sự khó khăn nảy sinh từ nhu cầu chịu lỗi.
Tính kết thúc hình thức hóa ý tưởng về khả năng chịu lỗi. Về bản chất nó nói rằng một thuật toán đồng thuận không thể chỉ đứng đó và không làm gì mãi mãi, nói cách khác, nó phải tiến triển. Ngay cả khi một số node hỏng, các node khác vẫn phải đưa ra quyết định. (Tính kết thúc là thuộc tính sống (liveness property), trong khi ba thuộc tính kia là thuộc tính an toàn (safety properties), xem “Safety and liveness”.)
Nếu một node bị sập có thể phục hồi, bạn chỉ có thể chờ nó quay lại. Tuy nhiên, đồng thuận phải đảm bảo rằng nó đưa ra quyết định ngay cả khi một node bị sập đột ngột biến mất và không bao giờ quay lại. (Thay vì sập phần mềm, hãy tưởng tượng rằng có một trận động đất, và trung tâm dữ liệu chứa node của bạn bị phá hủy bởi lở đất. Bạn phải giả định rằng node của bạn bị chôn vùi dưới 30 feet bùn và sẽ không bao giờ trực tuyến trở lại.)
Tất nhiên, nếu tất cả các node đều sập và không có node nào đang chạy, thì không có thuật toán nào có thể quyết định bất cứ điều gì. Có giới hạn về số lần hỏng mà một thuật toán có thể chịu đựng: thực tế, có thể chứng minh rằng bất kỳ thuật toán đồng thuận nào cũng yêu cầu ít nhất đa số node hoạt động đúng để đảm bảo tính kết thúc 73. Đa số đó có thể an toàn tạo thành quorum (xem “Quorums for reading and writing”).
Do đó, tính kết thúc phụ thuộc vào giả định rằng ít hơn nửa số node bị sập hoặc không thể tiếp cận. Tuy nhiên, hầu hết các thuật toán đồng thuận đảm bảo rằng các tính chất an toàn, gồm đồng thuận, toàn vẹn và hợp lệ, luôn được đáp ứng, ngay cả khi đa số node hỏng hoặc có sự cố mạng nghiêm trọng 75. Do đó, một sự cố quy mô lớn có thể khiến hệ thống không thể xử lý các yêu cầu, nhưng không thể làm hỏng hệ thống đồng thuận bằng cách khiến nó đưa ra các quyết định không nhất quán.
So sánh và đặt như đồng thuận
Một thao tác so sánh và đặt (compare-and-set, CAS) kiểm tra xem giá trị hiện tại của một đối tượng có bằng một giá trị kỳ vọng nào đó không; nếu có, nó nguyên tử cập nhật đối tượng thành một giá trị mới; nếu không, nó để nguyên đối tượng và trả về lỗi.
Nếu bạn có một thao tác CAS tuyến tính hóa, chịu lỗi, thì dễ dàng giải quyết vấn đề đồng thuận: ban đầu đặt đối tượng về giá trị null; mỗi node muốn đề xuất một giá trị gọi CAS với giá trị kỳ vọng là null, và giá trị mới là giá trị mà nó muốn đề xuất (giả sử nó khác null). Giá trị được quyết định sau đó là bất kỳ giá trị nào đối tượng được đặt thành.
Tương tự, nếu bạn có giải pháp cho đồng thuận, bạn có thể triển khai CAS: bất cứ khi nào một hay nhiều node muốn thực hiện CAS với cùng giá trị kỳ vọng, bạn dùng giao thức đồng thuận để đề xuất các giá trị mới trong lời gọi CAS, rồi đặt đối tượng thành bất kỳ giá trị nào được quyết định bởi đồng thuận. Bất kỳ lời gọi CAS nào mà giá trị mới không được quyết định đều trả về lỗi. Các lời gọi CAS với giá trị kỳ vọng khác nhau sử dụng các lần chạy riêng của giao thức đồng thuận.
Điều này cho thấy CAS và đồng thuận là tương đương với nhau 28 73. Cả hai đều đơn giản trên một node duy nhất, nhưng khó để chịu lỗi. Như một ví dụ về CAS trong môi trường phân tán, chúng ta đã thấy các thao tác ghi có điều kiện cho object store trong “Databases backed by object storage”, chỉ cho phép một lần ghi xảy ra nếu một đối tượng có cùng tên chưa được tạo hoặc sửa đổi bởi một client khác kể từ khi client hiện tại đọc nó lần cuối.
Tuy nhiên, một thanh ghi đọc-ghi (read-write register) tuyến tính hóa không đủ để giải quyết đồng thuận. Kết quả FLP cho chúng ta biết rằng đồng thuận không thể được giải quyết bởi một thuật toán tất định trong mô hình crash-stop bất đồng bộ 72, nhưng chúng ta đã thấy trong “Linearizability and quorums” rằng một thanh ghi tuyến tính hóa có thể được triển khai bằng cách sử dụng quorum đọc/ghi trong mô hình này 24 25 26. Từ đó suy ra rằng một thanh ghi tuyến tính hóa không thể giải quyết đồng thuận.
Log dùng chung như đồng thuận
Chúng ta đã thấy một số ví dụ về log, chẳng hạn như log nhân bản, log giao dịch, và write-ahead log. Một log lưu trữ một chuỗi các mục log (log entry), và bất kỳ ai đọc nó đều thấy cùng các mục theo cùng thứ tự. Đôi khi một log có một writer duy nhất được phép thêm các mục mới, nhưng log dùng chung (shared log) là log mà nhiều node có thể yêu cầu thêm các mục vào. Một ví dụ là nhân bản leader đơn: bất kỳ client nào cũng có thể yêu cầu leader thực hiện ghi, leader thêm vào log nhân bản, và sau đó tất cả các follower áp dụng các lần ghi theo cùng thứ tự như leader.
Chính thức hơn, một log dùng chung hỗ trợ hai thao tác: bạn có thể yêu cầu một giá trị được thêm vào log, và bạn có thể đọc các mục trong log. Nó phải thỏa mãn các tính chất sau:
- Thêm vào cuối cùng (Eventual append)
- Nếu một node yêu cầu một giá trị được thêm vào log, và node đó không sập, thì node đó cuối cùng phải đọc được giá trị đó trong một mục log.
- Phân phối đáng tin cậy (Reliable delivery)
- Không có mục log nào bị mất: nếu một node đọc một mục log nào đó, thì cuối cùng mọi node không bị sập cũng phải đọc được mục log đó.
- Chỉ thêm vào (Append-only)
- Một khi một node đã đọc một mục log nào đó, nó là bất biến, và các mục log mới chỉ có thể được thêm vào sau nó, chứ không phải trước. Một node có thể đọc lại log, trong trường hợp đó nó thấy cùng các mục log theo cùng thứ tự như lần đọc ban đầu (ngay cả khi node sập và khởi động lại).
- Đồng thuận (Agreement)
- Nếu hai node cùng đọc một mục log e, thì trước e chúng phải đã đọc chính xác cùng một chuỗi các mục log theo cùng thứ tự.
- Tính hợp lệ (Validity)
- Nếu một node đọc một mục log chứa một giá trị nào đó, thì một node nào đó trước đó đã yêu cầu giá trị đó được thêm vào log.
Note
Một log dùng chung còn được gọi chính thức là giao thức phát sóng tổng thứ tự (total order broadcast), phát sóng nguyên tử (atomic broadcast), hoặc multicast tổng thứ tự (total order multicast) 26 76 77 Đây là cùng một thứ được mô tả bằng những từ khác nhau: yêu cầu một giá trị được thêm vào log thì được gọi là “phát sóng” (broadcasting) nó, và đọc một mục log thì được gọi là “phân phối” (delivering) nó.
Nếu bạn có một triển khai của log dùng chung, thì dễ dàng giải quyết vấn đề đồng thuận: mỗi node muốn đề xuất một giá trị sẽ yêu cầu nó được thêm vào log, và bất kỳ giá trị nào được đọc lại trong mục log đầu tiên là giá trị được quyết định. Vì tất cả các node đọc các mục log theo cùng thứ tự, chúng được đảm bảo đồng ý về giá trị nào được phân phối đầu tiên 28.
Ngược lại, nếu bạn có giải pháp cho đồng thuận, bạn có thể triển khai log dùng chung. Chi tiết phức tạp hơn một chút, nhưng ý tưởng cơ bản là như thế này 73:
- Bạn có một slot trong log cho mỗi mục log tương lai, và bạn chạy một phiên bản riêng của thuật toán đồng thuận cho mỗi slot đó để quyết định giá trị nào nên đi vào mục đó.
- Khi một node muốn thêm một giá trị vào log, nó đề xuất giá trị đó cho một trong các slot chưa được quyết định.
- Khi thuật toán đồng thuận quyết định cho một trong các slot, và tất cả các slot trước đó đã được quyết định, thì giá trị được quyết định được thêm vào như một mục log mới, và bất kỳ slot liên tiếp nào đã được quyết định cũng có giá trị được quyết định của chúng được thêm vào log.
- Nếu một giá trị được đề xuất không được chọn cho một slot nào đó, node muốn thêm nó sẽ thử lại bằng cách đề xuất nó cho một slot sau.
Điều này cho thấy đồng thuận tương đương với phát sóng tổng thứ tự và log dùng chung. Nhân bản leader đơn không có failover không đáp ứng các yêu cầu về tính sống, vì nó ngừng phân phối các thông điệp nếu leader sập. Như thường lệ, thách thức là thực hiện failover một cách an toàn và tự động.
Fetch-and-add như đồng thuận
Bộ sinh ID tuyến tính hóa mà chúng ta đã thấy trong “Linearizable ID Generators” gần như giải quyết đồng thuận, nhưng còn hơi thiếu. Chúng ta có thể triển khai bộ sinh ID như vậy bằng cách sử dụng thao tác fetch-and-add, thao tác này nguyên tử tăng một bộ đếm và trả về giá trị bộ đếm cũ.
Nếu bạn có thao tác CAS, thì dễ dàng triển khai fetch-and-add: trước tiên đọc giá trị bộ đếm, sau đó thực hiện CAS với giá trị kỳ vọng là giá trị bạn đã đọc, và giá trị mới là giá trị đó cộng thêm một. Nếu CAS thất bại, bạn thử lại toàn bộ quá trình cho đến khi CAS thành công. Điều này kém hiệu quả hơn thao tác fetch-and-add gốc khi có tranh chấp, nhưng về mặt chức năng là tương đương. Vì bạn có thể triển khai CAS bằng đồng thuận, bạn cũng có thể triển khai fetch-and-add bằng đồng thuận.
Ngược lại, nếu bạn có thao tác fetch-and-add chịu lỗi, liệu bạn có thể giải quyết vấn đề đồng thuận không? Giả sử bạn khởi tạo bộ đếm về không, và mỗi node muốn đề xuất một giá trị gọi thao tác fetch-and-add để tăng bộ đếm. Vì thao tác fetch-and-add là nguyên tử, một trong các node sẽ đọc giá trị ban đầu là không, và các node còn lại đều đọc một giá trị đã được tăng ít nhất một lần.
Bây giờ giả sử rằng node đọc được không là người thắng, và giá trị của nó được quyết định. Điều đó hoạt động cho node đọc được không, nhưng các node khác có vấn đề: chúng biết rằng chúng không phải người thắng, nhưng không biết node nào trong số các node khác đã thắng. Node thắng có thể gửi thông báo cho các node khác để cho họ biết nó đã thắng, nhưng nếu node thắng sập trước khi có cơ hội gửi thông báo này thì sao? Trong trường hợp đó các node khác bị treo, không thể quyết định giá trị nào, và do đó đồng thuận không kết thúc. Và các node khác không thể chuyển sang node khác, vì node đọc được không có thể quay lại và quyết định đúng giá trị mà nó đã đề xuất.
Một ngoại lệ là nếu chúng ta biết chắc chắn rằng không nhiều hơn hai node sẽ đề xuất giá trị. Trong trường hợp đó, các node có thể gửi cho nhau các giá trị mà họ muốn đề xuất, và sau đó mỗi node thực hiện thao tác fetch-and-add. Node đọc được không quyết định giá trị của chính mình, và node đọc được một quyết định giá trị của node kia. Điều này giải quyết vấn đề đồng thuận giữa hai node, đó là lý do tại sao chúng ta có thể nói rằng fetch-and-add có số đồng thuận (consensus number) là hai 28. Ngược lại, CAS và log dùng chung giải quyết đồng thuận cho bất kỳ số node nào có thể đề xuất giá trị, vì vậy chúng có số đồng thuận là vô cực (∞).
Cam kết nguyên tử như đồng thuận
Trong “Distributed Transactions” chúng ta đã thấy vấn đề cam kết nguyên tử (atomic commitment), là đảm bảo rằng các cơ sở dữ liệu hoặc phân mảnh liên quan đến một giao dịch phân tán đều commit hoặc hủy bỏ giao dịch. Chúng ta cũng đã thấy thuật toán two-phase commit (cam kết hai pha), dựa vào một bộ điều phối (coordinator) là điểm lỗi đơn (single point of failure).
Mối quan hệ giữa đồng thuận và cam kết nguyên tử là gì? Thoạt nhìn, chúng có vẻ rất giống nhau vì cả hai đều yêu cầu các node đi đến một dạng thỏa thuận nào đó. Tuy nhiên, có một sự khác biệt quan trọng: với đồng thuận, bất kỳ giá trị được đề xuất nào cũng có thể được quyết định, trong khi với cam kết nguyên tử, thuật toán phải hủy bỏ nếu bất kỳ bên tham gia nào bỏ phiếu hủy. Chính xác hơn, cam kết nguyên tử yêu cầu các tính chất sau 78:
- Đồng thuận đồng nhất (Uniform agreement)
- Không có hai node nào quyết định kết quả khác nhau.
- Tính toàn vẹn (Integrity)
- Một khi một node đã quyết định một kết quả, nó không thể thay đổi ý kiến bằng cách quyết định kết quả khác.
- Tính hợp lệ (Validity)
- Nếu một node quyết định commit, thì tất cả các node phải đã bỏ phiếu commit trước đó. Nếu bất kỳ node nào bỏ phiếu hủy, các node phải hủy bỏ.
- Tính không tầm thường (Non-triviality)
- Nếu tất cả các node bỏ phiếu commit, và không có timeout giao tiếp nào xảy ra, thì tất cả các node phải quyết định commit.
- Tính kết thúc (Termination)
- Mọi node không bị sập cuối cùng sẽ quyết định commit hoặc hủy bỏ.
Tính hợp lệ đảm bảo rằng một giao dịch chỉ có thể commit nếu tất cả các node đồng ý; và tính không tầm thường đảm bảo rằng thuật toán không thể chỉ luôn hủy bỏ (nhưng nó cho phép hủy bỏ nếu bất kỳ giao tiếp nào giữa các node hết thời gian chờ). Ba tính chất còn lại về cơ bản giống với đồng thuận.
Nếu bạn có giải pháp cho đồng thuận, có nhiều cách bạn có thể giải quyết cam kết nguyên tử 78 79. Một cách hoạt động như thế này: khi bạn muốn commit giao dịch, mỗi node gửi phiếu bầu commit hay hủy bỏ của mình đến mọi node khác. Các node nhận được phiếu bầu commit từ bản thân và mọi node khác đề xuất “commit” bằng thuật toán đồng thuận; các node nhận được phiếu bầu hủy, hoặc gặp timeout, đề xuất “hủy bỏ” bằng thuật toán đồng thuận. Khi một node biết được quyết định của thuật toán đồng thuận, nó commit hoặc hủy bỏ tương ứng.
Trong thuật toán này, “commit” chỉ được đề xuất nếu tất cả các node bỏ phiếu commit. Nếu bất kỳ node nào bỏ phiếu hủy, tất cả các đề xuất trong thuật toán đồng thuận sẽ là “hủy bỏ”. Có thể xảy ra trường hợp một số node đề xuất “hủy bỏ” trong khi các node khác đề xuất “commit” nếu tất cả các node bỏ phiếu commit nhưng một số giao tiếp hết thời gian; trong trường hợp này không quan trọng các node commit hay hủy bỏ, miễn là chúng đều làm giống nhau.
Nếu bạn có giao thức cam kết nguyên tử chịu lỗi, bạn cũng có thể giải quyết đồng thuận. Mỗi node muốn đề xuất một giá trị bắt đầu một giao dịch trên một quorum các node, và tại mỗi node nó thực hiện CAS trên một node đơn để đặt thanh ghi thành giá trị được đề xuất nếu giá trị của nó chưa được đặt bởi một giao dịch khác. Nếu CAS thành công, node bỏ phiếu commit; nếu không, nó bỏ phiếu hủy. Nếu giao thức cam kết nguyên tử quyết định commit một giao dịch, giá trị của nó được quyết định cho đồng thuận; nếu cam kết nguyên tử hủy bỏ, node đề xuất thử lại với một giao dịch mới.
Điều này cho thấy cam kết nguyên tử và đồng thuận cũng tương đương với nhau.
Đồng Thuận Trong Thực Tế
Chúng ta đã thấy rằng đồng thuận một giá trị, CAS, log dùng chung, và cam kết nguyên tử đều tương đương với nhau: bạn có thể chuyển đổi một giải pháp cho bất kỳ vấn đề nào trong số chúng thành giải pháp cho bất kỳ vấn đề nào khác. Đó là một cái nhìn sâu sắc lý thuyết có giá trị, nhưng nó không trả lời câu hỏi: trong số nhiều hình thức biểu diễn của đồng thuận này, cái nào hữu ích nhất trong thực tế?
Câu trả lời là hầu hết các hệ thống đồng thuận cung cấp log dùng chung, còn gọi là phát sóng tổng thứ tự (total order broadcast). Raft, Viewstamped Replication, và Zab cung cấp log dùng chung ngay ra khỏi hộp. Paxos cung cấp đồng thuận một giá trị, nhưng trong thực tế hầu hết các hệ thống sử dụng Paxos thực sự dùng phần mở rộng gọi là Multi-Paxos, cũng cung cấp log dùng chung.
Sử dụng log dùng chung
Một log dùng chung rất phù hợp cho nhân bản cơ sở dữ liệu: nếu mỗi mục log đại diện cho một lần ghi vào cơ sở dữ liệu, và mọi bản sao xử lý cùng các lần ghi theo cùng thứ tự bằng logic tất định, thì các bản sao sẽ đều kết thúc ở trạng thái nhất quán. Ý tưởng này được gọi là nhân bản máy trạng thái (state machine replication) 80, và đây là nguyên lý đằng sau event sourcing mà chúng ta đã thấy trong “Event Sourcing and CQRS”. Log dùng chung cũng hữu ích cho xử lý luồng (stream processing), như chúng ta sẽ thấy trong Chương 12.
Tương tự, một log dùng chung có thể được dùng để triển khai các giao dịch có thể tuần tự hóa (serializable transaction): như đã thảo luận trong “Actual Serial Execution”, nếu mỗi mục log đại diện cho một giao dịch tất định được thực thi như một stored procedure, và nếu mọi node thực thi những giao dịch đó theo cùng thứ tự, thì các giao dịch sẽ có thể tuần tự hóa 81 82.
Note
Các cơ sở dữ liệu phân mảnh với mô hình nhất quán mạnh thường duy trì một log riêng cho mỗi phân mảnh, điều này cải thiện khả năng mở rộng, nhưng hạn chế các đảm bảo nhất quán (ví dụ: snapshot nhất quán, tham chiếu khóa ngoài) mà chúng có thể cung cấp trên các phân mảnh. Các giao dịch có thể tuần tự hóa xuyên phân mảnh là có thể, nhưng đòi hỏi điều phối bổ sung 83.
Một log dùng chung cũng mạnh mẽ vì nó có thể dễ dàng được điều chỉnh sang các hình thức đồng thuận khác:
- Chúng ta đã thấy trước đó cách dùng nó để triển khai đồng thuận một giá trị và CAS: đơn giản là quyết định giá trị xuất hiện đầu tiên trong log.
- Nếu bạn muốn nhiều phiên bản của đồng thuận một giá trị (ví dụ: một phiên bản cho mỗi ghế trong rạp hát mà nhiều người đang cố đặt), hãy bao gồm số ghế trong các mục log, và quyết định mục log đầu tiên chứa số ghế đã cho.
- Nếu bạn muốn fetch-and-add nguyên tử, hãy đặt số cần thêm vào bộ đếm trong một mục log, và giá trị bộ đếm hiện tại là tổng của tất cả các mục log cho đến nay. Một bộ đếm đơn giản trên các mục log có thể được dùng để tạo ra các token hàng rào (fencing token) (xem “Fencing off zombies and delayed requests”); ví dụ, trong ZooKeeper, số thứ tự này được gọi là
zxid18.
Từ nhân bản leader đơn đến đồng thuận
Chúng ta đã thấy trước đó rằng đồng thuận một giá trị dễ dàng nếu bạn có một node “độc tài” đưa ra quyết định, và tương tự một log dùng chung dễ dàng nếu một leader duy nhất là node duy nhất được phép thêm các mục vào nó. Câu hỏi là làm thế nào để cung cấp khả năng chịu lỗi nếu node đó hỏng.
Theo truyền thống, các cơ sở dữ liệu với nhân bản leader đơn không giải quyết vấn đề này: họ để failover leader là hành động mà người quản trị viên phải thực hiện thủ công. Thật không may, điều này có nghĩa là một lượng thời gian chết đáng kể, vì có giới hạn về tốc độ con người có thể phản ứng, và nó không thỏa mãn tính chất kết thúc của đồng thuận. Đối với đồng thuận, chúng ta yêu cầu thuật toán có thể tự động chọn một leader mới. (Không phải tất cả các thuật toán đồng thuận đều có leader, nhưng các thuật toán thường dùng thì có 84.)
Tuy nhiên, có một vấn đề. Chúng ta đã thảo luận trước đó về vấn đề split brain, và nói rằng tất cả các node cần đồng ý về ai là leader, nếu không hai node khác nhau có thể mỗi node tin mình là leader, và do đó đưa ra các quyết định không nhất quán. Do đó, có vẻ như chúng ta cần đồng thuận để bầu chọn leader, và chúng ta cần leader để giải quyết đồng thuận. Làm thế nào để thoát khỏi bế tắc này?
Thực ra, các thuật toán đồng thuận không yêu cầu rằng chỉ có một leader tại bất kỳ thời điểm nào. Thay vào đó, chúng đưa ra một đảm bảo yếu hơn: chúng định nghĩa một số epoch (epoch number) (được gọi là số ballot trong Paxos, epoch, thì leader là duy nhất.
Khi một node tin rằng leader hiện tại đã chết vì không nhận được tín hiệu từ leader trong một khoảng thời gian chờ nhất định, nó có thể bắt đầu một cuộc bỏ phiếu để bầu leader mới. Cuộc bầu cử này được gán một epoch number mới lớn hơn bất kỳ epoch nào trước đó. Nếu có xung đột giữa hai leader khác nhau ở hai epoch khác nhau (có thể vì leader cũ thực ra chưa chết), thì leader có epoch number cao hơn sẽ thắng.
Trước khi một leader được phép thêm entry tiếp theo vào shared log, nó phải kiểm tra xem có leader nào khác với epoch number cao hơn có thể thêm một entry khác không. Nó có thể làm điều này bằng cách thu thập phiếu bầu từ một quorum của các node, thường nhưng không nhất thiết là đa số các node 85. Một node chỉ bỏ phiếu “có” nếu nó không biết về bất kỳ leader nào khác có epoch number cao hơn.
Như vậy, chúng ta có hai vòng bỏ phiếu: một lần để chọn leader, và một lần nữa để bỏ phiếu cho đề xuất của leader về entry tiếp theo cần thêm vào log. Các quorum cho hai lần bỏ phiếu đó phải chồng lấp nhau: nếu một phiếu bầu cho đề xuất thành công, ít nhất một trong những node đã bỏ phiếu cho nó cũng phải đã tham gia vào cuộc bầu cử leader gần nhất thành công 85. Do đó, nếu phiếu bầu cho đề xuất được thông qua mà không tiết lộ epoch number cao hơn nào, leader hiện tại có thể kết luận rằng không có leader nào với epoch number cao hơn đã được bầu, và do đó nó có thể an toàn thêm entry đề xuất vào log 26 86.
Hai vòng bỏ phiếu này trông bề ngoài tương tự như two-phase commit (cam kết hai giai đoạn), nhưng chúng là các giao thức rất khác nhau. Trong các thuật toán đồng thuận, bất kỳ node nào cũng có thể bắt đầu một cuộc bầu cử và chỉ cần quorum của các node phản hồi; trong 2PC, chỉ có coordinator mới có thể yêu cầu bỏ phiếu, và nó cần phiếu “có” từ mọi người tham gia trước khi có thể commit.
Những khía cạnh tinh tế của đồng thuận
Cấu trúc cơ bản này là chung cho tất cả Raft, Multi-Paxos, Zab và Viewstamped Replication: một phiếu bầu của quorum các node bầu ra leader, và sau đó một cuộc bỏ phiếu quorum khác được yêu cầu cho mỗi entry mà leader muốn thêm vào log 68 69. Mỗi log entry mới được đồng bộ sao chép đến một quorum của các node trước khi được xác nhận với client đã yêu cầu ghi. Điều này đảm bảo rằng log entry sẽ không bị mất nếu leader hiện tại bị lỗi.
Tuy nhiên, ma quỷ nằm ở những chi tiết, và đó cũng là nơi các thuật toán này có các cách tiếp cận khác nhau. Ví dụ, khi leader cũ bị lỗi và một leader mới được bầu, thuật toán cần đảm bảo rằng leader mới tôn trọng bất kỳ log entry nào đã được thêm bởi leader cũ trước khi nó bị lỗi. Raft thực hiện điều này bằng cách chỉ cho phép một node trở thành leader mới nếu log của nó ít nhất cập nhật như đa số người theo dõi của nó 69. Ngược lại, Paxos cho phép bất kỳ node nào trở thành leader mới, nhưng yêu cầu nó đồng bộ log với các node khác trước khi có thể bắt đầu thêm các entry mới của chính nó.
TÍNH NHẤT QUÁN VÀ TÍNH KHẢ DỤNG TRONG BẦU CỬ LEADER
Nếu bạn muốn thuật toán đồng thuận đảm bảo nghiêm ngặt các thuộc tính được đề ra trong “Shared logs as consensus”, điều cần thiết là leader mới phải cập nhật với bất kỳ log entry đã được xác nhận nào trước khi nó có thể xử lý bất kỳ lần ghi hoặc đọc tuyến tính hóa nào. Nếu một node có dữ liệu lỗi thời trở thành leader mới, nó có thể ghi một giá trị mới vào các log entry đã được ghi bởi leader cũ, vi phạm thuộc tính chỉ-thêm của shared log.
Trong một số trường hợp, bạn có thể chọn làm yếu đi các thuộc tính đồng thuận để khôi phục nhanh hơn sau lỗi leader. Ví dụ, Kafka cung cấp tùy chọn bật unclean leader election (bầu cử leader không sạch), cho phép bất kỳ replica nào trở thành leader, ngay cả khi nó không cập nhật. Ngoài ra, trong các cơ sở dữ liệu có sao chép không đồng bộ, bạn không thể đảm bảo rằng bất kỳ follower nào cập nhật khi leader bị lỗi.
Nếu bạn bỏ yêu cầu leader mới phải cập nhật, bạn có thể cải thiện hiệu suất và tính khả dụng, nhưng bạn đang đứng trên băng mỏng, vì lý thuyết đồng thuận không còn áp dụng nữa. Trong khi mọi thứ sẽ hoạt động tốt miễn là không có lỗi, các vấn đề đã thảo luận trong Chương 9 có thể dễ dàng gây ra nhiều mất mát hoặc hỏng dữ liệu.
Một điểm tinh tế khác là cách các thuật toán xử lý các log entry đã được đề xuất bởi leader cũ trước khi nó bị lỗi, nhưng cuộc bỏ phiếu để thêm vào log chưa hoàn thành. Bạn có thể tìm thấy các thảo luận về những chi tiết này trong các tài liệu tham khảo cho chương này 23 69 86.
Đối với các cơ sở dữ liệu sử dụng thuật toán đồng thuận để sao chép, không chỉ các lần ghi cần được chuyển thành log entry và sao chép đến quorum. Nếu bạn muốn đảm bảo các lần đọc tuyến tính hóa, chúng cũng phải trải qua phiếu bầu quorum tương tự như một lần ghi, để xác nhận rằng node tin rằng mình là leader thực sự vẫn còn cập nhật. Các lần đọc tuyến tính hóa trong etcd hoạt động như thế này, chẳng hạn.
Ở dạng tiêu chuẩn, hầu hết các thuật toán đồng thuận giả định một tập hợp node cố định, nghĩa là các node có thể bị tắt và khởi động lại, nhưng tập hợp các node được phép bỏ phiếu là cố định khi cluster được tạo. Trong thực tế, thường cần thiết phải thêm node mới hoặc xóa node cũ trong cấu hình hệ thống. Các thuật toán đồng thuận đã được mở rộng với các tính năng reconfiguration (cấu hình lại) để làm cho điều này trở nên khả thi. Điều này đặc biệt hữu ích khi thêm vùng mới vào hệ thống, hoặc khi di chuyển từ một vị trí sang vị trí khác (bằng cách thêm node mới trước, sau đó xóa node cũ).
Ưu và nhược điểm của đồng thuận
Mặc dù phức tạp và tinh tế, các thuật toán đồng thuận là một bước đột phá lớn cho các hệ thống phân tán. Đồng thuận về cơ bản là “single-leader replication (sao chép một leader) được thực hiện đúng”, với tự động chuyển đổi dự phòng khi leader bị lỗi, đảm bảo rằng không có dữ liệu đã cam kết nào bị mất và không thể xảy ra tình trạng split-brain (phân mảnh não), ngay cả khi đối mặt với tất cả các vấn đề chúng ta đã thảo luận trong Chương 9.
Vì sao chép một leader với tự động chuyển đổi dự phòng về cơ bản là một trong các định nghĩa của đồng thuận, bất kỳ hệ thống nào cung cấp tự động chuyển đổi dự phòng nhưng không sử dụng thuật toán đồng thuận đã được chứng minh đều có khả năng không an toàn 87. Sử dụng thuật toán đồng thuận đã được chứng minh không phải là sự đảm bảo tính đúng đắn của toàn bộ hệ thống, vì vẫn còn nhiều nơi khác mà lỗi có thể ẩn náu, nhưng đó là một khởi đầu tốt.
Tuy nhiên, đồng thuận không được sử dụng ở khắp mọi nơi, vì những lợi ích đi kèm với chi phí. Các hệ thống đồng thuận luôn yêu cầu một đa số nghiêm ngặt để hoạt động: ba node để chịu được một lỗi, hoặc năm node để chịu được hai lỗi. Mỗi thao tác cần giao tiếp với một quorum, vì vậy bạn không thể tăng thông lượng bằng cách thêm nhiều node hơn (trên thực tế, mỗi node bạn thêm làm cho thuật toán chậm hơn). Nếu một phân vùng mạng cắt đứt một số node khỏi phần còn lại, chỉ có phần đa số của mạng có thể tiếp tục tiến triển, còn lại bị chặn.
Các hệ thống đồng thuận thường dựa vào timeout (thời gian chờ) để phát hiện các node bị lỗi. Trong các môi trường có độ trễ mạng biến đổi cao, đặc biệt là các hệ thống phân tán qua nhiều vùng địa lý, có thể khó điều chỉnh các timeout này: nếu chúng quá lớn thì mất nhiều thời gian để khôi phục sau lỗi; nếu chúng quá nhỏ thì có thể có nhiều cuộc bầu cử leader không cần thiết, dẫn đến hiệu suất tệ vì hệ thống có thể kết thúc dành nhiều thời gian hơn để chọn leader hơn là làm công việc hữu ích.
Đôi khi, các thuật toán đồng thuận đặc biệt nhạy cảm với các vấn đề mạng. Ví dụ, Raft đã được chứng minh có các trường hợp biên không dễ chịu 88 89: nếu toàn bộ mạng hoạt động đúng ngoại trừ một liên kết mạng cụ thể liên tục không đáng tin cậy, Raft có thể rơi vào các tình huống mà quyền lãnh đạo liên tục bật qua lại giữa hai node, hoặc leader hiện tại liên tục bị buộc từ chức, vì vậy hệ thống thực sự không bao giờ tiến triển. Thiết kế các thuật toán mạnh mẽ hơn với mạng không đáng tin cậy vẫn là một vấn đề nghiên cứu mở.
Đối với các hệ thống muốn có tính khả dụng cao, nhưng không muốn chấp nhận chi phí của đồng thuận, sự thay thế thực sự duy nhất là sử dụng mô hình nhất quán yếu hơn, chẳng hạn như những mô hình được cung cấp bởi sao chép không leader hoặc đa leader như đã thảo luận trong Chương 6. Các cách tiếp cận này thường không cung cấp tuyến tính hóa, nhưng đối với các ứng dụng không cần nó thì điều đó không sao.
Dịch vụ phối hợp
Các thuật toán đồng thuận hữu ích trong bất kỳ cơ sở dữ liệu phân tán nào muốn cung cấp các thao tác tuyến tính hóa, và nhiều cơ sở dữ liệu phân tán hiện đại sử dụng thuật toán đồng thuận để sao chép. Nhưng một họ hệ thống là người dùng đặc biệt nổi bật của đồng thuận: coordination services (dịch vụ phối hợp) như ZooKeeper, etcd hoặc Consul. Mặc dù các hệ thống này trông bề ngoài giống như bất kỳ kho key-value nào khác, chúng không được thiết kế để lưu trữ dữ liệu đa năng như hầu hết các cơ sở dữ liệu.
Thay vào đó, chúng được thiết kế để phối hợp giữa các node của một hệ thống phân tán khác. Ví dụ, Kubernetes phụ thuộc vào etcd, trong khi Spark và Flink ở chế độ khả dụng cao phụ thuộc vào ZooKeeper chạy ở nền. Các dịch vụ phối hợp được thiết kế để giữ lượng nhỏ dữ liệu có thể vừa hoàn toàn trong bộ nhớ (mặc dù chúng vẫn ghi vào đĩa để đảm bảo độ bền), được sao chép qua nhiều node sử dụng thuật toán đồng thuận chịu lỗi.
Các dịch vụ phối hợp được mô hình hóa theo dịch vụ khóa Chubby của Google 17 58. Chúng kết hợp thuật toán đồng thuận với một số tính năng khác hóa ra đặc biệt hữu ích khi xây dựng các hệ thống phân tán:
- Locks và leases (khóa và thuê)
- Chúng ta đã thấy trước đó cách các hệ thống đồng thuận có thể thực hiện một thao tác compare-and-set (CAS) nguyên tử, chịu lỗi. Các dịch vụ phối hợp dựa vào cách tiếp cận này để thực hiện khóa và leases: nếu nhiều node đồng thời cố gắng thu được cùng một lease, chỉ một trong số chúng sẽ thành công.
- Hỗ trợ fencing
- Như đã thảo luận trong “Distributed Locks and Leases”, khi một tài nguyên được bảo vệ bởi lease, bạn
cần fencing (hàng rào) để ngăn các client can thiệp lẫn nhau trong trường hợp tạm dừng tiến trình hoặc độ trễ mạng lớn. Các hệ thống đồng thuận có thể tạo fencing token bằng cách gán cho mỗi log entry một ID tăng đơn điệu (
zxidvàcversiontrong ZooKeeper, số phiên bản trong etcd). - Phát hiện lỗi
- Các client duy trì một phiên dài hạn trên dịch vụ phối hợp và định kỳ trao đổi heartbeat để kiểm tra xem node kia còn sống không. Ngay cả khi kết nối tạm thời bị gián đoạn hoặc máy chủ bị lỗi, bất kỳ lease nào do client nắm giữ vẫn còn hiệu lực. Tuy nhiên, nếu không có heartbeat lâu hơn timeout của lease, dịch vụ phối hợp cho rằng client đã chết và giải phóng lease (ZooKeeper gọi những thứ này là ephemeral nodes, nghĩa là các node tạm thời).
- Thông báo thay đổi
- Một client có thể yêu cầu dịch vụ phối hợp gửi cho nó thông báo bất cứ khi nào một số key thay đổi. Điều này cho phép client biết khi nào một client khác tham gia cluster (dựa trên giá trị mà nó ghi vào dịch vụ phối hợp), hoặc nếu một client khác bị lỗi (vì phiên của nó hết thời gian chờ và các ephemeral node của nó biến mất), chẳng hạn. Những thông báo này giúp client không phải thường xuyên thăm dò dịch vụ để tìm hiểu về các thay đổi.
Phát hiện lỗi và thông báo thay đổi không yêu cầu đồng thuận, nhưng chúng hữu ích để phối hợp phân tán cùng với các thao tác nguyên tử và hỗ trợ fencing cần có đồng thuận.
QUẢN LÝ CẤU HÌNH VỚI CÁC DỊCH VỤ PHỐI HỢP
Các ứng dụng và cơ sở hạ tầng thường có các tham số cấu hình như timeout, kích thước thread pool, v.v. Các dịch vụ phối hợp đôi khi được sử dụng để lưu trữ dữ liệu cấu hình như vậy, được biểu diễn dưới dạng cặp key-value. Các tiến trình tải cài đặt mới nhất khi khởi động và đăng ký nhận thông báo về bất kỳ thay đổi nào. Khi cấu hình thay đổi, tiến trình có thể bắt đầu sử dụng cài đặt mới ngay lập tức hoặc tự khởi động lại để tải các thay đổi mới nhất.
Quản lý cấu hình không cần khía cạnh đồng thuận của dịch vụ phối hợp, nhưng sẽ thuận tiện khi sử dụng dịch vụ phối hợp và dựa vào tính năng thông báo của nó nếu bạn đã chạy dịch vụ phối hợp dù sao. Ngoài ra, một tiến trình có thể định kỳ thăm dò các bản cập nhật cấu hình từ một tệp hoặc URL, điều này tránh nhu cầu về một dịch vụ chuyên dụng.
Phân công công việc cho các node
Dịch vụ phối hợp hữu ích nếu bạn có nhiều thực thể của một tiến trình hoặc dịch vụ, và một trong số chúng cần được chọn làm leader hoặc primary. Nếu leader bị lỗi, một trong các node khác nên tiếp quản. Điều này cần thiết cho các cơ sở dữ liệu single-leader, nhưng nó cũng phù hợp cho các bộ lập lịch công việc và các hệ thống stateful (có trạng thái) tương tự.
Một trường hợp sử dụng khác là khi bạn có một số tài nguyên được phân mảnh (cơ sở dữ liệu, luồng tin nhắn, lưu trữ tệp, hệ thống actor phân tán, v.v.) và cần quyết định shard nào được gán cho node nào. Khi các node mới tham gia cluster, một số shard cần được chuyển từ các node hiện có sang các node mới để cân bằng lại tải. Khi các node bị xóa hoặc bị lỗi, các node khác cần tiếp quản công việc của các node bị lỗi.
Các loại nhiệm vụ này có thể được thực hiện bằng cách sử dụng khéo léo các thao tác nguyên tử, ephemeral node và thông báo trong dịch vụ phối hợp. Nếu được thực hiện đúng cách, cách tiếp cận này cho phép ứng dụng tự động khôi phục sau lỗi mà không cần can thiệp của con người. Không dễ dàng, mặc dù có các thư viện như Apache Curator đã xuất hiện để cung cấp các công cụ cấp cao hơn trên API client ZooKeeper, nhưng vẫn tốt hơn nhiều so với việc cố gắng tự triển khai các thuật toán đồng thuận cần thiết từ đầu, vốn rất dễ xảy ra lỗi.
Một dịch vụ phối hợp chuyên dụng cũng có lợi thế là nó có thể chạy trên một tập hợp node cố định (thường là ba hoặc năm), bất kể có bao nhiêu node trong hệ thống phân tán phụ thuộc vào nó để phối hợp. Ví dụ, trong một hệ thống lưu trữ với hàng nghìn shard, sẽ cực kỳ không hiệu quả khi chạy thuật toán đồng thuận qua hàng nghìn node; tốt hơn nhiều là “thuê ngoài” đồng thuận cho một số nhỏ node chạy dịch vụ phối hợp.
Thông thường, loại dữ liệu được quản lý bởi dịch vụ phối hợp thay đổi khá chậm: nó đại diện cho thông tin như “node chạy trên địa chỉ IP 10.1.1.23 là leader cho shard 7”, và các phân công như vậy thường thay đổi theo thang thời gian tính bằng phút hoặc giờ. Các dịch vụ phối hợp không được thiết kế để lưu trữ dữ liệu có thể thay đổi hàng nghìn lần mỗi giây. Đối với điều đó, tốt hơn là sử dụng cơ sở dữ liệu thông thường; ngoài ra, các công cụ như Apache BookKeeper 90 91 có thể được sử dụng để sao chép trạng thái nội bộ thay đổi nhanh của một dịch vụ.
Khám phá dịch vụ
ZooKeeper, etcd và Consul cũng thường được sử dụng cho service discovery (khám phá dịch vụ), nghĩa là để tìm ra địa chỉ IP nào bạn cần kết nối để đến được một dịch vụ cụ thể (xem “Load balancers, service discovery, and service meshes”). Trong các môi trường đám mây, nơi phổ biến việc các máy ảo liên tục xuất hiện và biến mất, bạn thường không biết địa chỉ IP của các dịch vụ trước thời gian. Thay vào đó, bạn có thể cấu hình các dịch vụ của mình sao cho khi chúng khởi động, chúng đăng ký các điểm cuối mạng của mình trong một service registry (sổ đăng ký dịch vụ), nơi chúng có thể được tìm thấy bởi các dịch vụ khác.
Sử dụng dịch vụ phối hợp cho khám phá dịch vụ có thể tiện lợi, vì các tính năng phát hiện lỗi và thông báo thay đổi của nó giúp client dễ dàng theo dõi các thực thể dịch vụ khi chúng xuất hiện và biến mất. Và nếu bạn đã sử dụng dịch vụ phối hợp cho leases, khóa hoặc bầu cử leader, thì có ý nghĩa khi cũng sử dụng nó cho khám phá dịch vụ, vì nó đã biết node nào nên nhận yêu cầu cho dịch vụ của bạn.
Tuy nhiên, sử dụng đồng thuận cho khám phá dịch vụ thường là quá mức cần thiết: trường hợp sử dụng này thường không yêu cầu tuyến tính hóa, và quan trọng hơn là khám phá dịch vụ phải có tính khả dụng cao và nhanh, vì nếu không có nó, mọi thứ sẽ dừng lại. Do đó, thường tốt hơn là lưu cache thông tin khám phá dịch vụ và chấp nhận rằng nó có thể hơi lỗi thời. Ví dụ, khám phá dịch vụ dựa trên DNS sử dụng nhiều lớp bộ nhớ đệm để đạt được hiệu suất và tính khả dụng tốt.
Để hỗ trợ trường hợp sử dụng này, ZooKeeper hỗ trợ observers (người quan sát), là các replica nhận log và duy trì một bản sao dữ liệu được lưu trữ trong ZooKeeper, nhưng không tham gia vào quá trình bỏ phiếu của thuật toán đồng thuận. Các lần đọc từ observer không phải là tuyến tính hóa vì chúng có thể lỗi thời, nhưng chúng vẫn có thể truy cập ngay cả khi mạng bị gián đoạn, và chúng tăng thông lượng đọc mà hệ thống có thể hỗ trợ bằng cách lưu cache.
Tóm tắt
Trong chương này, chúng ta đã xem xét chủ đề nhất quán mạnh trong các hệ thống chịu lỗi: nó là gì và cách đạt được nó. Chúng ta đã xem xét sâu về tuyến tính hóa, một hình thức hóa phổ biến của nhất quán mạnh: nó có nghĩa là dữ liệu được sao chép xuất hiện như thể chỉ có một bản sao duy nhất, và tất cả các thao tác tác động lên nó một cách nguyên tử. Chúng ta đã thấy rằng tuyến tính hóa hữu ích khi bạn cần một số dữ liệu phải cập nhật khi bạn đọc nó, hoặc nếu bạn cần giải quyết race condition (điều kiện chạy đua, ví dụ: nếu nhiều node đồng thời cố gắng làm cùng một việc, như tạo các tệp có cùng tên).
Mặc dù tuyến tính hóa hấp dẫn vì nó dễ hiểu, khiến cơ sở dữ liệu hoạt động như một biến trong chương trình đơn luồng, nó có nhược điểm là chậm, đặc biệt trong các môi trường có độ trễ mạng lớn. Nhiều thuật toán sao chép không đảm bảo tuyến tính hóa, mặc dù bề ngoài có vẻ như chúng có thể cung cấp nhất quán mạnh.
Tiếp theo, chúng ta áp dụng khái niệm tuyến tính hóa trong bối cảnh các bộ tạo ID. Một bộ đếm tự tăng trên một node là tuyến tính hóa, nhưng không chịu lỗi. Nhiều sơ đồ tạo ID phân tán không đảm bảo rằng các ID được sắp xếp nhất quán với thứ tự mà các sự kiện thực sự xảy ra. Các đồng hồ logic như Lamport clock và hybrid logical clock cung cấp thứ tự nhất quán với quan hệ nhân quả, nhưng không có tuyến tính hóa.
Điều này dẫn chúng ta đến khái niệm đồng thuận. Chúng ta đã thấy rằng đạt được đồng thuận có nghĩa là quyết định điều gì đó theo cách mà tất cả các node đồng ý về những gì đã được quyết định, và sao cho chúng không thể thay đổi quyết định. Một loạt các vấn đề thực sự có thể quy về đồng thuận và tương đương với nhau (nghĩa là nếu bạn có giải pháp cho một trong số chúng, bạn có thể chuyển đổi nó thành giải pháp cho tất cả các vấn đề còn lại). Các vấn đề tương đương như vậy bao gồm:
- Thao tác compare-and-set tuyến tính hóa
- Register cần nguyên tử quyết định có nên đặt giá trị của nó hay không, dựa trên việc giá trị hiện tại của nó có bằng tham số được đưa ra trong thao tác hay không.
- Locks và leases
- Khi nhiều client đồng thời cố gắng lấy lock hoặc lease, lock quyết định ai đã thu được thành công.
- Ràng buộc duy nhất
- Khi nhiều giao dịch đồng thời cố gắng tạo các bản ghi xung đột với cùng key, ràng buộc phải quyết định cho phép cái nào và cái nào nên thất bại với vi phạm ràng buộc.
- Shared log
- Khi nhiều node đồng thời muốn thêm entry vào log, log quyết định thứ tự mà chúng được thêm vào. Total order broadcast (phát sóng tổng thứ tự) cũng tương đương.
- Cam kết giao dịch nguyên tử
- Các node cơ sở dữ liệu tham gia vào một giao dịch phân tán phải tất cả quyết định theo cùng cách có commit hoặc hủy bỏ giao dịch.
- Thao tác fetch-and-add tuyến tính hóa
- Thao tác này có thể được sử dụng để triển khai bộ tạo ID. Nhiều node có thể đồng thời gọi thao tác, và nó quyết định thứ tự chúng tăng bộ đếm. Trường hợp này thực sự chỉ giải quyết đồng thuận giữa hai node, trong khi các trường hợp khác hoạt động cho bất kỳ số lượng node nào.
Tất cả những điều này đều đơn giản nếu bạn chỉ có một node, hoặc nếu bạn sẵn sàng giao khả năng ra quyết định cho một node duy nhất. Đây là những gì xảy ra trong cơ sở dữ liệu single-leader: tất cả quyền lực để đưa ra quyết định được trao cho leader, đó là lý do tại sao các cơ sở dữ liệu như vậy có thể cung cấp các thao tác tuyến tính hóa, ràng buộc duy nhất, replication log và nhiều hơn nữa.
Tuy nhiên, nếu leader duy nhất đó bị lỗi, hoặc nếu sự gián đoạn mạng làm cho leader không thể tiếp cận được, một hệ thống như vậy trở nên không thể tiến triển cho đến khi con người thực hiện chuyển đổi dự phòng thủ công. Các thuật toán đồng thuận được sử dụng rộng rãi như Raft và Paxos về cơ bản là sao chép single-leader với bầu cử leader tự động tích hợp và chuyển đổi dự phòng nếu leader hiện tại bị lỗi.
Các thuật toán đồng thuận được thiết kế cẩn thận để đảm bảo rằng không có dữ liệu đã cam kết nào bị mất trong quá trình chuyển đổi dự phòng, và hệ thống không thể rơi vào trạng thái split-brain trong đó nhiều node đang chấp nhận ghi. Điều này yêu cầu mỗi lần ghi, và mỗi lần đọc tuyến tính hóa, phải được xác nhận bởi quorum (thường là đa số) của các node. Điều này có thể tốn kém, đặc biệt là qua các vùng địa lý, nhưng không thể tránh khỏi nếu bạn muốn có nhất quán mạnh và khả năng chịu lỗi mà đồng thuận cung cấp.
Các dịch vụ phối hợp như ZooKeeper và etcd cũng được xây dựng trên các thuật toán đồng thuận. Chúng cung cấp các tính năng khóa, leases, phát hiện lỗi và thông báo thay đổi hữu ích để quản lý trạng thái của các ứng dụng phân tán. Nếu bạn thấy mình muốn làm một trong những việc có thể quy về đồng thuận, và bạn muốn nó chịu lỗi, thì nên sử dụng dịch vụ phối hợp. Nó sẽ không đảm bảo rằng bạn sẽ làm đúng, nhưng nó có lẽ sẽ giúp ích.
Các thuật toán đồng thuận phức tạp và tinh tế, nhưng chúng được hỗ trợ bởi một tập lý thuyết phong phú đã được phát triển từ những năm 1980. Lý thuyết này giúp có thể xây dựng các hệ thống có thể chịu được tất cả các lỗi mà chúng ta đã thảo luận trong Chương 9, và vẫn đảm bảo rằng dữ liệu của bạn không bị hỏng. Đây là một thành tựu đáng kinh ngạc, và các tài liệu tham khảo ở cuối chương này giới thiệu một số điểm nổi bật của công việc này.
Tuy nhiên, đồng thuận không phải lúc nào cũng là công cụ phù hợp: trong một số hệ thống, các thuộc tính nhất quán mạnh mà nó cung cấp không cần thiết, và tốt hơn là có nhất quán yếu hơn với tính khả dụng cao hơn và hiệu suất tốt hơn. Trong những trường hợp này, thường sử dụng sao chép không leader hoặc đa leader, mà chúng ta đã thảo luận trước đây trong Chương 6. Các đồng hồ logic mà chúng ta đã thảo luận trong chương này hữu ích trong bối cảnh đó.
Tài liệu tham khảo
Maurice P. Herlihy and Jeannette M. Wing. Linearizability: A Correctness Condition for Concurrent Objects. ACM Transactions on Programming Languages and Systems (TOPLAS), volume 12, issue 3, pages 463–492, July 1990. doi:10.1145/78969.78972 ↩︎ ↩︎
Leslie Lamport. On interprocess communication. Distributed Computing, volume 1, issue 2, pages 77–101, June 1986. doi:10.1007/BF01786228 ↩︎
David K. Gifford. Information Storage in a Decentralized Computer System. Xerox Palo Alto Research Centers, CSL-81-8, June 1981. Archived at perma.cc/2XXP-3JPB ↩︎
Martin Kleppmann. Please Stop Calling Databases CP or AP. martin.kleppmann.com, May 2015. Archived at perma.cc/MJ5G-75GL ↩︎ ↩︎ ↩︎
Kyle Kingsbury. Call Me Maybe: MongoDB Stale Reads. aphyr.com, April 2015. Archived at perma.cc/DXB4-J4JC ↩︎
Kyle Kingsbury. Computational Techniques in Knossos. aphyr.com, May 2014. Archived at perma.cc/2X5M-EHTU ↩︎
Kyle Kingsbury and Peter Alvaro. Elle: Inferring Isolation Anomalies from Experimental Observations. Proceedings of the VLDB Endowment, volume 14, issue 3, pages 268–280, November 2020. doi:10.14778/3430915.3430918 ↩︎
Paolo Viotti and Marko Vukolić. Consistency in Non-Transactional Distributed Storage Systems. ACM Computing Surveys (CSUR), volume 49, issue 1, article no. 19, June 2016. doi:10.1145/2926965 ↩︎ ↩︎
Peter Bailis. Linearizability Versus Serializability. bailis.org, September 2014. Archived at perma.cc/386B-KAC3 ↩︎
Daniel Abadi. Correctness Anomalies Under Serializable Isolation. dbmsmusings.blogspot.com, June 2019. Archived at perma.cc/JGS7-BZFY ↩︎
Peter Bailis, Aaron Davidson, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Highly Available Transactions: Virtues and Limitations. Proceedings of the VLDB Endowment, volume 7, issue 3, pages 181–192, November 2013. doi:10.14778/2732232.2732237, extended version published as arXiv:1302.0309 ↩︎
Philip A. Bernstein, Vassos Hadzilacos, and Nathan Goodman. Concurrency Control and Recovery in Database Systems. Addison-Wesley, 1987. ISBN: 978-0-201-10715-9, available online at microsoft.com. ↩︎
Andrei Matei. CockroachDB’s consistency model. cockroachlabs.com, February 2021. Archived at perma.cc/MR38-883B ↩︎
Murat Demirbas. Strict-serializability, but at what cost, for what purpose? muratbuffalo.blogspot.com, August 2022. Archived at perma.cc/T8AY-N3U9 ↩︎
Ben Darnell. How to talk about consistency and isolation in distributed DBs. cockroachlabs.com, February 2022. Archived at perma.cc/53SV-JBGK ↩︎
Daniel Abadi. An explanation of the difference between Isolation levels vs. Consistency levels. dbmsmusings.blogspot.com, August 2019. Archived at perma.cc/QSF2-CD4P ↩︎
Mike Burrows. The Chubby Lock Service for Loosely-Coupled Distributed Systems. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006. ↩︎ ↩︎
Flavio P. Junqueira and Benjamin Reed. ZooKeeper: Distributed Process Coordination. O’Reilly Media, 2013. ISBN: 978-1-449-36130-3 ↩︎ ↩︎ ↩︎ ↩︎
Murali Vallath. Oracle 10g RAC Grid, Services & Clustering. Elsevier Digital Press, 2006. ISBN: 978-1-555-58321-7 ↩︎ ↩︎
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. Coordination Avoidance in Database Systems. Proceedings of the VLDB Endowment, volume 8, issue 3, pages 185–196, November 2014. doi:10.14778/2735508.2735509 ↩︎
Kyle Kingsbury. Call Me Maybe: etcd and Consul. aphyr.com, June 2014. Archived at perma.cc/XL7U-378K ↩︎
Flavio P. Junqueira, Benjamin C. Reed, and Marco Serafini. Zab: High-Performance Broadcast for Primary-Backup Systems. At 41st IEEE International Conference on Dependable Systems and Networks (DSN), June 2011. doi:10.1109/DSN.2011.5958223 ↩︎ ↩︎
Diego Ongaro and John K. Ousterhout. In Search of an Understandable Consensus Algorithm. At USENIX Annual Technical Conference (ATC), June 2014. ↩︎ ↩︎ ↩︎
Hagit Attiya, Amotz Bar-Noy, and Danny Dolev. Sharing Memory Robustly in Message-Passing Systems. Journal of the ACM, volume 42, issue 1, pages 124–142, January 1995. doi:10.1145/200836.200869 ↩︎ ↩︎
Nancy Lynch and Alex Shvartsman. Robust Emulation of Shared Memory Using Dynamic Quorum-Acknowledged Broadcasts. At 27th Annual International Symposium on Fault-Tolerant Computing (FTCS), June 1997. doi:10.1109/FTCS.1997.614100 ↩︎ ↩︎
Christian Cachin, Rachid Guerraoui, and Luís Rodrigues. Introduction to Reliable and Secure Distributed Programming, 2nd edition. Springer, 2011. ISBN: 978-3-642-15259-7, doi:10.1007/978-3-642-15260-3 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Niklas Ekström, Mikhail Panchenko, and Jonathan Ellis. Possible Issue with Read Repair? Email thread on cassandra-dev mailing list, October 2012. ↩︎
Maurice P. Herlihy. Wait-Free Synchronization. ACM Transactions on Programming Languages and Systems (TOPLAS), volume 13, issue 1, pages 124–149, January 1991. doi:10.1145/114005.102808 ↩︎ ↩︎ ↩︎ ↩︎
Armando Fox and Eric A. Brewer. Harvest, Yield, and Scalable Tolerant Systems. At 7th Workshop on Hot Topics in Operating Systems (HotOS), March 1999. doi:10.1109/HOTOS.1999.798396 ↩︎
Seth Gilbert and Nancy Lynch. Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services. ACM SIGACT News, volume 33, issue 2, pages 51–59, June 2002. doi:10.1145/564585.564601 ↩︎ ↩︎ ↩︎
Seth Gilbert and Nancy Lynch. Perspectives on the CAP Theorem. IEEE Computer Magazine, volume 45, issue 2, pages 30–36, February 2012. doi:10.1109/MC.2011.389 ↩︎
Eric A. Brewer. CAP Twelve Years Later: How the ‘Rules’ Have Changed. IEEE Computer Magazine, volume 45, issue 2, pages 23–29, February 2012. doi:10.1109/MC.2012.37 ↩︎ ↩︎
Susan B. Davidson, Hector Garcia-Molina, and Dale Skeen. Consistency in Partitioned Networks. ACM Computing Surveys, volume 17, issue 3, pages 341–370, September 1985. doi:10.1145/5505.5508 ↩︎
Paul R. Johnson and Robert H. Thomas. RFC 677: The Maintenance of Duplicate Databases. Network Working Group, January 1975. ↩︎
Michael J. Fischer and Alan Michael. Sacrificing Serializability to Attain High Availability of Data in an Unreliable Network. At 1st ACM Symposium on Principles of Database Systems (PODS), March 1982. doi:10.1145/588111.588124 ↩︎
Eric A. Brewer. NoSQL: Past, Present, Future. At QCon San Francisco, November 2012. ↩︎
Adrian Cockcroft. Migrating to Microservices. At QCon London, March 2014. ↩︎
Martin Kleppmann. A Critique of the CAP Theorem. arXiv:1509.05393, September 2015. ↩︎ ↩︎
Daniel Abadi. Problems with CAP, and Yahoo’s little known NoSQL system. dbmsmusings.blogspot.com, April 2010. Archived at perma.cc/4NTZ-CLM9 ↩︎ ↩︎ ↩︎
Daniel Abadi. Hazelcast and the Mythical PA/EC System. dbmsmusings.blogspot.com, October 2017. Archived at perma.cc/J5XM-U5C2 ↩︎ ↩︎
Eric Brewer. Spanner, TrueTime & The CAP Theorem. research.google.com, February 2017. Archived at perma.cc/59UW-RH7N ↩︎
Daniel J. Abadi. Consistency Tradeoffs in Modern Distributed Database System Design. IEEE Computer Magazine, volume 45, issue 2, pages 37–42, February 2012. doi:10.1109/MC.2012.33 ↩︎ ↩︎
Nancy A. Lynch. A Hundred Impossibility Proofs for Distributed Computing. At 8th ACM Symposium on Principles of Distributed Computing (PODC), August 1989. doi:10.1145/72981.72982 ↩︎
Prince Mahajan, Lorenzo Alvisi, and Mike Dahlin. Consistency, Availability, and Convergence. University of Texas at Austin, Department of Computer Science, Tech Report UTCS TR-11-22, May 2011. Archived at perma.cc/SAV8-9JAJ ↩︎
Hagit Attiya, Faith Ellen, and Adam Morrison. Limitations of Highly-Available Eventually-Consistent Data Stores. At ACM Symposium on Principles of Distributed Computing (PODC), July 2015. doi:10.1145/2767386.2767419 ↩︎
Peter Sewell, Susmit Sarkar, Scott Owens, Francesco Zappa Nardelli, and Magnus O. Myreen. x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors. Communications of the ACM, volume 53, issue 7, pages 89–97, July 2010. doi:10.1145/1785414.1785443 ↩︎
Martin Thompson. Memory Barriers/Fences. mechanical-sympathy.blogspot.co.uk, July 2011. Archived at perma.cc/7NXM-GC5U ↩︎
Ulrich Drepper. What Every Programmer Should Know About Memory. akkadia.org, November 2007. Archived at perma.cc/NU6Q-DRXZ ↩︎
Hagit Attiya and Jennifer L. Welch. Sequential Consistency Versus Linearizability. ACM Transactions on Computer Systems (TOCS), volume 12, issue 2, pages 91–122, May 1994. doi:10.1145/176575.176576 ↩︎
Kyzer R. Davis, Brad G. Peabody, and Paul J. Leach. Universally Unique IDentifiers (UUIDs). RFC 9562, IETF, May 2024. ↩︎ ↩︎
Ryan King. Announcing Snowflake. blog.x.com, June 2010. Archived at archive.org ↩︎
Alizain Feerasta. Universally Unique Lexicographically Sortable Identifier. github.com, 2016. Archived at perma.cc/NV2Y-ZP8U ↩︎
Rob Conery. A Better ID Generator for PostgreSQL. bigmachine.io, May 2014. Archived at perma.cc/K7QV-3KFC ↩︎
Leslie Lamport. Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, volume 21, issue 7, pages 558–565, July 1978. doi:10.1145/359545.359563 ↩︎ ↩︎
Sandeep S. Kulkarni, Murat Demirbas, Deepak Madeppa, Bharadwaj Avva, and Marcelo Leone. Logical Physical Clocks. 18th International Conference on Principles of Distributed Systems (OPODIS), December 2014. doi:10.1007/978-3-319-14472-6_2 ↩︎
Manuel Bravo, Nuno Diegues, Jingna Zeng, Paolo Romano, and Luís Rodrigues. On the use of Clocks to Enforce Consistency in the Cloud. IEEE Data Engineering Bulletin, volume 38, issue 1, pages 18–31, March 2015. Archived at perma.cc/68ZU-45SH ↩︎
Daniel Peng and Frank Dabek. Large-Scale Incremental Processing Using Distributed Transactions and Notifications. At 9th USENIX Conference on Operating Systems Design and Implementation (OSDI), October 2010. ↩︎
Tushar Deepak Chandra, Robert Griesemer, and Joshua Redstone. Paxos Made Live – An Engineering Perspective. At 26th ACM Symposium on Principles of Distributed Computing (PODC), June 2007. doi:10.1145/1281100.1281103 ↩︎ ↩︎ ↩︎
Will Portnoy. Lessons Learned from Implementing Paxos. blog.willportnoy.com, June 2012. Archived at perma.cc/QHD9-FDD2 ↩︎
Brian M. Oki and Barbara H. Liskov. Viewstamped Replication: A New Primary Copy Method to Support Highly-Available Distributed Systems. At 7th ACM Symposium on Principles of Distributed Computing (PODC), August 1988. doi:10.1145/62546.62549 ↩︎
Barbara H. Liskov and James Cowling. Viewstamped Replication Revisited. Massachusetts Institute of Technology, Tech Report MIT-CSAIL-TR-2012-021, July 2012. Archived at perma.cc/56SJ-WENQ ↩︎
Leslie Lamport. The Part-Time Parliament. ACM Transactions on Computer Systems, volume 16, issue 2, pages 133–169, May 1998. doi:10.1145/279227.279229 ↩︎
Leslie Lamport. Paxos Made Simple. ACM SIGACT News, volume 32, issue 4, pages 51–58, December 2001. Archived at perma.cc/82HP-MNKE ↩︎
Robbert van Renesse and Deniz Altinbuken. Paxos Made Moderately Complex. ACM Computing Surveys (CSUR), volume 47, issue 3, article no. 42, February 2015. doi:10.1145/2673577 ↩︎
Diego Ongaro. Consensus: Bridging Theory and Practice. PhD Thesis, Stanford University, August 2014. Archived at perma.cc/5VTZ-2ADH ↩︎
Heidi Howard, Malte Schwarzkopf, Anil Madhavapeddy, and Jon Crowcroft. Raft Refloated: Do We Have Consensus? ACM SIGOPS Operating Systems Review, volume 49, issue 1, pages 12–21, January 2015. doi:10.1145/2723872.2723876 ↩︎
André Medeiros. ZooKeeper’s Atomic Broadcast Protocol: Theory and Practice. Aalto University School of Science, March 2012. Archived at perma.cc/FVL4-JMVA ↩︎
Robbert van Renesse, Nicolas Schiper, and Fred B. Schneider. Vive La Différence: Paxos vs. Viewstamped Replication vs. Zab. IEEE Transactions on Dependable and Secure Computing, volume 12, issue 4, pages 472–484, September 2014. doi:10.1109/TDSC.2014.2355848 ↩︎ ↩︎
Heidi Howard and Richard Mortier. Paxos vs Raft: Have we reached consensus on distributed consensus?. At 7th Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC), April 2020. doi:10.1145/3380787.3393681 ↩︎ ↩︎ ↩︎ ↩︎
Miguel Castro and Barbara H. Liskov. Practical Byzantine Fault Tolerance and Proactive Recovery. ACM Transactions on Computer Systems, volume 20, issue 4, pages 396–461, November 2002. doi:10.1145/571637.571640 ↩︎
Shehar Bano, Alberto Sonnino, Mustafa Al-Bassam, Sarah Azouvi, Patrick McCorry, Sarah Meiklejohn, and George Danezis. SoK: Consensus in the Age of Blockchains. At 1st ACM Conference on Advances in Financial Technologies (AFT), October 2019. doi:10.1145/3318041.3355458 ↩︎
Michael J. Fischer, Nancy Lynch, and Michael S. Paterson. Impossibility of Distributed Consensus with One Faulty Process. Journal of the ACM, volume 32, issue 2, pages 374–382, April 1985. doi:10.1145/3149.214121 ↩︎ ↩︎
Tushar Deepak Chandra and Sam Toueg. Unreliable Failure Detectors for Reliable Distributed Systems. Journal of the ACM, volume 43, issue 2, pages 225–267, March 1996. doi:10.1145/226643.226647 ↩︎ ↩︎ ↩︎ ↩︎
Michael Ben-Or. Another Advantage of Free Choice: Completely Asynchronous Agreement Protocols. At 2nd ACM Symposium on Principles of Distributed Computing (PODC), August 1983. doi:10.1145/800221.806707 ↩︎
Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer. Consensus in the Presence of Partial Synchrony. Journal of the ACM, volume 35, issue 2, pages 288–323, April 1988. doi:10.1145/42282.42283 ↩︎
Xavier Défago, André Schiper, and Péter Urbán. Total Order Broadcast and Multicast Algorithms: Taxonomy and Survey. ACM Computing Surveys, volume 36, issue 4, pages 372–421, December 2004. doi:10.1145/1041680.1041682 ↩︎
Hagit Attiya and Jennifer Welch. Distributed Computing: Fundamentals, Simulations and Advanced Topics, 2nd edition. John Wiley & Sons, 2004. ISBN: 978-0-471-45324-6, doi:10.1002/0471478210 ↩︎
Rachid Guerraoui. Revisiting the Relationship Between Non-Blocking Atomic Commitment and Consensus. At 9th International Workshop on Distributed Algorithms (WDAG), September 1995. doi:10.1007/BFb0022140 ↩︎ ↩︎
Jim N. Gray and Leslie Lamport. Consensus on Transaction Commit. ACM Transactions on Database Systems (TODS), volume 31, issue 1, pages 133–160, March 2006. doi:10.1145/1132863.1132867 ↩︎
Fred B. Schneider. Implementing Fault-Tolerant Services Using the State Machine Approach: A Tutorial. ACM Computing Surveys, volume 22, issue 4, pages 299–319, December 1990. doi:10.1145/98163.98167 ↩︎
Alexander Thomson, Thaddeus Diamond, Shu-Chun Weng, Kun Ren, Philip Shao, and Daniel J. Abadi. Calvin: Fast Distributed Transactions for Partitioned Database Systems. At ACM International Conference on Management of Data (SIGMOD), May 2012. doi:10.1145/2213836.2213838 ↩︎
Mahesh Balakrishnan, Dahlia Malkhi, Ted Wobber, Ming Wu, Vijayan Prabhakaran, Michael Wei, John D. Davis, Sriram Rao, Tao Zou, and Aviad Zuck. Tango: Distributed Data Structures over a Shared Log. At 24th ACM Symposium on Operating Systems Principles (SOSP), November 2013. doi:10.1145/2517349.2522732 ↩︎
Mahesh Balakrishnan, Dahlia Malkhi, Vijayan Prabhakaran, Ted Wobber, Michael Wei, and John D. Davis. CORFU: A Shared Log Design for Flash Clusters. At 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), April 2012. ↩︎
Vasilis Gavrielatos, Antonios Katsarakis, and Vijay Nagarajan. Odyssey: the impact of modern hardware on strongly-consistent replication protocols. At 16th European Conference on Computer Systems (EuroSys), April 2021. doi:10.1145/3447786.3456240 ↩︎
Heidi Howard, Dahlia Malkhi, and Alexander Spiegelman. Flexible Paxos: Quorum Intersection Revisited. At 20th International Conference on Principles of Distributed Systems (OPODIS), December 2016. doi:10.4230/LIPIcs.OPODIS.2016.25 ↩︎ ↩︎
Martin Kleppmann. Distributed Systems lecture notes. University of Cambridge, October 2024. Archived at perma.cc/SS3Q-FNS5 ↩︎ ↩︎
Kyle Kingsbury. Call Me Maybe: Elasticsearch 1.5.0. aphyr.com, April 2015. Archived at perma.cc/37MZ-JT7H ↩︎
Heidi Howard and Jon Crowcroft. Coracle: Evaluating Consensus at the Internet Edge. At Annual Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), August 2015. doi:10.1145/2829988.2790010 ↩︎
Tom Lianza and Chris Snook. A Byzantine failure in the real world. blog.cloudflare.com, November 2020. Archived at perma.cc/83EZ-ALCY ↩︎
Ivan Kelly. BookKeeper Tutorial. github.com, October 2014. Archived at perma.cc/37Y6-VZWU ↩︎
Jack Vanlightly. Apache BookKeeper Insights Part 1 — External Consensus and Dynamic Membership. medium.com, November 2021. Archived at perma.cc/3MDB-8GFB ↩︎